 夜雨聆风
夜雨聆风




个人简介




齐涛,北京邮电大学计算机学院特聘研究员、博士生导师,隶属王尚广教授团队。齐涛博士分别于2020年、2024年于清华大学获学士、博士学位,主要研究方向为服务计算、人工智能隐私保护、大模型安全。以第一作者身份发表Nature Communications 2篇(其中1篇入选该期刊Highlights,AI隐私保护方向唯一)、CVPR Oral 1篇(录用率约0.7%),以一作/通讯身份在ICML、NeurIPS、IEEE TIFS等发表CCF-A类论文20余篇。主持科技创新2030-重大项目课题、国家自然科学基金、CCF-深信服基金、国家电网科技项目等(主持经费超1000万)。研究成果依托合作项目在微软、国家电网、华为等企业应用,并形成多项开源工具。曾获微软学者提名奖(亚洲范围遴选21人)、惟新学者奖(60万自主支配科研奖金)、斯坦福全球前2%科学家(连续2年)、ACM SIGWeb China优博(全国遴选3人)、清华大学优博、北京市优秀毕业生等。



研究心语


在人工智能加速融入经济社会发展的过程中,通用AI能力正在快速提升,医疗、金融、政务、工业、科研等关键领域也持续积累了大量高价值数据。然而,这些数据往往涉及个人隐私、行业机密和国家安全,难以在开放环境中被充分共享和利用,导致“有数据不能用、想智能不敢用”成为制约人工智能深入落地的重要瓶颈。AI隐私保护的核心价值,正是在安全与发展之间建立可信桥梁:一方面保障敏感数据在训练、推理和应用全过程中的安全可控,另一方面释放关键领域数据资源的智能价值,支撑大模型在真实场景中安全、高效、合规地发挥作用。面向国家人工智能战略需求,开展AI安全与隐私保护研究,不仅是技术问题,更是推动可信人工智能发展、服务数据要素流通、支撑数字中国建设的重要基础。



代表成果


代表成果1:高效无偏的隐私保护训练方法
分布式机器学习能够协同利用实际系统中分布于不同节点的数据与计算资源,通过节点间共享模型参数等学习中间变量完成模型训练。由于其去中心化特性,该技术在一定程度上避免了数据集中存储带来的隐私风险,已成为面向隐私保护的主流机器学习方法之一。然而,随着研究的深入,分布式机器学习也暴露出新的隐私安全挑战:节点原始数据与训练过程中共享的中间变量之间存在高度相关性,已有研究表明,攻击者可通过共享变量成功反推出隐私数据。
针对上述问题,研究提出了一套基于差分隐私知识迁移的协同学习框架,实现了分布式学习全过程的隐私保护。同时,进一步提出了一种具有可证明隐私安全性的高效模型训练方法,解决了差分隐私机制直接应用于现有分布式机器学习模型时容易导致模型性能断崖式下降的难题。该方法在为分布式学习过程提供有效且可证明的隐私安全保护的同时,相较于现有隐私保护机器学习方法,最高可实现84.2%的性能提升。
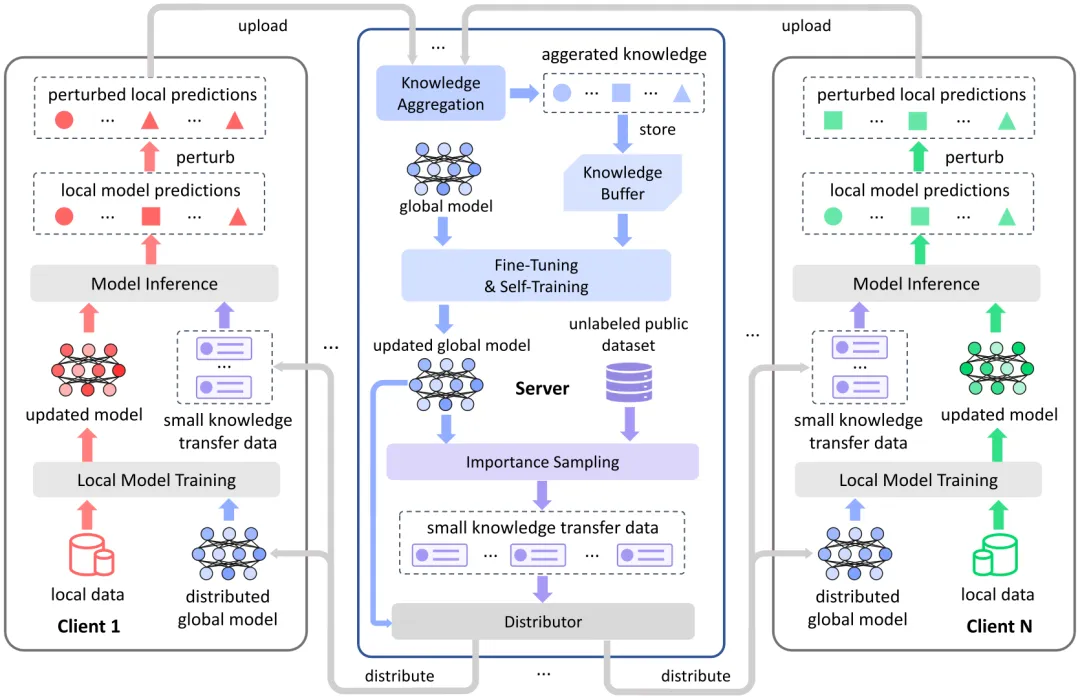
图1:基于差分隐私知识迁移的分布式训练框架
代表成果2:精准快速的隐私保护推理方法
人工智能推理隐私保护能够在模型服务调用过程中保护用户查询、检索知识和中间表示等敏感信息,避免云端大模型在推理阶段直接接触原始隐私数据,是面向可信大模型应用的重要安全技术。然而,随着云原生大模型服务与检索增强生成框架广泛应用,人工智能推理隐私保护也遇到了新的挑战:当前云端RAG框架通常需要将本地或第三方知识库中检索得到的原始文本以明文形式发送至云端模型,检索内容可能包含隐私数据、商业机密和受版权保护材料,存在被云服务提供方缓存、分析、复用甚至重构泄漏的风险。
针对上述问题,研究提出了一套基于代理知识表示的云端RAG隐私保护推理框架,将检索得到的原始知识压缩为与大模型语义空间对齐的代理表示,实现推理过程中敏感知识的非明文共享。同时,提出了一种面向查询的知识表示方法和差分隐私增强的协同推理机制,有效过滤与问题无关的冗余内容,并为在线推理传输数据提供可证明的隐私安全保障。该方法在保障云端大模型有效利用外部知识的同时,显著降低了推理阶段的隐私泄漏风险,并在7个公开基准和4种主流大模型上保持了高质量生成效果。
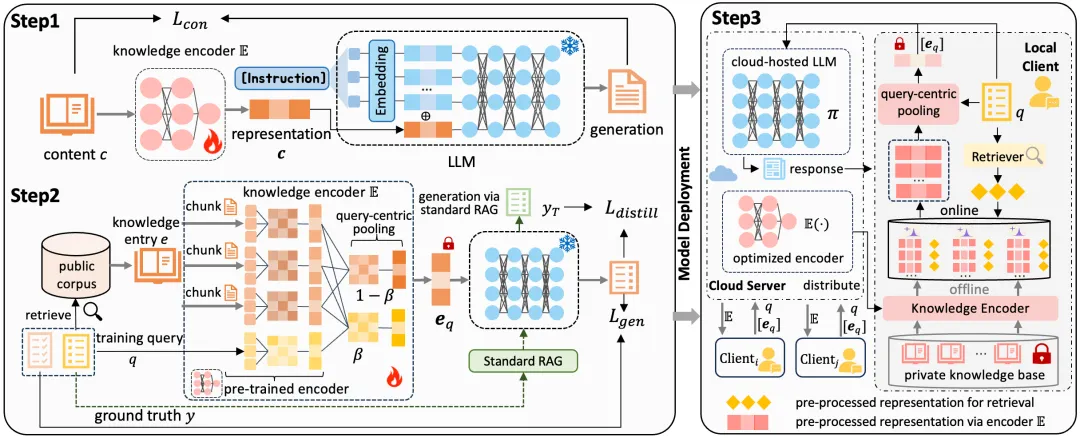
图2:基于知识压缩表征的云端协同框架
代表成果3:可靠完备的隐私保护评估方法
大语言模型服务能够基于海量训练数据生成高质量内容,已成为当前人工智能应用的重要基础设施。但是,随着大模型能力不断提升,其对训练数据的记忆与重现生成也带来了隐私泄漏风险。成员推理攻击能够判断特定数据是否参与模型训练,是评估大模型服务训练数据泄漏风险的重要方法。当前大模型服务通常以黑盒接口形式开放,用户难以获取模型结构、参数和训练过程信息,仅能基于模型输出结果开展风险评估。同时,模型生成内容受到先验知识、语义泛化和跨模态关联等因素影响,导致现有方法难以准确区分训练数据记忆与通用知识推理。
针对上述问题,研究提出了一套基于信息同位素技术的黑盒大模型隐私风险评估方法,揭示了隐私数据中微结构信息可在模型学习与生成过程中稳定保留的机理,实现了对训练数据成员性的精确度量。同时,提出了先验知识解耦与校准机制,突破了黑盒条件下大模型训练数据泄漏风险难检测、难量化的难题。在仅依赖模型输出的情况下,该方法最高实现了超过99%的检测准确率,并在多个主流大模型服务和百万Token级长文本场景中保持稳定表现,为大模型服务隐私风险评估与可信治理提供了有效技术支撑。
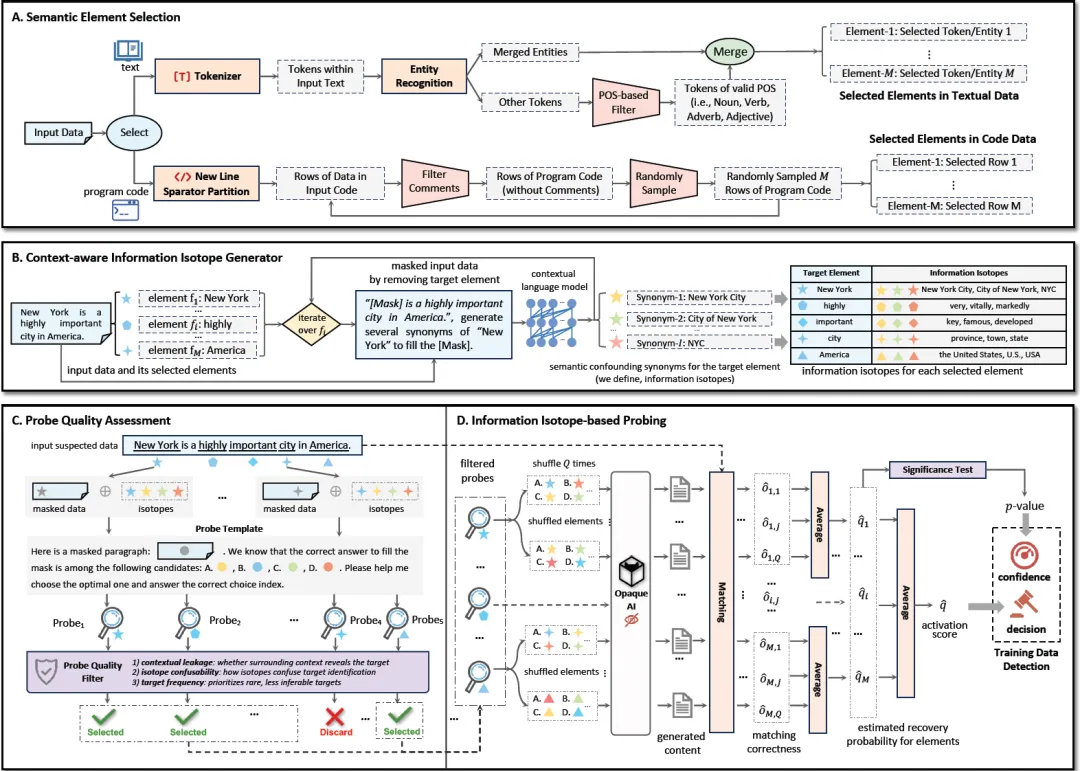
图3:基于信息同位素的训练数据检测与
隐私风险评估框架


供稿|齐涛
统筹|曹宇博
审核|张笑燕 张艺

