 夜雨聆风
夜雨聆风英伟达B200,全球最强AI芯片。
但在推理场景里,它98%的运算时间处于闲置状态。
这不是夸张,是英伟达自己的架构决定的。

图:英伟达B200芯片 — 来源:Nvidia官方
◆英伟达GPU的内存墙问题
先把问题说清楚。
AI推理和AI训练是两件不同的事。训练是一次性的大规模并行计算,GPU的架构天然适合——大量tensor core同时工作,效率极高。
但推理不一样。推理是一个串行过程:每次生成一个token,需要反复读取模型权重,然后计算,然后再读取,再计算。这个过程叫Decode阶段。
问题在这里:Decode阶段的瓶颈不是计算速度,是内存读取速度。
英伟达B200的内存带宽是8TB/s,听起来很大。但在Decode阶段,tensor core的空闲率超过99%,98%的运算时间处于等待内存数据的状态。你花了几百万美元买了一块算力极强的芯片,结果它大部分时间在等数据。
这就是「内存墙」问题。
德勤数据显示,2023年AI算力支出训练占60%、推理占40%,但到2025年这个比例几乎翻转,推理预计将占企业AI预算的85%。英伟达65%的数据中心收入来自推理,而这恰恰是传统GPU架构效率最低的场景。
◆ 颠覆者来了:Cerebras
Cerebras Systems 是一家专注于人工智能(AI)与高性能计算(HPC)领域的美国半导体初创公司,总部位于加利福尼亚州桑尼维尔市,成立于2016年。其核心创新在于颠覆传统芯片设计逻辑,5月15日通过IPO募集资金超过55亿美金,成为2026年以来最大规模的新股发行,市值一度超过800亿美金。
◆Cerebras的解法:把整片晶圆做成一块芯片
Cerebras的WSE-3(Wafer Scale Engine 3)是一个极端的工程方案:用整片300mm硅晶圆作为单一处理器。
普通芯片是从晶圆上切下来的一个小方块,多个芯片封装在一起,芯片之间通过总线通信,有延迟,有带宽限制。WSE-3没有这个问题,因为它就是一整片硅,片上通信速度极快。
官方数据:WSE-3片上带宽达21PB/s,是英伟达B200的8TB/s的2625倍。实测Llama 3.3 70B推理速度是当前最佳方案的18倍。
这个数字如果是真的,确实是颠覆性的。
但晶圆级芯片不是新概念,业界早就知道这个方向,为什么没人做?因为有三个工程难题,被认为几乎无法解决。
◆三个工程难题,Cerebras怎么解决的
▸难题一:良品率。
普通芯片从晶圆上切下来,一片晶圆可以切出几百个芯片,有缺陷的扔掉,良品率80%也能接受。但如果整片晶圆是一块芯片,只要有一个缺陷,整片晶圆就废了。
Cerebras的解法:小核心高缺陷容忍度设计。WSE-3上有40万个核心,每个核心很小,设计上允许一定比例的核心有缺陷,通过冗余设计绕过坏掉的核心继续工作。就像一个有几个灯泡坏掉的LED灯板,整体还能正常发光。
▸难题二:散热。
一整片晶圆的功耗极高,散热是个大问题。普通芯片可以用风冷,但晶圆级芯片的热密度远超风冷能处理的范围。
Cerebras的解法:垂直供电加水冷散热。电源从芯片底部垂直输入,减少电阻损耗;冷却水直接流过芯片表面,带走热量。这套方案需要专门的机柜,不能插在普通服务器里用。
▸难题三:光刻边界。
光刻机的曝光区域有限,一次只能曝光晶圆的一部分。整片晶圆需要多次曝光拼接,拼接处的电路连接是个难题。
Cerebras的解法:「划线桥接」光刻技术。在拼接处用特殊的桥接结构连接不同曝光区域的电路,保证信号传输的连续性。
这三个问题,Cerebras花了将近十年解决。这是真实的技术壁垒,不是PPT上的概念。
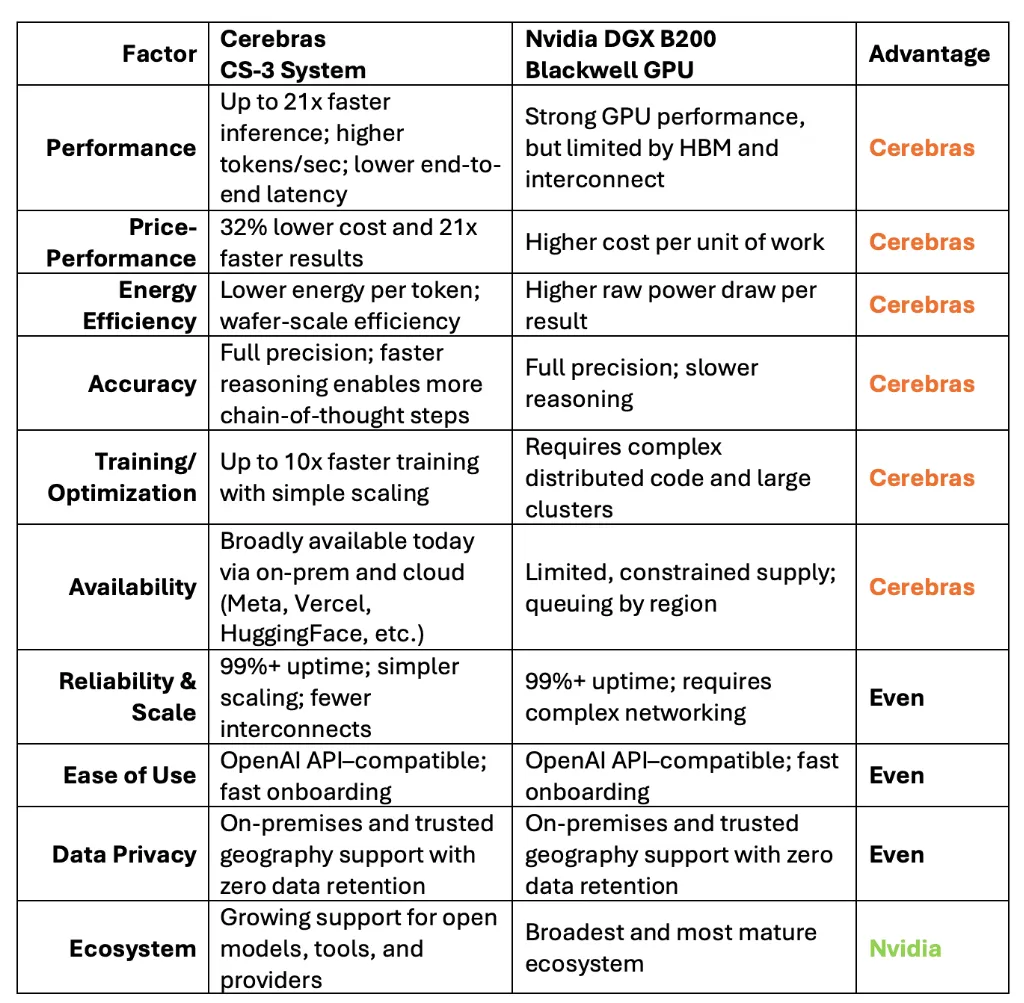
图:WSE-3 与英伟达 B200 详细性能对比 — 来源:Cerebras官方
◆但它有一个边界
WSE-3的推理速度是真实的,但有一个关键限制:44GB片上内存。
这个内存容量,只够装下中等规模的模型,做短上下文的一问一答推理。
增长最快的场景是什么?长上下文AI Agent——需要处理几十万token的上下文,需要多轮对话记忆,需要调用工具、执行多步骤任务。这些场景需要的内存远超44GB。
换句话说,WSE-3在它擅长的场景(短上下文、高吞吐量推理)里确实比英伟达快18倍,但在AI Agent这个增长最快的场景里,它的内存根本装不下。
这不是小问题。这意味着Cerebras的市场是推理市场的一个子集,而不是全部。
◆一个直接的判断
Cerebras解决了一个真实的工程问题,用了一个极端但有效的方案。这是值得认真对待的技术成就。
但它的市场定位是「特定场景的推理加速器」,不是「英伟达的全面替代品」。
说实话,AI推理市场不是赢家通吃的。英伟达做通用推理,Cerebras做短上下文高吞吐,Groq做低延迟,各自有各自的场景。这个市场足够大,容得下多个玩家。
对做AI硬件的人来说,Cerebras的故事有一个值得记住的教训:架构创新的壁垒,比工艺节点的壁垒更难复制。
英伟达可以用更先进的制程提升GPU性能,但它没办法把GPU变成晶圆级芯片——那需要重新设计整个架构,重新解决良品率、散热、光刻的问题。这是Cerebras真正的护城河。
等WSE-4出来,看它能不能把内存容量提上去,那才是真正的考验。
◇ ◇ ◇
数据来源:Cerebras官方、德勤、虎嗅网、Spheron技术分析、纳斯达克
AI硬玩社
聚焦 AI 硬件,分享见解和认知
