AI 的成本,很多时候不是花在“不会做事”,而是花在“说得太多”。 一次回答几百、上千个 token 很常见;如果再叠加多轮沟通、上下文回灌、多人协作,成本会继续往上叠。 今天这个工具:Caveman,做的事很直接,让 AI 少说废话,但别少说重点。它不改模型脑子,主要压缩表达层。按项目公开 benchmark 来看,输出 token 在不少场景里能明显下降,平均大约能省60%左右。 先看效果:同样一句话,为什么成本会差这么多 普通模式下,AI 可能会这样解释一个 React 组件为什么反复重渲染: 引用: 你的 React 组件之所以重渲染,很可能是因为你在每次渲染时都创建了一个新的对象引用。当你把内联对象作为 prop 传递时,React 的浅比较会认为它每次都是新对象,于是触发重新渲染。建议你使用useMemo来缓存这个对象。
而在Caveman模式下,同样的意思会被压成这样: 引用: 每次 render 都新对象。inline object prop = new ref = re-render。用useMemo。
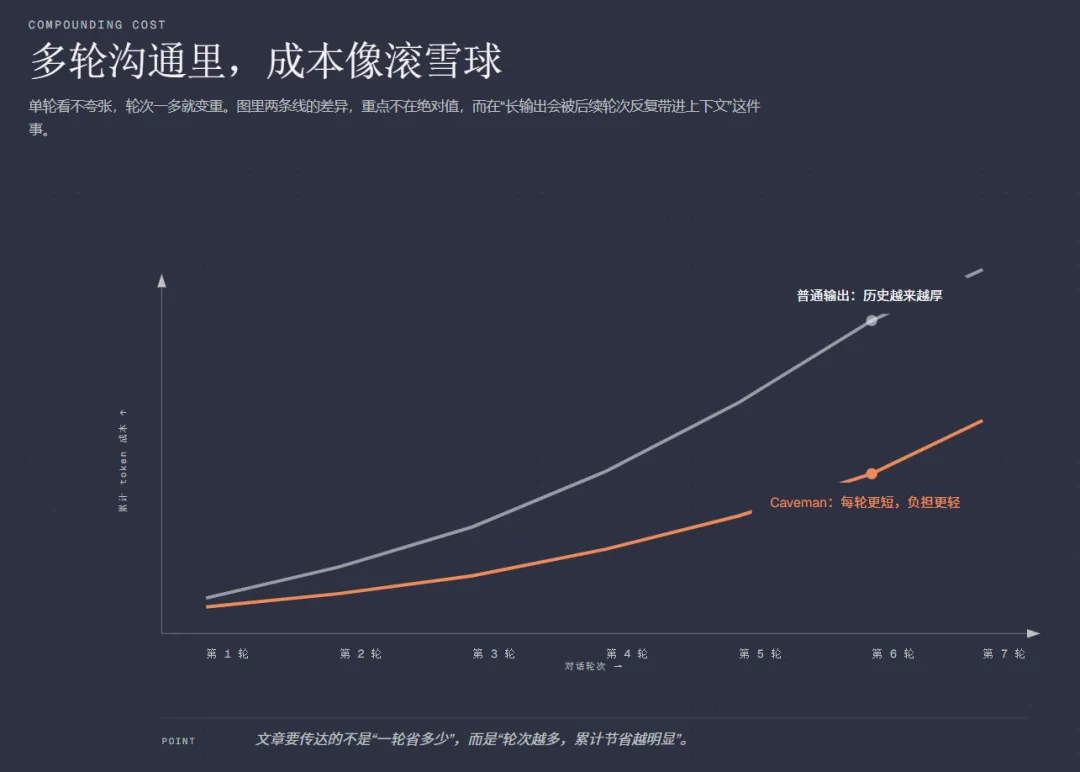
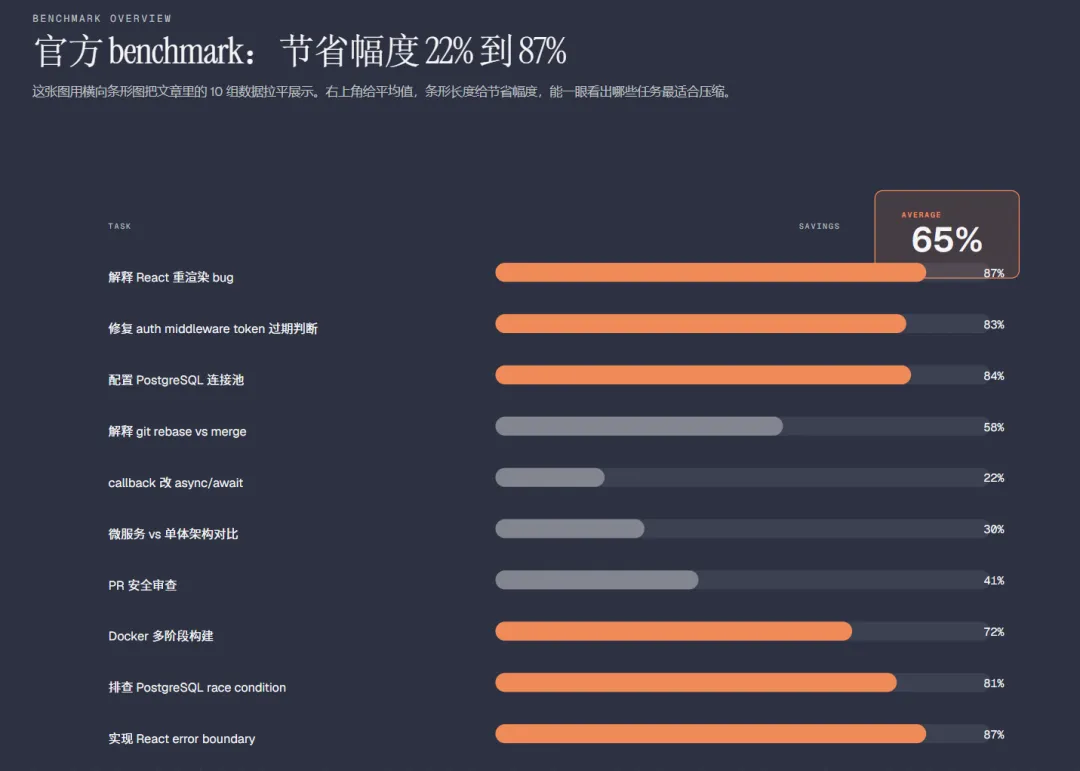
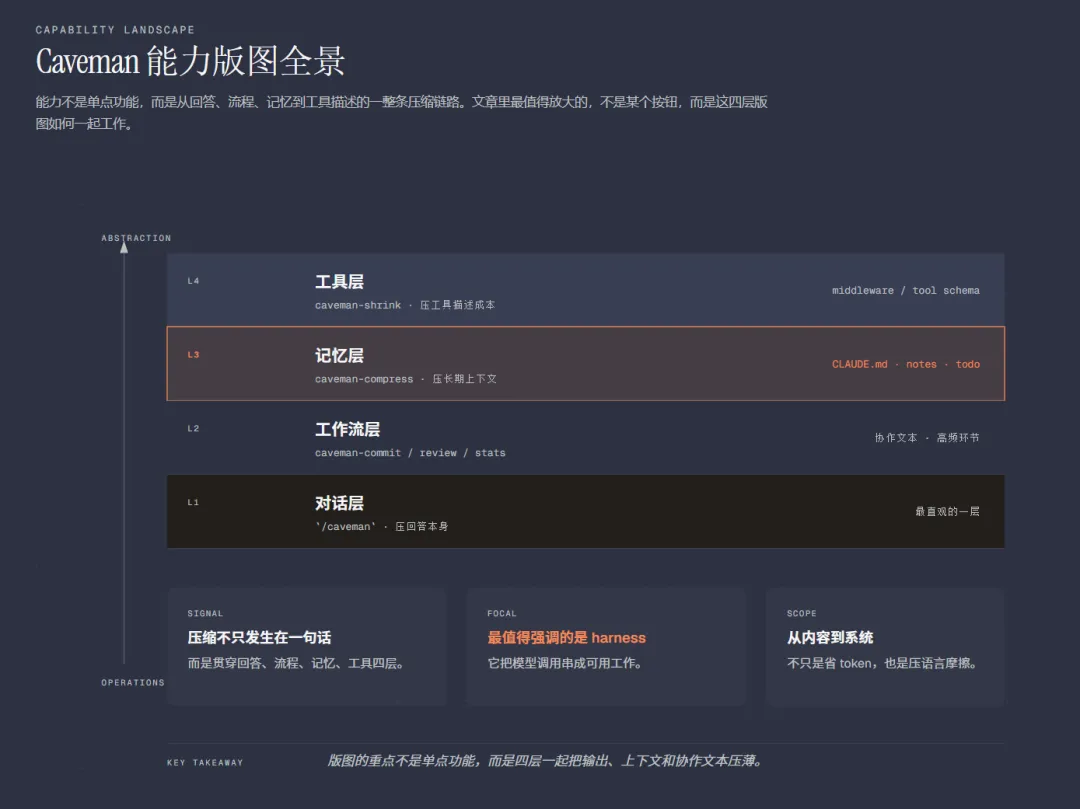
看起来只是“说短了”,但对按 token 计费的系统来说,差别很实际。项目 README 里给出的一个对比是:同类说明从69 token压到19 token。信息没丢,废话少了。 随着沟通轮次增加,省钱效果会更明显 很多人以为 AI 成本是“问一轮,付一轮”。但真实情况更像是:每一轮长回答都会被后续轮次继续带进上下文,轮次越多,历史包袱越重。 Caveman的价值就在这里:它先把每一轮里的冗余压掉,所以轮次越多,累计节省越明显。它省的不只是当前输出,还包括后续上下文膨胀之前那部分本可以不发生的成本。 更多官方数据对比:项目 README 里公开了什么 根据Caveman项目 README 公开的 benchmark,作者列出了 10 组任务对比。结论很直接:平均输出压缩约 65%,不同任务的节省幅度在22%到87%之间。 这些数据说明三件事:Caveman的节省可以量化;解释型、分析型、复述型任务压缩更明显;它压的主要是输出 token,不是 reasoning token。也就是说,它不是削思考能力,而是压表达层。 Caveman 到底是什么 Caveman可以理解成一个给 AI coding agent 用的“高密度表达工具”。 自然语言对人类很友好,但对高频 agent 协作来说,往往太啰嗦。 它压掉的不是语义骨架,而是语言包装层。看起来像“说话变糙了”,但在工程协作里反而更高效。 它的核心模式有哪些 1.lite 轻压缩模式。会去掉明显的废话和客套,但整体还保留比较自然的句子结构。 2.full 默认核心模式。压缩更明显,表达更紧凑,更像“工程协作语言”。 3.ultra 极限压缩模式。能缩则缩,甚至会大量使用片段句、缩写和箭头表达因果。 4.wenyan 中文压缩路线。它还有更细的分支,比如wenyan-lite、wenyan-full、wenyan-ultra,会往更高密度的中文表达去走。 能力版图与前景:它不只是“把回答变短” 如果只把Caveman理解成“让 AI 说话更短”,其实有点低估它了。 从当前项目已经公开出来的能力结构看,它更像是一套面向 agent 的压缩基础设施。能力版图大致可以分成 4 层。 1. 对话层:压缩回答本身 这是最直观的一层。也就是/caveman最核心的工作:减少冗长输出,保留关键语义。 2. 工作流层:压缩 commit、review、状态反馈 这意味着它不只是“压回答”,而是在压缩整个技术协作流程里的常见文本环节。 3. 记忆层:压缩长期上下文 像caveman-compress这类能力,针对的是CLAUDE.md、项目笔记、待办列表、长期记忆文件。 这层能力很关键,因为很多 token 不是浪费在“当前回答”里,而是浪费在每次开局都要重新带上的长背景里。项目 README 里给出的数据是,这类记忆文件平均还能压掉约46%。 4. 工具层:压缩 agent 与工具之间的描述成本 像caveman-shrink这类能力,会往 MCP middleware 的方向延伸,去压缩工具描述本身。 这件事很重要。agent 不只是和人说话,还和工具、子 agent、规则文件说话;这些地方一旦都变短,长期节省会更扎实。 所以它真正有意思的地方在于:它不是在优化一条回答,而是在优化整个 agent 工作流里的语言成本。 它为什么真能省:底层逻辑是什么 第一层:LLM 按 token 计费 字越多,token 越多。token 越多,成本越高。 第二层:自然语言本来就有大量冗余 礼貌、过渡、复述、修辞、防冒犯包装、完整句连接词等 这些东西对人类交流有价值,但在高频技术协作里,很多时候并不是必要信息。 第三层:技术任务真正需要的是信息骨架 第四层:多轮协作里,冗余会复利放大 一条长回答,不只是这一轮贵。它还会成为后面很多轮的历史负担。 所以Caveman节省的不只是当前输出,还包括后续上下文越来越厚之前那部分本可以不发生的膨胀。它做的其实是两件事: 如何安装 irm https://raw.githubusercontent.com/JuliusBrussee/caveman/main/install.ps1 | iex
macOS / Linux / WSL / Git Bash curl -fsSL https://raw.githubusercontent.com/JuliusBrussee/caveman/main/install.sh | bash
项目文档说明,这个安装流程会自动检测你机器上支持的 agent,并尝试走各自的原生安装路径。整个过程大约几十秒,前提是本机已经安装Node >= 18。 如果你是Codex CLI用户,对应的安装方式是: npx skills add JuliusBrussee/caveman -a codex
从项目公开文档来看,它支持的 agent 范围很广,包括: 不同 agent 的接入方式略有差异,但总体上无非三类: 如何使用 /caveman
/caveman lite
/caveman full
/caveman ultra
/caveman wenyan
normal mode
如果你是Codex CLI这类环境,通常更接近“每个 session 手动触发一次”。而像 Claude Code、Gemini CLI、OpenClaw 这类支持更深集成的环境,可以做到更接近自动激活。 除此之外,README 里还特别强调了几类值得配合使用的能力: caveman-review:压缩 review 反馈 caveman-commit:压缩 commit message caveman-compress:压缩记忆文件和长期上下文 caveman-shrink:进一步压缩工具描述成本 如果你只是轻度用户,先从/caveman开始就够了。如果你已经进入多 agent、长上下文、重协作阶段,那后面这些能力会更有味道。 使用时要注意什么 Caveman很有用,但也不是所有场景都适合一路开到底。 1. 它不适合直接拿来写最终对外文案
它的目标是高密度协作,不是面向大众的最终表达。用它做内部协作层很合适,直接拿去做对外成品通常不合适。 2. 安全警告、不可逆操作,不要压得太狠
像删库、迁移、权限改动这类事情,清楚比短更重要。顺序被压糊了,省下来的 token 不一定够你补锅。 3. 它省的是很多输出浪费,不是所有成本
如果你的主要账单来自超长输入、超大上下文或者高额 reasoning 开销,那它不会神奇地把所有费用都砍掉。 4. 不同任务的节省幅度不一样
项目公开 benchmark 里,最低节省是22%,最高可以到87%。所以最合理的预期不是“永远固定省 60%”,而是“很多高频场景下,平均能省下一大块”。 最后 Caveman真正聪明的地方,不是把 AI 变得像原始人,而是看透了一件事:今天很多 AI 成本,并不是花在“不会做事”,而是花在“说了太多没必要的话”。当你开始高频使用 AI、长时间协作、多人协同,甚至多 agent 并行时,表达冗余就会变成持续吞预算的问题。 它压缩的不只是 token,更是 AI 工作流里的语言摩擦。很多时候,最有效的优化不是换更贵的模型,而是先让它别那么能说。 参考资料 Caveman README: https://github.com/JuliusBrussee/caveman/blob/main/README.md Caveman INSTALL: https://github.com/JuliusBrussee/caveman/blob/main/INSTALL.md
 夜雨聆风
夜雨聆风