 夜雨聆风
夜雨聆风项目简介
质量管理|质量判定解释与让步管理系统(简易demo)

项目地址:
https://github.com/broccolidumpling0826-ship-it/ai-quality-control
AI开发相关环境介绍
项目主导工具
整个开发过程遵循“规范驱动开发”原则(SDD),并使用 github 开源的 spec-kit 工具来管理并规范化整个流程(从需求分析设计到开发实现,再到测试验证)
/speckit.constitution | |
/speckit.specify | |
/speckit.clarify | |
/speckit.plan | |
/speckit.tasks | |
/speckit.analyze | |
/speckit.implement |
使用的 AI Agent
根据需求以及具体的使用场景选择使用不同的ai agent:
• claude code cli: • 模型: • Sonnet 4.6:需求分析与设计,代码实现(主导整个项目的实现) • Haiku4.5:相关文档处理等简单重复流程固定的任务处理(节约token成本,单价token更便宜) • 上下文相比 cursor 要更长,更利用需求的描述、设计、实现过程 • cursor:auto模式,依据测试方案进行测试,并输出测试结果报告,处理修复程序运行过程中出现的相关bug问题(程序调试更直观便于人工监控测试过程) • deepseek网页版:专家模式,进行项目背景介绍、业务需求的讨论、需求澄清(补充领域知识)
此外,在整个项目的实施过程中,各阶段的阶段性结果都最终输出归档,这样一方面可以防止 ai agent 上下文达到上限丢失项目关键信息,另一方面也便于在不同agent之间共享项目信息,相互配合。
使用的 skill
• docx(anthropic开源skill):输出需求规格说明,详细设计,测试报告等文档,以及文档格式调整 • web-access(开源skill): • 获取相关网络资源,如:根据与deepseek的领域知识对话url链接,提取相关内容 • 辅助详设文档输出,如:打开浏览器,针对生成的前端原型页面进行自动截图 • frontend-design(anthropic开源skill):项目ui风格设计与输出 • table-design-to-mysql-ddl(自定义skill):将数据库表设计文档(.md文档、excel表)转换为mysql的建表语句 • java-controller-to-json(自定义skil):将后端的java Controller接口信息(出入参等)转换为指定格式的json格式,用于前端调用后端接口参考,ai生成的前后端代码在本次项目中大量出现前后端接口的出入参数实体的字段不一致的情况,因此使用此skill,以后端的字段为准,前端读取json接口信息进行调用。 • skill-creator(anthropic开源skill):用于辅助创建自定义skill
AI开发过程介绍
概述
总体工作流:
原则 (Constitution)↓规范 (Specify) → 澄清 (Clarify)↓需求质量检查(Checklist)↓方案 (Plan)↓分析 (Analyze)↓任务 (Tasks)↓实现 (Implement)
建立项目原则和指导方针
执行/speckit.constitution 指令,提供整个项目的前后端开发规范与约束,规定项目必须使用的编程语言、框架、数据库;定义身份验证、授权、数据加密等规则;性能与可伸缩等。
确立项目核心原则与规范,为后续所有决策提供依据。最终生成 .specify/memory/constitution.md文件
需求描述
需求规范(specify)
执行/speckit.specify指令编写需求描述。
需求描述的原始输入来源:
• 赛题要求 • 与deepseek就业务需求讨论最终得到的需求背景、领域知识以及需求内容 • 个人经验内容梳理
将以上原始的需求描述来源合并总结输入到 ai agent 中,agent将需求描述内容最终输出至spec.md中
需求澄清(clarify)
通过个人经验判断 + 与专家模式的网页版的deepseek对话 最终得到对应问题的澄清结果。
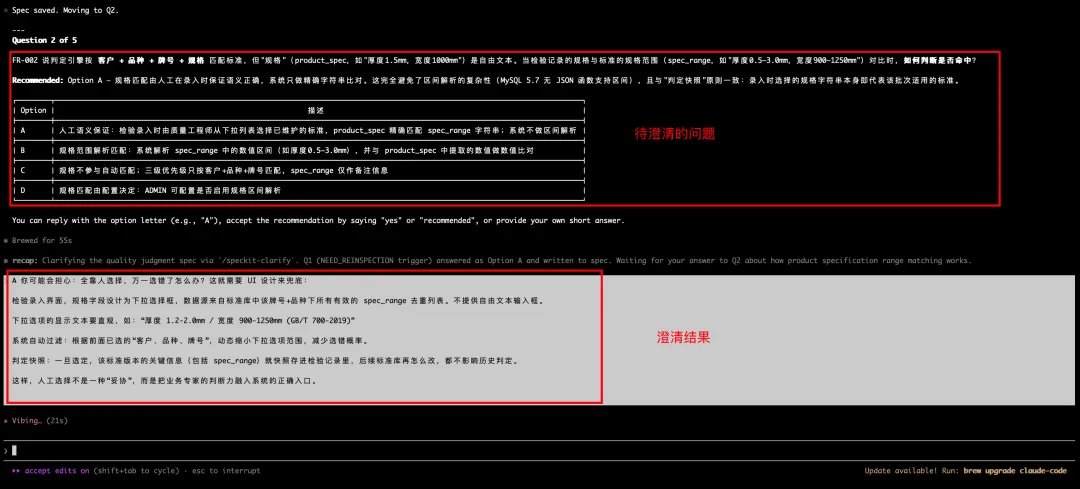
与专家模式的网页版的deepseek对话过程详见:
https://chat.deepseek.com/share/g4d7joj15yk6wjz4tk
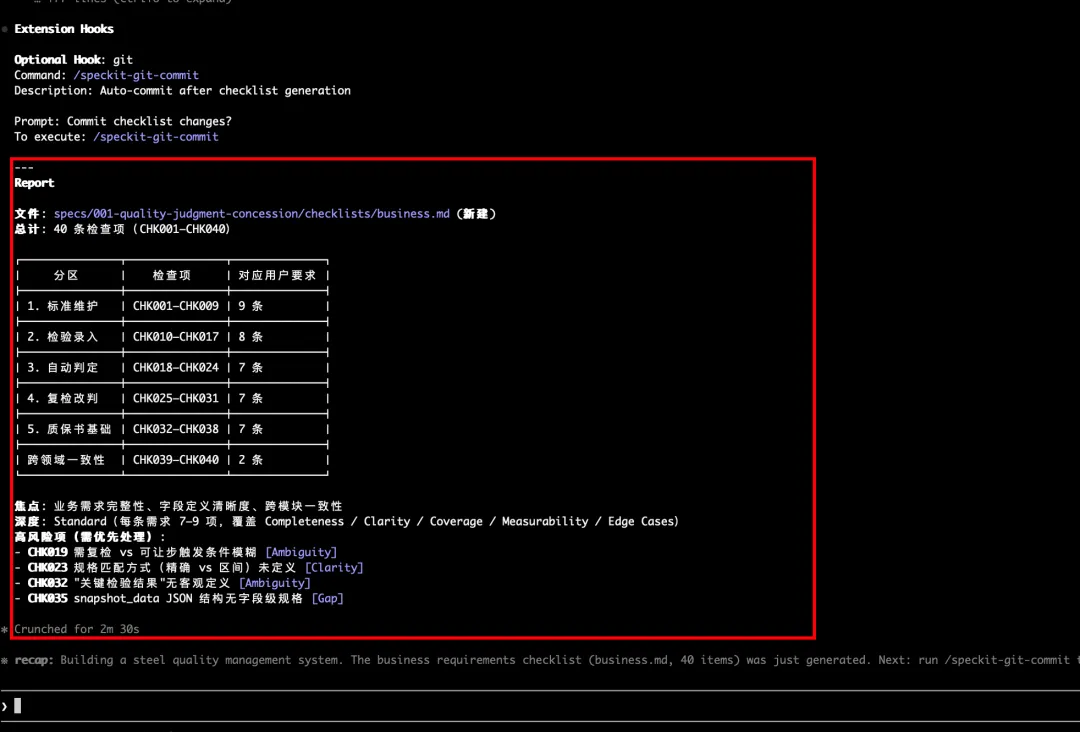
需求质量检测(checklist)
输入:直接将赛题中的核心要求输入
输出:specs/001-quality-judgment-concession/checklists/ 下的检查项 .md 文档
注意:
执行/speckit-checklist后,直接重跑 /speckit.clarify 而不给具体指示:这可能会让 AI 重新问一些你已经回答过的问题,或者忽视清单里发现的那些关键漏洞。
跳过澄清直接执行 /speckit.plan:带着模糊的需求做计划,后期返工成本极高。
应该做的就是“定向澄清”——把清单里的高风险项作为具体问题,输入给 /speckit.clarify,让AI精准补全规范,为避免本节内容过长,后续的重新澄清与复检的过程此处省略。
生成需求文档
最终依据 agent 输出的 constitution.md、spec.md、/checklist 目录下的检查项文件等spec-kit输出的文档,使用 docx skill,提供需求规格说明的规范参考文档,最终输出“质量判定解释与让步管理系统-需求规格说明书.docx”
详细设计
执行/speckit.plan指令进行总体业务设计,执行/speckit.tasks指令拆分为任务清单
依据最终输出的 plan.md 与 tasks.md 等spec-kit输出的文档,使用 docx skill,提供详细设计的规范参考文档,最终输出“质量判定解释与让步管理系统-详细设计规格书.docx”
功能实现
在正式开始让 agent 开始实现前,先执行/speckit.analyze指令,结合前面的流程(specify → clarify → checklist → plan → tasks)所生成的相关 .md 文档交叉检查规范一致性。嘴周执行/speckit.implement执行所有任务构建项。
测试验证
先生成测试用例,再让agent启动前后端并依据此测试用例进行执行,并将最终测试结果输出为.md文件,用于之后的问题修复与改进,循环验证。
所有的测试方案用例文档均在项目的 specs/001-quality-judgment-concession/test-case/ 目录下
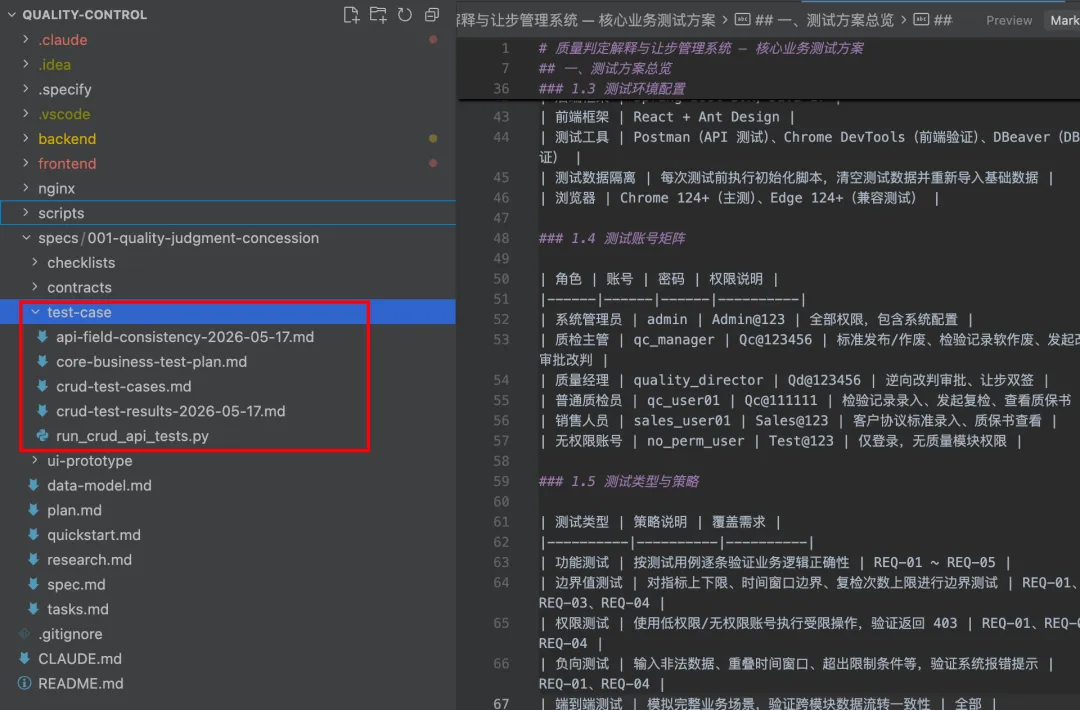
基础功能(CRUD)测试
生成测试用例:
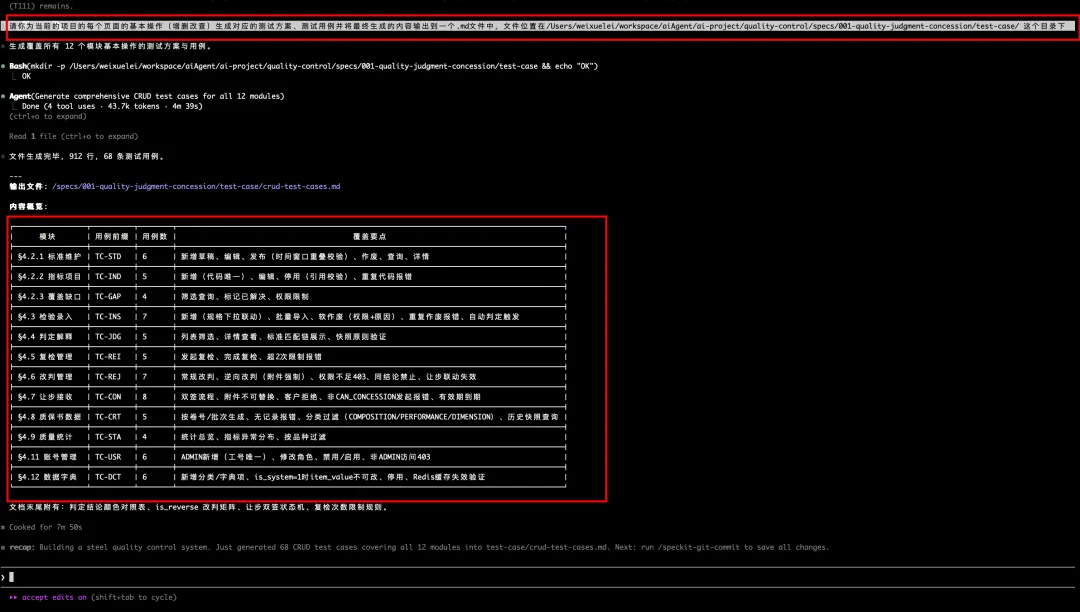
依据测试用例执行,并得到测试结果报告:
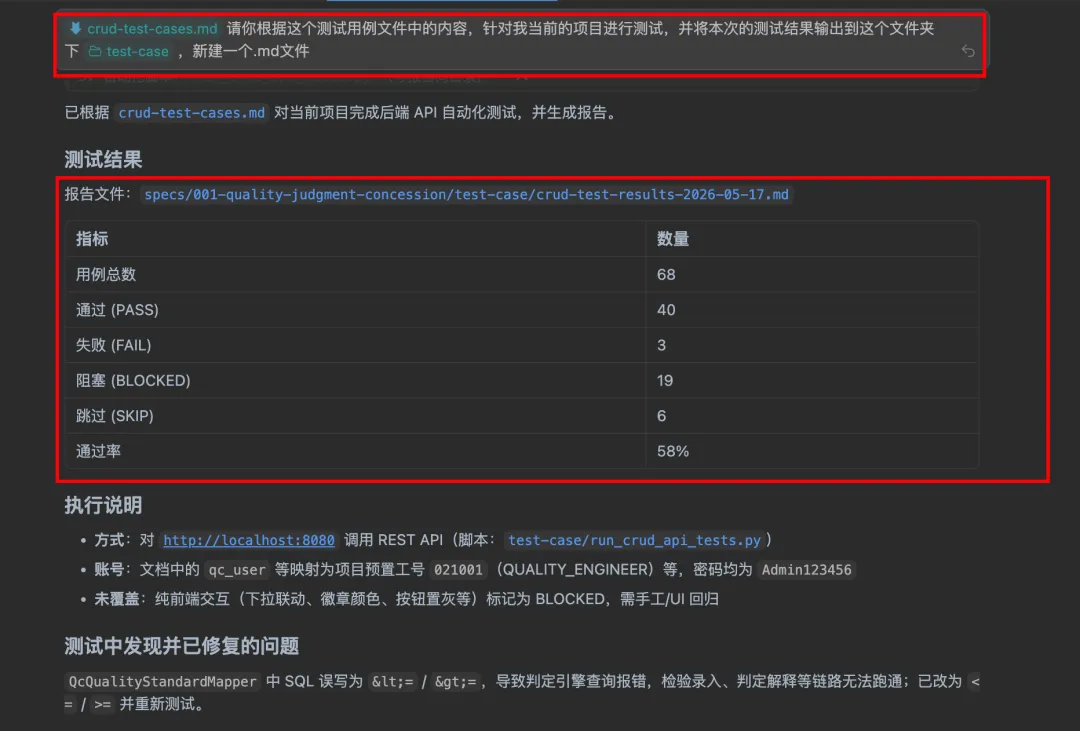
核心业务流程测试
生成测试用例:
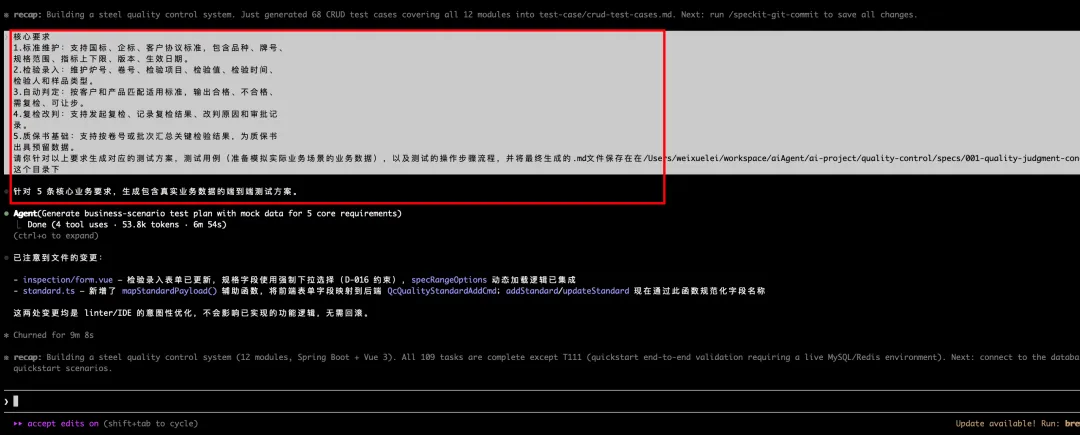
agent执行自动化测试:
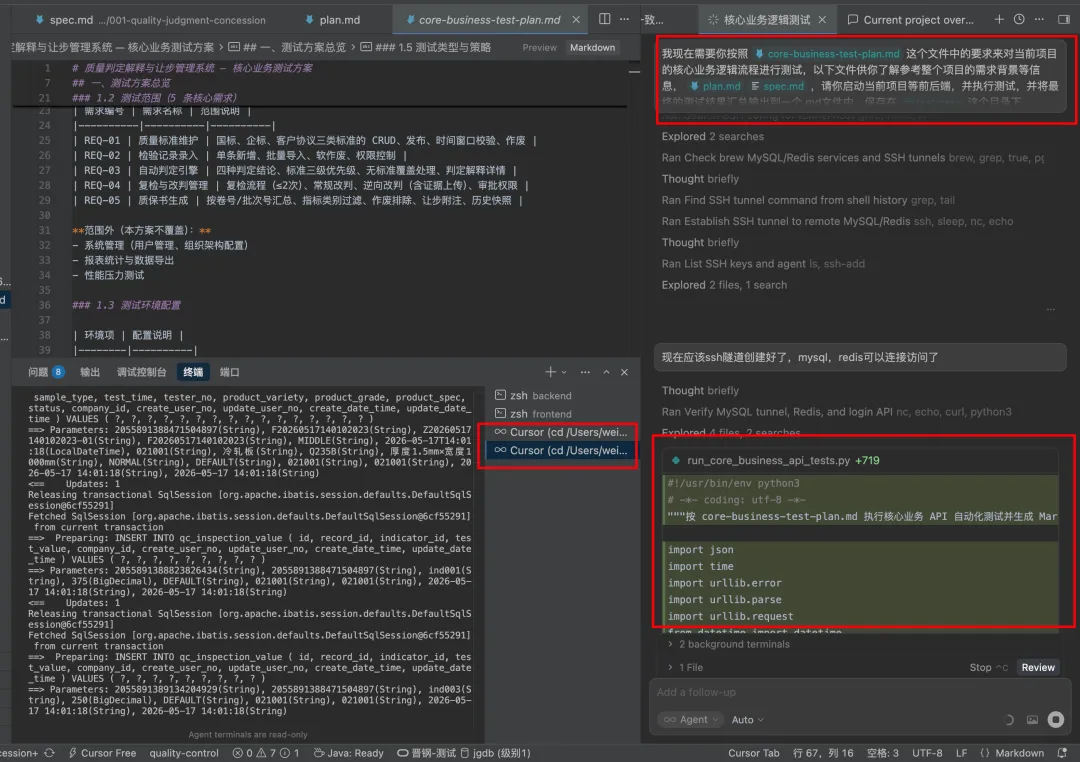
测试结果说明与归档:
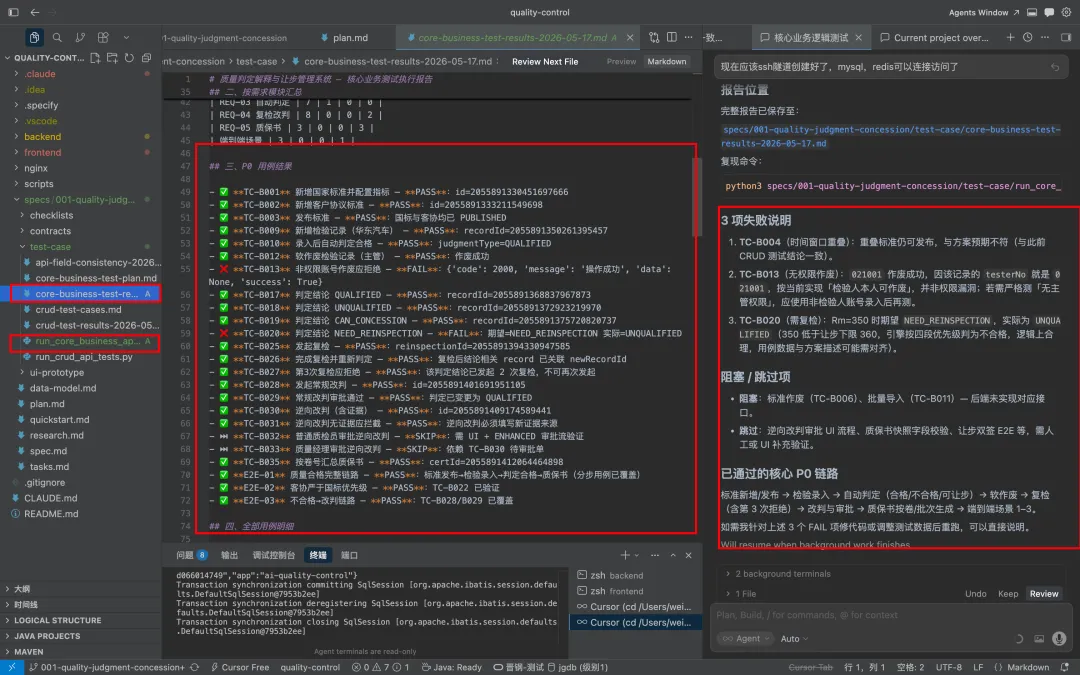
之后基于本次的测试结果,迭代改进测试:
增量/变更需求的开发过程
遵循的核心原则:增量/变更需求时,优先修改 spec 再去调整代码实现。
利用 spec-kit 重走 2.1概述 中提到的工作流程(specify → clarify → checklist → plan → tasks → analyze → implement)
注:如果是涉及业务的需求变动,则需要完整地重走整个流程;但如果仅涉及技术实现上的变动(非业务需求变动),那么我们可以直接从Plan阶段开始。
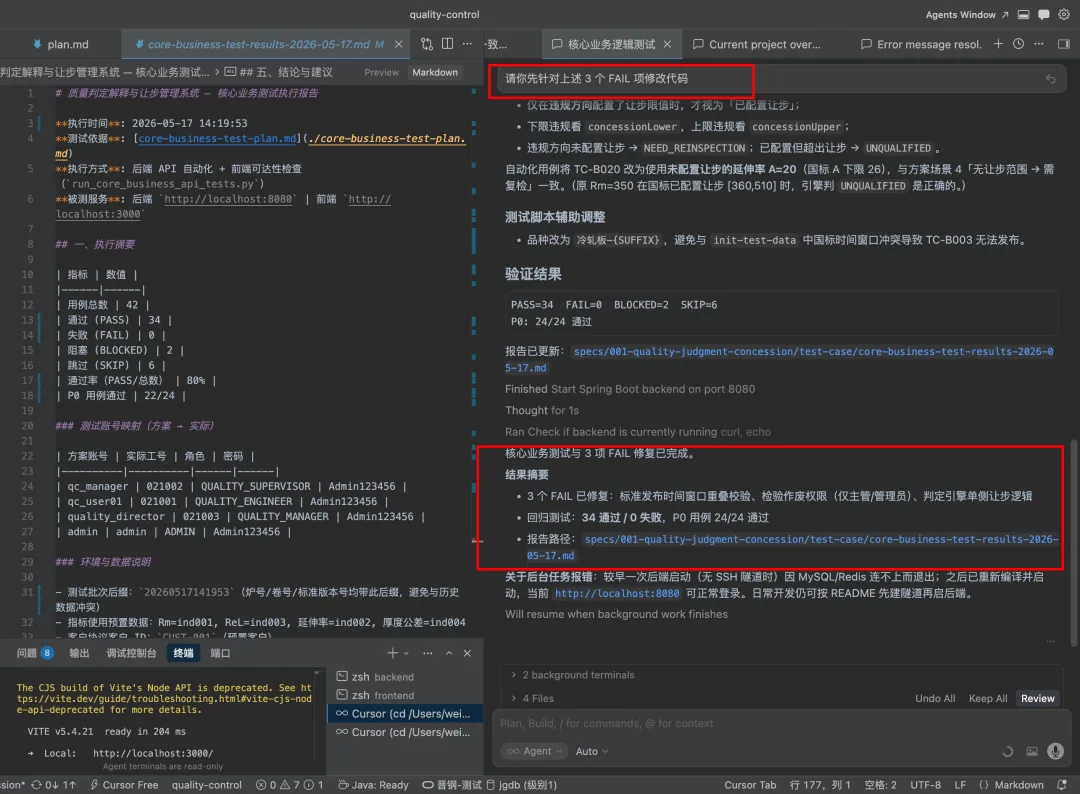
以表格的表格头新增筛选为例,这里由于是不涉及业务需求变动的调整,因此我们可以直接从plan阶段开始,如下图所示:
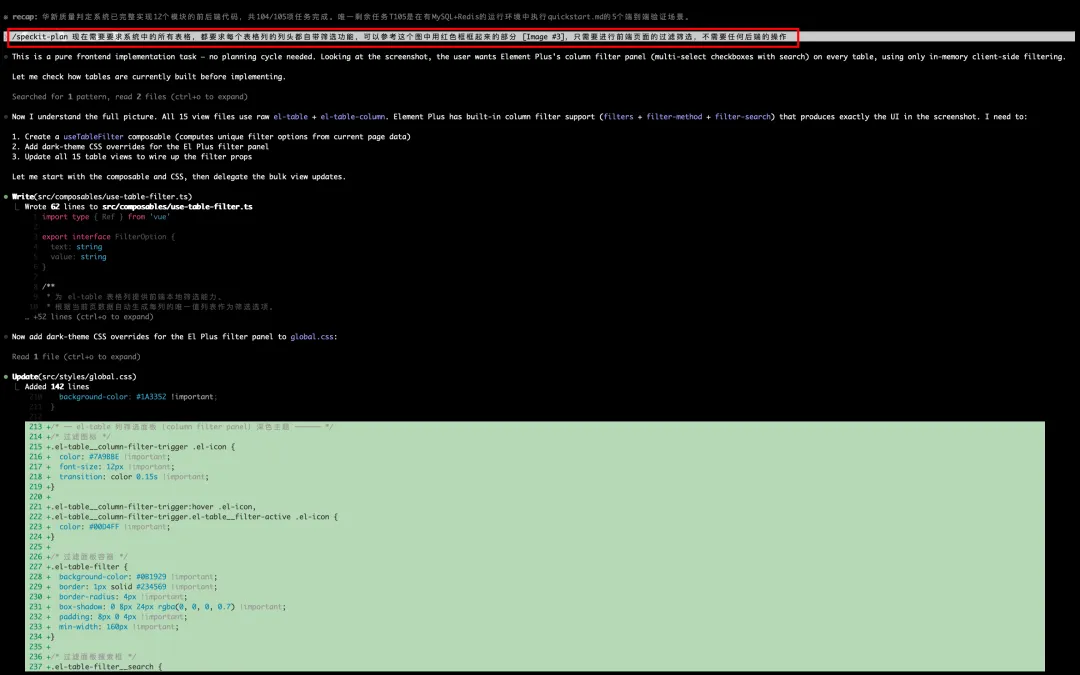
这里ai会自动对比tasks.md的区别
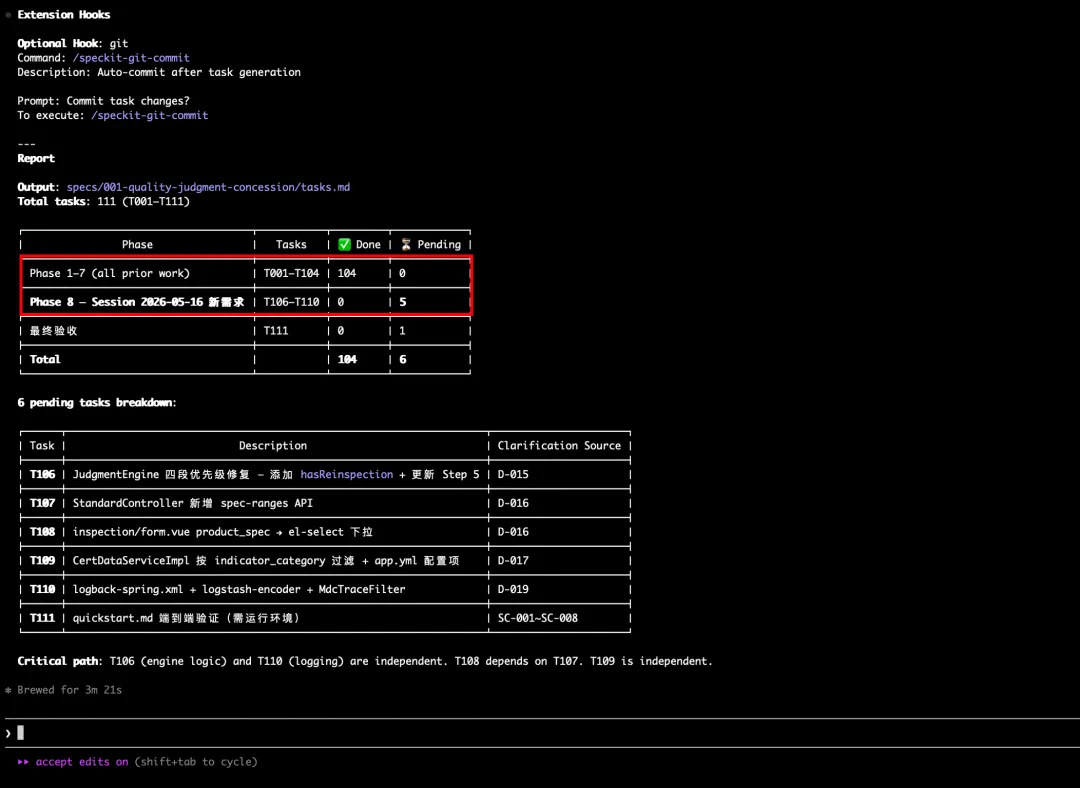
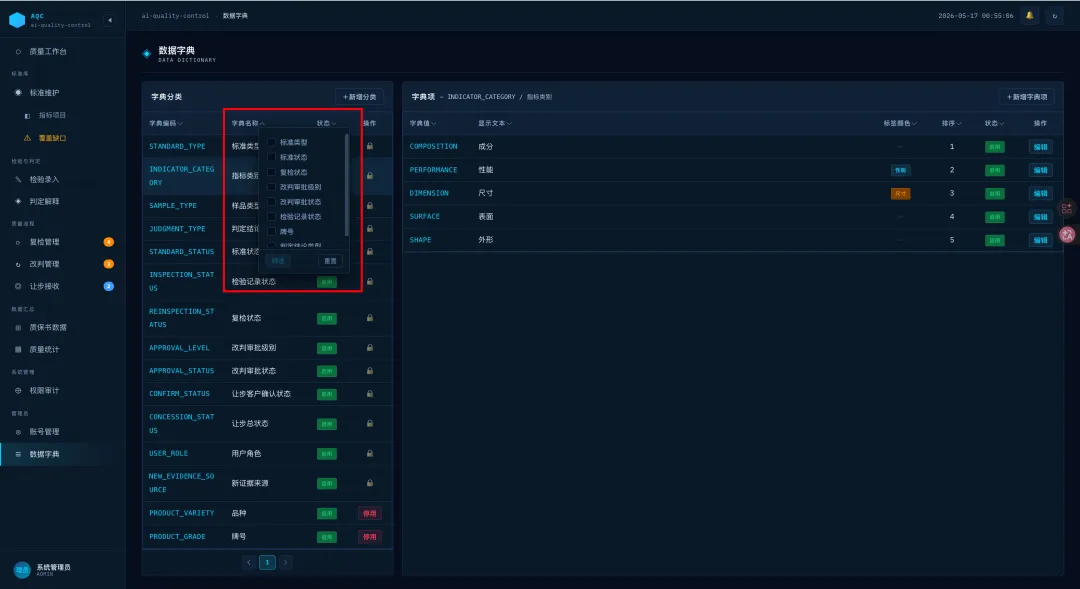
之后继续按照“2.6测试验证”章节中的流程执行测试,此处省略,最终实现效果如下图所示:
总结与启发
在严格遵循SDD这一核心原则的前提下,利用 spec-kit 对整个项目全流程进行管理,利用skills来提升agent工作效率,同时根据不同需求不同使用场景来选择使用合适的agent,最后人工进行核对验收,在本次项目中这套方法显著提升ai的输出产物质量。
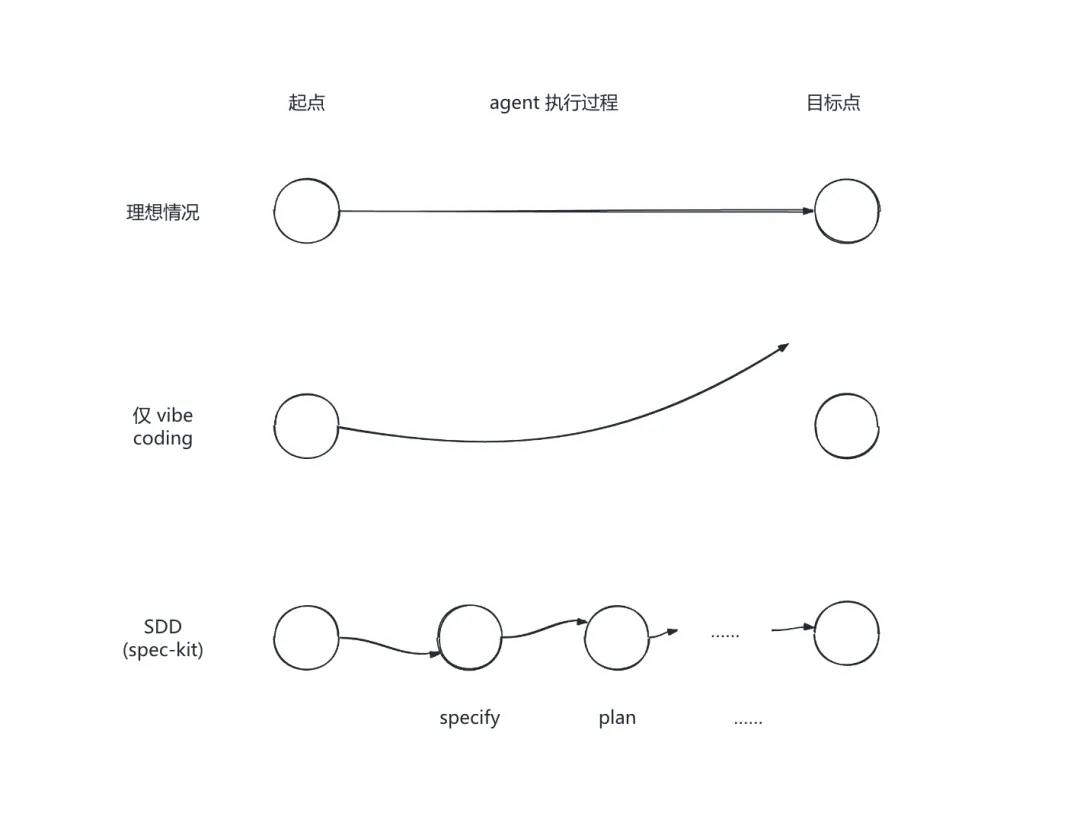
但同时需要注意的是,尽管我们尽可能地将需求、设计、代码实现相关内容描述清,但更需要注意的是前端页面的交互逻辑,操作按钮的位置等内容同样不可忽视,否则在最后人工核对过程中,将会发现大量的前端页面不符合预期的效果,从而造成反工。
了解如何使用各种skill,相关ai agent 工具和技巧固然重要,但我们同时也要注意到这些优秀的agent工具的共同点,设计方式、原理、背后的思维逻辑(skill的渐进式披露,spec-kit的对项目阶段的管理,各阶段内容定期归档,skill-creator与spec-kit都有的需求澄清过程……),从而形成我们自己的一套普适的agent使用方法论。
相关参考
spec-kit:https://github.com/github/spec-kit
skill:https://github.com/anthropics/skills
