 夜雨聆风
夜雨聆风普通 AI 对话学习,很多时候像是在路边问路。
你问一个问题,它回答一个问题;再问一个问题,它再回答一个问题。短时间看很方便,但学久了就会发现几个问题:知识点不成体系,问完就散,没有清晰路径,也不知道自己到底掌握到什么程度。
这也是我为什么开始研究 DeepTutor。
DeepTutor 更像是一个“学习驾驶舱”,不是单纯陪你聊天,而是把学习拆成一套完整流程。它里面有多 Agent 协作,有 RAG 知识库,有学习路径生成,有 Quiz 测验,也有 Mastery 掌握度追踪。
简单理解就是:
普通 AI 对话:像临时问答DeepTutor:像一个会备课、会答疑、会出题、会记录成绩的学习系统
我这次做的事情,首先是把 DeepTutor 这个开源项目真正跑起来。
过程并不是“克隆项目后一键启动”那么简单。我先从 GitHub 克隆项目,安装 Python 后端依赖和 Next.js 前端依赖,然后配置 DeepSeek 作为 LLM,配置 Embedding 模型,接着启动 FastAPI 后端和 Next.js 前端。
这一步像是先把一间教室搭起来:老师、黑板、课本、题库、学生档案都要能正常工作。
但真正困难的地方,不在“搭建”,而在“让它真的可用”。
在实际运行 DeepTutor 的过程中,我连续修复了 20 个问题。比如后端路由没有注册,导致 knowledge_learning API 返回 404;DeepSeek 不支持 JSON mode,导致知识点提取失败;UUID 格式不合法,导致学习会话启动崩溃;LearningSession 缺少 metadata,导致 Agent 拿不到知识点上下文;前端请求打到了错误端口,导致页面没反应;Markdown 没有正确渲染,导致 AI 回答看起来像原始文本;切换 Tab 后组件被卸载,聊天记录直接丢失。
这些问题单独看都不大,但叠在一起,就像一台机器每个齿轮都差一点点:能启动,不代表能稳定运转。
修完这些问题后,我开始用它做真实学习测试。
我上传了 AI 产品经理相关资料,让系统从资料里提取知识点,再生成学习路径。
然后通过 Tutor 讲解知识点,通过 QA 追问细节,通过 Quiz 检测理解,最后用 Mastery 查看掌握度。
这时候 DeepTutor 才真正形成了一个学习闭环:
上传资料 → 提取知识点 → 生成学习路径 → Tutor 讲解 → QA 答疑 → Quiz 测验 → Mastery 追踪这套流程和普通 AI 问答最大的区别是:
它不是只回答你当下的问题,而是在帮你搭一张学习地图。
在这个过程中,AI 也不只是帮我写代码。它还帮我读项目结构、定位 bug、修前后端、整理工作日志,并且把其中几个通用问题整理成 issue,提交到了 DeepTutor 上游仓库。
所以这次实战给我的最大感受是:
开源项目能跑,不等于真的能用;AI 编程也不是一句话生成项目,而是持续排错、改造和验证。
DeepTutor 本身像一套复杂的教学系统,而 AI 编程更像带着一个工程助手一起装修这间教室。它可以帮你搬桌子、接电路、修投影、整理课程表,但你仍然要不断检查:门能不能打开,灯会不会亮,学生坐下来以后能不能真的开始学习。
这才是我觉得这次项目最有价值的地方。它不是一个简单 demo,而是一次把开源项目从“可以启动”推进到“可以使用”的完整过程。
- 为什么我要搭一个 AI 产品经理学习助手
- DeepTutor 是什么:一个多 Agent 学习系统
- 我是怎么用 Claude Code 把项目跑起来的
- 从能启动到能使用:我修了哪些关键问题
- 我如何把它改造成 AI 产品经理学习助手
- Claude Code 在这次项目中真正帮了什么
- 这次实战给我的启发和踩坑总结

01.为什么我要搭一个 AI 产品经理学习助手?
我搭这个 AI 产品经理学习助手,不是因为想再做一个 AI 工具,而是因为我发现:AI 产品经理这件事,很难靠零散文章真正学明白。
第一,AI 产品经理的知识太杂,没人能一次讲清楚。
它不是单一学科。你既要懂技术,比如 LLM、Agent、RAG;也要懂产品,比如需求分析、用户画像、产品设计;还要懂商业,比如商业模式、增长路径、数据飞轮。
传统学习方式通常是看文章、看视频、翻文档。但每个来源的深度不一样,讲法也不一样。
遇到问题时,只能继续搜索。
我之前搭 RAG 系统时就有很深的感受。光是“向量检索怎么和 BM25 混合”这一个问题,就要问很多的AI,但每家的AI,哪怕世界最顶尖的大模型每次生成的内容都不一样,不能给出一个固定的答案,只有在实践中把项目搭好,进行复盘时才能把原理和实现方式串起来。
第二,学完容易忘,因为没有反馈闭环。
很多时候,看完一篇长文会觉得自己懂了,但一到实际应用或者做题,就发现只是“看懂了”,并没有真正掌握。
所以我需要一个能根据学习内容出题的系统。
不是网上随便找一套题库,而是围绕我刚刚学习的知识点,自动生成测验。
DeepTutor 里的 Quiz Agent 正好对应这个需求。
它可以根据知识点出题,让我通过回答问题来检查自己是不是真的理解了。
第三,现有 AI 工具更像通用问答,不像学习伙伴。
ChatGPT 很强,问什么都能答。
但普通对话有一个问题:它不知道我学到了哪一步,也不知道哪些内容我已经掌握,哪些地方还很薄弱。
我需要的不是一次性的答案,而是一个有学习记忆的系统。
它应该知道我学过哪些知识点,测验结果怎么样,下一步应该学什么。
这就是 DeepTutor 里学习路径和 Mastery 掌握度追踪的意义。
所以需要将大模型装进一个盒子里去发挥它的性能,在特定的领域,就需要搭建特定的Agent。ChatGPT+DeepTutor,性能也一定很强,在后续的实践过程中给到大家反馈!
第四,一个人学习很容易中断,需要持续互动。
自学最大的问题不是没有资料,而是很难一直坚持。
尤其是 AI 产品经理这种跨技术、产品、商业的方向,越学越容易觉得分散。
DeepTutor 里的 Tutor Agent、QA Agent、Quiz Agent 正好像三个不同角色:
Tutor Agent 负责讲解QA Agent 负责答疑Quiz Agent 负责出题Mastery 负责记录掌握情况
它不只是给我一份资料,而是把学习过程变成了一轮一轮的互动。相比一个人干看文档,这种方式更容易持续下去。
所以,我搭这个 AI 产品经理学习助手,核心目的不是“做一个聊天机器人”,而是想搭一套属于自己的学习系统:
资料能被整理知识点能被提取路径能被生成问题能被追问掌握度能被记录

DeepTutor 是什么?
如果说普通 AI 对话像“你问一句,它答一句”,那 DeepTutor 更像一间 AI 自习室。
它不是一个万能聊天机器人,而是 HKUDS 开源的一个多 Agent 学习系统。它的核心思路是:让多个 AI 角色分工协作,模拟一个完整的学习环境。
在这个系统里,AI 不只是回答问题,还会讲课、答疑、出题,并记录你的学习进度。
DeepTutor 里最关键的是三个学习角色:

这三个 Agent 不是孤立工作的。它们共享同一个学习会话的上下文。
比如我先让 Tutor Agent 讲解一个知识点,再切到 Quiz Agent 做测验,最后切到 QA Agent 追问错题。这个过程中,系统知道我刚刚学了什么、问了什么、哪里答错了,而不是每切一次角色就重新开始。
这就是 DeepTutor 和普通 ChatGPT 对话最大的区别。
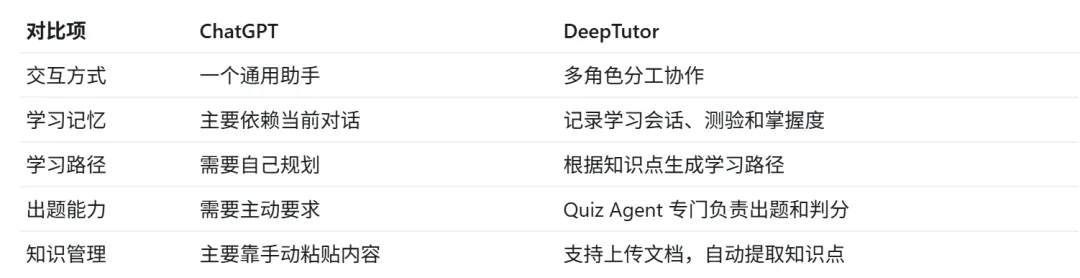
简单说,ChatGPT 更像一本随时能查的百科全书;
DeepTutor 更像一个陪你一步步学习的私教系统。
它不是只回答“这个问题是什么”,而是继续追问:
你学到哪了?这个知识点掌握了吗?要不要做几道题?下一步该学什么?错题要不要再解释一遍?
所以我更愿意把 DeepTutor 定义为:
DeepTutor 是一个多 Agent 学习系统:Tutor Agent 负责讲,Quiz Agent 负责考,QA Agent 负责答疑,多个 AI 角色围绕你的学习进度协作,而不是一个什么都懂但不知道你学到哪的聊天框。

03.我是怎么用 Claude Code 把项目跑起来的?
DeepTutor 的代码已经在 GitHub 上,但开源项目能克隆下来,不代表马上就能用。
我本地装好项目后,上传了一个“AI 产品经理学习路径”的资料包,一个 22MB 的 PDF。
结果点开“知识学习”页面,文档下拉框是空的,知识点树加载失败,学习会话也点不动。
这感觉就像买了一台新电脑,开机能亮,但一打开软件,到处都是报错。
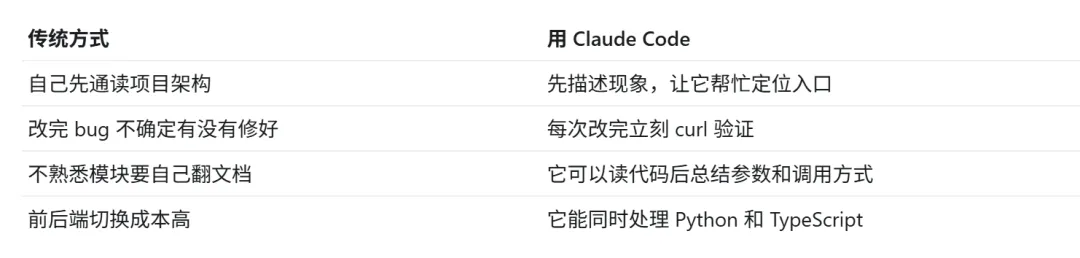
第一步,我让 Claude Code 当“代码侦探”。
我没有一行行读源码,而是先把现象告诉它:
知识学习页面,文档下拉框是空的,选不了任何东西。前端组件用的是硬编码空列表,没有真正调用 APIAPI 请求发到了前端端口,而不是后端 8001后端 knowledge_learning 路由没有注册到 main.py
也就是说,不是一个地方坏了,而是前端、接口、后端路由三段链路都没接上。
第二步,每次只修一个问题,然后重启验证。
Claude Code 的处理方式基本是:
读报错 → 定位文件 → 修改代码 → 重启服务 → curl 测试 API → 继续下一个问题PDF 太大,超过默认 10MB 限制DeepSeek 不支持 JSON mode,返回的是 markdown 包裹的 JSON提取出的知识点没有 UUID,前端无法选择
这就像修水管,看到的是水龙头不出水,但真正的问题可能在阀门、管道和水压三个地方。
第三步,让 Agent 真正动起来。
DeepTutor 里有 TutorAgent、QAAgent、QuizAgent,但原来的消息接口只是占位逻辑。用户发消息后,系统返回的是:
已记录你的消息,请通过对应的 Capability 执行 Agent 调用说白了,它只是记下消息,并没有真正调用 LLM。
Claude Code 读了 TutorAgent、QAAgent、QuizAgent 的代码,确认每个 Agent 需要什么参数,然后在 send_message 接口里补上真实调用逻辑。
其中 QuizAgent 还要多处理一步:它生成的是结构化题目,需要前端渲染成可以答题的界面,而不是直接显示成一段文本。
第四步,修体验细节。
功能能跑以后,还有很多“看起来小,但很影响使用”的问题:
Markdown 没有渲染,加粗和标题直接显示成原始语法掌握度和学习路径页面显示 UUID,看不出对应哪个知识点切换 Tab 后聊天记录丢失
这些问题最后也都被逐个修掉。比如 Markdown 问题是因为前端没有正确渲染;Tab 丢状态是因为组件被条件渲染卸载了,改成 CSS 隐藏后,聊天记录就能保留下来。
整个过程下来,我最大的感受是:
这次我一共修了 20 个问题,覆盖后端路由、DeepSeek JSON 解析、UUID、metadata、前端端口、Markdown 渲染、Tab 状态保持等多个环节。
最关键的一点是:我不需要一开始就完全理解 DeepTutor 的全部架构,但我必须清楚自己想要什么效果,并且让 Claude Code 每修一步都验证一步。
这也是 AI 编程和普通“让 AI 写代码”的区别。它不是一句话生成完整项目,而是像带着一个熟悉代码的工程助手,一边排查、一边改造、一边验证,最后把项目从“能启动”推进到“真的能用”。

04.从能启动到能使用:我修了 20 个关键问题
项目能启动,只能说明它没有在第一步倒下。
真正点进“知识学习”页面后,我才发现问题才刚开始:文档下拉框是空的,知识点加载失败,学习会话发消息没反应,掌握度和学习路径页面显示一串 UUID。
能启动和能用之间,隔着 20 个 bug。
我把这些问题分成六类来看。
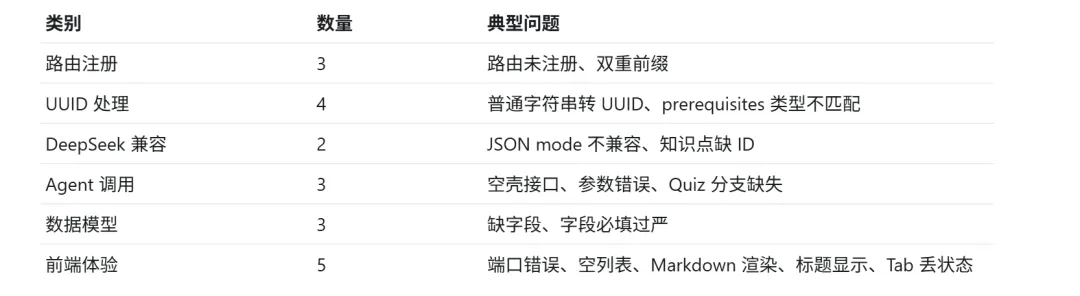
第一类是路由注册问题。
项目里有 knowledge_learning.py 和 mastery.py 这些路由文件,但它们没有完整注册到 main.py。结果就是前端页面调用接口时,后端直接返回 404。
还有一个更隐蔽的问题:路由文件里写了一次 /api/v1/knowledge-learning 前缀,main.py 注册时又加了一次,最后路径变成了:
/api/v1/knowledge-learning/api/v1/knowledge-learning/...看起来接口存在,实际永远匹配不到。
修复方式是:在 main.py 补上 import 和 include_router(),同时去掉路由文件里的重复前缀。
第二类是 UUID 问题。
DeepTutor 内部大量使用 UUID,但实际使用时,前端传来的可能是普通字符串,比如:
default-learner后端直接调用 UUID("default-learner"),自然就会崩。
类似问题还出现在学习路径、掌握度、prerequisites 字段里。LLM 提取出来的 prerequisites 可能是中文标题,比如:
["智能体的定义与基本要素"]但模型期望的是 UUID 列表。
修复方式是加一个 to_uuid() 辅助函数:如果本身是 UUID,就直接使用;如果是普通字符串,就用 uuid5(NAMESPACE_DNS, s) 生成一个稳定 UUID。这样同一个标题每次都会得到同一个 ID。
第三类是 DeepSeek 兼容问题。
DeepTutor 原本更偏 OpenAI API 的使用方式,但我实际配置的是 DeepSeek。
知识点提取 Agent 使用了:
response_format={"type": "json_object"}但 DeepSeek 不支持这个参数,返回的 JSON 还会包在 markdown 代码块里:
```json{"knowledge_points": [...]}```
这会导致 json.loads() 直接解析失败。
修复方式是:解析前先剥离 markdown 标记,再做 JSON 解析。同时,LLM 提取出的知识点如果没有 ID,就根据标题自动生成确定性 UUID。
第四类是 Agent 调用问题。
这是最关键的一类。
原来的 send_message 接口并没有真正调用 TutorAgent、QAAgent、QuizAgent。用户发消息后,只返回一句占位提示:
已记录你的消息,请通过对应的 Capability 执行 Agent 调用也就是说,页面看起来有 Agent,实际 Agent 没有动起来。
后面我让 Claude Code 读了 TutorAgent、QAAgent、QuizAgent 的代码,确认每个 Agent 的参数签名,然后在 send_message 里补上真实调用逻辑。
其中 QuizAgent 还要特殊处理:它生成的是结构化题目,需要通过 questions 字段返回给前端,再用 QuizPanel 渲染成交互式答题界面。
第五类是数据模型问题。
LLM 生成的数据和 Pydantic 模型之间有很多缝隙。
比如 LearningSession 没有 metadata 字段,导致 Agent 拿不到“当前正在学习哪个知识点”;KnowledgePoint 的 document_id 被定义成必填,但 LLM 提取结果里没有这个字段;PathStep 没有 title 字段,导致学习路径只能显示 UUID。
修复方式是让模型更贴近真实数据流:LearningSession 增加 metadata,KnowledgePoint 的 document_id 改为可选,PathStep 增加 title,生成学习路径时把知识点标题一起带上。
第六类是前端体验问题。
后端跑通后,前端还有一堆体验细节要修。
比如所有组件用相对路径 /api/... 请求接口,结果请求打到了前端端口,而不是后端 8001。文档下拉框是硬编码空列表,没有真正请求文档数据。Agent 返回的 Markdown 没有渲染,标题和加粗都原样显示。
还有一个很影响体验的问题:切换 Tab 后聊天记录会丢。原因是前端用了条件渲染:
{activeTab === "session" && <Component />}切换 Tab 时组件被卸载,状态自然没了。修复方式是让所有 Tab 始终挂载,只用 CSS hidden 隐藏非活跃页面。
这 20 个 bug,每一个单独看都不复杂,但叠在一起,就是一个“能启动但不能用”的项目。
这次 Claude Code 最大的价值,不是替我写了几段代码,而是帮我把问题拆开:从页面现象追到前端请求,再追到后端路由、数据模型、Agent 调用和 LLM 返回格式。
我不需要一开始就读懂几十个文件,但必须把现象描述清楚,并且让它每修一步都验证一步。
整个过程大概花了两三个小时。如果完全手动排查,我估计至少要一两天。

05. 我如何把它改造成 AI 产品经理学习助手
DeepTutor 本身是一个通用的多 Agent 学习框架,理论上什么学科都能用。
但我想做的不是一个“什么都能学”的平台,而是一个更具体的东西:AI 产品经理学习助手。
所以我的思路很简单:DeepTutor 提供学习系统的骨架,我把 AI 产品经理的知识灌进去,让它从一个通用框架,变成一个专属学习系统。
整个改造分四步。
第一步:上传学习资料,建立知识库
我手头有一份 22MB 的 AI 产品经理学习资料,里面包括智能体、LLM、Agent、RAG、Prompt Engineering、AI 产品设计方法论等内容。
这些内容如果只是放在 PDF 里,本质上还是一本“电子书”。你可以看,但它不会主动教你,也不会知道你哪里没学会。
所以第一步,是把这份 PDF 上传到 DeepTutor 的知识库里。系统会保存原始文件和元数据,相当于先把教材放进教室。
但上传资料只是开始。真正重要的是:让系统读懂这份资料。
第二步:提取知识点,把一本书变成一棵树
PDF 是一大块连续文本,不适合直接学习。
DeepTutor 会通过 KnowledgeExtractorAgent 从文档中提取知识点,把一整本资料拆成一个个可学习的小单元。
每个知识点会包含:
标题描述难度前置依赖唯一 ID
这一步很像把一本厚书拆成课程目录。原来是一整块内容,现在变成了有层级、有顺序、有依赖关系的知识树。
比如:
智能体的定义与基本要素↓传统智能体的演进类型↓LLM 驱动智能体的新范式↓智能体循环与运行机制
这棵知识树,就是后续学习路径、测验和掌握度追踪的基础。
第三步:生成个性化学习路径
有了知识点,还要解决一个问题:先学什么,后学什么?
如果没有路径,学习又会变回“东看一篇文章,西问一个问题”。
DeepTutor 会根据知识点之间的依赖关系生成学习路径。简单理解就是:先学基础概念,再学进阶内容;先学前置知识,再学复杂应用。
更重要的是,这条路径不是固定不变的。系统会结合你的掌握度来调整顺序。
已经掌握的知识点,可以往后放;还没学过、掌握度低的知识点,会被提前推荐。
它就像一个会动态调整的课程表,不是死板地从第一页学到最后一页。
第四步:用 Tutor / QA / Quiz / Mastery 完成学习闭环
这是 DeepTutor 最核心的地方。
学习不是单向看资料,而是一个循环:
讲解 → 提问 → 测验 → 反馈 → 调整路径在 DeepTutor 里,这个闭环由三个 Agent 和一个 Mastery 面板完成。
Tutor Agent 负责“讲”。
当我选择一个知识点后,它会像老师一样讲解:先讲定义,再解释原理,然后举例子,最后引导我继续思考。
QA Agent 负责“问”。
学习过程中如果我卡住了,可以直接追问。它不是脱离上下文地回答,而是知道我当前正在学哪个知识点,也知道前面讲过什么。
Quiz Agent 负责“考”。
学完一个知识点后,它会根据当前内容生成测验题,比如选择题、判断题、填空题。做完后,系统会根据结果判断我是不是真的理解了。
Mastery 负责“评”。
它像一张学习成绩单,记录每个知识点的掌握情况:
绿色:已掌握黄色:学习中红色:需要复习
而且这个掌握度不是摆设,它会反过来影响学习路径。薄弱的知识点会被优先推荐,已经掌握的内容就不会反复打扰你。
整个流程可以理解成:
上传 PDF↓提取知识点↓生成知识树↓规划学习路径↓Tutor 讲解 → QA 答疑 → Quiz 测验 → Mastery 评估↓根据掌握度调整下一步学习内容
所以,我做的不是简单地“把 PDF 上传到系统里”,而是把 AI 产品经理的学习资料接入 DeepTutor 的学习框架。
DeepTutor 提供多 Agent 协作、会话管理、测验评分和掌握度追踪;AI 产品经理资料提供具体学习内容。两者结合后,它就不再只是一个通用开源项目,而变成了一个围绕 AI 产品经理成长路径运转的学习助手。
如果用一个比喻来说:
PDF 是教材,DeepTutor 是学校,Tutor / QA / Quiz 是老师、助教和考官,Mastery 是成绩单。我要做的,就是把“AI 产品经理”这门课真正排进这所学校里。

06.Claude Code 在这次项目中真正帮了什么
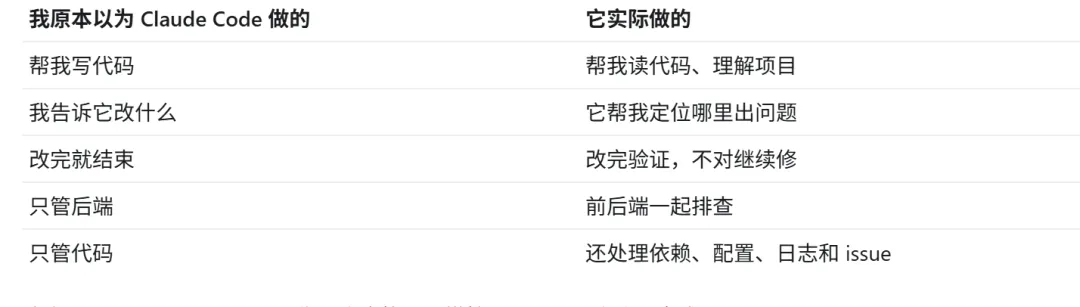
很多人以为 AI 编程助手就是:
我告诉它写什么代码,它帮我生成。
但这次 DeepTutor 项目做下来,我发现写代码反而只是其中一小部分。
Claude Code 真正帮我的,是把一个开源项目从“能启动”推进到“能使用”。
1. 读项目:先帮我找到入口
DeepTutor 是一个 Python + TypeScript 项目,前后端加起来几十个文件。正常接手这样的项目,光读代码和理清结构就要花不少时间。
我的做法不是一开始通读源码,而是先描述现象:
知识学习页面,文档下拉框是空的。Claude Code 会根据这个现象去读相关代码,最后发现问题不止一层:
page.tsx 里 select 是硬编码空列表KnowledgeTree.tsx 里的 API 路径不对main.py 里路由没有注册knowledge_learning.py 里路由前缀重复
一个页面空白,背后其实是前端、接口、后端路由一起出了问题。
这一步最有价值的地方是:我不需要一开始就完全理解整个架构,但必须把现象描述清楚。
2. 定位 bug:跨前后端追到底
这个项目最麻烦的地方,是很多问题都跨前后端。
比如学习路径里显示的是 UUID,而不是中文标题。这个问题看起来像前端展示问题,但真实原因可能藏在很多地方。
Claude Code 的排查路径大概是:
前端显示 UUID↓读 LearningPath.tsx,发现页面用的是 step.knowledge_point_id↓读后端 get_learning_path 返回值,发现没有 title↓读 PathStep 模型,发现模型里没有 title 字段↓读 LearningPathService,发现生成路径时没有填 title↓读 KnowledgePoint 模型,确认知识点本身有 title↓修复:PathStep 增加 title,生成路径时填入 title
这就是它和普通代码补全工具最大的区别:它不是只改眼前一行,而是能沿着数据流往前追。
3. 修代码:改完立刻验证
Claude Code 不是只把代码改完就停下。每次修完,它会继续做验证:
重启后端用 curl 测试 API检查返回值如果不符合预期,继续定位
比如修 send_message 的时候,它先测试 TutorAgent,确认能返回讲解内容。然后再测试 QuizAgent,发现它仍然走的是占位分支,于是继续补上 QuizAgent 的调用逻辑。
这件事很关键。很多 bug 不是“改完代码”就结束,而是要靠验证确认它真的修好了。
4. 处理 DeepSeek 兼容问题
DeepTutor 默认更偏 OpenAI API 的使用方式,但我实际使用的是 DeepSeek。
这里最典型的问题是知识点提取:原代码使用了 response_format={"type": "json_object"},但 DeepSeek 不支持这种 JSON mode,返回结果还会包在 markdown 代码块里。
于是原来的解析逻辑会直接崩。
Claude Code 帮我做了兼容处理:先剥离 markdown 代码块,再解析 JSON,同时补上知识点缺失 ID 的情况。
这类问题如果只看页面现象,很难想到是 LLM 返回格式导致的。
5. 前端不只是改组件,还要处理依赖和配置
比如 Markdown 渲染问题。表面上看,只是 Agent 回复里的标题、加粗、列表没有正常显示。
但真正修起来不只是改一个组件。Claude Code 做了几步:
检查 package.json确认 react-markdown 和 remark-gfm 是否存在检查 tailwind.config.js补上 @tailwindcss/typography修改组件渲染方式
如果只改组件,不处理 Tailwind typography,样式还是不完整。
这种跨组件、依赖、配置的修改,正是实际项目里最容易漏的地方。
6. 整理日志和提交上游 issue
项目跑通后,Claude Code 还帮我做了收尾工作。
第一是整理工作日志。它把修复过程按问题分类,写清楚现象、原因、修复方式和涉及文件,保存成文档。这样后面复盘时,不需要靠记忆还原。
第二是整理上游 issue。它从 20 个修复里挑出 4 个对 DeepTutor 原项目有价值的通用问题,提交到 GitHub 仓库,包括路由未注册、DeepSeek JSON 解析、LearningSession 缺 metadata、KnowledgePoint 校验过严等。
这些工作看起来不像“写代码”,但非常重要。因为没有记录,项目修完很快就会忘记当时为什么这么改。
一句话总结
这次项目里,Claude Code 更像一个全栈工程搭档,而不是一个代码生成器。
我负责说清楚“我想要什么效果”,它负责在项目里寻找实现路径、修改代码、验证结果。这个过程也让我更清楚地意识到:AI 编程的价值,不是把一句需求变成一堆代码,而是把一个复杂项目一步步修到可用。

07.这次实战给我的启发和踩坑总结
一、开源项目能跑,不等于能用
DeepTutor 在 GitHub 上有完整代码、文档和 Docker 配置。按照 README 走一遍,项目确实可以启动。
但真正点进“知识学习”功能后,问题才开始暴露:文档下拉框空白,知识点加载失败,学习会话没反应,掌握度和学习路径页面显示一串 UUID。
这不完全是 DeepTutor 的问题,而是很多开源项目都会遇到的现实:主路径可能能跑,但边缘功能、不同模型、不同环境下的适配未必完整。
比如这次遇到的路由未注册、接口占位符、模型字段和实际数据对不上,在开发者自己的环境里可能不是阻碍,但对新用户来说就是断点。
所以用开源项目,不要只看 README 里的“快速开始”。真正要把一个功能跑通,往往需要:
读代码,而不只是读文档准备改代码,而不只是当用户把“能启动”到“能使用”之间的距离当作正常现象
二、AI 编程不是“一句话生成项目”
网上很多 AI 编程 demo 看起来很爽:输入一句话,AI 生成一个完整项目。
但这次真实流程完全不是这样。
实际过程更像是:
发现问题↓告诉 Claude Code↓定位原因↓修改代码↓重启测试↓通过就继续↓失败就继续排查
这个循环重复了 20 次。
没有一步到位。每修一个问题,背后可能又冒出两三个关联问题。修路由时发现 UUID 不对,修 UUID 时发现模型字段缺失,修模型时又发现前端没传参数。
所以 AI 编程的正确姿势,不是:
帮我写一个完整系统先让项目跑起来一个功能一个功能调通每次只解决一个问题改完立刻验证
AI 是加速器,不是替代品。它能帮你节省读代码、找文件、查调用链的时间,但不能替你跳过理解和判断。
三、最大的坑不是技术,而是不知道哪里断了
这次 20 个 bug 里,很多技术点并不难。
UUID 转换、JSON 解析、路由注册、前端端口、Markdown 渲染,这些单独拿出来都不复杂。
真正难的是:你不知道问题断在哪一层。
页面空白,可能是前端没有请求数据,也可能是请求发错端口,也可能是后端路由没注册,也可能是接口返回格式不对。
一个症状后面,可能藏着三层原因。
所以排查问题最重要的能力,不只是“会写代码”,而是能不断缩小范围。Claude Code 在这次项目里最有价值的地方,就是它能快速读相关文件,沿着调用链追下去,告诉我问题大概断在哪几个位置。
四、20 个 bug 的分布规律
回头看这 20 个问题,大致可以分成几类:
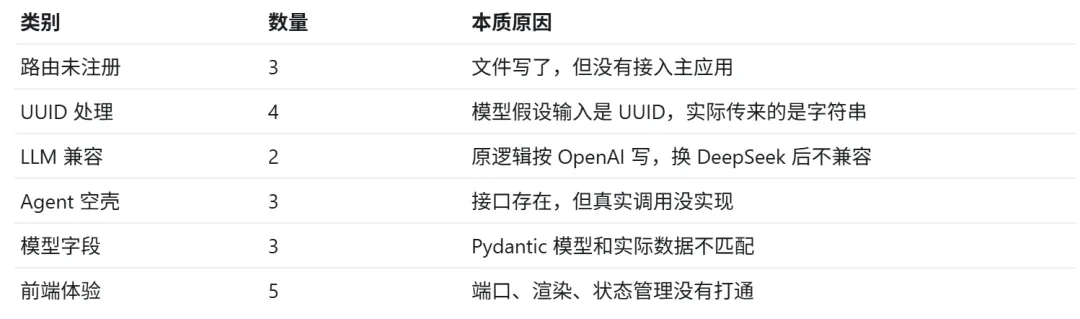
真正难在算法或工程设计上的 bug 并不多,更多是接线、兼容、字段和状态问题。
这也说明一个事实:很多开源项目的代码看起来完整,但真正换一个环境、换一个模型、换一种使用方式,就会暴露出没打通的地方。
所以我的心态也变了:我拿到的不是一个“直接可用的成品”,而是一个“已经搭好骨架的半成品”。我要做的是把它接上我的场景,补齐断点,让它真的为我所用。
五、Claude Code 改变了我的工作方式
以前接手这样的项目,我的流程通常是:
读文档 → 读代码 → 理解架构 → 找问题 → 改代码 → 测试 → 排错其中最耗时间的,往往是读代码和理解架构。
这次流程变成了:
描述现象 → Claude Code 定位 → 我确认方案 → 它修改代码 → 它测试 → 继续下一个问题我不再需要先把整个项目源码通读一遍,也很少需要手动在几十个文件之间来回跳转。
我的主要工作变成了三件事:
描述我想要什么效果判断修复方案是否合理在浏览器里验证最终结果
六、给想做类似项目的人
如果你也想用 Claude Code 改造一个开源项目,我的建议是:
第一,选一个真实需求。不要为了用 AI 而用 AI。
比如我这次选的是“AI 产品经理自学”,因为这个方向我确实需要长期学习。
第二,不要从零开始。找一个 80% 符合需求的开源项目,再用 AI 帮你改造。
DeepTutor 已经有多 Agent、会话管理、测验评分和掌握度追踪,我要做的是接入内容、修通链路、补齐体验。
第三,准备好改代码。开源项目不是下载即用的软件。
它提供骨架,Claude Code 帮你做手术,但最终要改成什么样,还是由你的需求决定。
第四,重视验证。每修一个问题,都要重新启动、测试接口、检查页面。
不要相信“代码看起来对了”,要相信运行结果。
END
最后一句话我想这样总结:
能跑和能用之间的距离,就是你和这个项目之间的距离。AI 可以帮你缩短这段距离,但走完这段路的还是你自己。
