夜雨聆风
夜雨聆风链接:https://pan.baidu.com/s/15r0rLWkJlcecUvBPKZo_MQ?pwd=mnsj提取码:mnsj
https://www.mizhushare.com/docs/
在数据处理时,我们经常会遇到这样的场景:手里样本数据的平均值,和某个“标准值”或者“理论值”到底有没有显著差异?例如:
某工厂生产的零件平均长度是否符合国家标准?
某班级学生的平均身高是否高于全国平均水平?
某款新饮料的含糖量是否真的如包装所说的只有5g?
这种用来检验“样本平均值”与某个“已知的或假设的数值”之间是否存在显著差异,就是单样本t检验的用武之地,它是SPSS中最基础、最常用的统计方法之一。
单样本 t 检验:
简单来说,单样本 t 检验是用来推断样本均值与已知总体均值(通常是一个常数或标准值)之间是否存在显著性差异的统计方法。
需要注意的是,该方法理论上要求数据服从或近似服从正态分布。不过t检验其实很“皮实”(稳健),只要不是极端偏态,通常都没问题。若数据非正态,可考虑非参数检验。

一、加载数据:
该数据为某汽车刹车盘工厂的质量控制数据,记录了8台机器各生产的16个刹车盘直径信息。
本次将使用单样本t检验来检查汽车刹车盘的生产是否达标,即查看8台机器各生产的16个刹车盘的平均直径是否与生产标准(322mm)存在显著差异。
二、拆分文件:
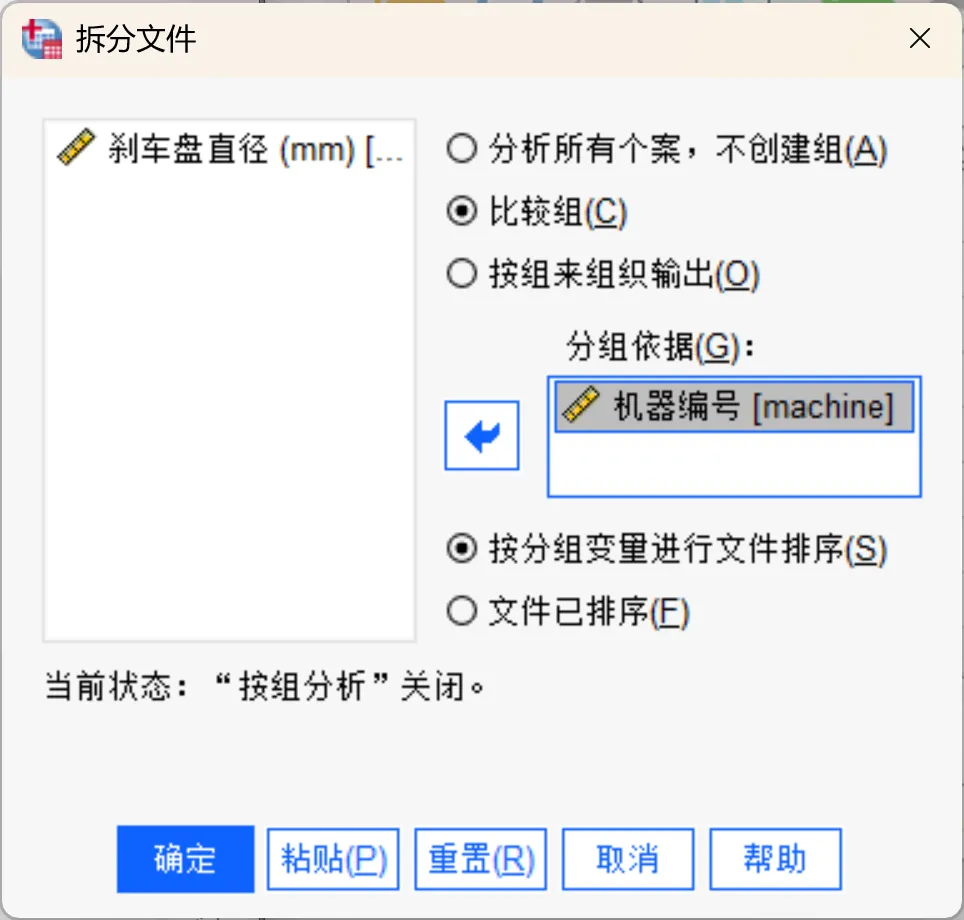
示例数据中包含8台机器的数据,因此在统计分析之前需使用标识机器编号的「machine」的变量,将文件拆分为不同的组,以便将每台机器的数据作为独立的样本进行分析。
点击顶部菜单栏的【数据→拆分文件】,根据机器编号(machine变量)进行文件拆分,具体内容可以参考以下文章:
三、t检验:
点击顶部菜单栏的【分析→比较平均值和比例→单样本t检验】,在打开的对话框中进行相应设置。
检验变量:选择一个或多个变量,以针对相同的检验值进行检验。
检验值:就是“标准答案”或“目标值”。本次为322mm。
估算效应大小:勾选该选项后,将会输出t检验效应值。
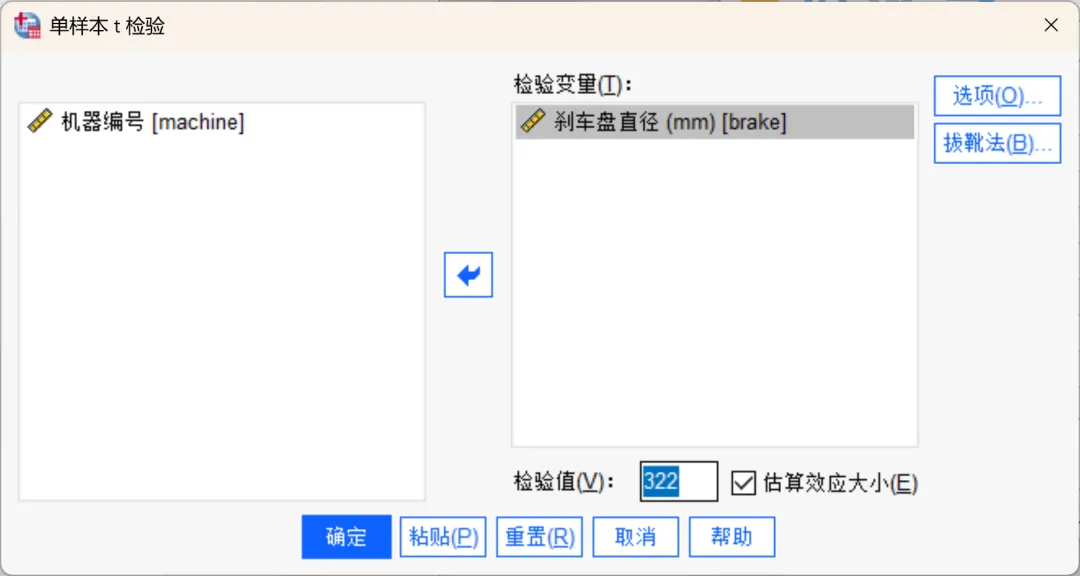
点击「选项」按钮,在打开的选项对话框中可指定用于判断这种差异的置信水平(本次设置为90)以及缺失值的处理方式。
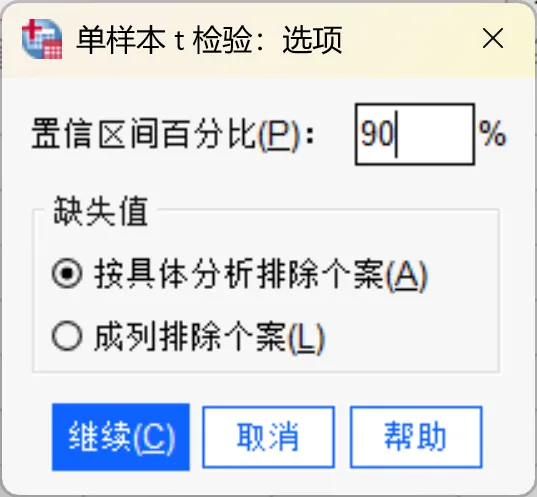

系统会为每个检验变量生成一系列描述性统计表。
输出结果一:
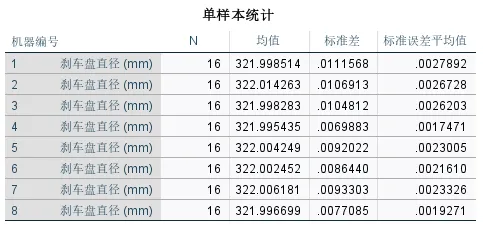
输出结果二:
t 列:显示了每个样本的观测 t 统计量,反映样本均值偏离标准值的程度。该值等于“均值差”除以“样本均值的标准误”。
自由度:通常情况下等于每组的个案数(样本量)减 1。
显著性:显示了基于自由度为15的t分布得出的概率值,也就是我们常说的P值。通常使用0.05(95%置信区间)或0.10(90%置信区间)作为判断显著性的临界值,如果该值小于临界值,表示拒绝原假设(样本均值与总体均值无差异),即说明差异是显著的。
平均值差值:通过用每个样本均值减去检验值(本例中为322)得到。
差值的90%置信区间:总体真实差值可能存在的范围。
本次示例中,由于机器 2、5 和 7 的置信区间完全位于0之上且p值小于0.1(90%置信区间),可以肯定地说,这些机器生产的圆盘平均直径显著大于322mm。同样,因为机器4的置信区间完全位于0之下且p值小于0.1,所以该机器生产的圆盘直径偏小。
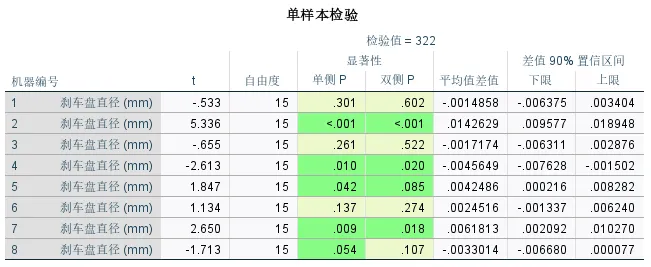
输出结果三:
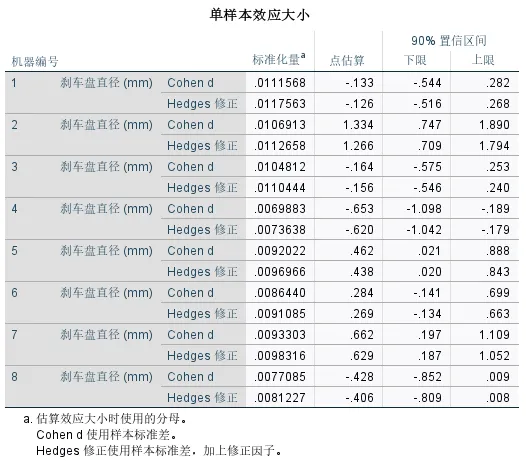
标准化量:Cohen's d和Hedges修正是衡量效应大小的两个指标。其中,Cohen's d是最常用的标准化均值差异指标;当样本量较小时,Cohen's d往往会略微高估真实的效应大小,Hedges修正后的数值通常比Cohen's d稍小一点,它提供了更保守、更准确的估计。因此在样本量较小时,建议优先报告Hedges修正值。 点估算:效应大小的具体数值。正数表示样本均值大于检验值(目标值),负数表示样本均值小于检验值。通常认为该值绝对值在0.2左右表示小效应(差异微弱),在0.5左右表示中等效应(差异中等),在0.8以上表示大效应(差异非常显著,具有实际意义)。 90%置信区间:效应大小真值可能存在的范围。
本次示例中,机器2、5和7的效应值均较高,且置信区间完全在0以上,说明这些机器生产的刹车盘直径显著大于目标值;机器4的效应值也较高,但置信区间完全在0以下,说明该机器生产的刹车盘直径显著小于目标值。这也验证了之前得到的结论,但是通过该表可以发现机器2的问题最严重,偏差极大,需立即检查。