 夜雨聆风
夜雨聆风❝多数开发者第一次用编程 Agent,都是把它当代码工具:检视一个仓库、写一份 diff、跑测试、提一个 PR。这仍然是 Codex 最核心的场景。但作者的观察是:电脑上的工作早就不止写代码——执行 shell、浏览网页、调 API、导文档、响应事件、触发自动化。当这些能力都接进 Codex 之后,它越来越不像一个"写代码的助手",而更像一个"替你完成电脑工作的系统"。
❞

Codex 应用本身把这种转变变得可感知:一个对话线程能保留上下文、调用工具、产出可见的产物(artifact),并在多次 prompt 之间持续推进,而不是每一轮都从零开始。
要把 Codex 用透,得把下面这几样能力组合起来用:
「持久线程」——保留长期上下文 「语音、中断、排队」——人还在回路里时的操作方式 「浏览器、计算机控制、MCP server、连接器」——让 Codex 越过单个仓库去做事 「线程自动化与目标」——人不在时把活继续推进 「侧边栏」——审阅代码、文档、PPT、其他产物的统一界面
持久线程(durable threads)
❝「持久线程」:跨多次会话保留工作上下文的长生命周期 Codex 线程。
❞
把线程"钉住"是把持久线程留在手边的常用做法。适合钉住的,是那些会反复回到同一份上下文的工作流,例如:
一个"幕僚长(Chief of Staff)"线程 一个发布管理(release)线程 一个文档评审线程 一个专门盯外部监控的线程
它们不是聊几句就关掉的临时对话,而是「持久工作区」。Codex 可以隔几天再回来,先前的决策、偏好、工作上下文都还在,不必每次重新讲一遍。
钉住线程还有一个实操层面的细节:Cmd-1到Cmd-9可以直接跳到对应位置的固定线程。对一个"上午写代码、下午跟监控、晚上看周报"的人来说,这套快捷键省下的切换成本会比想象中可观。
❝落地点——大多数 Agent 工具的"会话历史"是平铺时间线,第二天就找不到。Codex 这种钉住的设计实际上把"几个长期角色"显式建出来了,类似 IDE 里的"工作区"概念。
❞
语音输入
语音输入有用,是因为它能在一个想法被压缩成"漂亮句子"之前就抓住它的粗糙版本。
Codex 内置了语音输入。它特别适合那种"嘴上能说出来、打字反而费劲"的模糊起点:
❝我记得有个叫 Ben 的人在 Slack 里提过这件事, 细节我也不记得了, 你帮我去找一下。
❞
对一个能搜索、收集上下文、再把结果讲给你听的 Agent 来说,这种程度的输入往往就够了。
它对两三分钟的"想法倾倒"也很合适——任务还没成形,先把脑子里的东西全说出来。
转录稿(transcript)的逻辑是一样的。一段会议原始转录,或者随手口述的计划备忘,往往比一份压缩过的摘要是更好的素材,因为它保留了不确定、强调、未说完的句子——这些都是后续推理需要的信号。
中断与排队(steering & queuing)
把语音和「对正在进行的任务的显式控制」结合起来用,价值会更大。
❝「Steering(中断引导)」:在当前步骤还没结束时插话,给 Codex 一条新方向。
❞
中断的典型场景是:Agent 走偏了,需要在它继续往下做之前先纠回来。比如让 Codex 评审一个网页时,用户可以一边在页面上画批注一边打断它:"这块布局先别动,先把字号统一了。"
❝「Queuing(任务排队)」:在当前任务还在跑的时候,先把下一个任务排进去。
❞
排队解决的是另一个问题:你已经知道接下来要让它干什么,但不想等它跑完再来下一条。把任务排上,然后去喝杯水,回来时下一步已经在跑了。
❝解析——这两个能力听起来微小,实际上把"Agent 异步执行"这件事变成了"双方都不闲着"的协作模式。多数 Agent 工具到今天还是"用户问 → Agent 答 → 用户再问"的回合制,Codex 这套设计更像两个人结对工作。
❞
让 Codex 走出仓库:浏览器、MCP、计算机控制
代码之外的工作怎么办?Codex 给了几条出口。
**计算机控制(computer-use)**让 Codex 能直接操作浏览器和应用——点按钮、填表单、读屏。这一类操作以前要写一堆胶水脚本,现在可以靠自然语言指挥 Agent 完成。
「MCP server 与连接器」把 Codex 接到团队已经在用的系统里:日历、文档、项目管理、监控告警。MCP 这层的好处是不需要为每个工具单独写适配,只要那个系统暴露了 MCP 接口,Codex 就能用。
「应用内浏览器」让 Codex 能直接看一个渲染后的页面、控制它,并对页面上的批注作出回应。也就是说,对一个网页或产物的评审,可以留在工作循环内部,而不必另外开一个频道交接。
❝对比——这其实是 Anthropic、OpenAI、Cursor 三家不同思路的分水岭。Cursor 把 Agent 嵌进编辑器,假设工作主体在代码里;Codex 这套设计是反过来的——假设工作主体在浏览器、文档、应用之间流转,代码只是其中一环。哪条路对,要看你的工作到底花在哪。
❞
线程自动化与目标(thread automations & goals)
❝「Thread automations(线程自动化)」:让一个线程按计划继续推进工作,即使用户没在看。
「Goals(目标)」:给一个线程一个明确的完成条件,让 Codex 朝它持续推进。
❞
这两个能力是"把人从回路里临时拿出来"的关键。
线程自动化的常见用法:
每天早上跑一次外部监控扫描,把异常摘要扔到对应线程 每周一刷新一份团队 dashboard 每次某个 webhook 触发,就让对应的工作线程被唤醒
目标则是给一个长任务定一个"做完算什么样"的标准。比如"帮我把这份 RFC 的所有评论都解决掉"——Codex 会把目标拆开,逐个推进,直到全部解决再停。
人不在时,线程自动化负责保持节奏,目标负责保持方向。两者一起用,才有可能让一个 Agent 跨越数小时甚至数天稳定推进。
侧边栏:对话和产物放在一起
侧边栏的设计哲学是:「对话和产物不要分屏」。
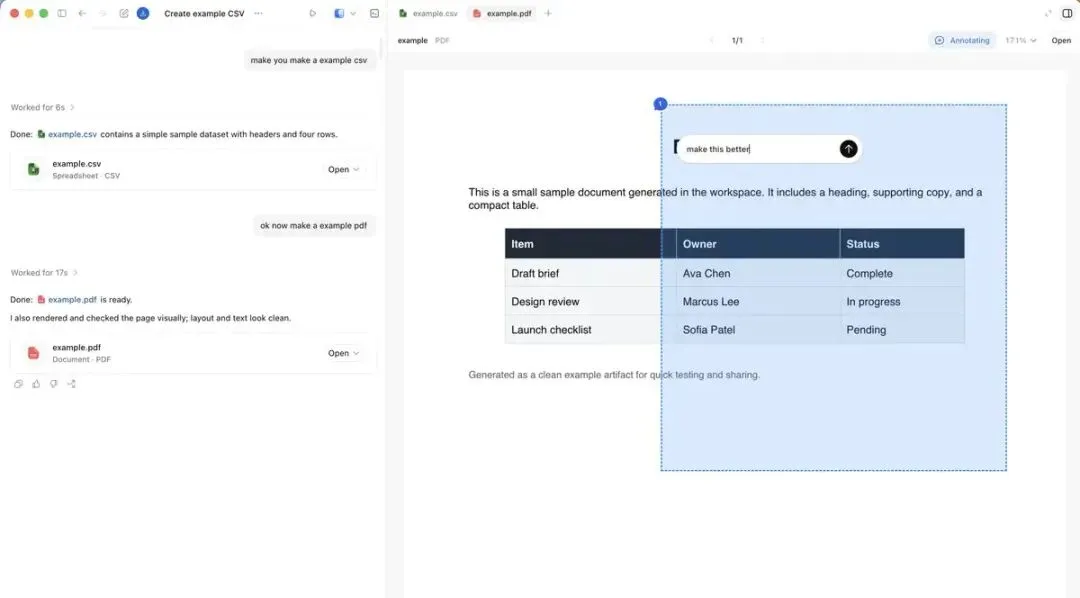
PPT 或 PDF 可以和生成它的对话留在同一个界面里,随时审阅、随时改。
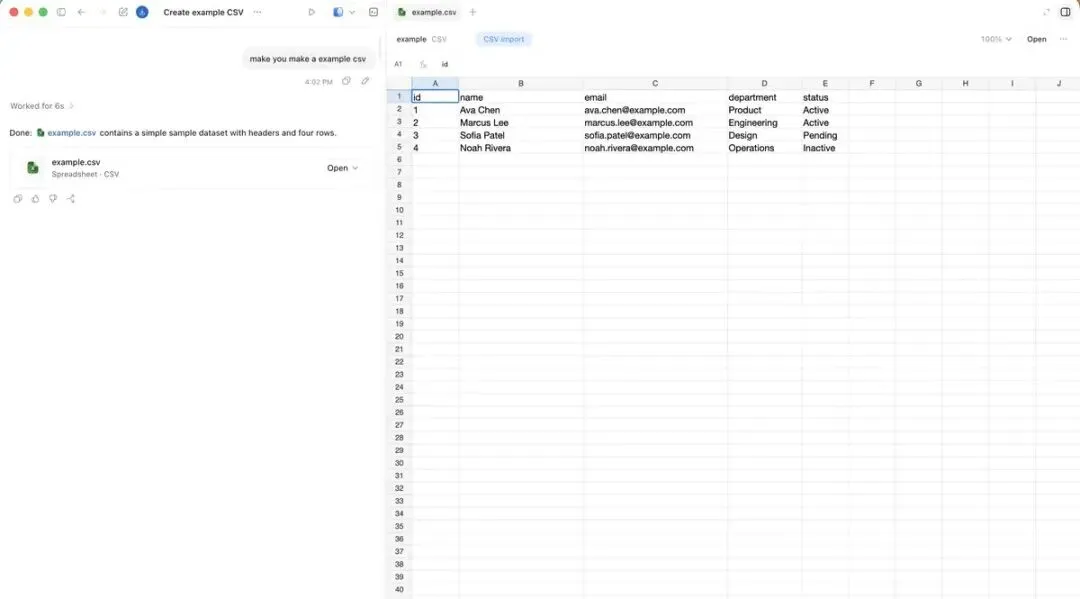
应用内浏览器让 Codex 能看一个渲染好的页面、控制它,对页面上批注的评论会直接进入工作循环,而不是变成另一个孤立的反馈环节。
网页这时候既是输出,也是控制面。Codex 可以构建一个产物、在侧边栏打开它、检视它、调试它,再继续在原地把它打磨好。
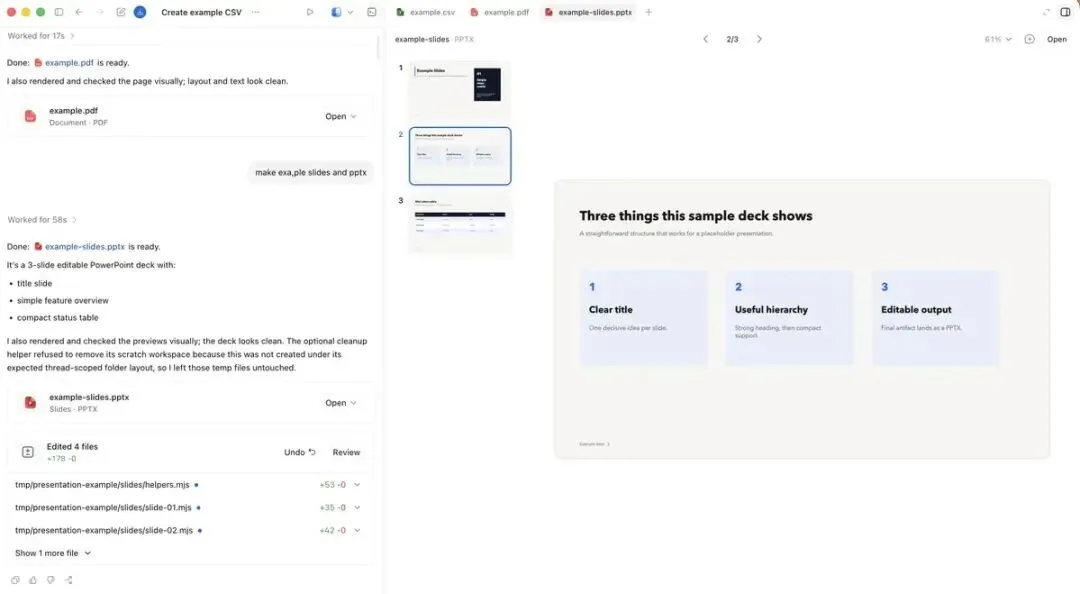
下面这几种产物形式,特别适合放在侧边栏迭代:
index.html——轻量静态产物Storybook——UI 评审 Remotion Studio——程序化动画 浏览器原生 PPT 数据应用——分析工作流
一个index.html文件就能成为一个长期可交互的产物,无需服务端。线程自动化甚至可以定期刷新这些静态产物——用户下次回到线程时,新一版已经准备好了。
共享记忆(shared memory)
长生命周期线程要变得真的有用,记忆不能只活在一个对话里。
❝「Shared memory(共享记忆)」:放在单个线程之外的持久上下文,保证未来的工作能从一个明确、可审查的地方继续。
❞
一个有点门道的做法:把持久线程锚定在一个 Obsidian vault 里。落到实操层面,这其实就是一个「纯文件夹的 plain markdown 文件集合」——可以审、可以改、可以挪、可以放很久。需要同步的话,团队可以把这个文件夹放到云盘、Git、Dropbox、Google Drive 等任何同步层。
一个 vault 大致长这样:
vault/
├── TODO.md
├── people/
├── projects/
├── agent/
└── notes/
最上层放一个AGENTS.md,约束 Codex 在了解到新事实时应该怎么更新这个工作区。
不要直接抄结构。要做的事情是:告诉 Agent「持久上下文该住在哪里、要保留什么、什么情况下不要瞎写」。
一份能用的AGENTS.md可能这样写:
把 ~/vault当作长期工作记忆。偏好"权威笔记",不要让笔记到处散。 TODO、人物、项目、日报、临时笔记,每种都有明确归属的目录。 保留:决策、阻塞项、负责人、日期、有用的链接。 如果什么有意义的事情都没发生,「不要为了写而写」。
仓库存代码。vault 存的是滚动上下文:相关的人、最近改了什么、卡在哪、还要跟进什么、那些不写下来下次就会忘的事。
重要的上下文不应该只活在对话记录里,得显式落到下一根线程能拿起来继续的地方。
Codex 自己也提供原生记忆功能(Settings > Personalization > Memories),那是一层本地召回——偏好、常用工作流、已知坑点都可以放进去。它和显式写下来的 vault 是互补关系,不是替代。Chronicle 走的是同一方向:让 Codex 从最近的屏幕上下文中自己积累记忆。
结语:从代码向外
Codex 的起点仍然是代码。但围绕代码的工作,今天已经能通过同一套系统覆盖:MCP server、浏览器界面、桌面控制、线程自动化、可审阅的产物。
这件事改变的是「控制模型」:
「中断」修正方向 「排队」安排下一步 「线程自动化」让任务在用户离开时继续跑 「目标」给线程一个明确的终点
把这几个组合起来,Codex 就能把一个完整的工作流——从指令、到执行、到产物评审——一路带下去,即使工作早已离开了原本那个仓库。
