 夜雨聆风
夜雨聆风就在昨天,微博热搜榜上突然出现了一个新名词——“微信读书 Skill”。
一旦用户把自己的微信读书账号与这项功能对接,AI 就能瞬间获取到该用户的全部阅读档案。它不仅能帮你查书、扫一遍书架上的库存,还能像私人助理一样,统计出你平时的阅读偏好,整理你留下的笔记,甚至顺带给你推荐几本可能感兴趣的书。
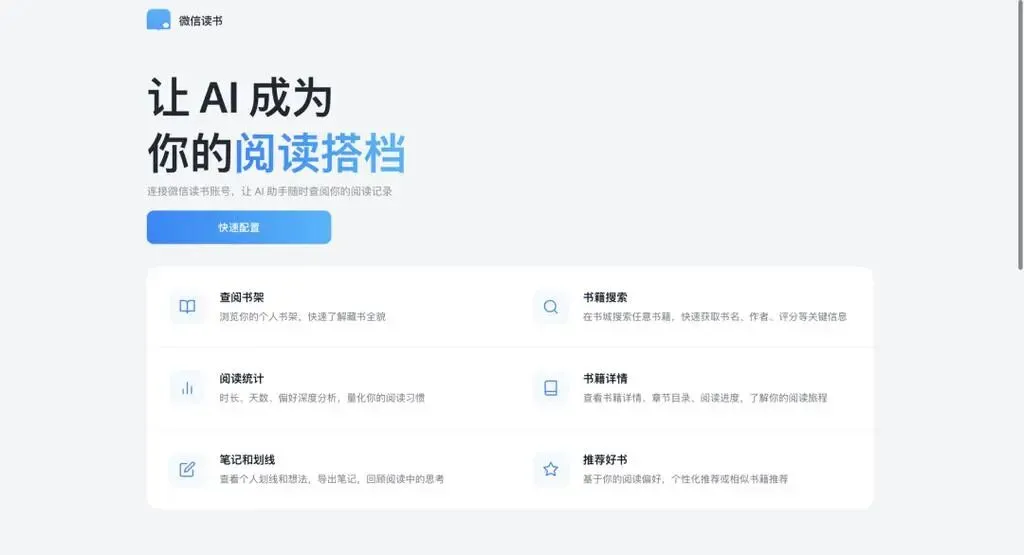
从功能划分的角度来看,微信读书 Skill 能够被细分成六个不同的类别:
第一类是书架查阅功能,它让使用者能够浏览自己的个人书架,从而快速掌握所藏书籍的总体情况。
第二类是书籍搜索模块,允许用户在书城当中检索特定书目,并获取书名、作者、评分这类核心信息。
第三类涉及阅读统计功能,通过分析阅读时长、天数以及偏好深度,将阅读行为进行量化评估。
第四类是书籍详情展示,包括查看书籍的详细信息、章节目录以及当前阅读进度。
第五类聚焦于笔记和划线功能,用户能够查看已经划下的重点内容,导出笔记,并回顾自己在阅读过程中的思考。
第六类则是推荐好书机制,系统会根据个人的阅读偏好给出个性化推荐,或者推荐与已读书籍类似的作品。
安装这一过程可以分解为两个关键步骤:首先,要把 Skill 部署到 AI 助手当中;接着,再通过 API Key 来绑定个人的微信读书账号。
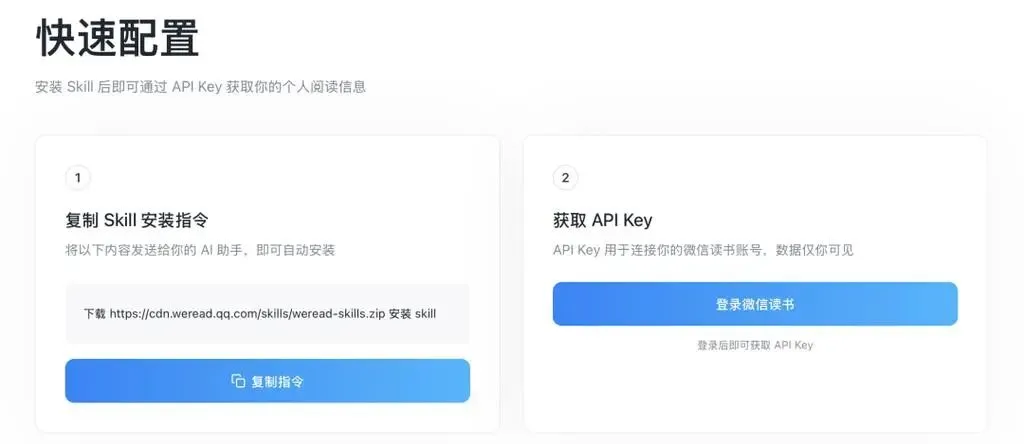
打开微信读书的“Skill”功能页面(网址是:https://weread.qq.com/r/weread-skills)。
这个页面里,能看到关于Skill的详细介绍,还附带了安装所需的文件。
接下来,需要启动Codex、Claude Code,或者WorkBuddy这些工具。
考虑到网络条件在国内不太稳定,这里推荐用腾讯自家的AI助手——WorkBuddy。
在WorkBuddy里创建一个全新的对话窗口,然后把下面这条完整的指令粘贴进去:
“下载 https://cdn.weread.qq.com/skills/weread-skills.zip 安装 skill”。
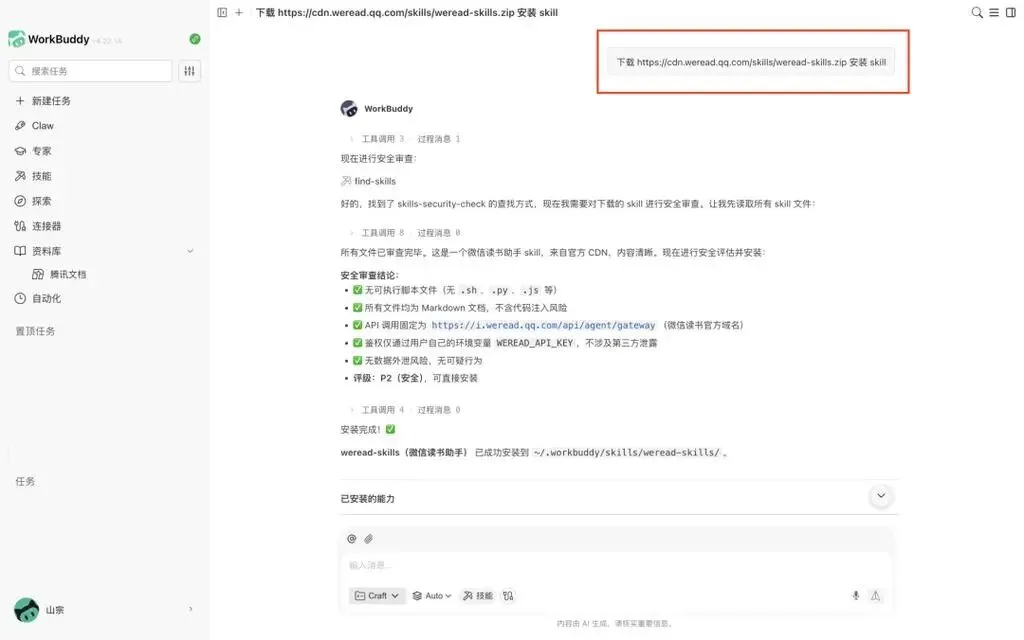
WorkBuddy需要从微信读书给出的链接中,拉取一个Skill格式的压缩包,然后自行安装,这正是这条指令所驱动的流程。发出指令后,系统就会进入执行阶段,通常情况下,只需等待几分钟,WorkBuddy就会弹出提示,告知部署已经结束。
然而,即便部署完成,也并不意味着可以立刻上手使用。原因在于,AI为了能够顺利读取用户个人账号里的书架内容、阅读进度以及笔记信息,必须借助API Key来完成授权环节。
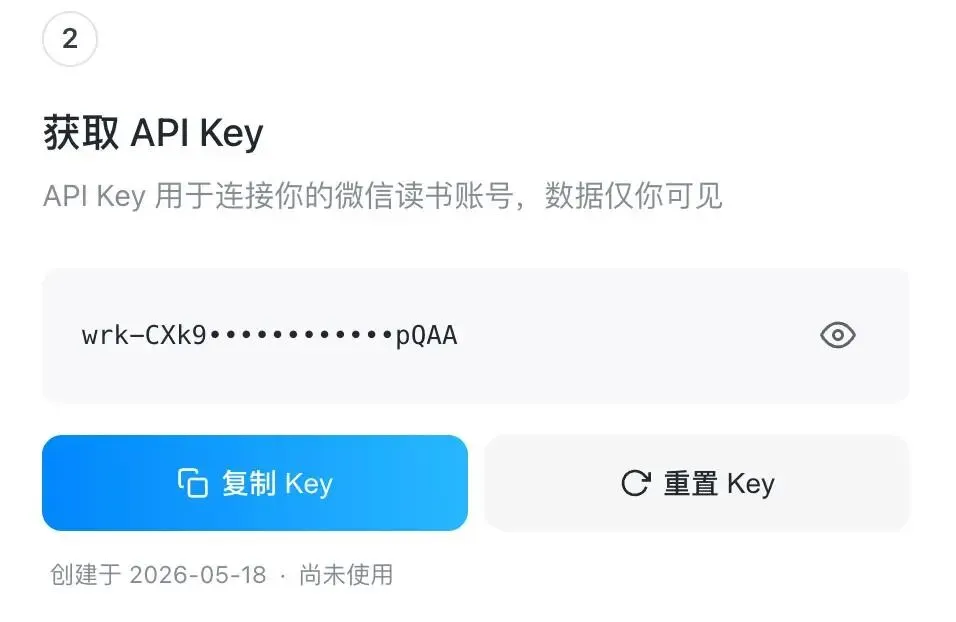
通过微信读书获取API Key,必须使用扫码登录这一方式。当用户根据系统或WorkBuddy的相关指引完成扫码验证之后,系统便会自动生成一串专属的API Key。
这串字符本质上是一种授权凭证,用于绑定并连接你的微信读书账户。为了确保账户安全,建议绝对不要将其随意公开,同时也应避免在缺乏信任的环境中进行分享。
获得API Key后,存在两种配置途径:一是将其直接提交给WorkBuddy进行设置,二是借助环境变量完成。为此,需运行如下指令:
export WEREAD_API_KEY=复制你得到的API Key
特别要注意的是,指令中的“复制你得到的API Key”部分,必须替换成通过扫码登录流程所生成的真实API Key。当配置工作顺利结束后,WorkBuddy便会解析授权信息,进而与用户的微信读书账号建立连接。
在完成安装与授权环节后,可选一个基础问题来检验其功能是否正常。譬如,向它提问:“请展示我的微信读书书架”或“今年我在微信读书完成了哪些阅读活动?”倘若WorkBuddy能够准确给出书架详情、阅读历史记录或相应的统计数据,那就表明微信读书Skill已经成功启用。
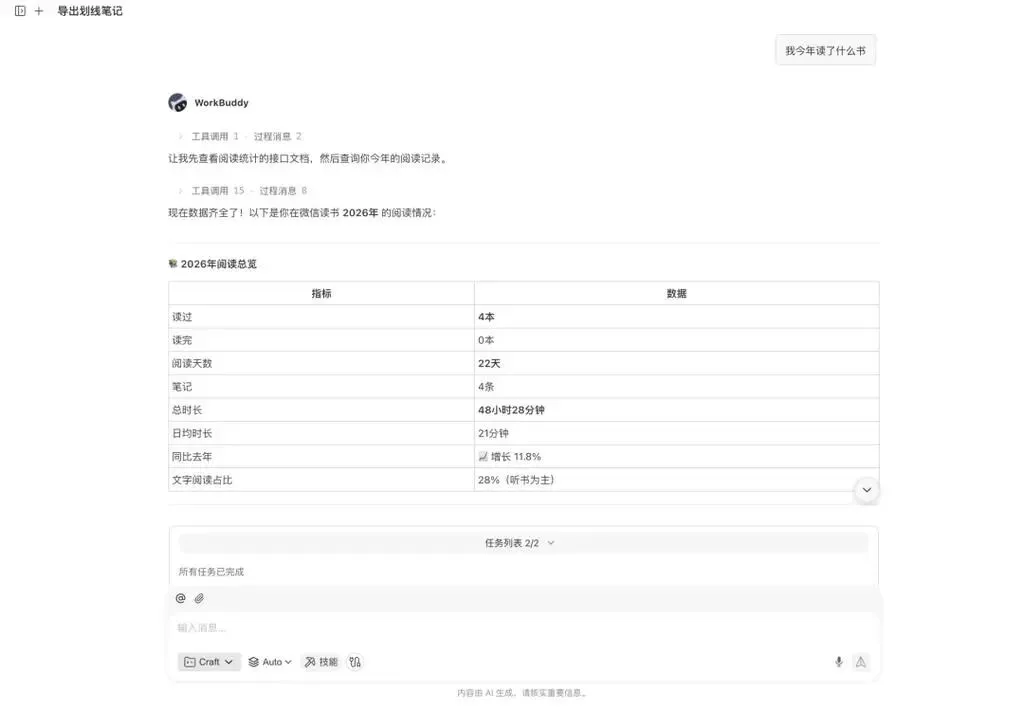
授权步骤与安装流程结束之后,我们归纳出了几种新颖的使用思路,专为微信读书技能量身定制。
---
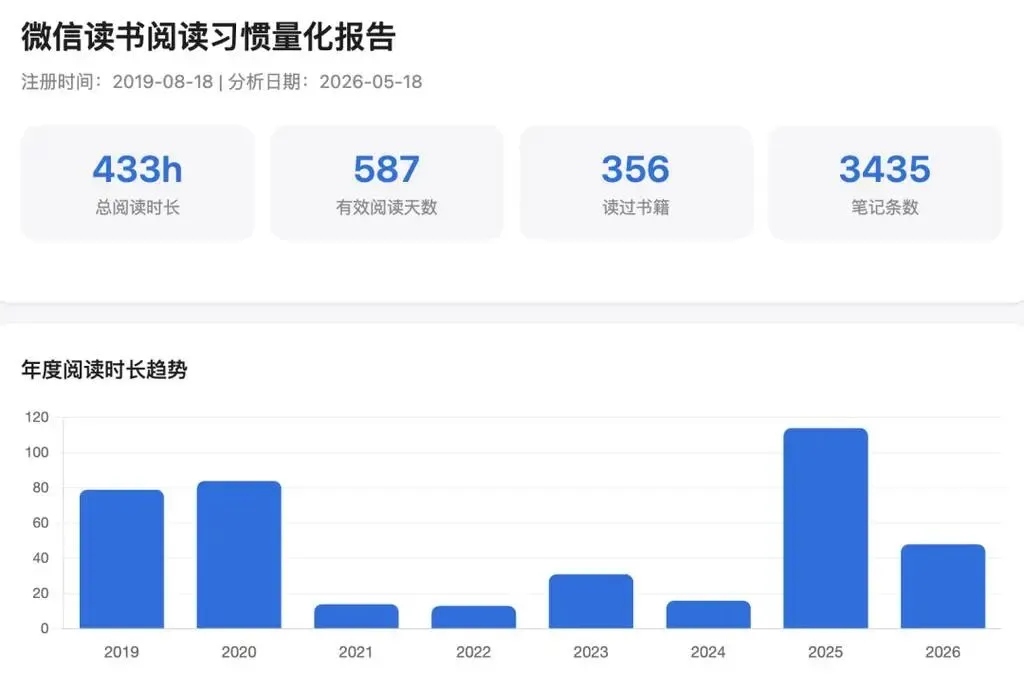
一种玩法聚焦在阅读行为的日常量化上。
以往,想回顾年度书单或分析自己何时读书最频繁,人们只能手动翻查历史记录、拼凑零散数据。
现在,借助这项技能,这类繁琐工作能直接由人工智能代劳。
它能清晰呈现你的阅读节奏,帮你一眼看清自己的学习习惯。
你可以这样使用提示词:
过去一年我翻阅过哪些书?希望你能按月份、书籍类别以及读到什么程度,帮我做成一个清晰的表格。 把我的微信读书使用习惯转化成具体数据,比如总共花了多少时间、坚持了多少天、最喜欢读哪种书、是不是连续不断地阅读。 我通常在一天里的哪个时间段看书?请按照早晨、上午、下午、晚上和深夜这几个时段分别统计。 哪一本书是我读得最久的?告诉我那本书的名字、读了几天、读到了什么位置。 根据我的阅读数据,对比一下最近三个月和全年来看,我的阅读习惯到底发生了什么变化。
第二类:个性化推荐
尽管微信读书本身就搭载了推荐机制,但 Skill 系统与之截然不同——它能够深度结合用户个人的书架数据与阅读历史,生成针对性更强的建议。它的运作方式并非简单推送热门榜单,而是具体分析你读过的书籍类型、你的阅读倾向、以及你近期重点关注的内容,最终整理出一份能精准贴合个人口味的书单。
你可以像这样向系统提问:
基于我过去的阅读习惯,请推荐 10 本可能感兴趣的散文作品,并逐一说明每本书值得推荐的原因。
我想了解《人间滋味》这本书,请帮我查一下它的作者、评分、所属分类、出版社、出版时间以及ISBN号码。
目前我对人工智能相关话题兴趣浓厚,不妨扫一眼我的书架,看看有哪些书能帮助我快速构建起关于AI的背景知识。
根据我的阅读历史,推荐 5 本与近期读过的作品在风格或主题上比较相似的书籍。

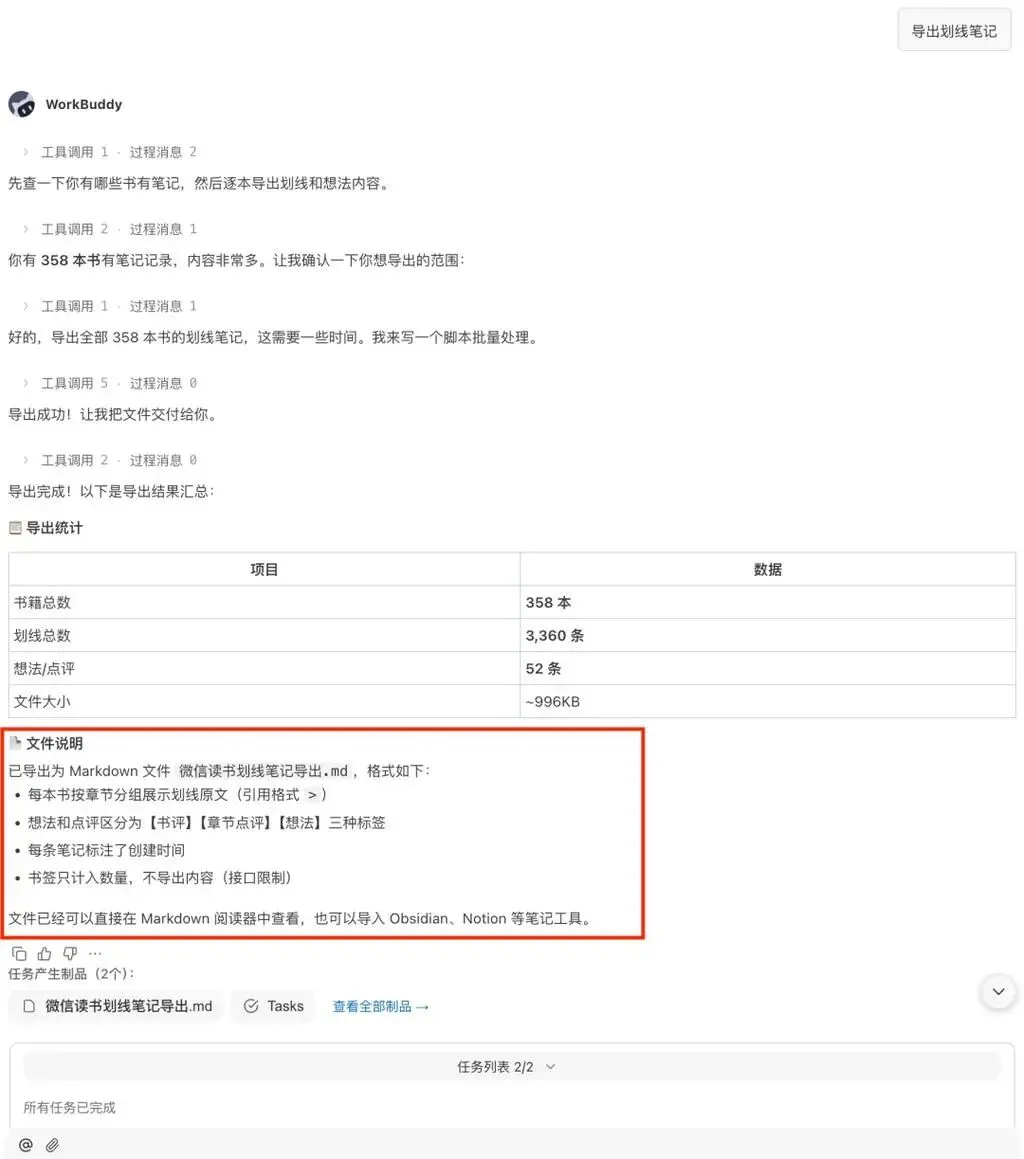
第三类应用:梳理阅读记录与挖掘知识盲区
对那些喜欢在微信读书里反复划线、写下批注的读者而言,真正让人头疼的并非没有留下痕迹,而是这些痕迹散落在不同的书籍里,几乎从未被系统性地整合过。Skill 的独特之处,就在于它能把这些零散的阅读印记重新串联起来。你可以试试这样问它:
把最近读完的三本书中所有划线笔记导出来,并按书名逐一整理。
将《某本书》的全部划线内容导出,再按主题进行归类,最终提炼出10条最核心的观点。
分析一下,我阅读时更偏好收集事实、记录观点、品味故事、学习方法论,还是捕捉情绪表达?
根据我的划线内容,判断我主要关注的是问题剖析、经验总结、人物叙事,还是价值判断?
把《某本书》的划线全部导出,然后基于这些内容为我生成5道测试题,看看我究竟理解了多少。
此外,还有一种更进阶的使用场景:发现认知盲区
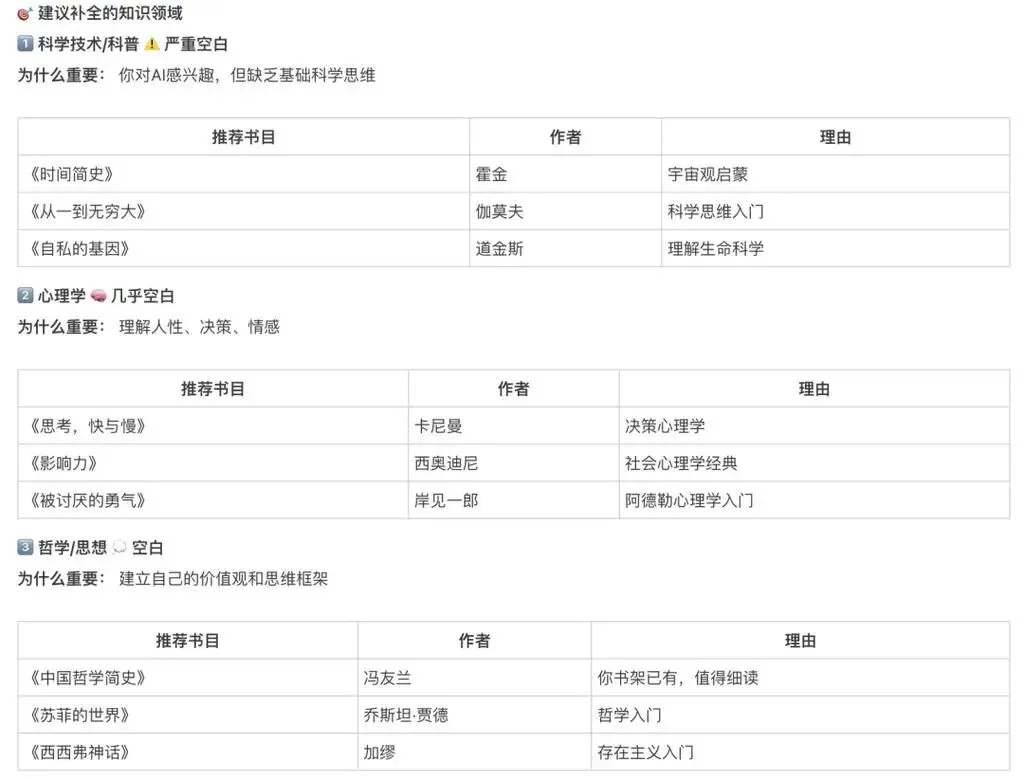
长期沉浸在同类型内容中,人很容易被困在信息茧房里。因此,不要让AI只推荐那些你原本就熟悉的东西。相反,应该让它基于你的阅读记录,找出你接触较少的领域,然后推荐那些能够填补知识空白的书籍。
比如说,长期钻研商业书籍的人,可能缺乏历史维度的思考;技术书读得太多的人,往往对社会学和伦理议题关注不够;而常年沉浸在文学世界里的人,也可能对经济、科技和组织管理方面的知识了解有限。别只让AI告诉你“你读过什么”,反过来,让它分析“你还没读什么”,这或许更有价值。
你可以尝试这样提问:
根据我读过的内容,判断我在哪些领域存在明显的知识盲区。
基于我的阅读记录,推荐一些能帮我拓宽认知、避免知识结构局限的书籍。
分析我书架上的藏书,指出哪些领域我读得较多,哪些几乎没涉及。
结合我的阅读历史,整理一份认知提升书单,按文学、历史、科技、商业、社会学和哲学分类。
参考我近期的对话内容,找出我最需要改进的地方,然后从微信读书书架里定位到具体的书籍和章节。
最后一个提示词,其实更接近一种定向检索的玩法。与其笼统推荐一本书,不如把你当下的困惑、已有的书架和具体章节直接关联起来。
简而言之,微信读书 Skill 最有价值的地方,不是帮你查了几本书或导出几条笔记,而是把你多年积累的阅读痕迹——书架、进度、划线、想法——这些原本沉睡在 App 里的行为数据,都激活成了 AI 可读取的知识索引。
过去这些信息只是静静躺在那里,现在它们全被调动起来了。你不再只是用一个阅读 App,更像是在喂养一个不断理解你的个人知识库 Agent。
以往那些阅读类工具,核心功能仅仅是告诉你“去哪读”,而推荐算法则聚焦于“接下来该读哪本”。不过,随着大模型技术的渗透,Skill 这个产品已经开始探索第三个更关键的问题:我们所读过的内容,怎样才能真正融入并影响我们此刻的思考、写作和决策?
尤其值得关注的是,在长达数千年的历史里,阅读一直是个人的单向行为。人们埋头于书本,究竟能记住多少、运用多少,完全依赖于自身的记忆力与领悟力,过程单调而孤立。
然而,人工智能的介入,彻底打破了这种模式。它让阅读变成了名副其实的双向互动——读者与内容之间,不再是简单的“看”与“被看”,而是有了更深层的对话与反馈。这无疑是令人振奋的进步。
