 夜雨聆风
夜雨聆风我又用AI做了一个专利工具
—— 这次是「优先审查」一键判断
一个不会写代码的专利代理师,用 AI 造的第二套生产力工具
原创 · 知识产权+AI·2026年5月
先说结论:上面这张图里所有功能,又都是我"聊"出来的
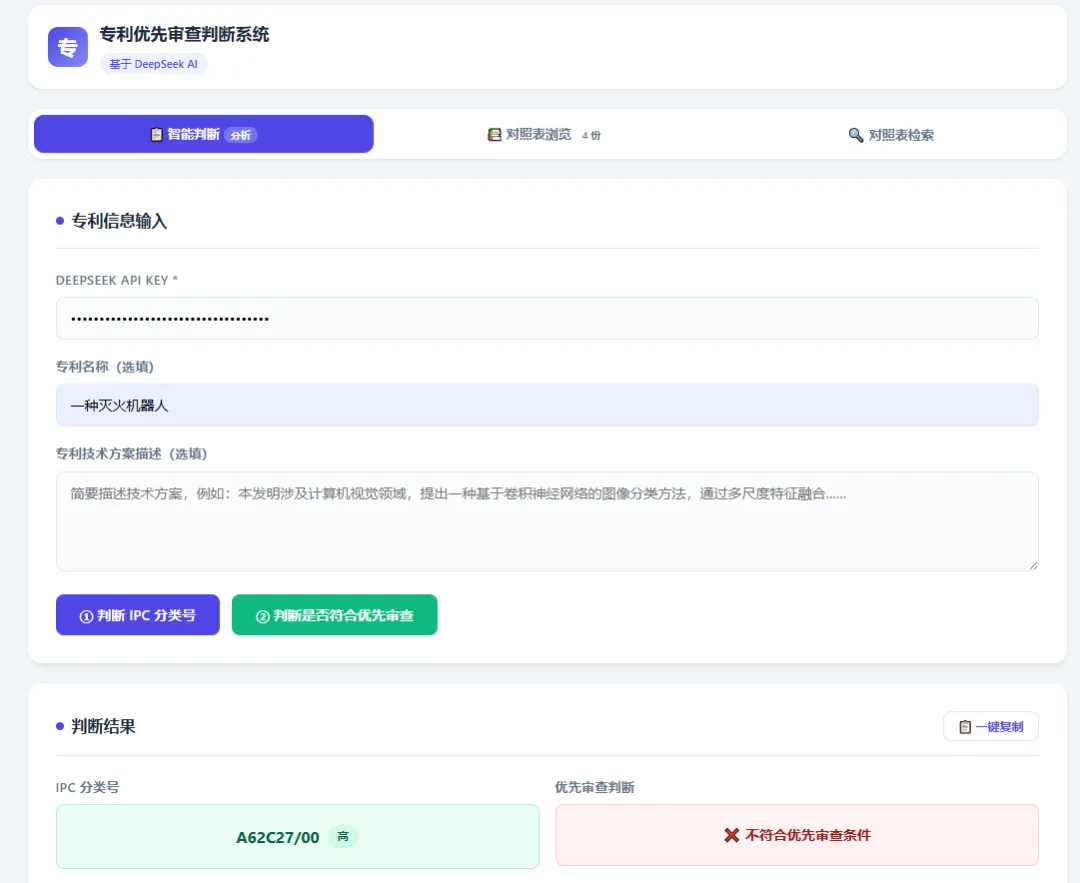
是的,你没看错。
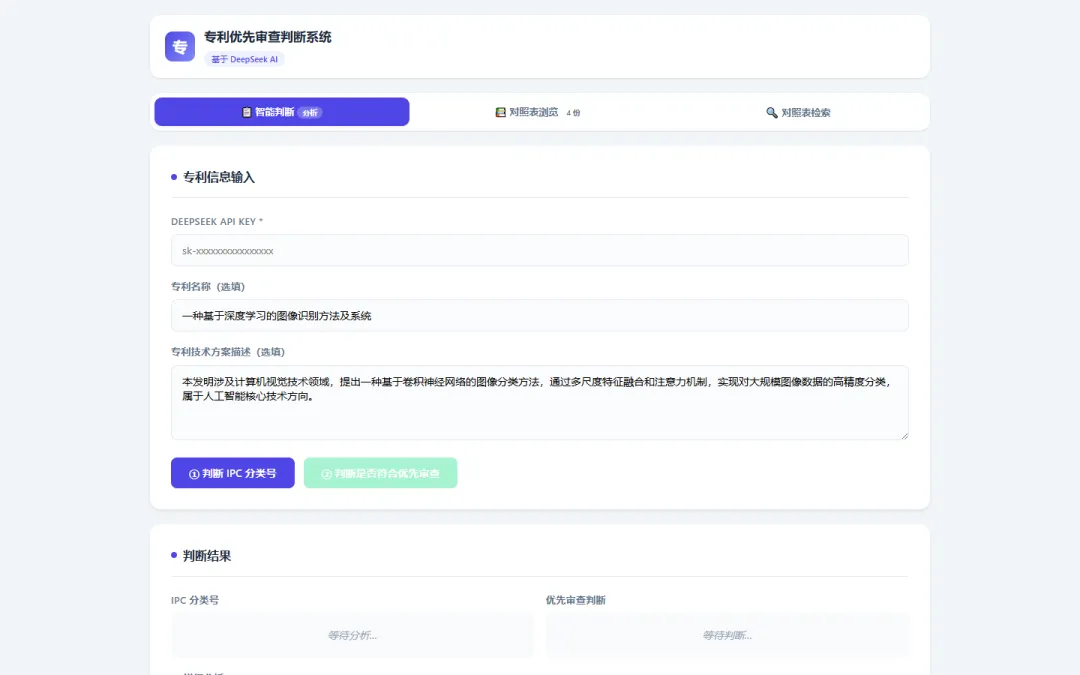
输入技术方案 → AI 自动判断 IPC 分类号 → 四份国知局对照表毫秒级检索 → 一键判断能不能走优先审查。全程 30 秒。
而我,上一次用 AI 做了一套 2893 家代理机构检索系统之后,这次又用 AI 聊出了一套专利优先审查判断系统。不会写 Python 后端、不会写前端页面、没碰过 Nginx 配置。
如果我都能做到,你也一定能。
▲ 首次访问弹出公众号关注引导——跟上一套系统一样,引流不能少
···
第一章:上次那套系统,给了我底气
可能有些读者第一次看到我的文章。先花一分钟回顾一下——
我上一篇文章详细记录了,怎么用 AI(Claude Code)做出一套完整的「专利代理机构精准保障名单查询系统」。全程没有写一行代码,靠的就是用中文跟 AI 对话。
上一套系统长什么样
最终产出了一套完整的 Web 应用,部署在 AWS 云端,现在仍然在线使用:
• 2893 家代理机构数据,AI 写爬虫从国知局网站自动抓取(12 小时跑完)
• 6 个可视化图表的仪表盘,一屏全览全国机构分布
• 中国地图热力图——北京 650 家颜色最深,一眼看出地域集中度
• 多维度筛选 + 模糊搜索 + 排序 + 分页 + 详情弹窗
• 暗色模式一键切换、CSV 数据导出、公众号引流弹窗
• 部署到 AWS 云服务器,Nginx + PM2,域名访问
而操作过程,我做的事就是——说"这里改个颜色""加个排序功能""能不能导出 Excel"。AI 听懂了,改了,跑起来了。
有读者问:"你是不是有技术背景?"
答:真没有。HTML 不会写、CSS 不认识、服务器没碰过。秘诀就一条——把 AI 当成不会累的技术合伙人,用中文把业务需求说清楚。
做完第一套系统之后,我信心大增。正好工作中频繁遇到另一个痛点——优先审查判断。于是我跟 AI 说:再做一个。
···
第二章:优先审查判断 —— 每个代理人都逃不掉的高频痛点
做专利代理的都清楚:优先审查能大幅缩短审查周期——发明专利从平均 2-3 年缩短到 3-6 个月。对客户来说,这可能是产品上市时间的关键差距。
但申请优先审查的第一关,就让很多人犯难——
你的 IPC 分类号,在不在国知局公布的对照表里?
国知局发布了四份专利分类对照表,用来界定哪些技术方向可以申请优先审查:
• 战略性新兴产业分类与国际专利分类参照关系表 —— 3000+ IPC
• 绿色技术专利分类体系 —— 780 IPC,含"全部涉及 / 部分涉及"区分
• 关键数字技术专利分类体系 —— 4200+ IPC,AI、芯片、量子计算、大数据等
• 「新三样」相关技术专利分类体系 —— 380 IPC,电动汽车、锂电池、光伏
四个 PDF,加起来几百页,总共超过 8400 个 IPC 分类号。
更麻烦的是,这些 PDF 里的匹配规则并不一样——
• 有些带 * 号 —— 表示该前缀及以下所有子类都算命中(通配符)
• 有些加了 NOT 排除 —— 比如 G06F11* 但不含 G06F11/14 和 G06F11/36
• 绿色技术体系里,同一个分类号可能标注"全部涉及"或"部分涉及",处理逻辑完全不同
每次判断一个申请能不能走优先审查,就是在这四份 PDF 里面大海捞针。搞不好还要跟同事来回讨论半天。
我心想:这个流程,AI 绝对能帮上忙。
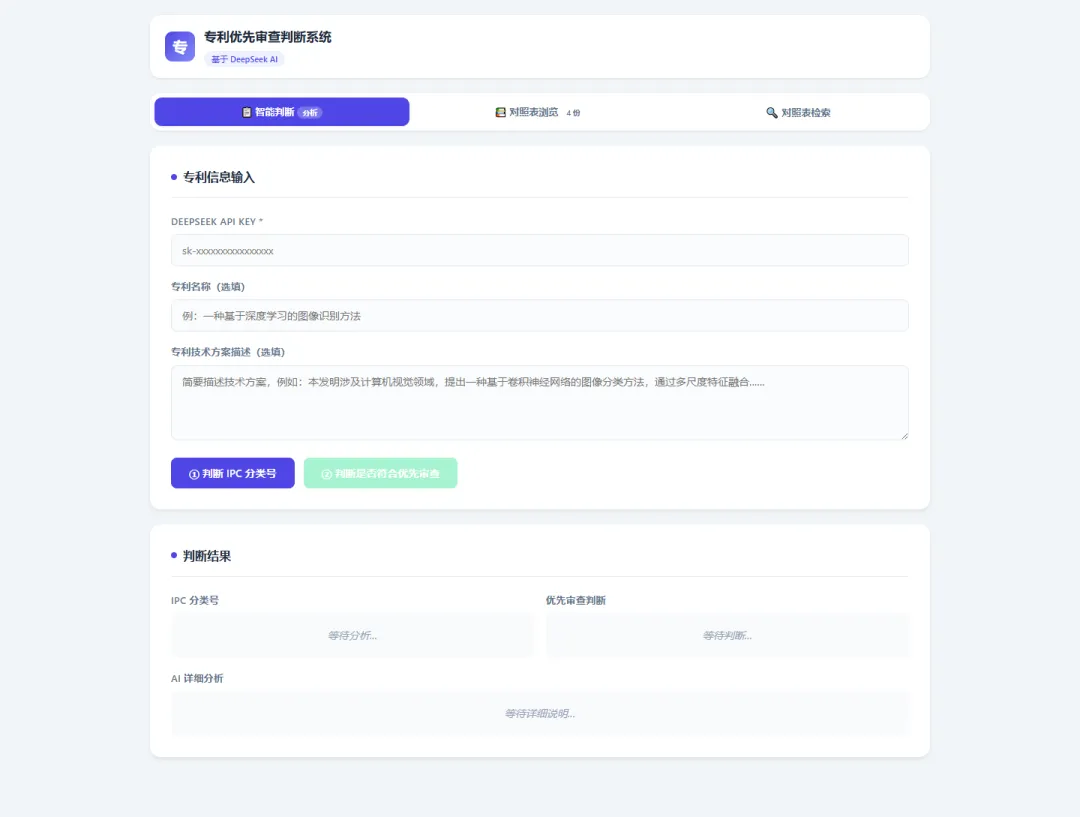
▲ 系统主界面全貌——三个Tab:智能判断、对照表浏览、对照表检索
···
第三章:从 PDF 到结构化数据 —— AI 啃下了最硬的骨头
做这套系统最难的部分,其实不是让 AI 判断分类号,而是第一步——
把四份 PDF 对照表变成计算机可以检索的结构化数据。
PDF 是给人看的,不是给机器看的。四份 PDF 的表格格式千奇百怪——
• 跨页行 —— 一行数据被分到两页上,解析程序需要自动判断下一页的文本是"延续上一行"还是"新的一行"
• 多级嵌套 —— 表4(新三样)有四级层级(一级目录 → 二级 → 三级 → 四级),每一级都有各自的关键词和 IPC 分类号
• 半口语化表述 —— 比如"主要涉及小类有:"这种写法,需要专门写正则来抓取
• 限定词区分 —— 表2 里同一个 IPC 号可能是"全部涉及"或"部分涉及",匹配规则完全不同
我把 PDF 丢给 AI,让它用 pymupdf(一个 Python PDF 解析库)逐页提取文本,然后写了一套状态机来跟踪当前所处的层级位置。
大概的思路是:读 PDF 每一行 → 判断这行是哪个层级(通过编号格式和缩进判断) → 如果检测到新的层级编号就切换上下文 → 如果上一行没有结束符就判定为跨页延续 → 提取 IPC 分类号和关键词 → 输出结构化 JSON。
思路不复杂,但 PDF 的坑特别多。AI 写了 200 多行解析脚本,我跟它反复调试了十来轮——每次它解析完一批数据,我抽查几条看看有没有乱入、遗漏,有问题就截图丢给它修。
最终解析成果
四份 PDF → 四个结构化 JSON 文件 → 总共超过 8400 条 IPC 分类号:
• 表1 战略性新兴产业:3000+ 条 IPC 分类号
• 表2 绿色技术:780 条分类号,含 NOT 排除和全部/部分涉及逻辑
• 表3 关键数字技术:4244 条分类号,含 * 通配符匹配
• 表4 新三样:380 条分类号,四级层级嵌套
四份对照表,全部装进了系统里。查询速度:毫秒级。
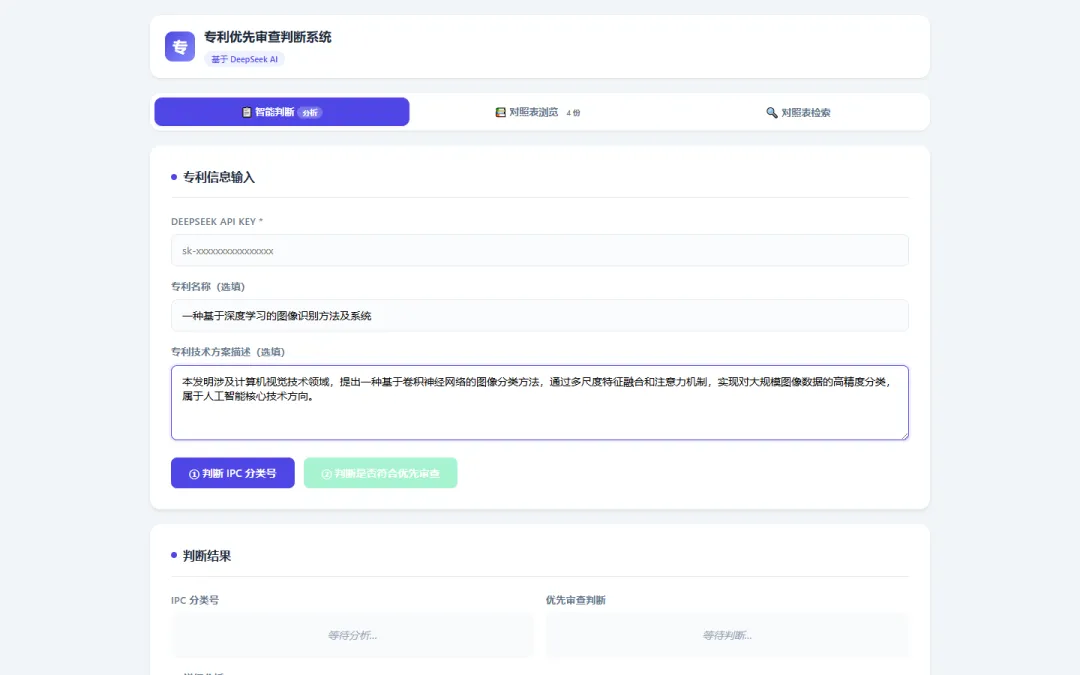
▲ 专利信息输入界面:填写技术方案描述后,AI 自动判断 IPC 分类号
···
第四章:匹配引擎 —— 然后 AI 自己发现了一个隐藏 Bug
有了数据,还需要一套匹配引擎。核心逻辑:输入一个 IPC 分类号 → 在四份对照表中查找 → 返回命中了哪个技术方向。
AI 设计了"最长前缀优先"匹配算法——
比如 G06F18/00 → 系统先匹配 G06F → 再匹配 G06F18 → 最具体的那个匹配就是答案。
同时处理通配符(G06F* = G06F 及所有下级子类全部命中)和 NOT 排除(G06F11* 但不含 G06F11/14 和 G06F11/36)。
匹配引擎写完,我开始测试。输入了几个我知道答案的分类号——
然后出事了
我输入 F23D14/26。这个分类号我确定属于绿色技术体系(表2),但系统告诉我"无匹配结果"。
我截图丢给 AI,让它排查。AI 翻了一遍代码之后,给出的诊断让我吃了一惊——
"问题不在匹配引擎,在 build 脚本。把表2原始数据转成 JSON 的时候,每个子类的 IPC 条目被 [:50] 截断了——只保留前 50 条就丢弃了后面的。"
"表2 的「1.1 煤炭清洁高效利用」子类实际有 133 条 IPC,但因为截断只保留了前 50 条。F23D14/26 刚好在第 50 条之后。"
"我检查了表3,情况更严重——被 [:100] 截断,丢失了 444 条数据。两个表合计,540 条分类号被截掉了。"
这个 Bug,我根本不会自己发现。我甚至不知道 build 脚本里有限制——那是我几次迭代之前,AI 为了"防数据太大"自己加的。
AI 不仅找到了代码里 540 条数据被截断的 Bug,还主动修好了。
这件事给我的触动很深。AI 不只是"听话写代码",它在帮你排查问题的时候,能追溯到自己之前写的代码里找逻辑缺陷。这种能力,已经不是"工具"两个字能概括的了。
···
第五章:双层判断 —— AI 分析 + 本地匹配,交叉验证
IPC 匹配引擎负责"查表",但还有一个问题——谁来给专利分 IPC?这需要 AI 来理解技术方案。
系统设计了两层判断逻辑:
第一层:AI 语义理解(DeepSeek API)
调用 DeepSeek API,用 Function Calling 模式让 AI 阅读用户输入的技术方案描述。AI 分析技术领域后:
• 输出最可能的 IPC 分类号
• 给出置信度(高 / 中 / 低)
• 附上分类说明——为什么判定这个分类号,技术依据是什么
注意:这一步不是简单查表,是让 AI 真正"读懂"技术方案。同样是"图像识别",可能是 G06F18(计算机视觉),也可能是 G06V10(模式识别),还可能涉及 G06T7(图像分析)——AI 根据具体描述来选择。
第二层:本地精确匹配(对照表检索)
拿到 AI 输出的 IPC 之后,匹配引擎在四份对照表中做本地精确检索。返回结果包含——
• 这张表叫什么名字(战略新兴产业 / 绿色技术 / 关键数字技术 / 新三样)
• 属于哪个大类 → 哪个子类(完整层级路径)
• 匹配到的具体 IPC 条目是什么,匹配精度如何
两层交叉验证:AI 负责"理解技术方案",本地引擎负责"精确查表"。两边的结果互相印证。
你可以自己核对每一个匹配结果。不是黑盒。
▲ 判断结果展示区:IPC 分类号 + 置信度 + 对照表命中位置 + AI 详细分析
···
第六章:四张对照表,一键浏览 + 全文搜索
除了 AI 判断功能,系统还做了两个可以直接用的工具:
对照表浏览 —— 想看哪张点哪张
四份对照表展开在页面上,按"大类 → 子类 → 单个 IPC 条目"的层级组织。想看绿色技术有哪些方向?点开、展开、翻——每条 IPC 都带着技术关键词说明,不用再去翻原始 PDF。
• 总共 4 张主表,几十个产业大类,上百个技术子类
• 每个子类下面列出完整的 IPC 分类号和对应的技术领域说明
• 点一下展开、再点一下折叠——跟文件夹一样操作
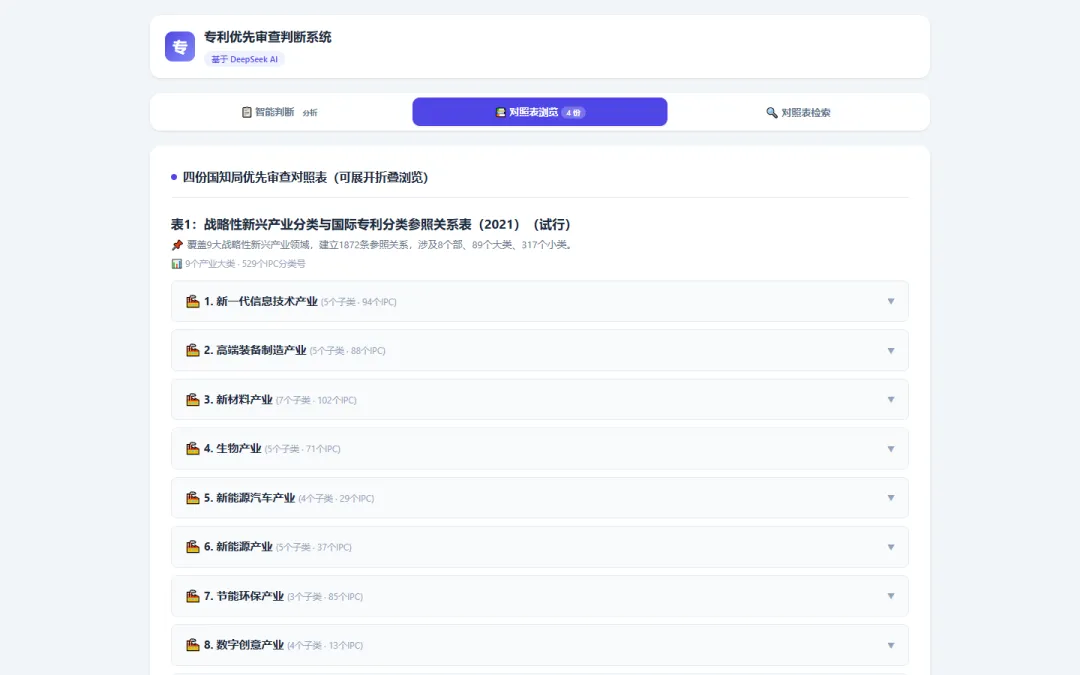
▲ 四份对照表浏览页——按产业大类分开展示,点击即可展开
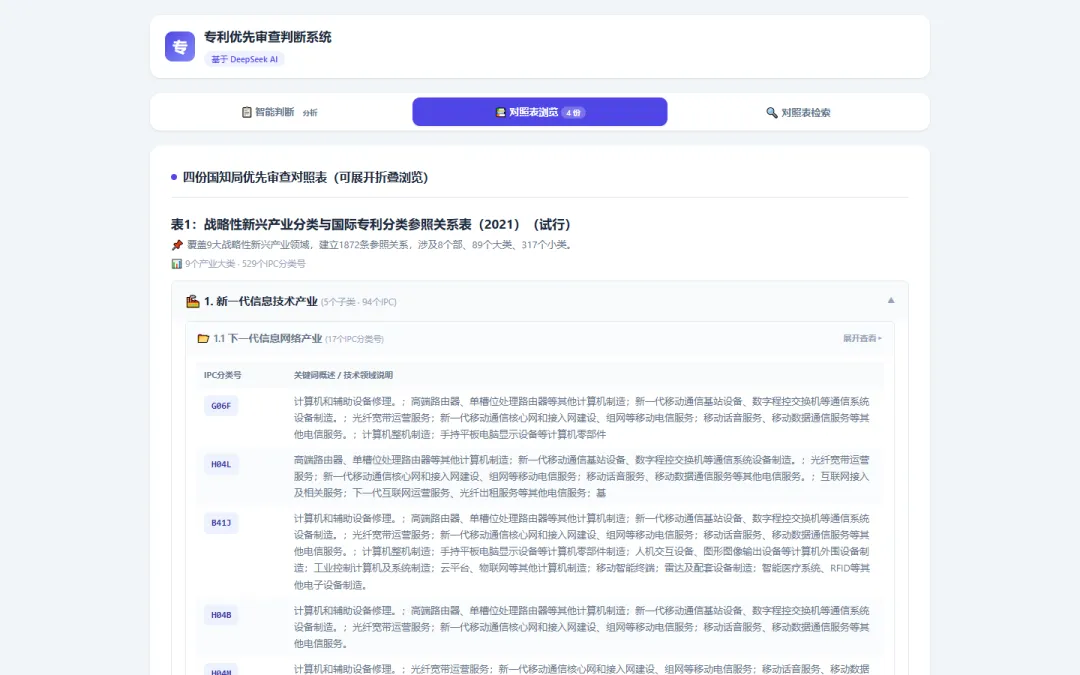
▲ 展开到最细层级——每个子类下的 IPC 分类号 + 技术关键词说明,一目了然
对照表检索 —— 输入关键词或 IPC 号,秒出结果
支持两种检索方式:
• 按 IPC 分类号查:输入 G06F18,显示该分类号在四张表中分别命中哪些位置
• 按关键词查:输入"锂电池",搜索所有涉及锂电池的技术分类条目
搜索范围覆盖四份对照表的全部内容——IPC 分类号 + 技术名称 + 关键词说明。
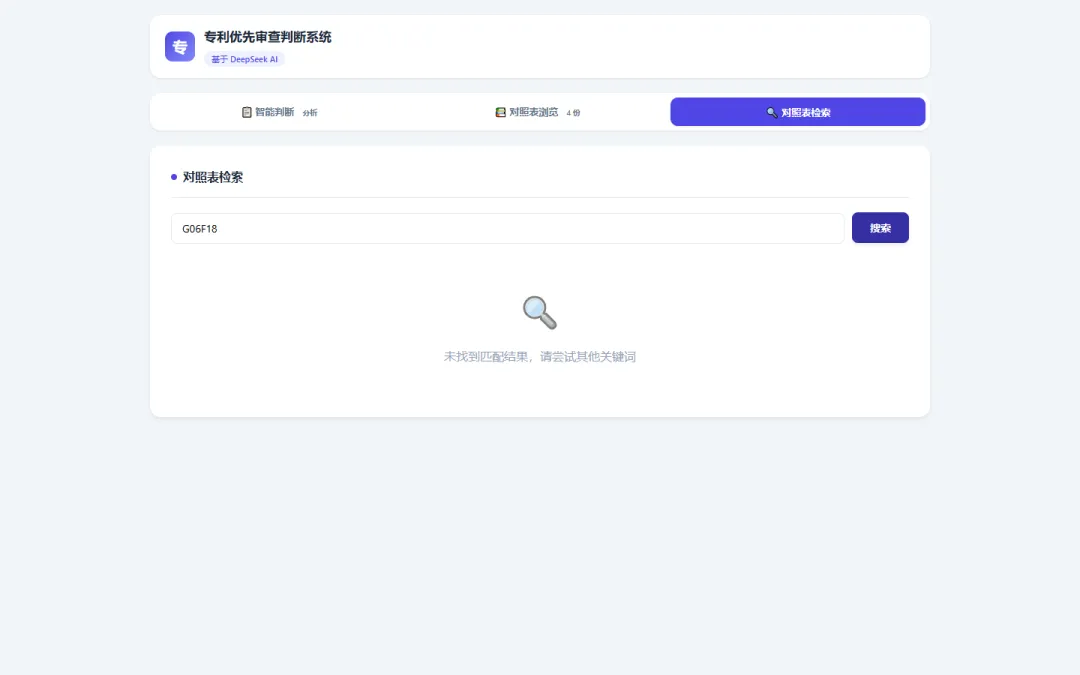
▲ 按 IPC 分类号 G06F18 检索——在战略新兴产业和关键数字技术两张表中命中
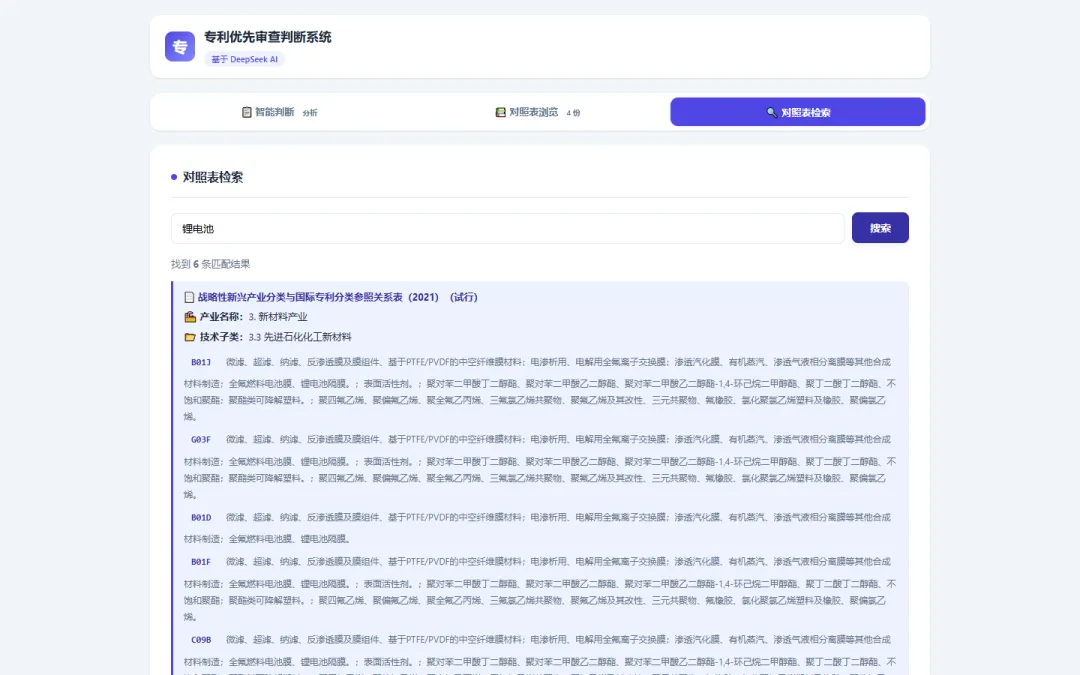
▲ 按关键词"锂电池"检索——跨表搜索结果,每个命中项显示所属表名和分类路径
···
第七章:优先审查被驳回?先用这个自查三点
做这套系统的过程中,我反复测试了大量分类号,对优先审查判断有了更具体的认识。总结下来,被驳回的原因就三类——
第一坑:分类号不在对照表里 —— 硬门槛
国知局四份对照表是白名单机制——不在表里的分类号,优先审查走不通。但八千多个分类号、"全部涉及/部分涉及"的区分、各种 NOT 排除——人眼一个一个核对太容易漏。
用工具的检索功能,输入你的 IPC 分类号,30 秒确认。
第二坑:技术方案描述太笼统 —— 审查员看不出产业关联
"一种新型节能装置""一种智能化控制系统"——这种写法,审查员根本看不出来跟重点产业的具体关系。优先审查的核心逻辑是:你的技术方案必须清晰地落入国家重点支持的技术方向。
描述越具体、跟对照表里的技术分支对应关系越明确,通过率越高。比如不要说"节能装置",说"一种基于相变储热的工业余热回收系统"。
第三坑:四张表选错了 —— 匹配度天差地别
四份对照表有交叉但不完全重叠。举个例子——"智能电网"在绿色技术体系里有(节能储能方向),同时在关键数字技术里也有(大数据+能源管理方向)。选哪张表匹配度更高?选错了,可能直接导致判断结果变成"不符合"。
我们的系统同时在四张表中检索,给出每张表的命中情况——你不用猜。
···
第八章:部署上线 —— 两个项目,一台服务器
系统写完了,要上线。
上一套代理机构检索系统已经跑在一台 AWS EC2 t2.micro 服务器上(1核1G,954MB 内存)—— Express + PM2 + Nginx。
这台服务器本来就不宽裕。再加一套 Flask 应用,内存够吗?端口怎么分?
AI 给出的方案非常简单:
Nginx 路径路由 —— 同一个对外端口,承载两个项目。
两个项目、同一台服务器、同一个对外端口(3001)、各自独立运行、互不影响。一个 1 核 1G 的 t2.micro,稳稳地承载两套完整的 Web 应用。
部署过程,AI 一步步指导我:SSH 连上服务器 → 装好 Python 依赖 → 用 Waitress 替代 Gunicorn(内存更轻) → 写 server.py 启动脚本 → 配 Nginx 路径路由 → PM2 守护进程。全程我在终端里复制粘贴 AI 给的命令,没写过一行配置。
部署完成后,我在服务器上跑了一下——
两个项目内存合计约 135MB。机器还有 800MB 空闲。
···
这次做系统,我又加深了一个信念
上次那篇文章的结尾,我说过一句话。这次做完第二套工具,我的体会更深了:
AI 时代,知识产权行业的竞争壁垒,不再是"谁会写代码"——
而是"谁更懂业务、谁更有想法、谁愿意花一个下午把想法变成工具"。
第一套系统证明了"一个不会编程的人用 AI 能做出一套工具"。
第二套系统证明了"这个模式可以复制——越做越快"。
第一套花了一个周末,第二套一个下午就搞定了核心功能。因为很多技术积累已经在那儿了——Flask、Nginx、PM2、服务器架构、路径路由——AI 都有了上下文,说一句话就能复用。
两套系统回顾
全程我没有写一行代码:
• 2893 家代理机构检索系统 —— Node.js + ECharts + 数据仪表盘 + 中国地图 + 暗色模式
• 专利优先审查判断系统 —— Python Flask + DeepSeek AI + 8400+ IPC 匹配引擎 + 四份对照表
两套系统、同一台服务器、同一个端口、都在线上跑着。
而且我相信,第三套只会更快。
···
这次你最想要哪个功能?评论区告诉我
跟上次一样——点赞最多的需求,我下一个就用 AI 做出来,并且把完整的开发过程公开分享:
• A. 批量判断 —— 一次提交多个专利,批量输出优先审查结果
• B. 生成优先审查申请理由书 —— 结合匹配结果自动生成申请文书
• C. 对接专利年费监控 —— 优先审查 + 年费提醒,一站式管理
• D. 支持更多对照表 —— 自动追踪国知局更新,保持数据最新
• E. 其他 —— 评论区发挥,说不定你的想法就变成下一个工具
···
系统免费使用。需要自己注册一个 DeepSeek API Key(deepseek.com 免费注册即得,新用户有免费额度)。
体验地址:一定要关注我
长按识别二维码,关注本公众号
获取更多「知识产权× AI」实操案例与生产力工具分享

��评论区告诉我:你最想要的 AI+知识产权工具是什么?
点「在看」让更多同行看到,一起推动行业的 AI 化
❤ 点「在看」让更多同行看到|💬 评论区告诉我你的需求|🔄 转发给需要的同行
···
— END —
