 夜雨聆风
夜雨聆风——从奥特曼200万美元算力换股权,到阿里云修AI工厂:模型协同时代开启了?
一|模型时代,可能真的快结束了
历史的改变,经常不是轰的一声,而是某一天,几个看似无关的新闻,同时发生。
大多数人刷过去了,少数人后来才意识到:哦,时代拐弯了。
2026年5月20日,AI行业同时发生了两件事。一件在美国,据《The Information》报道,OpenAI CEO萨姆奥特曼开始向YC(Y Combinator)体系的一批创业公司提出一个新方案,提供约200万美元OpenAI算力额度,用以交换公司股权。
你没看错,不是美元,不是融资,是算力。
另一件发生在中国。同一天。在2026阿里云峰会上,阿里云一口气发布了芯片、云、模型、推理平台,再到千问云。
官方给出的名字很长:“面向Agentic时代,芯—云—模型—推理全面升级。”
很多人看到这里,第一反应可能是,阿里开发布会——大厂常规动作。
但这两件事其实都和一个问题相关:
如果未来AI开始24小时自己工作,谁来养它?
这个问题很重要。今天AI行业最大的变化,可能不是模型变聪明了,而是AI开始从“回答问题”,变成“持续工作”。
这是一个被很多人低估的转折点。
过去这两年,我们对AI的理解还停留在:问问题、写文案、做PPT、生成图片......仿佛它只是一个高级搜索引擎,或者是一个更聪明的实习生。
但今天,事情已经开始变了。阿里云峰会上有一句话,其实特别值得注意。
阿里云资深副总裁刘伟光说:Agent突破临界点之后,可以24小时不间断工作。
这句话的意思可以这么理解:过去,AI像助手;未来,AI开始像员工,而且是不用下班的员工。
你给它任务,它自己规划,自己调用工具,自己协作,自己执行,甚至自己修正错误。
官方提供了一个案例,特别夸张。
这次发布的新模型,通义千问Qwen3.7-Max,在训练时从没见过的新芯片环境下,它只靠任务说明,自主连续工作35小时,从零写出一个生产级AI计算内核,最终性能比官方版本提高了10倍。
这已经不是“帮我写一段话。”而是“帮我完成一项工作。”
很多人还在争,GPT厉害还是DeepSeek厉害,但产业真正的问题已经变了。
AI开始越来越像基础设施,就像电、云和网络。这意味着真正的竞争逻辑也在发生变化。
过去两年,整个AI行业拼的是什么?
谁模型更强,谁参数更大,谁排行榜第一。
大家像在刷奥运积分榜:今天GPT第一,明天Claude反超,后天DeepSeek炸场......
而现在,一个巨大的变化是,模型正在迅速地“商品化”。
听起来可能有点反直觉。毕竟过去两年,大家一直把大模型看作类似某种“核武器”一般的存在。就在今天凌晨,谷歌还宣布推出了Gemini 3.5系列模型,重点展示了Gemini 3.5 Flash,并称其是迄今为止最强的编程模型。
直至今日,AI界的炸场模型和踢馆速度也是令人瞠目的。
但是,回望历史,几乎所有技术都会经历这样同一个过程,从奇迹,到商品。
来看19世纪。蒸汽机先是国运,后来是工厂标配。
到了20世纪。电力先是高科技。后来变成水电煤。
回想互联网刚出来时,有网站是能力。后来变成了默认配置。
还有云计算。刚出现时,企业还在争:要不要上云?今天已经没人讨论这个问题了,因为,云已经是基础设施了。
AI模型也在走在同一条路上。
一个最明显的变化是,去年很多公司还在说,我们有自己的大模型。今年问题开始变成了:“我们怎么用模型?”甚至可能更进一步:“我们怎么组织模型?”
这是完全不同的问题。
未来的企业,很可能不是一个模型打天下,而是多个模型协同工作。
这也是OpenAI和以阿里云为代表的国内AI厂商押注的不一样的道路。
如果这个问题有点抽象,我们可以设想一下B端客户的现实场景。
一家企业通常拥有包括但不限于如下岗位:客服、法务、营销和财务。
不同岗位需要的是完全不同的能力。
客服问答的重点是便宜,那么轻量模型足够。
合同审核的重点是准确率,那么,需要上更强推理模型。
市场创意的重点则是创造力,那么相应的,可能另一类模型更强。
所以,未来企业真正的问题,已经不再是用哪个模型?而是如下这些问题:谁来组织模型?谁负责自动切换模型?谁控制token成本?谁分配推理资源?谁来协调多个Agent?谁去管理调用日志?
这也是产业逻辑开始突然转向的时候。
因为真正贵的已经不再只是训练,而是推理,也就是AI被使用的成本。
这是今天最容易被忽略的一件事。
过去很多不少人有一种错觉,以为模型做出来就完了。其实恰恰相反。真正烧钱的部分才刚刚开始。
二 奥特曼“圈地”,阿里云建“AI工厂”
要真正理解今天的AI行业,是无法绕开一件事的:推理成本(Inference Cost)。
如前所述,今天AI行业最贵的已经不只是训练模型,而是让模型持续工作。这也是为什么再过去一年,整个行业似乎开始突然改口了。
以前大家喜欢说:“大模型军备竞赛。”抢人才,抢资源,都归结于这个标签之下。
现在越来越多公司开始讨论的是,怎么把推理成本打下来?
原因很简单。用户规模上来以后,账单会突然变得非常恐怖,而中国市场已经给出了一个非常明确的信号。
根据QuestMobile等公开行业数据,豆包月活用户已经达到3亿级。而通义千问也已经进入1亿级规模。
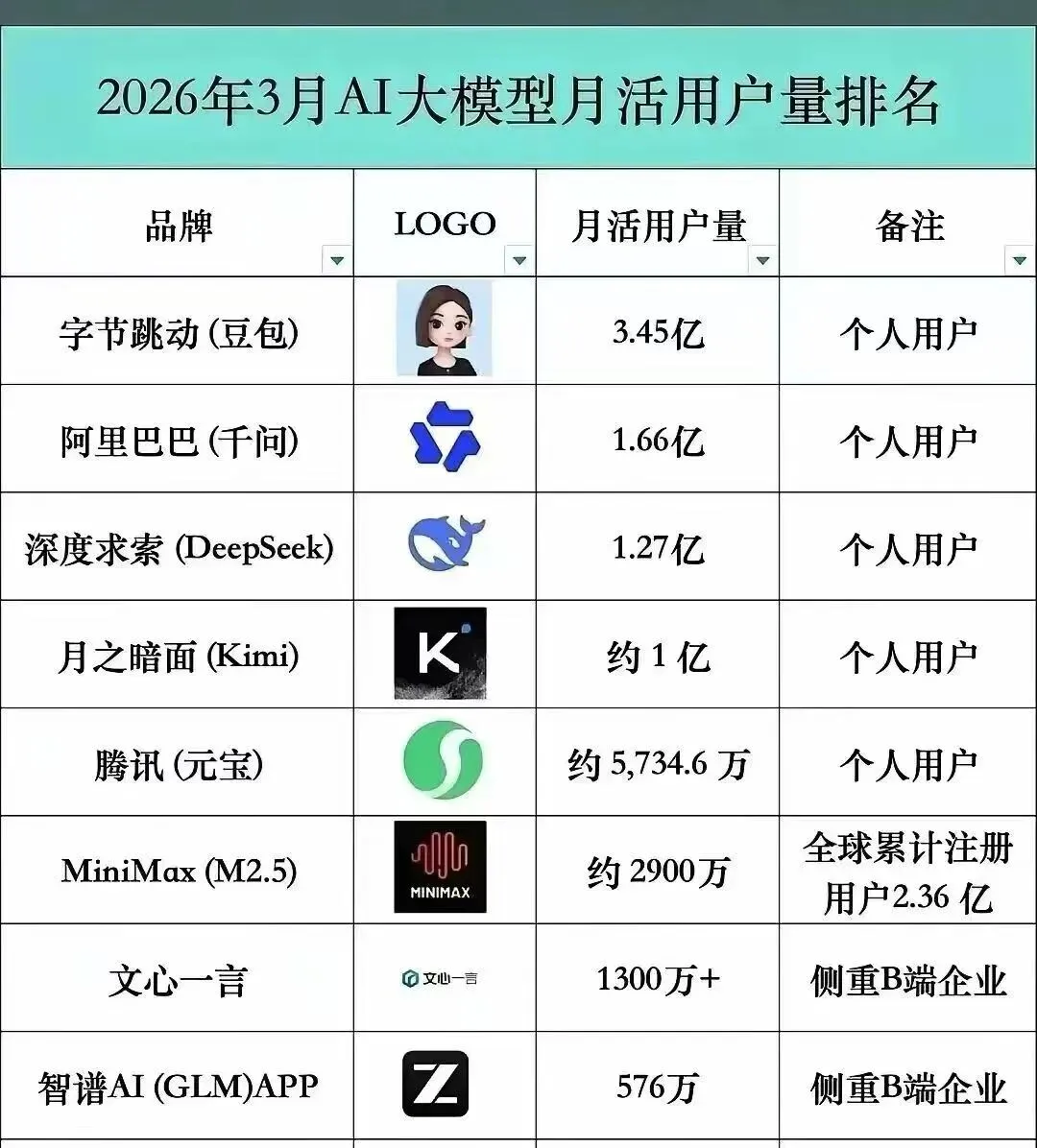
很多普通用户看到的是,增长真猛。
但工程师看到的是另一句话:GPU开始不够烧了......
如果一个用户每天问10次问题,一次几百甚至上千tokens,那么上亿用户意味着什么?意味着背后是数百亿tokens的级别调用。
以前互联网公司喜欢比服务器,今天,AI公司拼的是谁养得起“发电厂”。
这才是奥特曼突然开始用算力换股权的真正背景。
关于这条新闻,有评论表示,OpenAI开始圈养创业公司了。这种说法有一点道理,可惜只说了一半。
因为,如果站在创业公司的角度,今天最大的压力,确实已经不是工资,不是办公室,不是市场预算,而是算力成本。
今天,只要是一个不算太傻的Agent产品,尤其是处理复杂推理、代码和长任务场景的时候,烧GPU的速度远比多数人想象得快。
于是,OpenAI提供算力换股权,本质上其实是一种资源换生态的做法。
可以这么理解:我帮你先活下来,你以后长大了,就留在我体系里。
看到这一幕,有没有眼熟的感觉?
是的,特别像互联网早期云计算刚起来的时候。
很多创业公司为什么选亚马逊云服务?因为人家省钱、省事、跑得快。
只是后来慢慢发现,迁移成本越来越高,于是只好留下来了。国内的云计算厂商,也是提供各种服务,让你长大,并提高迁移成本。
OpenAI其实也一样。今天它真正想绑定的可能已经不是创业公司,而是未来的Agent生态。
未来,这些创业公司,将会默认使用OpenAI模型,用OpenAI推理,用OpenAI工作,用OpenAI Agent......
久而久之,他们确实获得了增长,也能够长大,但也开始越来越难离开。
这就是平台战争的经典逻辑。看起来是扶持,实际考量是抢入口。
所以,今天OpenAI真正争的,可能不是谁的模型最强,而是未来智能运行在哪里。
有意思的是,就在同一天,阿里云给出了完全不同的一套答案。
如果说,OpenAI更像先占生态,那么今天的阿里,更像是先建工厂,而且是一整座AI工厂。
今天的千问云确实独领风骚,但值得关注的是,今天阿里真正发布的,其实是“芯—云—模型—推理”的一一套完整链路。
先看真武M890芯片。这是今天第一次亮相的新一代AI芯片。
官方信息显示:单芯片144GB显存,性能是真武810E的3倍,片间互联带宽800GB/s。更重要的是,阿里直接做了128卡超节点服务器。
过去,GPU像单机作战,而现在开始集群打仗了。
而且官方明确说了,目标就是Agent时代的大规模并发推理。
我们可以继续以前述公司现实场景为例。
未来,你让一个Agent做这些事:调研市场、写方案、做预算、生成PPT。
它可能在毫秒之间就连续调用几十次模型,同时还会调CPU、GPU、网络和存储。
所以,今天真正难的,已经不只是模型聪不聪明,而是整个系统能不能扛住。
这也是为什么,阿里今天提出了一个词:Agentic Cloud,这也许是第二个特别容易被低估的地方。
过去的云,是给人用的。你打开控制台,点按钮,调API......但未来,Agent不会点按钮,它直接给你调函数。
所以阿里今天做的一件事,是把云产品Skill化、MCP化和CLI化。也就是把云改造成Agent能自己调用的环境。
以前,是人调云。以后,是AI调云。
三|千问云的价值:不是模型,而是调度
如果说,OpenAI是在抢未来Agent跑在哪,那么阿里今天真正想解决的问题,可能是未来Agent怎么跑的问题。
这是两个完全不同的问题。
理解千问云,不要将其简单看作是又一个模型平台。阿里今天真正发布的可能根本不是一个模型时长,而是Agent时代的入口层。
关于千问云,有一个特别容易被忽略的细节,是Skills + CLI。
官方原话,是把模型服务能力封装成Skills和CLI工具,为开发者和Agent提供更友好的体验。
我们可以这么理解:AI开始自己调用AI。
假设未来你对一个Agent说,帮我调研一个行业,写一份分析报告,审一份合同,最后做一个PPT。过去需要人类自己切模型。
此时的你恐怕恨不得化身千手观音,查资料用一个模型,数据分析换另一个,写作换一个,做图再换一个......中间还要,自己复制、粘贴、切窗口。
而当AI开始自己调用AI,逻辑就开始变了。
Agent会自己判断。
第一步,搜集信息,它自动选更快、更便宜的模型,因为该阶段的关键词是成本;第二步,合同审核,它自动切换至推理更强的模型,因为该项目的重点是准确率;第三步,要写方案了,再换成创造力更强的模型,因为该项目的重点,已经变成了表达与创意;最后再自动生成PPT。
整个过程,你甚至不用知道它到底切了几个模型,因为,AI会替你选模型。
这件事非常重要。
它意味着企业真正开始进入“多模型时代”。
今天很多人还在争,GPT厉害还是DeepSeek厉害。这个问题越来越像当初人们讨论Windows更好还是Mac更优。
这个问题的确有意义,但也没那么重要了。因为,未来多数企业的现实是,都要用到。
那时的重点,已经不是谁会赢,而是谁来组织:谁帮企业自动选模型,控制token成本,优化推理路径,调度Agent协作,以及做统一治理。
竞争逻辑彻底改变的时候也将到来。
以前比的是谁发动机更强,现在比的是,谁在修高速公路。
因此,今天阿里发布会上,最容易被低估的,其实不是千问模型,而是Agentic Cloud +百炼推理平台。
阿里做了一件特别现实的事——他们开始解决“养不起AI”的问题。
关于百炼推理平台,官方今天重点强调的有,上下文缓存,并池调度,吞吐弹性,Agentic RL和安全治理。
这些词听起来很技术,其实就是怎么让AI更省钱、更稳定、更不掉链子,尤其是推理成本。
未来真正可怕的地方,是Agent不是问一次问题,而是连续工作24小时。
这意味着不停调用、不停协作、不停地执行任务。
所以,未来最大的成本,很可能不是训练一个GPT,而是“养一万个Agent。”
再回看阿里今天的全栈升级,其实就在解决一如前所述的那件事:
如果未来AI开始像员工一样工作,谁来养它?
OpenAI和阿里,看起来打法完全不同,但其实都在抢同一个东西。
OpenAI更像苹果,先占生态,让未来创业公司,默认跑在自己系统里;阿里更像亚马逊云 + Windows,先修路,先建工厂。
阿里默认的是,未来一定是多模型和多Agent世界。
还有一个真正值得注意的变化。过去互联网争夺的是时间,后来移动互联网争夺的是流量入口,而AI时代,巨头们开始争夺的是决策入口。
我们可以再大胆一点想象,如果未来你的方案、商业分析、工作流甚至公司运营都越来越依赖Agent,那么最后真正重要的问题,可能不再是谁模型最强,而是,谁来定义未来智能世界的运行规则。
从今天开始,AI行业,已经开始从“模型竞争”,进入“操作系统竞争”。
模型会越来越便宜,而真正昂贵的,可能不再是智能,而是组织智能的能力。
