AI 记忆功能,正在从“高级玩法”变成基础配置。2026年5月,OpenAI 把 ChatGPT 文件库扩展到 Free 和 Go 用户,Free 有 500MB,Go 有 4GB,Plus 和 Business 有 20GB,Pro 有 100GB。文件会留在 Library 里,直到手动删除;临时聊天里的文件则不会保存到 Library。这个变化很关键,AI 开始从聊天工具,变成一个会保存材料、调用历史、延续上下文的工作台。过去每次打开 AI,都要重复交代账号定位、写作风格、读者是谁、禁用哪些表达、文章要多长、要不要小标题。重复 10次,时间就被吃掉了。记忆功能的出现,解决的正是这个问题。让 AI 记住长期稳定的信息,下一次对话就少铺垫一大截。做公众号、写论文、做方案、剪视频、整理资料,都会明显提速。但麻烦也在这里。能记住,代表能沉淀。能沉淀,代表边界开始变得重要。AI 记忆真正危险的地方,通常不在“单次泄露一个词”,而在长期拼图。一次写作偏好、一次项目背景、一次客户资料、一次私人聊天,单看都没那么吓人,连起来就可能变成一份很完整的个人画像。2025年,斯坦福 AI Index 统计显示,全球组织使用 AI 的比例已经从 2023年的 55% 上升到 2024年的 78%。麦肯锡 2025年调研也显示,接近 90% 的受访组织已经在至少一个业务功能中经常使用 AI,62% 已经在试验 AI Agent。AI 已经进入日常工作流,记忆能力自然会跟着进入工作流。所以,AI 记忆的问题已经不是“开不开”。更现实的问题是,哪些信息值得长期保存,哪些信息只能临时使用,哪些信息连输入都要慎重。
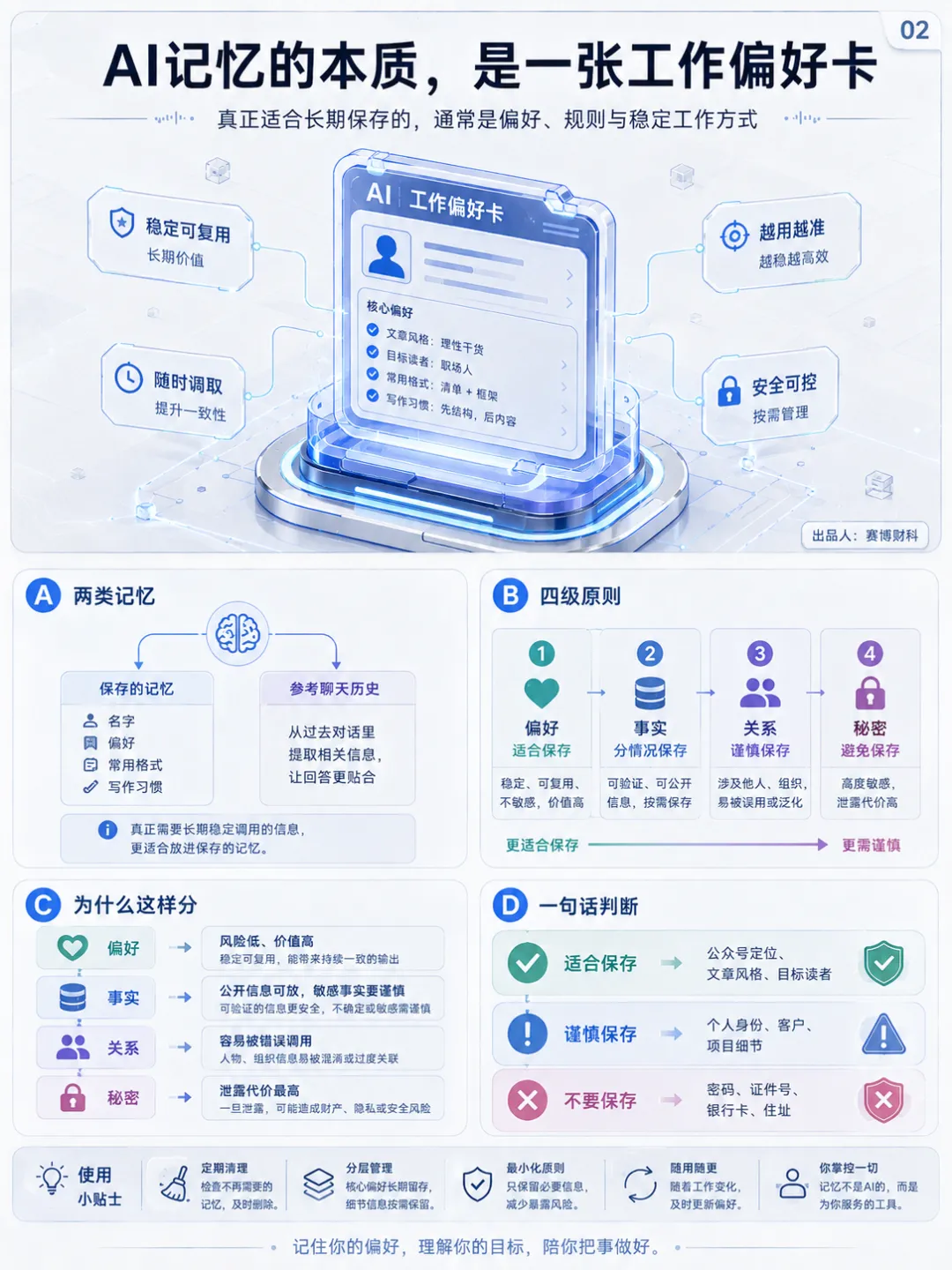
1、AI记忆的本质,是一张工作偏好卡
ChatGPT 的记忆主要分成两类。一类是“保存的记忆”。比如名字、偏好、常用格式、写作习惯。OpenAI 官方说明里提到,保存的记忆会像自定义指令一样进入后续回答,除非手动删除。另一类是“参考聊天历史”。开启后,AI 可以参考过去对话里的信息,让后续回答更贴合已有偏好。官方也说明,它不会记住每个细节,所以真正需要长期稳定调用的信息,更适合放进保存的记忆。这就决定了一个基本原则。AI 记忆适合保存“偏好”,谨慎保存“事实”,少保存“关系”,避免保存“秘密”。偏好泄露的风险低,价值高。比如公众号定位、文章风格、常用结构、目标读者、标题偏好、排版规则、禁用表达。这些信息放进记忆,AI 的输出会更稳定。事实要分情况。公开事实可以保存,比如“账号长期写 AI 工具科普”“文章面向普通职场人”“每篇文章控制在 1500字左右”。涉及个人身份、客户、公司项目、合同、财务、账号系统的事实,就要谨慎。关系信息更敏感。私人聊天、家庭关系、客户关系、合作分成、内部矛盾,一旦被长期记住,下一次对话可能被错误调用。工作效率提升一点,隐私风险放大一截。秘密信息直接排除。密码、密钥、身份证号、银行卡、家庭住址、未公开商业计划、客户名单、合同原件、公司内部文档,全部不适合进入长期记忆。
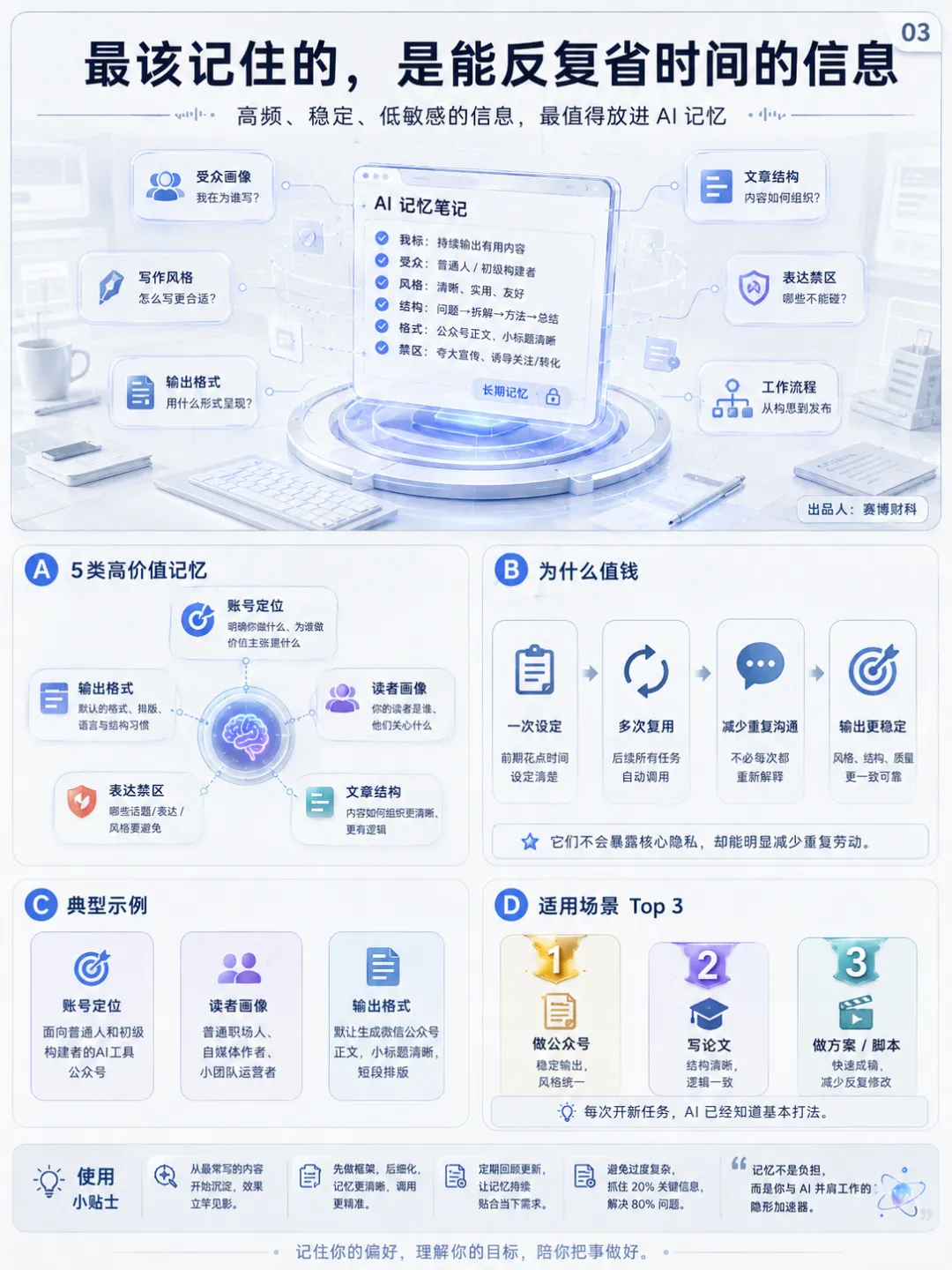
2、最该记住的,是能反复省时间的信息
做内容的人,最适合让 AI 记住 5类东西。比如我这个账号,就可以这样设置。账号定位:这是一个面向普通人和初级构建者的 AI 技术公众号。文章要通俗、克制、有操作感,从具体场景切入,每篇讲清楚一个工具或概念解决什么问题,并给出使用方法。读者画像:读者主要是普通职场人、自媒体作者、小团队运营者、AI 入门用户。知识基础有限,但愿意学习实用工具。文章要避免堆术语,重点放在场景、方法、风险和判断。文章结构:标题要有信息差;开头用具体场景切入;中段讲清楚原理、用法和误区;结尾给出行动清单;每段控制在 3到5句;少用空泛趋势判断。表达禁区:避免营销腔,避免“颠覆”“革命”“赋能”等空词;避免过度承诺;避免把 AI 写成万能工具;涉及数据必须核查来源。输出格式:默认生成微信公众号正文;小标题清晰;重点句加粗;少用表格;多用短段;数据尽量用 2025年、2026年资料。这些记忆非常值钱。它们不会暴露核心隐私,却能减少大量重复沟通。每次开新文章,AI 已经知道基本打法,输出会更接近稳定合作的编辑。
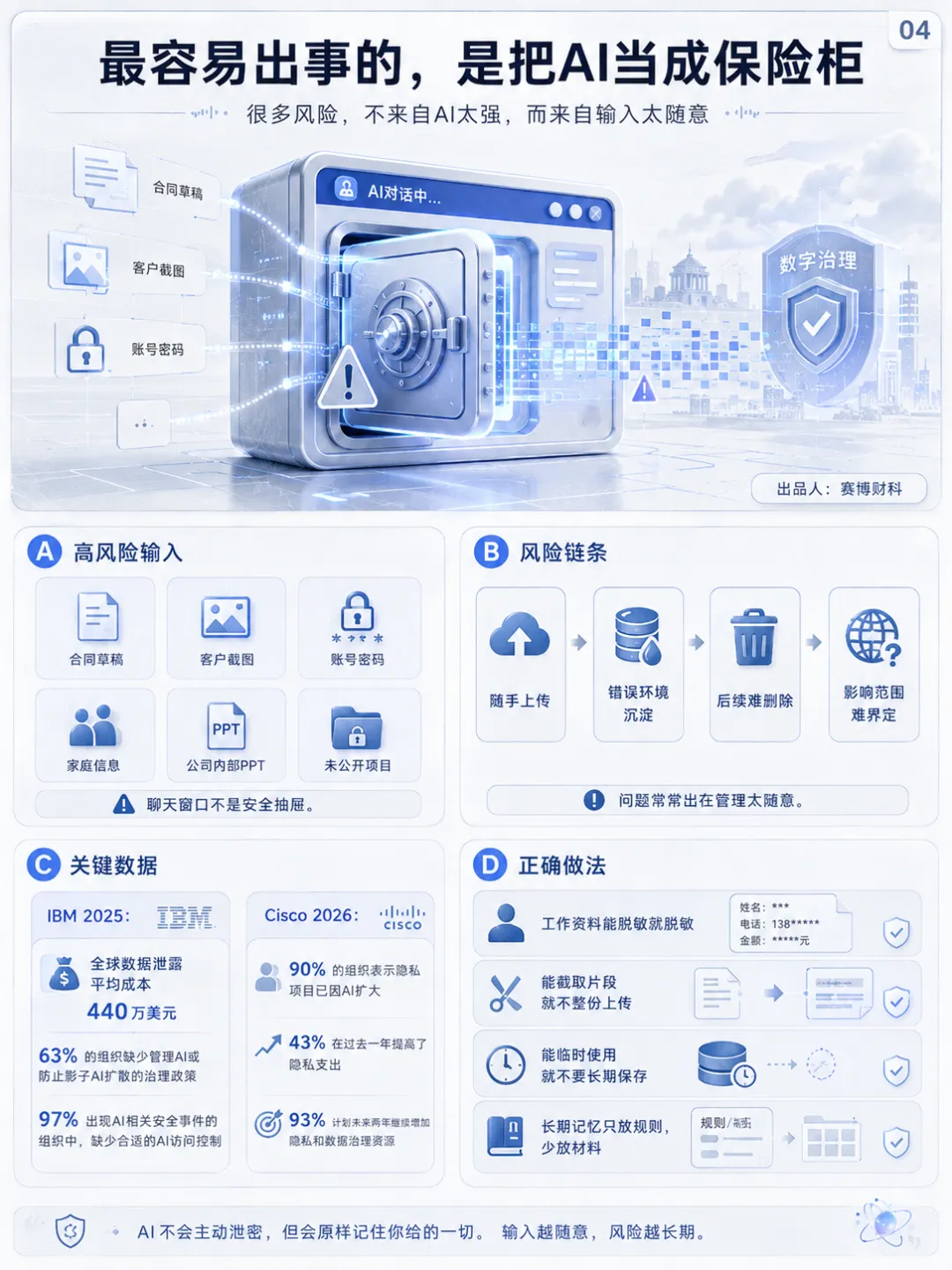
3、最容易出事的,是把AI当成保险柜
很多人使用 AI 的问题,来自一个错觉。觉得聊天窗口是安全抽屉,什么都能塞进去。合同草稿、客户截图、账号密码、家庭信息、公司内部 PPT,全往里丢。这类用法风险很高。IBM 2025年《数据泄露成本报告》显示,全球数据泄露平均成本为 440万美元。报告还提到,63% 的组织缺少管理 AI 或防止影子 AI 扩散的治理政策;出现 AI 相关安全事件的组织中,97% 缺少合适的 AI 访问控制。AI 风险常常不来自技术多先进,而来自管理太随意。员工觉得只是“让 AI 帮忙总结一下”。公司觉得只是“提高效率”。材料一旦进入错误环境,后面追责、删除、证明影响范围,都会变得麻烦。Cisco 2026年数据与隐私基准研究也显示,90% 的组织表示隐私项目已经因 AI 扩大,43% 过去一年提高了隐私支出,93% 计划未来两年继续增加隐私和数据治理资源。企业已经在为 AI 时代补隐私治理的课。个人使用 AI,也需要同一套思路。工作资料可以给 AI 看,但要控制范围。敏感资料能脱敏就脱敏,能截取片段就截取片段,能临时使用就临时使用。长期记忆只放“规则”,少放“材料”。
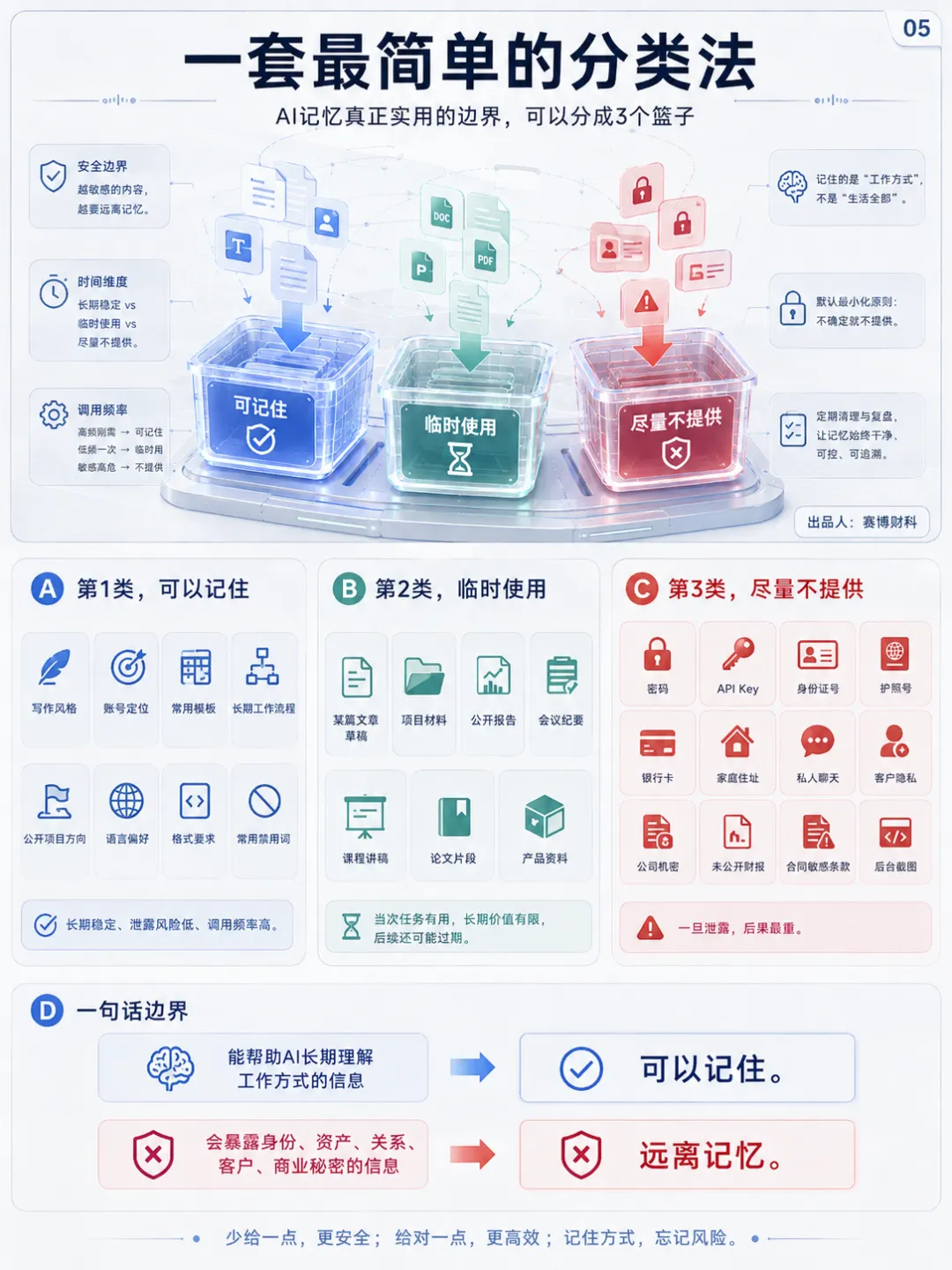
4、一套最简单的分类法
AI 记忆可以分成 3个篮子。第1类,可以记住。写作风格、账号定位、常用模板、长期工作流程、公开项目方向、语言偏好、格式要求、常用禁用词。这类信息长期稳定,泄露风险低,调用频率高。第2类,可以临时使用,少放长期记忆。某篇文章草稿、某次项目材料、公开报告、会议纪要、课程讲稿、论文片段、产品资料。这类信息对当次任务有用,但长期价值有限,后续还可能过期。第3类,尽量不提供。密码、API Key、身份证号、护照号、银行卡、家庭住址、私人聊天记录、客户隐私、公司机密、未公开财报、合同敏感条款、内部组织架构、账号后台截图。真正实用的边界就这一句:能帮助 AI 长期理解工作方式的信息,可以记住。会暴露身份、资产、关系、客户、商业秘密的信息,远离记忆。
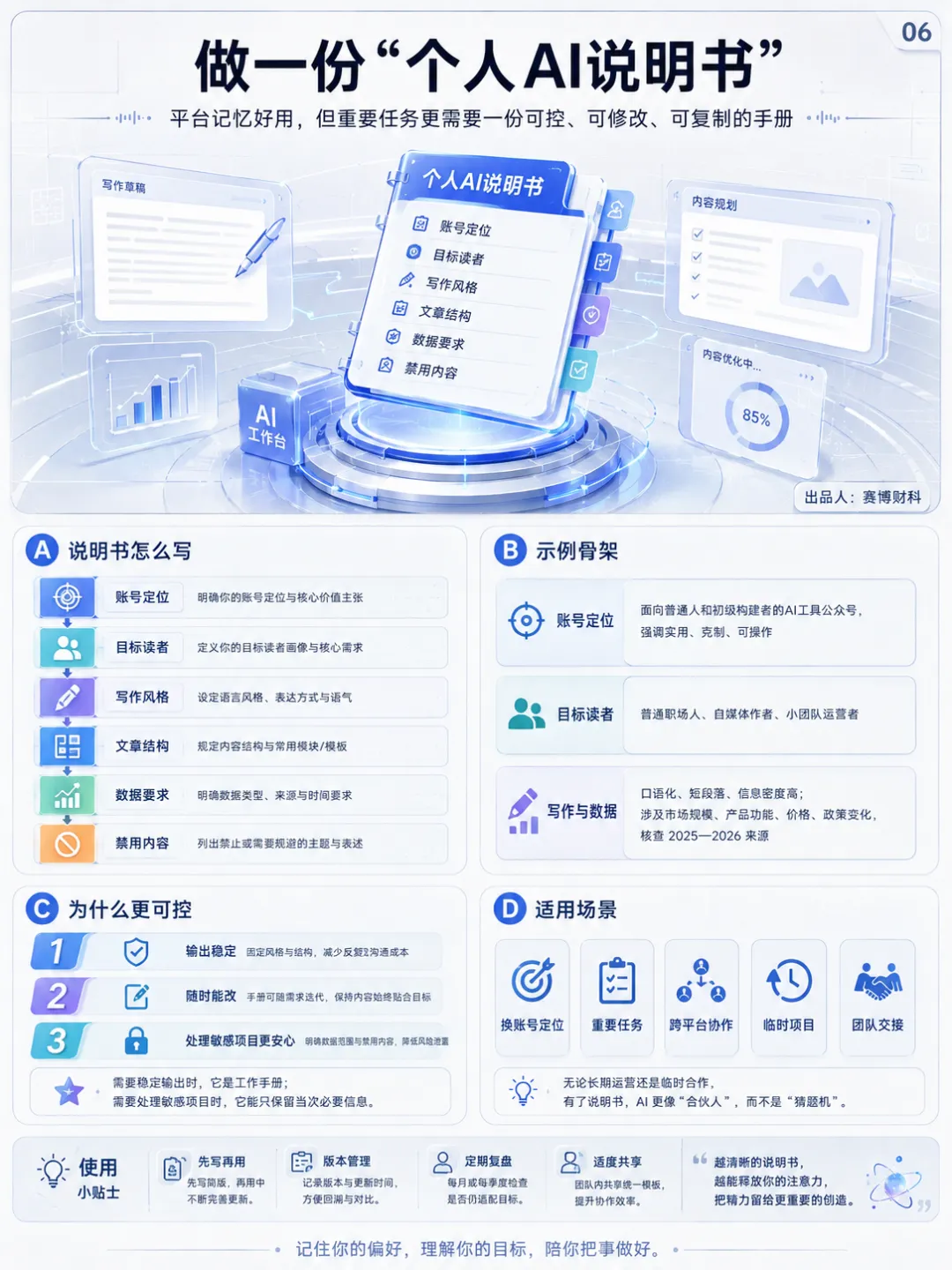
5、做一份“个人AI说明书”
平台记忆好用,但不能完全依赖。更稳妥的做法,是准备一份“个人 AI 说明书”。每次遇到重要任务,直接贴进去。这样既能保持输出稳定,也能随时修改,不会把所有信息长期交给系统记住。说明书可以这样写:账号定位:面向普通人和初级构建者的 AI 工具公众号,强调实用、克制、可操作。目标读者:普通职场人、自媒体作者、小团队运营者,对 AI 感兴趣,但不熟悉技术细节。写作风格:口语化、信息密度高、短段落、有画面感,避免空泛趋势判断。文章结构:用具体场景开头,中间讲清楚工具原理、适用场景、操作方法、常见误区,结尾给出行动建议。数据要求:涉及市场规模、产品功能、政策变化、价格、模型能力,必须核查 2025年或 2026年来源。禁用内容:不保存身份证、银行卡、密码、客户资料、公司机密、私人聊天、未公开项目。这份说明书比盲目开记忆更可控。需要稳定输出时,它就是工作手册。需要换账号定位时,直接改。需要处理敏感项目时,删掉无关背景,只保留当次任务需要的信息。
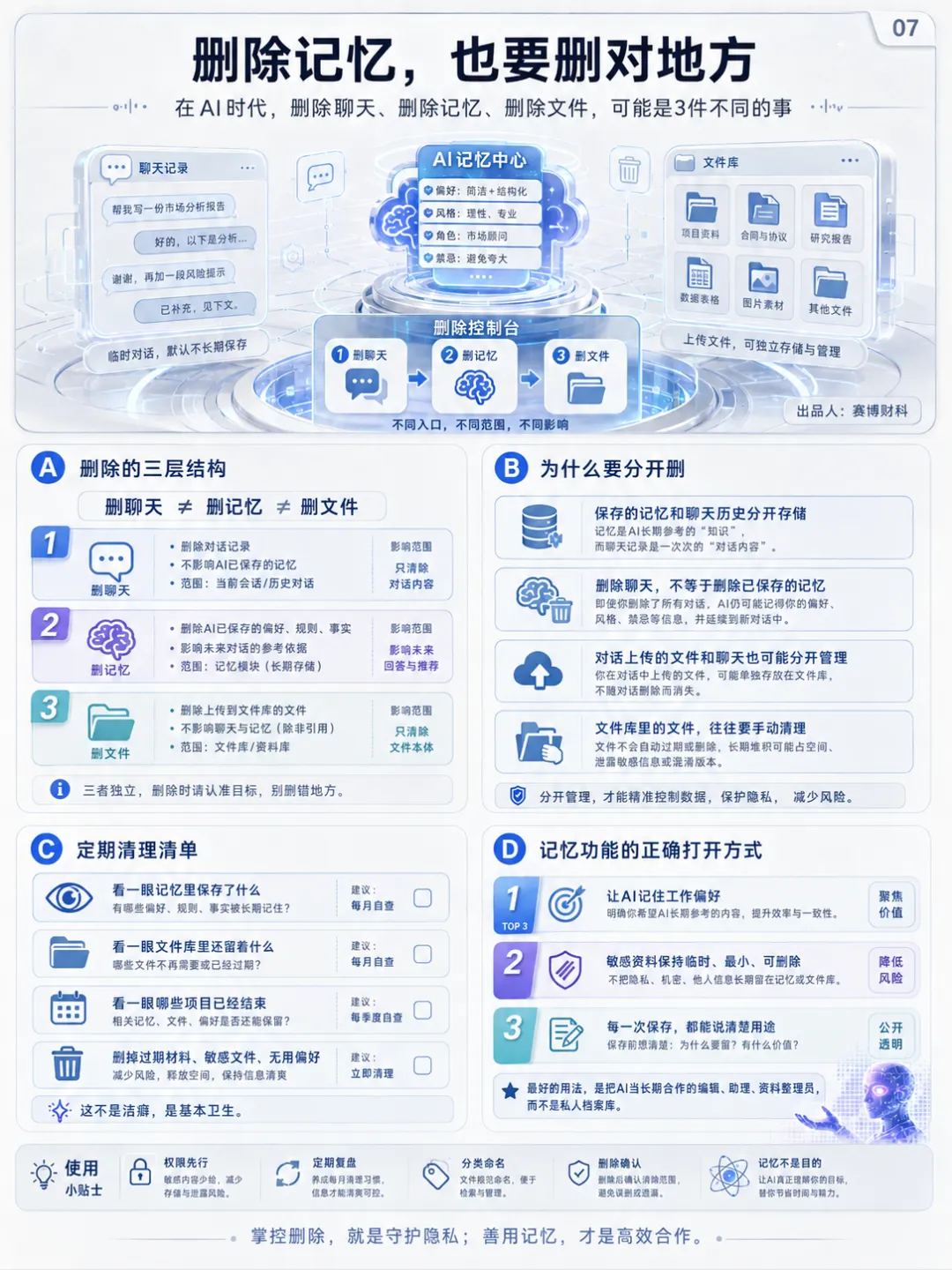
6、删除记忆,也要删对地方
很多人以为删掉聊天记录,记忆就没了。OpenAI 官方说明里写得很清楚:保存的记忆和聊天历史分开存储,删除聊天并不会删除已经保存的记忆。要彻底移除,需要在记忆管理里删除对应记忆;如果要更完整地删除,还要删除最初分享该信息的聊天。文件也是类似逻辑。OpenAI 的文件保留说明提到,对话中上传的文件会存储在 Library 里,聊天和文件分开管理。删除聊天,不等于删除 Library 里的文件。这点很重要。AI 时代的“删除”,开始变成多层动作。删聊天、删记忆、删文件,可能是三件事。长期使用 AI 的人,应该定期做一次清理。看一眼记忆里保存了什么。看一眼文件库里还留着什么。看一眼哪些项目已经结束。把过期材料、敏感文件、无用偏好删掉。这不是洁癖,是基本卫生。
7、记忆功能的正确打开方式
AI 记忆真正该服务的,是重复劳动。比如每次写公众号,都要反复交代风格。每次改论文,都要反复说明研究主题。每次做招聘邮件,都要反复说明岗位背景。每次写脚本,都要反复说明受众和格式。这些内容适合让 AI 记住。真正不适合交给记忆的,是承担后果的信息。钱、证件、密码、客户、合同、公司内部资料、私人关系、未公开项目。任何一类泄露后会带来麻烦,都不适合长期保存。AI 越好用,越容易让人放松警惕。方便会让边界变软。边界一软,隐私和工作风险就会跟着进来。最好的用法,是把 AI 当作长期合作的编辑、助理、资料整理员,而不是一个什么都能装的私人档案库。让 AI 记住工作偏好。让敏感资料保持临时、最小、可删除。让每一次保存,都能说清楚用途。这才是 AI 记忆真正成熟的用法。-END-
如果大家喜欢我的内容,请多多关注!!
商务合作:kim_v520
基本文件流程错误SQL调试
请求信息 : 2026-05-22 14:33:34 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/651132.html
 夜雨聆风
夜雨聆风