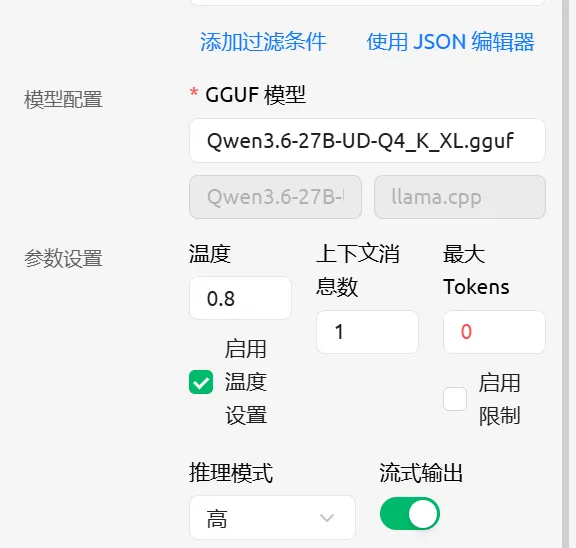
阮咸AI助手,新增Qwen3.6: 27b本地模型 阮咸AI助手v1.0.5版本将会新增Qwen3.6: 27b本地模型(Q4量化),主要应用在诸如混合数据分析、资金分析、python/C++ 程序自动编译等较为复杂的应用场景。 注:阮咸AI助手用户可以从魔塔社区下载任意模型放入阮咸AI助手指定目录,无需配置环境,几千款模型,可立即调取使用(注意模型和硬件上限之间需要匹配) 工作流参数配置: 经优化,使用轻便笔记本电脑,搭配桌面算力(32GB),输出平均速度在55 Tokens/秒。每天一个关于本地大模型的热知识(一): 本地大模型都是有上下文限制的,主流开源大模型的上下文64K~256K,换成数据容量大概就是120KB~512KB,也就是每次发送给大模型的数据量不能超过该值,一旦超过该值,要么它只分析最后一段,要么就开始抽风不知所云。 所以想把几百M甚至几十G的取证数据一次性抛给大模型让他去分析,在没有专业辅助工具的前提下,原生的大模型就算是671B体量的也是处理不了的。 大模型能做的就是,理解你的意图,然后主动分析当前可以用哪些工具,然后主动调用这些工具的多个接口、方法去调取处理数据,然后汇总结果,所以用哪个大模型并不是关键,关键的是能被它调用的诸多碎片化工具,这些工具就叫MCP。 有了MCP工具,对于大模型来说,就可以充分放飞自我了,但是人的表达能力参差不齐,大模型理解的和人表达语义间可能会存在一定的差异,就会导致,大模型在胡乱执行,这时候就要规范它的行为,让它朝着我们实际的目标执行,简单规范就叫做提示词,复杂规范就称作skill。前一段时间爆火的小龙虾,就是到了这一步,集成了MCP也集成了skill。 那么大模型处理问题不一定是单一问题,很有可能就是多重逻辑问题、循环问题、复杂问题,对于这些问题,大模型在没有条理性规范的前提下,就会懵逼,这一步干完了下一步干啥?怎么干?受上下文限制,它还会偶尔遗忘,所以将前后所有的工作帮他穿起来,一步一步引导它,走完一步走下一步,这个规范就叫做工作流。 所以像之前某单位 XXX万搞个服务器部署了一个deepseek-R1:671B; 结果也只能聊个天。。。。别的啥也干不了。 明天我们讲:2B;4B;8B这种小模型和35B;70B以及300B;600B这种大模型有什么本质区别。关注阮咸科技
 夜雨聆风
夜雨聆风