夜雨聆风
夜雨聆风LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AI - 人工智能
1、[CL] optimize_anything:A Universal API for Optimizing any Text Parameter
2、[LG] A Bitter Lesson for Data Filtering
3、[AI] Agent Security is a Systems Problem
4、[LG] Optimal Reconstruction from Linear Queries
5、[LG] Density-Ratio Losses for Post-Hoc Learning to Defer
摘要:适配全场景的文本参数优化通用API、数据过滤的苦涩教训、智能体安全本质上是一个系统性工程问题、线性查询下的最优重构、基于密度比损失的事后学习推迟方法
1、[CL] optimize_anything: A Universal API for Optimizing any Text Parameter
L A Agrawal, D Lee, S Tan, W Ma…
[UC Berkeley]
optimize_anything:适配全场景的文本参数优化通用API
要点:
将极其广泛的问题(智能体架构、云调度策略、CUDA内核、视觉SVG和系统提示词)统一形式化为“文本伪影(text artifact)优化”问题。 在一个单一的声明式API( optimize_anything)下,统一了三种截然不同的优化范式:单任务搜索、多任务搜索和泛化。首次将多任务搜索引入LLM进化中,证明了优化模式(如CUDA中的内存合并)可以通过共享的帕累托前沿在不同但相关的任务之间进行迁移。 反直觉的发现:多任务搜索是一把双刃剑。当任务共享结构模式(如CUDA内核)时,它能显著提升性能;但当任务本质上相互独立时(如不同N值的圆排列问题),它会引入噪声并导致性能下降。 将“辅助信息”(Side Information, SI)提升为一等API契约。作为一种“文本梯度”,SI(堆栈跟踪、VLM批评、子分数)使得算法能够进行有针对性的改变而非盲目突变,将收敛速度提高了4-6倍。 揭示了“多模块帕累托蛙跳(Leapfrogging)”动态:通过在共享的帕累托前沿上同时追踪代码产物和精炼提示词,这两个模块轮流为彼此的下一次改进奠定基础。 证明了复杂的、包含300多行代码的多阶段智能体架构(包括验证和回退逻辑),可以纯粹通过自动化的迭代优化,从一个只有10行的原生种子(单次LLM调用)中自发涌现。 引入了“无种子模式(Seedless mode)”,当提供初始代码过于困难时,允许优化过程完全从自然语言目标(例如从零生成3D独角兽的CAD脚本)启动并自举。
主旨: 现有基于大语言模型(LLM)的优化系统(如AlphaEvolve、GEPA)通常局限于特定的领域(纯代码或纯提示词),且仅支持单一的优化模式(单任务或泛化)。本文旨在解决这一碎片化问题,提出并开源了一个名为 optimize_anything 的通用API,将所有优化问题统一建模为“文本参数”的评估与迭代,旨在用一个框架在跨度极大的不同领域中匹配甚至超越领域特定的优化工具。
创新:
统一的三重优化模式:在一个API下同时支持单任务搜索(Single-task)、多任务搜索(Multi-task,LLM进化领域首次引入)和泛化(Generalization)。 将辅助信息(SI)作为“文本梯度”:打破了传统标量奖励的限制,将报错信息、性能分析数据、甚至图像渲染结果作为一等公民(API Contract)直接反馈给LLM,使其能够像人类工程师一样进行“有理有据”的调试。 扩展的帕累托搜索:将基于帕累托前沿的选择机制从提示词优化扩展到任意文本产物,并引入“每指标(per-metric)”和“每样本(per-example)”的非支配排序,确保多样性并防止过早收敛。 无种子启动(Seedless Mode):无需初始代码,仅凭自然语言描述即可冷启动并从零生成复杂代码架构(如3D建模)。
贡献:
通用性证明:首次证明单一的LLM文本优化系统可以在六个完全不同的领域(智能体架构、云调度、CUDA加速、数学提示词、圆排列优化、图像生成)同时达到SOTA(最先进)水平。 范式扩展:确立了“基于LLM搜索的文本优化”是一种通用的问题解决范式,打破了以往需要针对不同问题设计专门启发式算法的传统。 跨任务迁移的实证:通过多任务搜索模式,在CUDA内核生成任务中证明了LLM能够自动提取并在不同任务间迁移底层优化逻辑。 开源生态:开源了 optimize_anything及多个后端(作为GEPA项目的一部分),极大地降低了各领域专家使用高级AI优化技术的门槛。
提升:
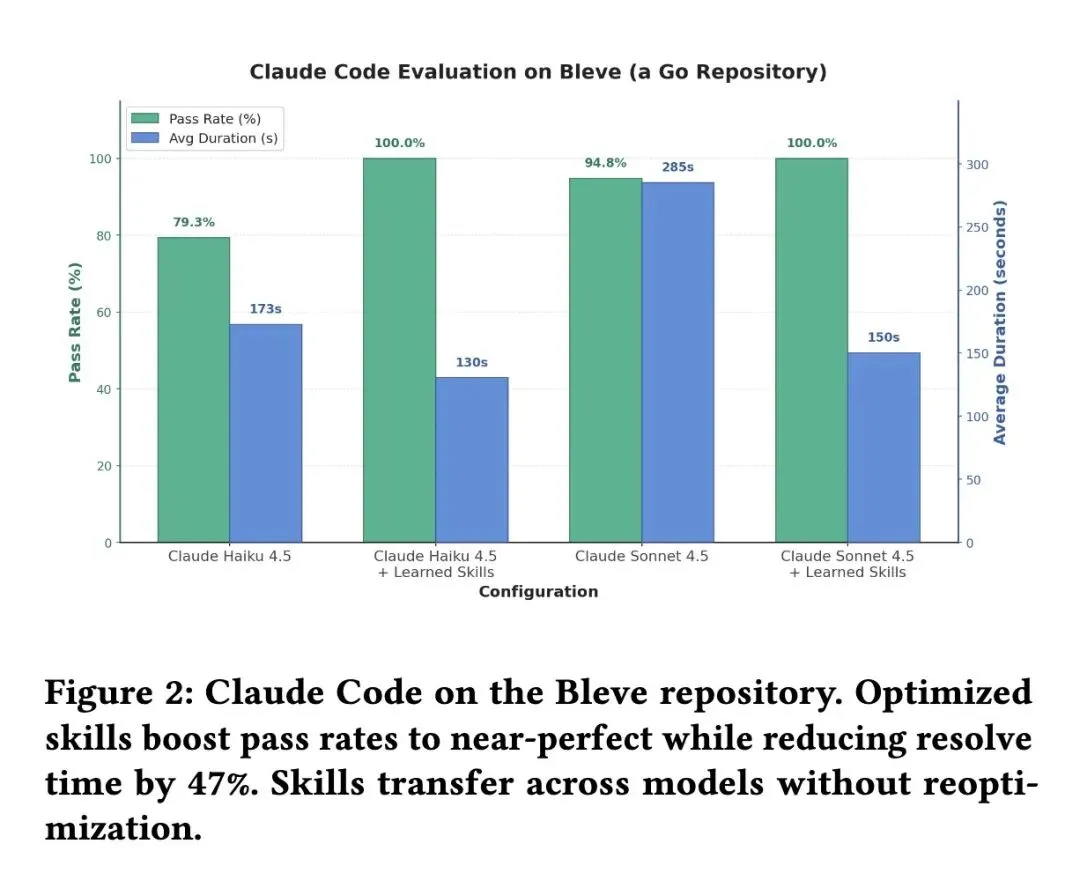
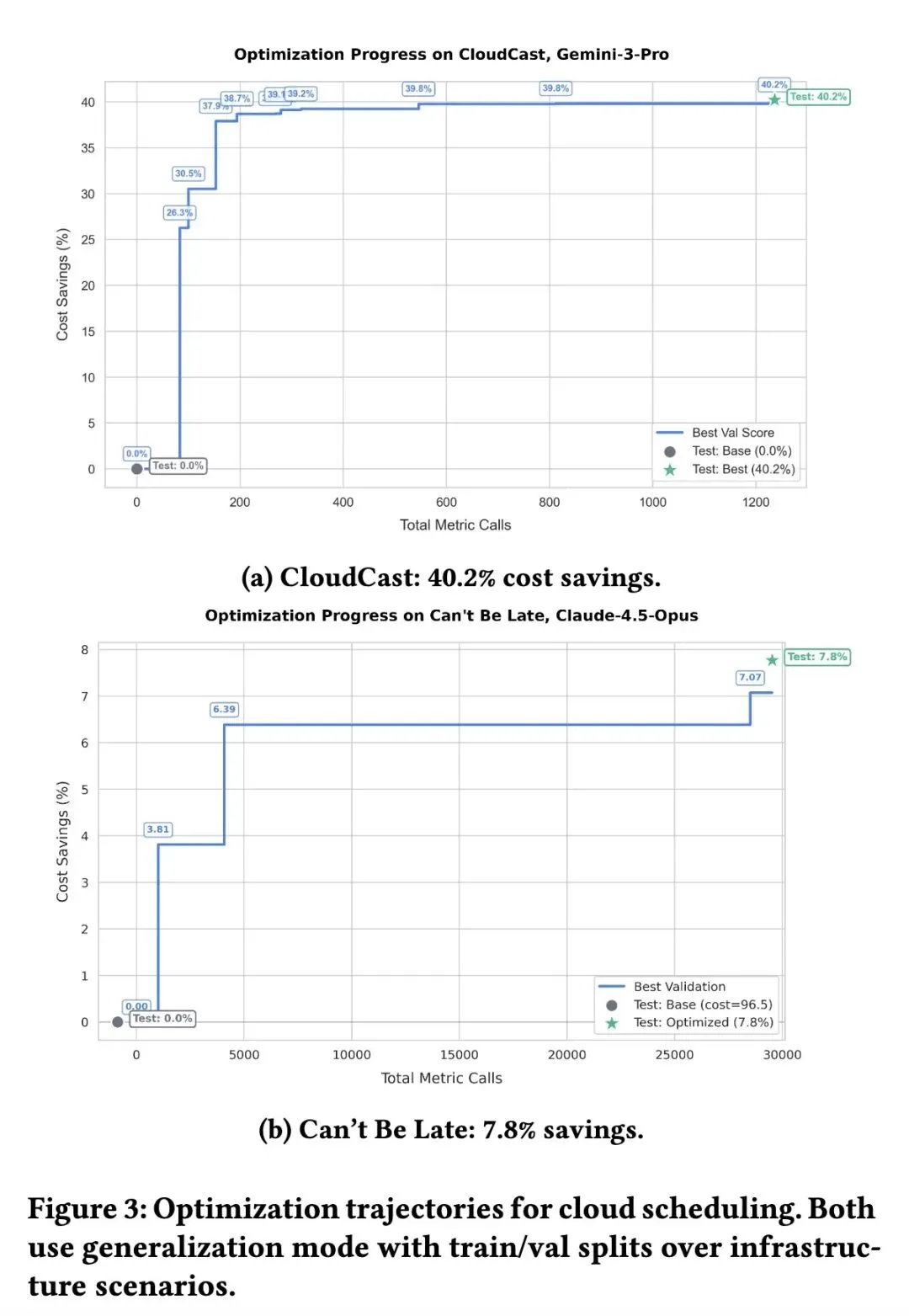
智能体能力(ARC-AGI):将 Gemini 3 Flash 在 ARC-AGI 测试集上的准确率从 32.5% 跃升至 89.5%(提升57个百分点)。 系统降本(云调度):在 CloudCast 任务中,相比 Dijkstra 路由基线节省了 40.2% 的成本;在 Can't Be Late 任务中节省 7.8%,登顶 ADRS 榜单。 代码性能(CUDA内核):生成的内核中有 87% 达到或超越 PyTorch 官方基线,其中 25% 实现了 20% 以上的加速。 提示词推理(AIME):将 GPT-4.1-mini 在 AIME 2025 上的准确率从 46.67% 提升至 60.0%。 收敛效率:消融实验表明,引入 SI(辅助信息)后,模型达到目标性能所需的评估次数减少了 4-6 倍。
不足:
极度依赖评估器成本:高质量的优化需要频繁调用评估器,当评估涉及复杂环境交互(如 ARC-AGI 智能体评估花费 144 美元)时,资金和时间成本较高。 受限于底层 LLM 能力:提案模型(Proposer LLM)的推理能力直接决定了优化的上限。实验表明,使用较小的模型(如 GPT-5-nano)会显著降低最终的性能天花板。 多任务模式的负迁移风险:如果强行将没有底层结构相关性的任务(如不同 N 值的圆排列问题)放在一起进行多任务搜索,反而会引入噪声并导致性能退化。 数据模态限制:系统假设所有优化的参数或架构最终都可以被序列化为文本,对于原生连续参数或二进制产物的优化仍需要文本作为代理。
心得:
“文本梯度”是迈向Agentic System的核心钥匙:传统优化算法苦于无法处理不可微问题,而 optimize_anything证明了丰富的诊断信息(Side Information,如堆栈报错、耗时分析)实际上充当了 LLM 的“文本梯度”。给模型一个分数它只能盲猜,给模型一个报错日志它却能精准修复。未来的系统设计应将“如何生成丰富的多模态反馈”置于与“如何设计模型”同等重要的位置。系统架构的“自然涌现”极其震撼:在 ARC-AGI 实验中,一个原本仅包含 10 行代码的简单 LLM 调用,在无人类干预的情况下,自动“进化”成了包含代码生成、沙盒验证、多轮重试和 LLM 降级回退的 300 行复杂工程架构。这深刻启示我们:未来 AI 工程师的工作可能不再是手动编写复杂的 Workflow 或 LangChain 逻辑,而是定义好评估函数,让架构在演化中自行生长。 迁移学习的本质是“底层逻辑共享”:多任务搜索模式在 CUDA 优化中大放异彩(因为不同的算子底层都需要内存合并和 warp 级约简),却在圆排列中翻车。这反直觉地提醒我们:在利用大模型进行批量优化时,任务表面的相似性并不重要,底层是否存在可以复用的“结构化策略”才是决定多任务优化能否产生正向协同效应的唯一标准。
一句话总结:optimize_anything 是一个通用的声明式 LLM 优化框架,它通过将任意问题转化为“文本参数”,并利用富诊断信息(辅助信息)驱动帕累托搜索,首次在智能体架构、云调度、CUDA加速等六个截然不同的领域用单一工具实现了超越专用算法的 SOTA 性能。
Can a single LLM-based optimization system match specialized tools across fundamentally different domains? We show that when optimization problems are formulated as improving a text artifact evaluated by a scoring function, a single AI-based optimization system—supporting single-task search, multi-task search with crossproblem transfer, and generalization to unseen inputs—achieves state-of-the-art results across six diverse tasks. Our system discovers agent architectures that nearly triple Gemini Flash’s ARC-AGI accuracy (32.5% → 89.5%), finds scheduling algorithms that cut cloud costs by 40%, generates CUDA kernels where 87% match or beat PyTorch, and outperforms AlphaEvolve’s reported circle packing solution (n=26). Ablations across three domains reveal that actionable side information yields faster convergence and substantially higher final scores than score-only feedback, and that multitask search outperforms independent optimization given equivalent per-problem budget through cross-task transfer, with benefits scaling with the number of related tasks. Together, we show for the first time that text optimization with LLM-based search is a generalpurpose problem-solving paradigm, unifying tasks traditionally requiring domain-specific algorithms under a single framework.
https://arxiv.org/abs/2605.19633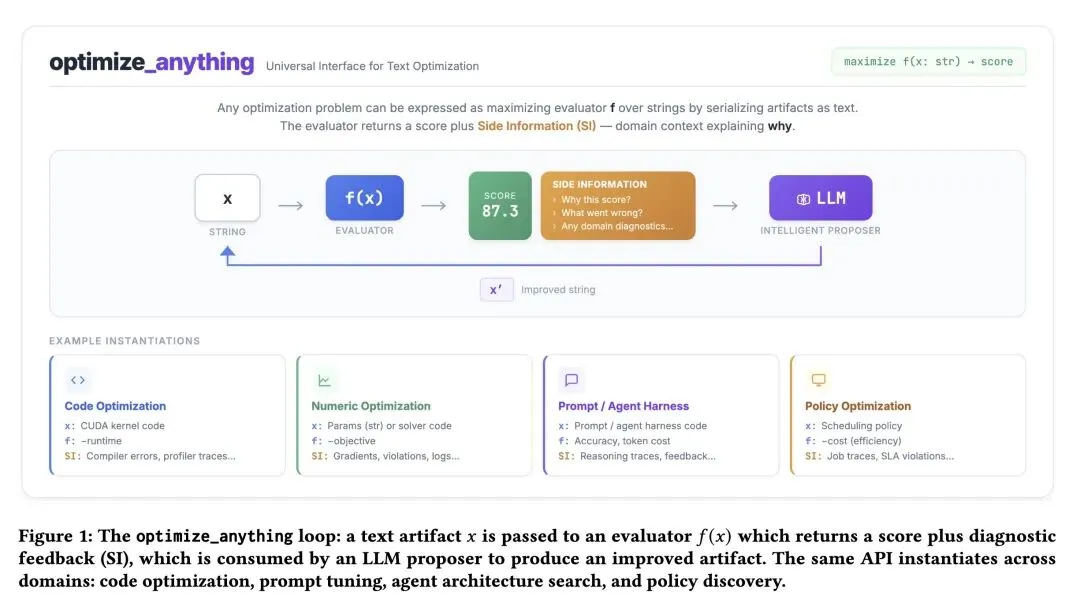
2、[LG] A Bitter Lesson for Data Filtering
C Mohri, J Duchi, T Hashimoto
[Stanford University]
数据过滤的苦涩教训
要点:
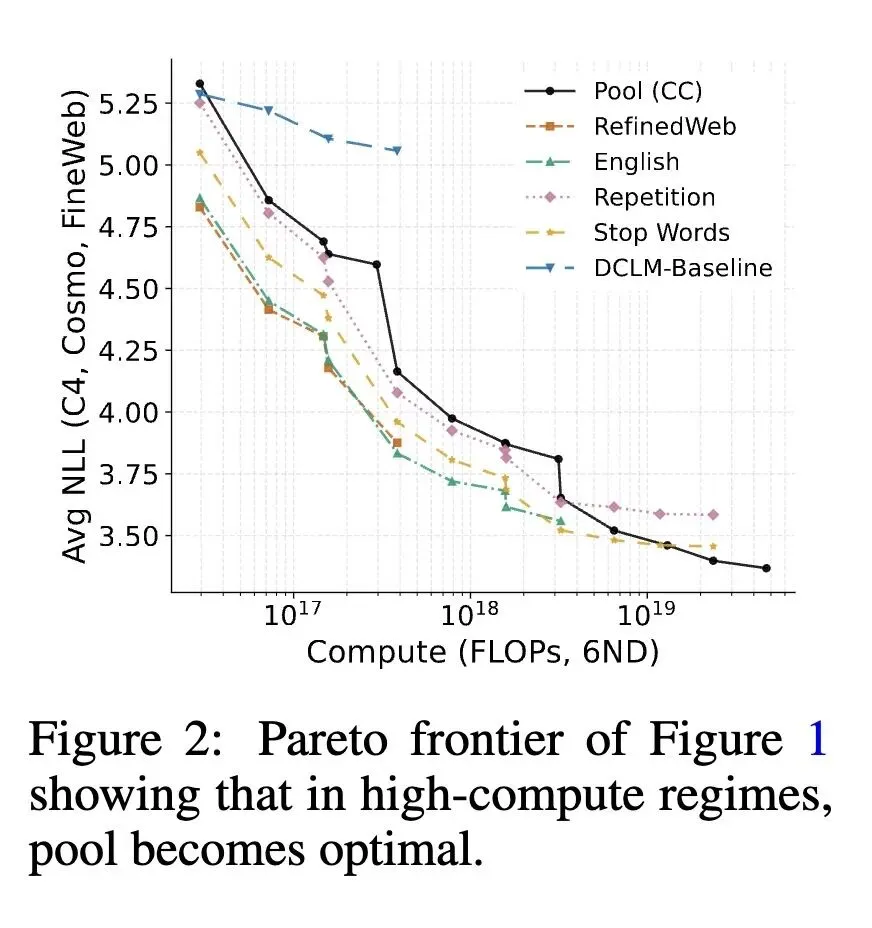
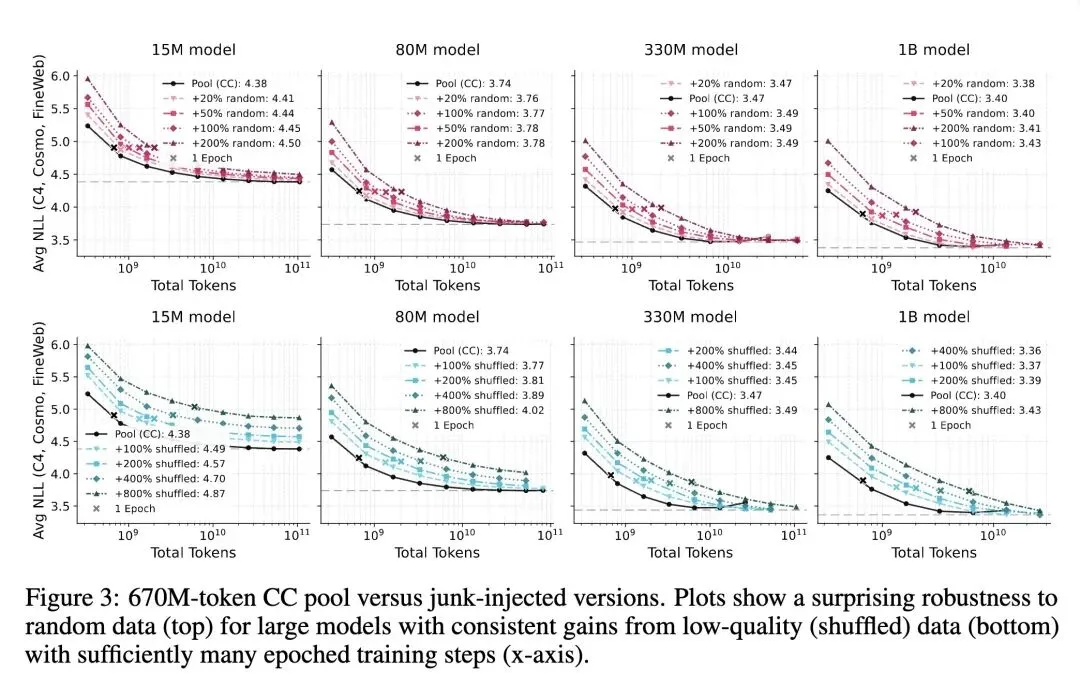
挑战了目前被广泛接受的传统认知,即:对预训练数据(如Common Crawl)进行严格过滤以保留“高质量”文本是训练大语言模型必不可少的步骤。 证明了在极高算力极限下(大模型配合极多的训练步数/多Epochs),在未过滤的Common Crawl (CC) 全量数据池上进行训练,最终表现会超越像RefinedWeb和DCLM-Baseline这样经过重重过滤的高质量数据集。 反直觉的发现:足够大的模型对人为注入的“垃圾”数据具有惊人的鲁棒性,例如完全随机生成的字符串或词序被彻底打乱的废话文章,根本无法摧毁模型的表现。 高信息熵内容:大型模型不仅能容忍这些“垃圾”数据,甚至还能从中获益(例如,即使文章词序被打乱,大模型依然能从中提取并利用unigram分布和词汇共现统计信息)。 建立了精确的缩放定律(Scaling Laws),预测在算力达到约 1e30 FLOPs 时,完整的240万亿Token的未过滤CC数据集将成为数学上的最优解。 提供了一个基于线性矩阵分解的理论基础:高容量(高秩)模型可以将噪声任务正交化并吸收到独立的子空间中,从而不会导致性能下降;而小模型则会因为特征干涉而崩溃。 呼应了Richard Sutton的“苦涩的教训(Bitter Lesson)”:人类手工设计的启发式数据过滤器,就像过去的手工特征工程一样,最终都会被简单的“无过滤策略+庞大算力规模”所击败。
主旨: 本文探讨了在充足乃至极限算力下,大语言模型预训练中的数据过滤问题。文章提出并验证了一个极具颠覆性的观点:“最好的数据过滤器就是没有过滤器”。研究表明,在模型参数量足够大、训练时间足够长的情况下,全量且未过滤的网络数据(哪怕包含大量低质量或垃圾内容)不仅不会损害模型,反而比经过精心筛选的高质量数据集更能提升模型的性能上限。
创新:
反常识的极端压力测试:颠覆了行业内不断“内卷”数据清洗管道的趋势,通过人为注入纯随机字符串和打乱词序的极端“垃圾数据”来测试大模型的鲁棒性边界。 构建高算力下的数据缩放定律(Scaling Laws):没有停留在中小算力规模的观察上,而是通过系统的缩放实验,推演出当算力达到 1e30 FLOPs 时,完全放弃数据清洗将超越目前最先进的数据集(如DCLM)。 结合容量理论解释抗噪机制:创新性地利用矩阵分解(Matrix Factorization)的数学模型,从理论层面证明了为什么“小模型怕脏数据,而大模型不怕”(高阶矩阵可以正交化隔离噪声)。
贡献:
实证贡献:提供了强有力的实证数据,证明了在验证集损失(Perplexity)和下游任务基准上,未过滤数据在充足算力下的最终表现超越了所有主流过滤策略。 理论贡献:提出了表征维度的理论解释,揭示了模型容量如何直接决定其消化吸收冗余信息和噪声数据的能力。 认知贡献:纠正了对于互联网预训练数据“事实性毒性”的过度担忧。通过语料库分析证明,尽管Common Crawl包含错误信息,但支持性/相关性事实的数量远大于反驳性(错误)事实,模型足以去伪存真。 战略预测:为AI工业界的未来发展提供了明确的路线图预测,即未来极大规模的预训练可能会逐渐放弃昂贵且复杂的启发式数据清洗步骤。
提升:
性能上限突破:实验证明,通过简单地增加模型参数和训练Epoch,基于纯Common Crawl训练的模型最终跨越了交叉点,其性能上限超过了去重、质量分类器、停用词过滤等手段处理过的高质数据集。 “废料”利用率:证明了模型具备从字面意义上的“垃圾数据”(词序完全随机打乱)中提取有效统计特征的能力,相当于提升了数据池中每一滴信息的利用率。
不足:
极度依赖庞大的未来算力:论文预测“无过滤”成为最优解的算力阈值约为 1e30 FLOPs,这远远超出了当前最先进模型(如Grok 3等,通常在 1e26 级别)的算力水平。对于当下的实践者来说,数据过滤仍然是必需的。 未涵盖更复杂的现代架构:实验主要基于基础的密集型(Dense)Transformer模型。对于MoE(混合专家模型)等在训练动态上更不稳定的架构,是否依然对垃圾数据免疫尚不确定。 高质量合成数据的冲击:文章主要对比的是真实网络数据过滤。目前业界正在大量引入高质量的AI合成数据(Synthetic Data),如果合成数据的收益远大于低质量自然数据,数据配比的最佳策略可能会改变。
心得:
“苦涩的教训”在数据维度的终极重演:Rich Sutton的名言指出,人类试图将先验知识编码进AI系统的努力(如特征工程、国际象棋的启发式规则),最终都会被简单通用的算法加上极致的算力所碾压。本文告诉我们,目前大厂耗费数百万美元研发的“高质量数据分类器”、“启发式清洗管道”,本质上依然是人类先验知识的变种。在未来的算力巨兽面前,直接给它喂整个互联网(无论好坏)反而会是最终答案。 “垃圾进,垃圾出 (GIGO)”定律的条件性失效:传统计算机科学中坚不可摧的 GIGO 定律,在大语言模型时代需要被重新定义。小模型确实是 GIGO,因为它容量小,好知识和垃圾信息会在相同的权重空间里“打架”(特征干涉);但对于超大模型,它有着浩瀚的参数空间(高秩),相当于拥有无数个正交的房间,它会自动把垃圾信息锁在无关的房间里,并从废墟里捡出有用的砖块(如词频共现)。只要网络足够深邃,垃圾也能成为养料。 分布偏移(Covariate Shift)不等于数据投毒(Data Poisoning):为什么注入海量废话和乱码不会毁掉模型?这启发我们认识到,LLM其实完全不在乎“低信息密度”或“奇怪的语言分布”。只要互联网数据中依然存在那千分之一的真实人类知识,大模型就能把它吸掉。真正可怕的不是“废话”,而是结构完美但故意颠倒黑白的“毒药”(比如海量且一致的错误事实陈述)。幸运的是,自然形成的互联网语料中,废话虽多,但系统性的系统谎言比例依然可控。
一句话总结: 本文挑战了预训练必须进行严格数据过滤的传统共识,通过实证与理论证明,在算力和模型容量足够大的前提下,大型语言模型不仅能完美抵御并隔离“垃圾数据”的干扰,甚至能从中提取残余价值,“放弃数据过滤直接训练全量互联网”将成为未来极致算力时代下的必然选择。
We investigate data filtering for large model pretraining via new scaling studies that target the high compute, data-scarce regime. In spite of an apparently common belief that filtering data to include only high-quality information is essential, our experiments suggest that with enough compute, the best data filter is no data filter. We find that sufficiently trained large parameter models not only tolerate low-quality and distractor data, but in fact benefit from nominally “poor” data.
https://arxiv.org/abs/2605.19407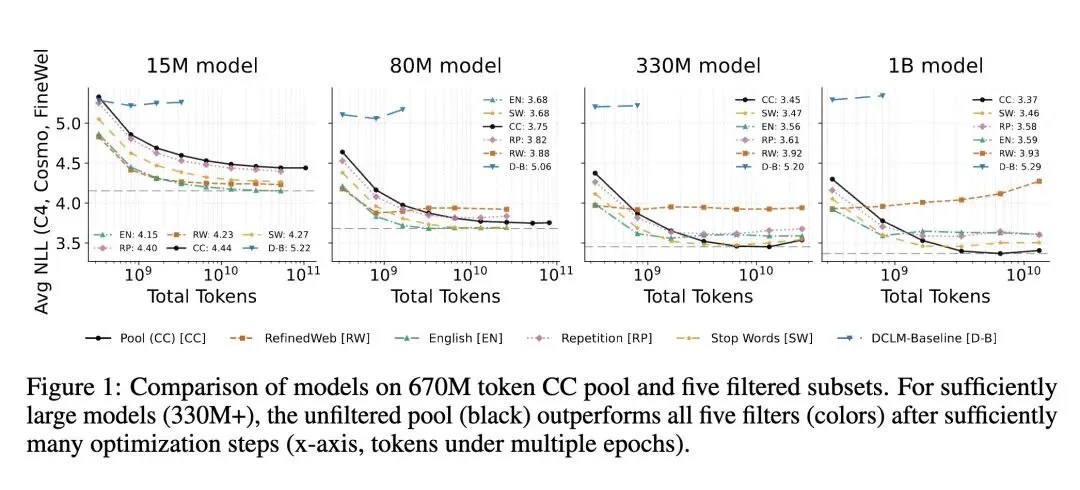
3、[AI] Agent Security is a Systems Problem
M Christodorescu, E Fernandes, A Hooda, S Jha…
[Google & University of California San Diego]
智能体安全本质上是一个系统性工程问题
要点:
挑战了AI安全领域占据主导地位的“以模型为中心”的范式,指出由于大语言模型固有的非决定论性质和意图的模糊性,试图通过对齐(Alignment)让模型变得绝对鲁棒在根本上是行不通的。 反直觉的洞见:堆叠基于机器学习的护栏(如输入/输出分类器)并不能构成真正的“纵深防御(defense-in-depth)”,因为这些模型共享相同的统计失效模式;能欺骗Agent的攻击,大概率也能欺骗负责监控它的AI护栏。 提出范式转移:将驱动Agent的AI模型视为根本上“不可信的组件(untrusted component)”,并借鉴几十年来传统系统安全的研究成果,在外部系统层面强制执行安全不变量。 识别出“语义鸿沟(Semantic Gap)”是核心脆弱性:与拥有清晰抽象层(内核⇔进程⇔网络)的传统操作系统架构不同,Agent将高级的自然语言意图直接坍缩为低级的工具调用,这使得传统的安全策略执行变得异常困难。 指出“标签爆炸(Label Explosion)”是将信息流控制(IFC)应用于LLM时的关键阻碍。当LLM处理混合输入时,在模型内部追踪数据来源会导致每个输出都被打上所有输入的标签,从而使追踪失去意义。 分析了11个真实的Agent攻击案例(如ChatGPT间谍软件、Claude DNS数据外泄),证明这些现代AI漏洞本质上是经典的系统漏洞(如缓冲区溢出或权限提升),根源在于缺乏“完全中介(Complete Mediation)”和“安全信息流”等传统安全原则。 勾勒了Agent安全的三个开放性核心研究挑战:(1)在上下文窗口中可证明地分离指令与数据;(2)从模糊的自然语言中可验证地生成正式的最小权限策略;(3)兼容LLM的信息流控制(IFC)。
主旨: 本文提出,Agent(智能体)的安全不应仅仅依赖于提升底层AI模型自身的鲁棒性,而必须被视为一个“系统工程”问题。研究者呼吁改变现状,应将LLM作为一个不可信的黑盒组件,并在其外围构建类似于传统操作系统和网络安全的架构,通过严格的系统级机制(如指令与数据分离、可验证的安全策略、信息流控制)来确保Agentic系统的整体安全。
创新:
视角的颠覆性转换:从“修补模型(Model-centric)”转向“系统防御(System-centric)”,提出不再强求LLM本身绝对安全,而是通过外部系统架构来容忍LLM的不可靠性。 引入异构强制执行(Heterogeneous Enforcement):明确反驳了当前流行的“用AI监督AI”的安全思路,创新性地提出防御机制必须是异质的(例如确定的系统沙箱配合形式化验证),以打破纯AI防御中共享统计缺陷的致命弱点。 传统安全理论的AI重构:创造性地将计算机科学中经过时间检验的经典原则(如W⊕X指令数据分离、可信计算基TCB、信息流追踪IFC)映射到基于自然语言交互的Agent环境中。
贡献:
理论框架映射:系统性地将现有的Agent安全威胁映射到传统计算机安全原则(如最小权限、TCB防篡改、完全中介、安全信息流)的缺失上。 实证实证分析:收集并深度剖析了11个具有代表性的真实世界Agent攻击案例,为系统安全视角的必要性提供了无可辩驳的实证支持。 定义未来研究路线图:为AI安全社区指明了三个高度具体且极具挑战性的研究方向(指令与数据分离的数学定义与实现、自然语言到形式化策略的自动翻译与验证、大模型内部的因果/机制可解释性信息流追踪)。
提升:
防御的确定性与可靠性:相比于基于提示词工程或模型微调的概率性防御,系统级防御能够提供更加确定(甚至可形式化验证)的安全边界,大幅提高了攻击者突破系统的门槛。 抵御自适应攻击的能力:由于不依赖于底层模型的统计分布,该方法能够有效抵御那些专门针对模型弱点进行优化的对抗性攻击(如通用提示词注入和越狱)。
不足:
缺乏具体的落地实现方案:本文主要是一篇立场/愿景论文(Position Paper)。虽然提出了宏大的蓝图和解决方向,但对于如何真正实现“在上下文中分离指令与数据”或“解决LLM标签爆炸”等核心难题,尚未提供可以直接部署的技术方案。 可用性与安全的权衡(Trade-off)挑战:在传统系统中强制执行最小权限和信息流控制往往会牺牲系统的灵活性。对于以“自主适应未知环境”为卖点的Agent来说,过于严格的系统边界可能会严重削弱其智能性和实用性,如何平衡这一点论文并未深入展开。
心得:
“用魔法打败魔法”是死胡同:业界目前非常热衷于用一个小模型去监控大模型的输出(Guardrails),本文极其敏锐地指出这是无效的“伪纵深防御”。因为如果黑客找到了攻破主模型的对抗性特征,这个特征大概率也会击穿监控模型。真正的安全必须跨越范式,引入非统计学的、确定性的物理或逻辑隔离。 AI时代的操作系统雏形正在孕育:现在的Agent开发就像在没有操作系统的裸机上写代码,不仅高低层逻辑混杂,而且缺乏权限隔离。本文提出的“语义鸿沟”问题,实质上是在呼唤一个“Agent OS”的诞生——我们需要为LLM设计出类似Ring 0/Ring 3的特权级别、文件系统沙盒以及网络栈防火墙。 温故而知新,经典永不过时:当面对提示词注入这种看似全新的AI攻击时,如果将其本质剥离,它其实就是20年前在Web安全中泛滥的SQL注入,或者是更早的缓冲区溢出(将数据当成指令执行)。面对狂飙突进的AI技术,安全研究者不应恐慌,而应从20世纪70年代的Saltzer和Schroeder安全原则中汲取智慧。
一句话总结: 不要再奢望把大模型训练得绝对安全,真正的Agent安全之道在于接受模型的不可靠性,并用传统计算机系统的隔离、沙箱和权限控制原则,为这个“聪明的黑盒”打造一套坚不可摧的外部枷锁。
We take the position that agent security must be approached as a systems problem: the AI model powering the agent must be treated as an untrusted component, and security invariants must be enforced at the system level. Through this lens, efforts to increase model robustness (the dominant viewpoint in the community) are insufficient on their own. Instead, we must complement existing efforts with techniques from the systems security domain. Based on our experience as cybersecurity researchers in operating systems, networks, formal methods, and adversarial machine learning, we articulate a set of core principles, grounded in decades of systems security research, that provide a foundation for designing agentic systems with predictable guarantees. As evidence, we analyze eleven representative real-world attacks on agents and discuss how systems principles, if realized, could have prevented these attacks. We also identify the research challenges that stand in the way of implementing these principles in agents.
https://arxiv.org/abs/2605.18991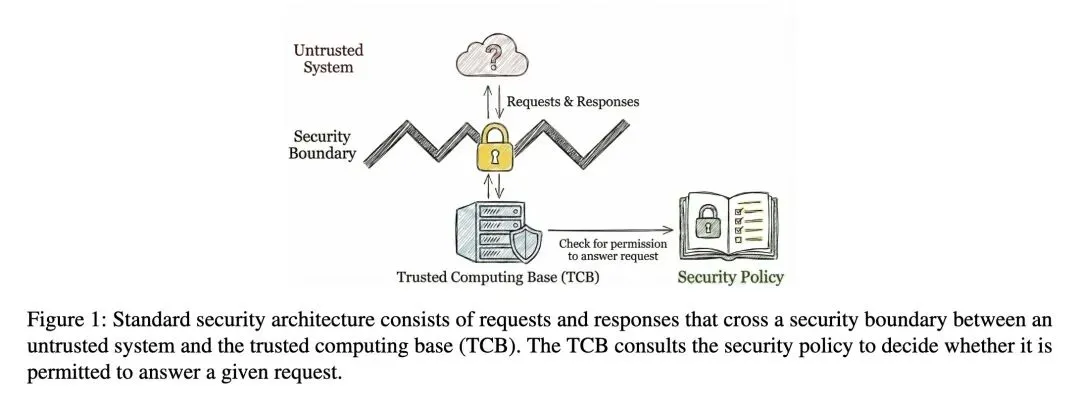
4、[LG] Optimal Reconstruction from Linear Queries
Y Filmus, S Moran, E Nesterova
[Technion – Israel Institute of Technology]
线性查询下的最优重构
要点:
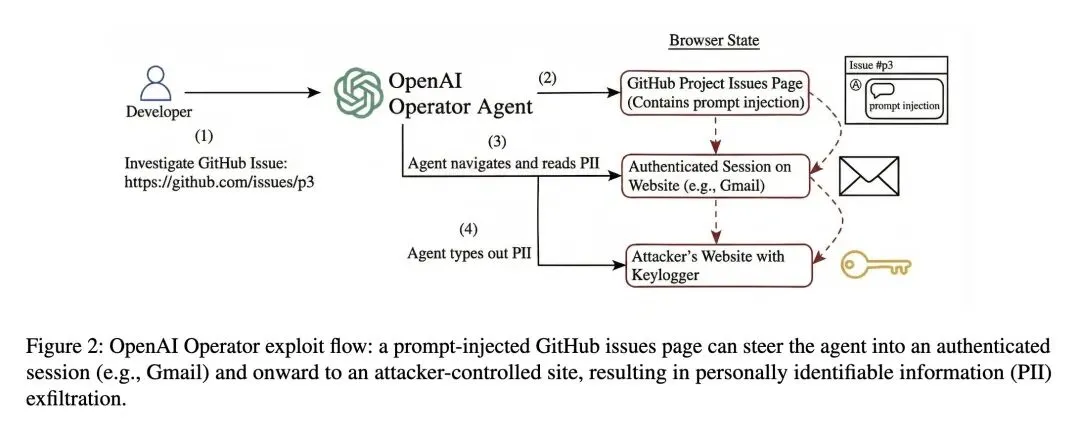
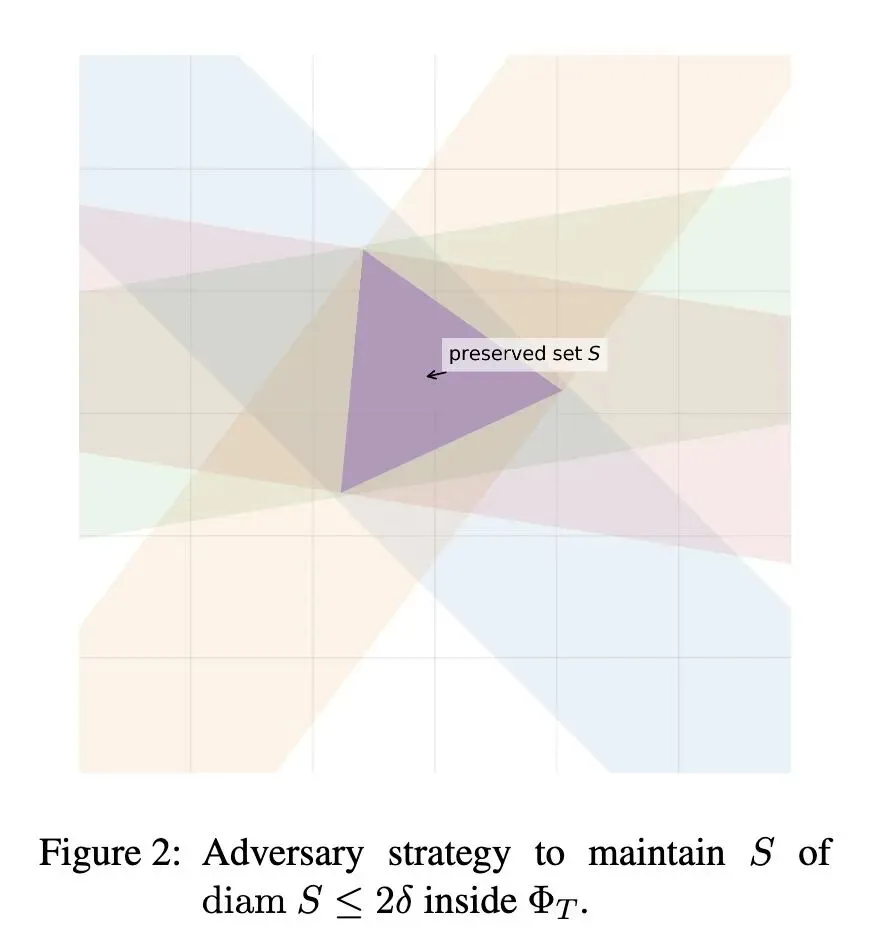
形式化了一个基础理论问题:在高维空间()中,使用 次自适应选择的线性查询,在存在对抗性噪声参数 的情况下,重构隐藏点的最优极小化极大(minimax)重构误差是多少? 确立了精确的渐近最优误差:随着查询次数 ,最优重构误差精确收敛于 。这个值在这个设定下扮演了类似于“贝叶斯最优误差”的角色。 证明了双重指数级的收敛速度:在固定维度 下,超额误差(即第 步的误差与渐近极限之间的差距)以双重指数级 的速度衰减,这种极快的收敛速度在学习理论中非常罕见。 发现了查询预算与维度的相变现象:为了使超额误差趋于零,查询次数 必须随维度 呈超指数级增长()。亚指数级的预算()将彻底失败。 证明了“鲁棒的容(Jung)定理”作为核心技术贡献:经典的容定理限制了给定直径集合的切比雪夫半径,而这个鲁棒版本刻画了“近乎极值”的集合,证明了那些导致近乎最大半径的子集必须紧密聚集在一个单一正单纯形(regular simplex)的顶点周围。 引入了“非真(improper)”重构变体:如果目标不是输出 中的一个点,而是输出一个预测未来查询答案的函数,那么最优渐近误差将下降到精确的 (小于 ),但收敛速度会从双重指数级大幅减慢到仅有极快的收敛速度多项式级别。
主旨: 本文从理论计算几何和交互式学习的角度,研究了如何通过带有对抗性噪声的线性查询(内积)在 空间中重构一个未知点。论文旨在精确刻画最优重构误差与查询次数 、空间维度 以及噪声参数 之间的函数关系,并揭示其收敛极限及收敛速率。
创新:
引入并证明了“鲁棒的容定理(Robust Jung's Theorem)”:这是本文最大的技术创新。传统的Jung定理是静态的界限,而本文的鲁棒版本刻画了处于极值边界的几何体的结构刚性(Structural Rigidity),为设计极其高效的自适应查询算法提供了理论基石。 发现了罕见的“双重指数级”收敛速度:在传统的学习曲线中,误差通常以多项式或指数级衰减,而本文证明了通过“预处理+自适应精化”的两阶段策略,可以将超额误差在每一步进行平方级缩小,从而实现双重指数级收敛。 真(Proper)与非真(Improper)重构的严格对比:创新性地提出了不输出具体点而是输出预测函数的“非真重构”模型,并揭示了它们在渐近极限值和收敛速度上截然相反的权衡(Trade-off)。
贡献:
精确给出了无限次查询的误差极限:证明了无论如何查询,重构误差的下界为 。 解决了固定维度下的收敛率问题:不仅证明了误差可以无限逼近上述极限,还给出了严格匹配的双重指数级上下界。 揭示了“维度灾难”的精确阈值:证明了需要指数级 的查询次数才能让超额误差消失,低于此阈值的查询将导致误差随维度发散。 几何与李群(Lie Group)方法的交叉应用:在证明鲁棒Jung定理时,巧妙地结合了Minkowski和(Minkowski sum)、豪斯多夫距离(Hausdorff distance)以及欧几里得运动群(Lie Algebra)的技术,丰富了理论计算机科学的数学工具箱。
提升:
相比于以往只关注“能否重构”或给出松散的渐近界限的工作(如微分隐私中的统计查询),本文给出了在对抗噪声下重构精度的绝对理论极限(Bayes-optimal error)。 将收敛速度的分析从常见的渐近多项式/单指数级别,提升到了极其精确的双重指数级别(在固定维度下)。
不足:
维度的指数级爆炸:算法和理论分析中,查询次数 必须达到 才能进入双重指数衰减的“精化阶段”,这意味着该方法在真正的高维场景(如 )中缺乏计算和采样上的可行性。 要求噪声必须绝对有界:模型假设所有的对抗噪声都严格被 限制,没有任何异常值(Outliers)。如果允许极少数的答案完全错误(即被破坏的答案),文中的几何交集(可行域)将会变成空集,算法会失效。 未探讨非自适应(Non-adaptive)查询的极限:文中的极快收敛完全依赖于上一轮的结果来选择下一轮的查询方向。如果在开始前必须一次性提交所有查询,其最优误差和收敛率尚不清楚。
心得:
自适应性的巨大威力:双重指数级的收敛速度让人惊叹。这揭示了一个深刻的道理:如果你的查询可以根据当前的“不确定性集合(可行域)”进行最优化调整(文中是去查询单纯形的边),那么排除错误假设的速度会比盲目采样快得不可思议。 非真学习(Improper Learning)的奇妙权衡:如果放弃寻找那个“真实的点”,而只是试图完美回答未来的问题(输出一个预测函数),你能达到的极限误差会更小(从 降到 )。但是!你到达这个极限的速度会慢得多(多项式 vs 双重指数)。这就像是:追求实用(预测答案)的上限更高,但追求本质(找到坐标)的收敛更快。 纯粹数学工具对算法理论的降维打击:为了证明一个算法的下界和收敛性,作者动用了拓扑学中的豪斯多夫距离和李代数(Lie Algebra)来分析单纯形的旋转。这提醒我们,在很多机器学习的深层理论中,一旦涉及到高维空间的结构刚性,现代几何和代数工具是不可或缺的。
一句话总结: 本文在理论上彻底解决了带有对抗噪声的线性查询重构问题,不仅精确找出了如同“贝叶斯最优”的误差理论极限,还利用创新的“鲁棒容定理(Robust Jung's Theorem)”证明了通过自适应查询,超额误差可以实现极其罕见的双重指数级衰减。
We study the problem of reconstructing an unknown point in ℝd from approximate linear queries. This setting arises naturally in applications ranging from low-dimensional remote sensing and signal recovery to high-dimensional data analysis and privacy-sensitive inference. Our main goal is to characterize the optimal reconstruction error as a function of the number of queries T, the ambient dimension d, and the noise parameter δ. We first analyze the limit T→∞ and show that the optimal reconstruction error converges to the explicit value 2d/(d+1)‾‾‾‾‾‾‾‾‾‾√δ, which plays a role analogous to the Bayes optimal error in supervised learning. When the dimension is fixed, we show that the excess error above this limit decays doubly exponentially fast as T→∞, a rate that is significantly faster than those typically encountered in learning curves. When the dimension grows, we show that a number of queries on the order of exp(d) is necessary and sufficient to achieve vanishing excess error. Finally, we introduce and analyze an improper variant of the reconstruction problem. From a technical perspective, our main contribution is a generalization of Jung's theorem (1901). The classical theorem bounds the maximum possible radius of a set of diameter 1 and characterizes extremal bodies. Our generalization provides a robust variant that characterizes near-extremal bodies and is proved via geometric and dynamical arguments exploiting symmetry and Lie group actions.
https://arxiv.org/abs/2605.19625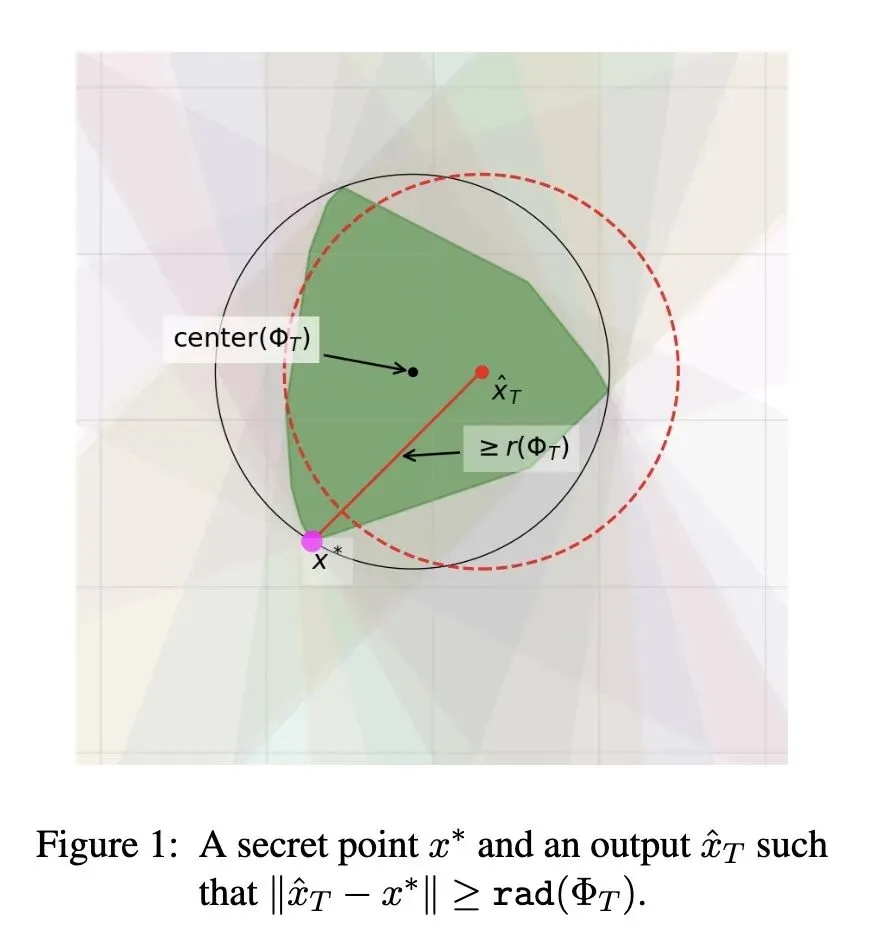
5、[LG] Density-Ratio Losses for Post-Hoc Learning to Defer
A Soen, R Thobaben, J Jaldén, R Nock
[KTH & Google Research]
基于密度比损失的事后学习推迟方法
要点:
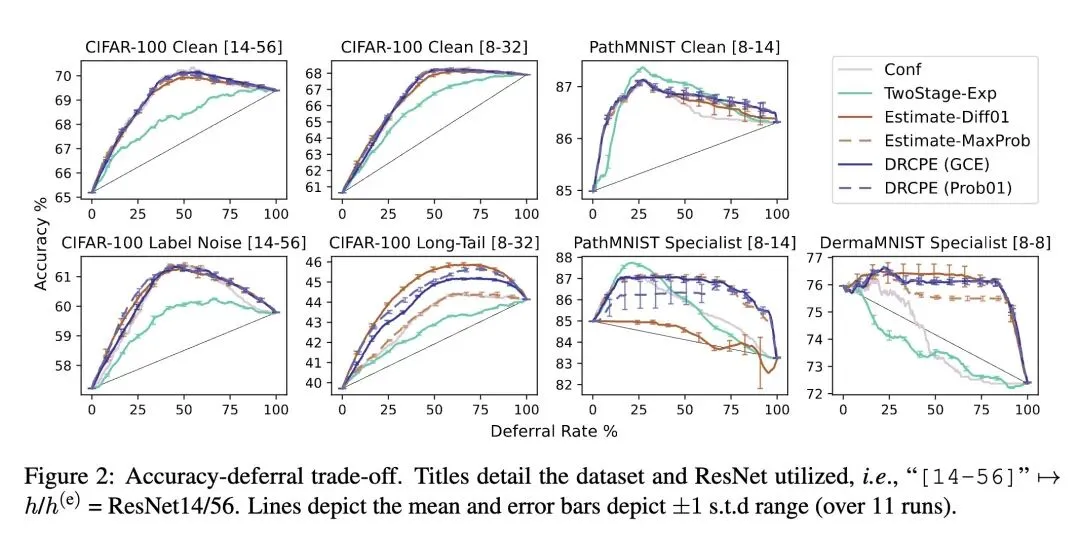
聚焦于“事后延迟学习(post-hoc Learning to Defer, L2D)”,即基础模型已经训练完毕并冻结,目标是在不重新训练基础模型的情况下学习一个延迟规则(何时将输入交给专家处理)。 引入了一种新的分布视角:通过基础模型和专家模型的“理想分布(ideal distributions)”之间的密度比(density-ratio)来定义延迟。 “理想分布”被定义为对原始数据分布进行散度正则化重加权后的分布,在该分布下特定模型能取得极低的损失。 区分了“边缘(marginal,仅关于X)”和“联合(joint,关于X和Y)”理想分布。 证明了对于KL散度,对边缘理想分布的密度比进行阈值化,可以完美还原经典的Chow最优拒绝规则。 反直觉地指出,对联合理想分布的密度比进行阈值化,等价于在一个“专家倾斜(expert-tilted)”的后验分布下执行Chow规则。这个倾斜分布会根据专家的表现好坏来转移概率质量,从而自然地将专家的比较优势融入到延迟决策中。 将延迟学习问题形式化为密度比估计(DRE)问题,在实践中通过将其归约(reduction)为二元类概率估计(CPE)任务来求解(即“DR CPE Loss”)。 提出的DR CPE方法将学到的打分器(scorer)与延迟阈值分离开来,使得从业者可以在测试时轻松调整延迟率,而无需重新训练模型。 实证表明,DR CPE方法在竞争中不输于最先进的基线方法,并且在各种受损数据集设置(如标签噪声、长尾分布、专家特化分布)下展现出显著更强的鲁棒性。 在事后L2D、经典拒绝理论(Chow规则)、专家比较回归目标以及异常检测之间建立了深厚的理论联系。
主旨: 本文从“理想分布(Ideal Distributions)”的独特视角,研究了事后延迟学习(post-hoc L2D)问题。通过对比基础模型和专家模型在各自理想分布下的密度比,作者提出了一种新的延迟决策规则,并通过密度比估计到类概率估计(DRE to CPE)的归约,推导出了用于训练打分器的 DR CPE 损失函数,使得模型能够在不重新训练的前提下,灵活且鲁棒地决定何时将预测任务交由专家处理。
创新:
概念创新:首次将 L2D 问题转化为计算两个模型(AI与专家)各自“理想分布”的密度比问题。 理论视角:揭示了基于“联合理想分布(Joint Ideals)”的密度比等价于在“专家倾斜后验(Expert-tilted Posterior)”下做决策。这意味着模型不仅仅看自己有多不确定,还会看专家在这个不确定区域是否真的更擅长。 优化方法:巧妙地利用了统计学中从密度比估计(DRE)到类概率估计(CPE)的归约技术,将一个复杂的分布间比较问题,转化为一个极其容易优化的二元分类损失函数(DR CPE Loss)。 解耦设计:将打分器(Scorer)的学习与延迟阈值(Threshold)的设定完全解耦,实现了“一次训练,动态调整延迟率”。
贡献:
理论框架:构建了一个基于散度正则化和理想分布的统一数学框架,桥接了经典的 Chow 拒绝规则、现代专家比较方法以及异常检测理论。 算法提出:推导并提出了具有实际可操作性的 DR CPE 损失函数系列。 鲁棒性验证:在多个具有挑战性的医学和视觉数据集(包含长尾、标签噪声、子群体特化)上进行了全面实验,证明了该方法比现有两阶段基线方法具有更强、更稳定的性能界限。
提升:
相比于简单的置信度阈值法(Confidence-based),该方法显式地建模了专家的能力,避免了将任务交给“连专家也不会做”的区域。 相比于直接回归专家优劣差值的方法(Expert-comparison regression),该方法在数据分布发生偏移(如长尾、特化)时表现出极强的鲁棒性,有效避免了灾难性的性能崩溃(如实验中基线在特化数据集上的失效)。 提高了工程实用性,由于是事后(post-hoc)方法且阈值可调,非常适合无法微调的大型预训练模型部署。
不足:
缺乏一致性保证:该方法目前主要通过经验和分布推导得出,尚未像部分基于代理损失(Surrogate loss)的 L2D 方法那样,提供严格的统计一致性(Consistency)理论保证。 温度超参数敏感:虽然无需在训练时预设延迟率,但方法中的散度正则化参数 (温度)依然会对最终性能产生不可忽视的影响,可能需要针对不同数据集进行繁琐的验证集调参。 专家成本建模的局限:目前的框架主要处理单一专家的简单二元决策。如果扩展到“多专家”或者“考虑专家查询的不同财务/时间成本”,框架的适应性有待进一步推导。
心得:
“倾斜后验(Tilted Posterior)”极其优雅:这篇论文最妙的设计在于,它没有生硬地把模型的误差和专家的误差做减法,而是推导出了一个“专家倾斜”的分布。这意味着,“延迟”不应该仅仅发生在我不会做的时候,而是应该发生在我不会做、且专家大概率会做的时候。这非常符合人类社会分工的直觉:你不会把难题推给一个同样不会解题的同事。 降维打击的归约技巧(Reduction):论文展示了高超的数学品味。计算两个虚拟的“理想分布”的密度比听起来是个无法落地的计算噩梦。但作者利用 DRE ⇔ CPE 的等价性,直接把它变成了一个极其普通的二分类 Loss(用 Sigmoid/Logistic 等跑一下就行)。这提醒我们,在做机器学习理论设计时,找到一个高阶概念到基础任务的映射(Reduction)是算法落地的关键。 事后诸葛亮(Post-hoc)是大势所趋:随着大模型(LLMs / Foundation Models)越来越庞大,要求在预训练时就把“是否拒绝”学进去(End-to-End L2D)变得极不现实。这种只训练一个轻量级“路由/打分器”的事后方法,不仅成本低,而且随时可以拔插更换专家,这绝对是未来 AI 工程化落地的核心范式。
一句话总结: 本文提出了一种新的事后延迟学习方法,通过计算模型与专家的“理想分布”密度比来决定是否让专家接手,并利用二元分类归约技术推导出易于优化的 DR CPE 损失,在不重新训练大模型的前提下,实现了高度鲁棒且延迟率动态可调的智能人机协作决策。
We study post-hoc Learning to Defer (L2D) through the lens of ideal distributions: divergenceregularized reweightings of the data distribution under which a model attains low loss. We define deferral via the density-ratio between a model’s and an expert’s ideals. Using the reduction from density-ratio estimation to class-probability estimation, we derive the DR CPE losses for post-hoc L2D scorers. Deferral decisions are then made by thresholding the scorer, allowing deferral rates to be adjusted without retraining. For KL-based ideal distributions, our deferral rules recovers Chow’s rule under the original distribution and a connection to an expert-tilted Bayes posterior—which incorporates the expert’s performance—depending on if the ideal distributions are joint or marginal distributions. Experimentally, our approach is competitive compared to common baselines and more robust across dataset settings. More broadly, our results cast post-hoc L2D as density-ratio learning between ideal distributions, bridging Chow-style rules, expert comparison, and elucidating connections to related learning settings including anomaly detection.
https://arxiv.org/abs/2605.19557