 夜雨聆风
夜雨聆风


电影剧情梗概生成框架MovieTeller借助外部工具与渐进策略支持长时序叙事
阿里通义实验室多模态配音大模型FunCineForge解决多人场景音色切换难题 CamDirector方法结合3D全局记忆库有效提升AI视频轨迹编辑一致性
我国团队提出基于电影分镜的高可控性多镜头视频生成框架STAGE
阿里世界模型Happy Oyster提供视频生成的长时序一致性与实时可控性协同优化新思路
【点睛】
当前AI视频生成技术正从单镜头短片段逐步发展演进,已初步具备多镜头叙事能力。然而,与专业影视在长时长、多角色、复杂镜头调度等实际需求与质量要求差距明显,致使AI应用仍主要局限在概念设计、创意参考以及部分重复性制作等初级任务和辅助环节。要推动AI真正融入现代影视工业生产体系,技术层面需解决跨镜头角色身份漂移、场景错位等时空一致性问题,同时也需平衡创意随机性与生成可控性,科学合理拓展艺术创作的表达空间。
对此,国内外学术界以影视数据为训练素材、以影视制作流程为参照,在剧情理解、声画同步、视角转换、多镜头生成等方向取得了一系列科研成果。通过记忆缓存保存历史生成信息,利用身份表征与三维场景约束维持跨镜头一致性,并借助条件扩散模型与相机轨迹控制,将剧本描述、镜头术语等专业指令转化为可解析的结构化信号,为长叙事、高可控性、强一致性的影视内容生成提供技术支撑。未来,行业仍需持续从前沿技术探索中汲取新思路新方法,推动从学术研究到工程落地的有效转化,优化完善工程化细节并实现工作流对接,使AI技术真正深度融入专业影视核心生产环节。
01
电影剧情梗概生成框架MovieTeller借助外部工具与渐进策略支持长时序叙事
当前使用AI模型对一部电影进行剧情梗概生成时,常出现角色混淆、剧情偏离等问题,这源于通用视觉语言模型(VLM)在处理数小时影视内容时,难以持续跟踪人物身份,且无法构建连贯的全局叙事。
对此,浙江大学联合中央广播电视总台、Watch AI团队发布自动视频摘要框架MovieTeller,采用外部工具增强与渐进式策略相结合方案,实现人物身份(ID)高度一致,显著降低剧情幻觉。在100部电影的测试中,大语言模型评分(LLM-as-a-Judge)提升39%,ID一致性指标提升117%,并在高达62%的案例中获得人类评估者的偏好。
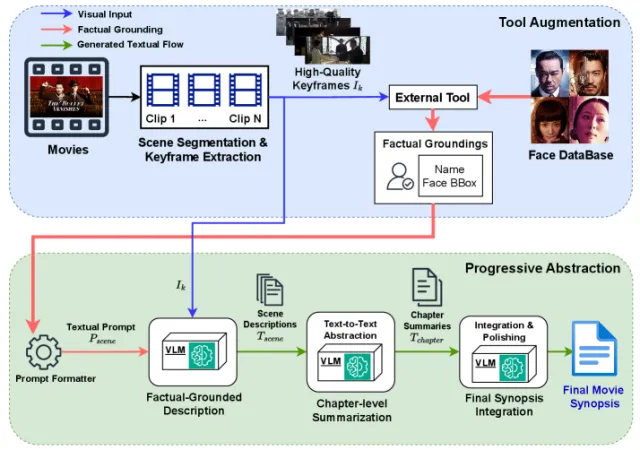
▲MovieTeller框架分为三大核心阶段:场景分割与关键帧提取、工具增强的事实锚定场景描述生成、渐进式摘要流程,最终输出高质量的电影梗概
整个框架分为三大核心阶段:
第一步,场景分割和关键帧提取。采用镜头切换检测工具PySceneDetect基于画面内容的显著变化,将电影切分成一系列语义连贯的场景,再从每个场景里提取一帧关键帧,实现原始视频流到结构化语义内容的转换。同时设计关键帧质量门控,通过平均亮度和像素标准差的双阈值校验,只把画面信息丰富的有效帧传给后续的VLM处理。
第二步,工具增强的事实锚定场景描述生成。利用公开演职人员信息构建人脸数据库,包含电影主要角色名称和人脸嵌入向量。对于每一张关键帧,调用InsightFace人脸识别模型检测画面中的人脸并提取嵌入向量,与预先构建的数据库进行余弦相似度匹配,从而建立身份关联,得到由角色身份及其脸部边界框构成的事实锚定信息,将这些事实锚定信息注入到VLM提示词中,生成具有准确角色身份的场景描述。通过为通用VLM引入专业人脸识别工具作为增强模块,有效解决长视频理解中人物ID不一致问题。
第三步,渐进式摘要流程。模仿人类理解电影的认知过程,设计了两阶段的渐进式摘要流程:首先把上一步生成的场景描述按叙事顺序分组成章节,利用VLM并行生成每个章节摘要,提炼出该章节的核心剧情推进、人物动机和关键转折点,保持角色名一致性;其后,把所有章节摘要拼接成完整草稿,赋予VLM编剧视角提示词,将草稿整合生成最终的电影梗概。

▲通用VLM(上)只能平铺直叙画面内容,缺乏人物ID一致性和叙事连贯性,MovieTeller(下)能精准识别角色,保证剧情梗概的完整与连续
该框架无需训练与微调,所有组件均即插即用,不仅能适配Qwen2.5-VL、InternVL3等多种主流VLM,还能拓展到纪录片、体育赛事、电视剧等更多长视频场景。
02
阿里通义实验室多模态配音大模型FunCineForge解决多人场景音色切换难题
现有电影配音生成通常存在一定局限性,一是高质量多模态配音训练数据集规模有限,词错误率高、标注稀疏,依赖成本高昂的人工标注,且仅限于独白场景,制约模型有效训练;二是配音模型仅依赖唇部区域学习声画同步,在面部遮挡、镜头切换频繁、多人对话、人物面部占比小、画面分辨率低等场景中效果骤降,在复杂真人实拍(Live-action)电影场景中易出现说话人混淆、语音截断与泄漏等问题,并在唇音同步、语音质量和情感表达方面表现欠佳。
近日,阿里通义实验室发布并开源了专为多样化电影场景设计的基于多模态大模型(MLLM)的配音模型FunCineForge,还配套开放了一个包含丰富标注和多样化场景的大规模中文影视剧配音数据集CineDub-CN。
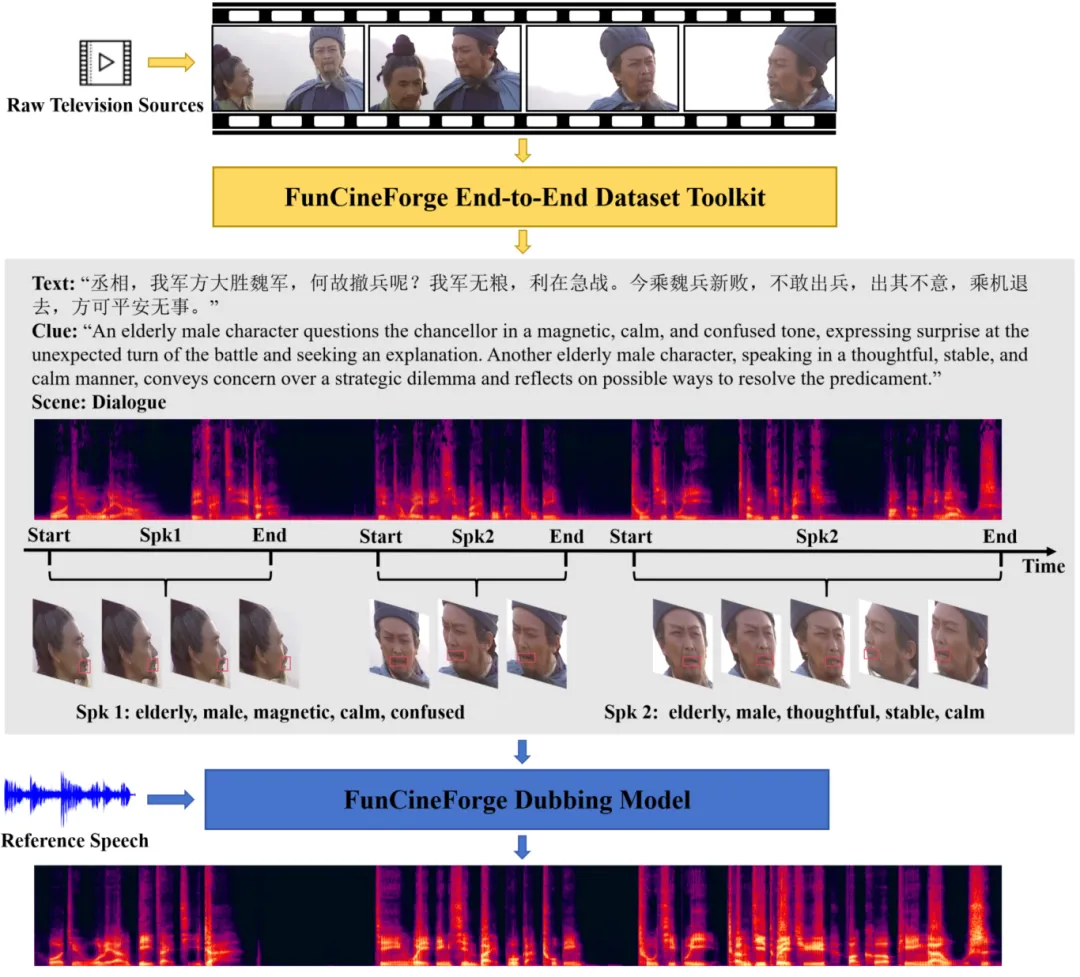
▲FunCineForge数据集生产流程将影视素材转化为多模态数据
FunCineForge首先构建了一套自动化数据集生产流程,自动完成音视频片段分割、人声分离、音视频联合说话人分离等流程,将原始影视素材转化为结构化多模态数据。在此基础上,引入“专用模型预测+多模态思维链(CoT)校正”策略大幅降低转录文本错误率和说话人时间对齐误差,通过多模态大模型校正错字等,并利用其思维链推理生成角色属性和情感线索。数据集覆盖独白、旁白、对话、多说话人等多种典型场景,每条数据均包含转录台词、帧级人脸唇部数据、角色属性与情感线索、毫秒级时间戳及干净人声轨道。
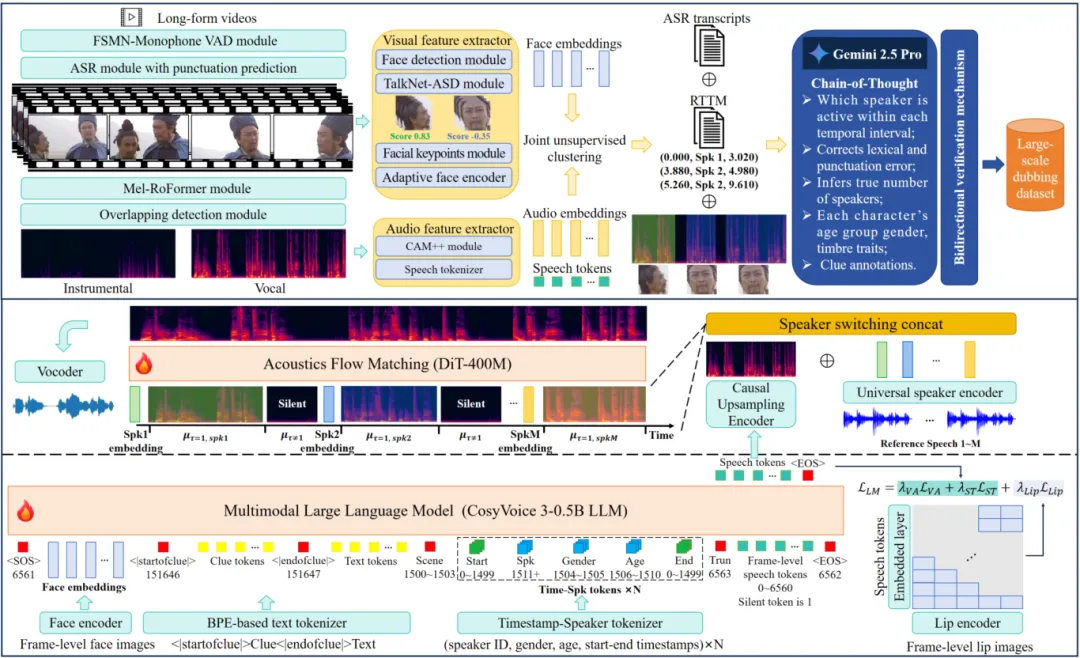
▲FunCineForge架构包含数据集生产流程与配音模型
FunCineForge配音模型采用MLLM与流匹配相结合的架构,首次将说话人时间戳作为独立模态,与文本、视觉、音频多模态信息共同输入MLLM。传统文本转语音(TTS)模型通常只依赖文本内容、声音特征或视觉信息,但时间维度在影视配音中至关重要,能够直接帮助模型精准控制每个角色台词在时间轴上的起始与结束位置,同时在面部遮挡等视觉模态缺失时,作为强监督信号,确保语音出现在正确的时间段。FunCineForge基于CosyVoice3架构,提出说话人切换拼接策略,利用携带角色信息的时间戳,定位台词前的最后一个静音词元(Token),并在此处动态拼接该角色的音色特征,确保音色在时间戳边界处精准切换。
03
CamDirector方法结合3D全局记忆库有效提升AI视频轨迹编辑一致性
视频轨迹编辑(Video Trajectory Editing, VTE)技术根据给定的源视频和相机运动轨迹,生成遵循该轨迹的目标视频,在保留原始视频场景内容的基础上,对原始视角下未见区域进行合理、连贯的修复,能将业余视频升级成具有专业电影级摄影机运动的作品。但现有VTE在长视频一致性与精确相机控制方面存在局限,会“忘记”前一帧内容导致生成画面前后矛盾。对此,来自加拿大麦克马斯特大学、多伦多大学、香港大学、麦吉尔大学、康考迪亚大学、阿联酋人工智能大学的研究者们联合提出了一种新方法CamDirector,使AI视频轨迹编辑拥有“全局记忆”,进而实现长时连贯的视频编辑。
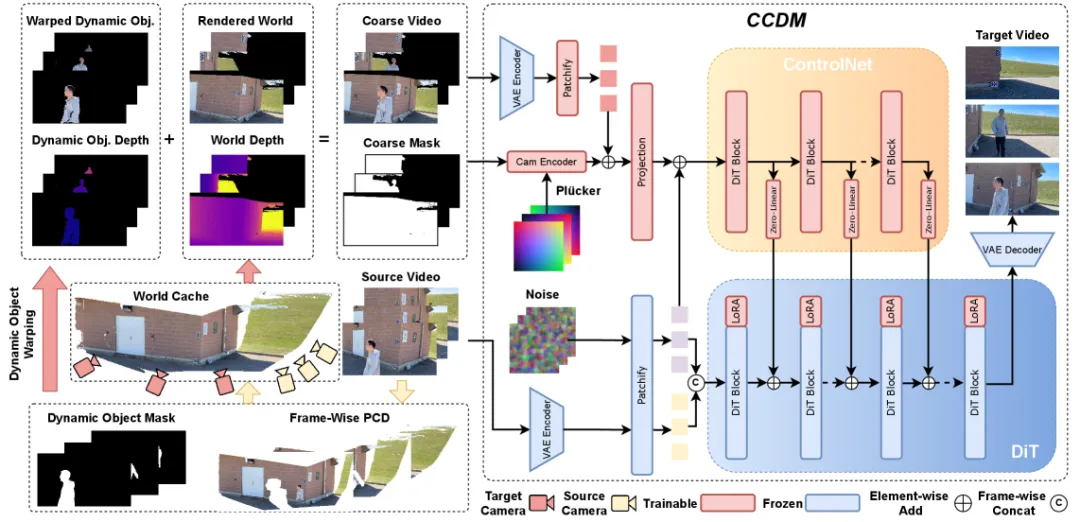
▲CamDirector整体框架:(左)混合扭曲方案,将动态区域与静态区域分开处理,利用整个源视频构建粗糙帧;(右)粗糙视频控制的扩散模型,通过ControlNet引入粗糙帧引导,并将源视频特征与目标噪声拼接,提供可靠先验
CamDirector的创新点在于混合扭曲方案和历史引导自回归生成,前者实现全局内容对齐,后者保障长时时序连贯。
混合扭曲方案首先使用运动分割模型将视频逐帧分离为动态物体和静态背景,动态物体根据其3D点云和颜色信息,通过相机位姿投影变换直接“扭曲”至目标相机视角,保证运动真实性;静态背景通过将所有帧的3D点云渐进式聚合,构建为轻量化的全局3D场景表示形成全局记忆库,即“世界缓存”;最后,针对目标视角从世界缓存中渲染静态背景,并基于深度信息与扭曲后的动态物体融合,得到粗糙帧,实现源内容在目标视角下的精准对齐,确保生成视频忠实于原始场景,避免无中生有。
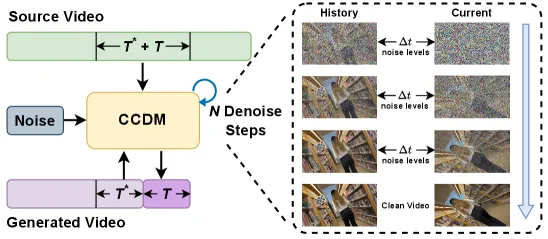
▲历史引导的自回归生成示意图:在每次迭代中,T*个先前生成的帧作为历史,指导后续T帧的合成,同时使用对应的T*+T个源帧作为输入来生成粗糙帧并提供原始场景上下文
历史引导的自回归生成将长视频生成任务分割为若干连续非重叠片段,每个片段包含T帧,上一片段末尾T*帧为历史帧。生成当前片段时,将历史帧与当前帧的噪声潜在表示拼接输入至粗糙视频控制的扩散模型CCDM,历史帧的潜在表示保持在比当前帧更低的噪声水平,历史帧中已确定的颜色、纹理、物体状态等信息可作为引导,通过注意力机制传递至当前帧的生成中。另外,采用渐进式世界缓存更新,生成新片段后提取新生成静态背景的3D点云信息,合并至之前的全局记忆库即世界缓存中,使其持续渐进式更新,保证片段间3D场景结构高度一致。
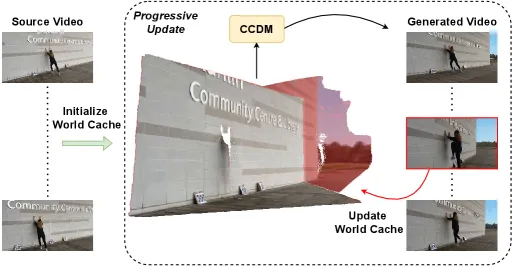
▲渐进式世界缓存更新示意图:每当生成一个新片段,就均匀采样若干帧提取新修复的静态区域,并将其合并到世界缓存中,更新区域用红色高亮
CamDirector团队还构建了一个新的基准数据集iPhone-PTZ,包含10个多元化场景,源视频是手持拍摄,目标视频则由专业人员使用云台拍摄,涵盖推拉、摇移、环绕等多种电影级运镜,相比iPhone数据集轨迹变化更大,视野更广。
04
我国团队提出基于电影分镜的高可控性多镜头视频生成框架STAGE
当前AI模型在生成多镜头长视频时通常采用关键帧方法,即先为每个镜头生成若干关键画面,再借助视频模型去补足中间帧,该方法在镜头切换时常面临连贯性问题,如人物外观变化、动作瞬移等。
对此,北京邮电大学、北京大学、北京智源人工智能研究院联合提出了一个以“电影分镜”为核心的多镜头视频生成框架STAGE,不再预测孤立的关键帧,而是直接生成每个镜头的“起始-结束帧对”(Start-End Frame Pairs),有效提升多镜头视频生成的可控性。目前该论文已被CVPR 2026录用,相关数据集、模型训练和推理代码将逐步开源。
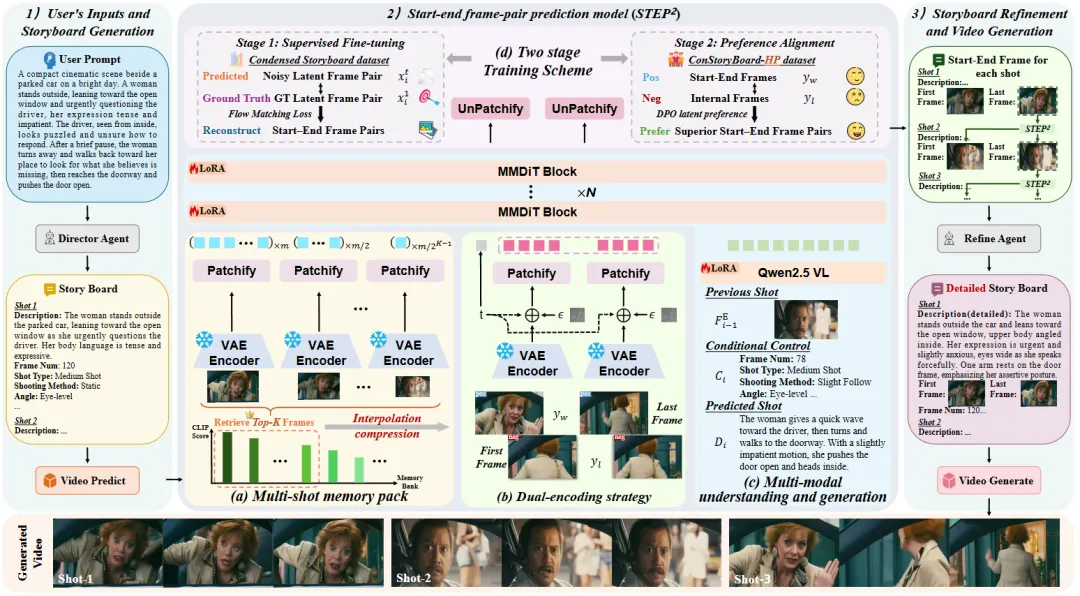
▲参考视频(上)与参考图(下)以起始-结束帧对预测模型STEP2为核心的STAGE流程概览
STAGE工作流的核心是起始-结束帧对预测模型STEP2(STart-End frame-Pair Prediction model)。该模型具备三大核心:首先是多镜头记忆包(Multi-shot Memory Pack),即高效记忆压缩机制,根据历史帧与当前镜头描述的CLIP相似度排序,按重要程度分配空间占比,将视觉信息压缩成一个紧凑的“记忆包”即二维特征图,在保证长期一致性的同时,避免巨大的计算开销;第二是双重编码策略(Dual-Encoding Strategy),将同一镜头的起始帧和结束帧拼接为联合张量,模型通过预测该联合张量,学习两帧之间的合理对应关系,从而掌握整个镜头的动态演变,保证单个镜头内部逻辑自洽;第三是两阶段训练方案(Two-stage Training Scheme),第一阶段监督微调(SFT)让模型在海量电影片段上学习基础镜头语言,第二阶段偏好对齐采用直接偏好优化(DPO),用人类精选的“好/坏”镜头转场案例进行训练,让模型学会电影感转场。

▲ConStoryBoard数据示例
研究团队构建了大规模数据集ConStoryBoard,从开源数据集Condensed Movies中筛选了10万余个高质量多镜头片段,提取每个镜头的起始-结束帧对,并进行了精细化标注,包括故事进展描述以及结构化电影学属性如镜头尺度、机位、运镜等。此外,还从中人工挑选出最优转场案例,构建了包含人类偏好的子集ConStoryBoard-HP,专门用于第二阶段基于人类偏好的的电影感训练。
05
阿里世界模型Happy Oyster提供视频生成的长时序一致性与实时可控性协同优化新思路
近日阿里发布可实时构建和交互的世界模型(World Model)产品Happy Oyster(快乐生蚝)。该模型基于原生多模态架构,支持多模态理解与音视频联合生成,生成过程中能够持续接收用户指令,画面实时响应,具备漫游(Wander)和导演(Direct)两大核心能力。漫游模式下,输入文本或图像可生成具备物理一致性的3D空间场景,可分开设定角色(Character)和场景(Scene),支持长达1分钟的480p实时位移控制和镜头控制。导演模式可作为实时AI视频生成引擎,用户通过文字指令实时操控镜头、调度角色、改写剧情,生成长达3分钟的480p或720p实时画面。

▲Happy Oyster漫游模式示例


▲Happy Oyster导演模式示例
Happy Oyster采用长时序世界演化建模,依托海量长视频训练数据,学习真实世界的运行规律。针对长视频生成易出现的内容漂移、结构退化等问题,Happy Oyster引入持续状态复用机制,通过历史状态的连续传递继承已生成信息,使生成内容始终沿既有时序语境扩展,减少了上下文重建带来的不稳定性,在更长时间尺度上维持场景结构与动态连贯性。
Happy Oyster设计了文本、图像等多样化控制信号,用户指令不仅作用于初始条件,还持续影响后续的世界演化,生成过程与实时交互深度绑定并共享同一时序框架,模型能够实现一致性与可控性的协同优化。
目前,世界模型已形成视觉词元逐帧预测、3D空间建模渲染以及像素空间动态演化等不同技术路径,其探索的时空一致性、因果推理等能力,与视频生成领域紧密相关。随着世界模型研究深入,视频生成模型有望借鉴世界模型的创新思路,突破角色一致性、叙事连贯性与过程可控性等核心瓶颈,更好满足电影制作对内容高质量、长时序、可编辑的需求,推动更具电影感的作品诞生,并催生更多新颖的生成式创作方式。(本期图片均来自互联网)

编辑撰写丨张雪
校对丨夏天琳
审核丨王萃
终审丨刘达



别忘了点赞+在看哦!

