 夜雨聆风
夜雨聆风一、现象引入:从"改错位置"到"精准修改"
几个月前,用 AI 编程工具"辅助修改代码"还是一件让人提心吊胆的事。
开发者们私下吐槽:AI 生成代码确实快,但一让它改代码就露怯——改错位置是家常便饭,缺少依赖包是常态,语法通不过更是见怪不怪。有人形容那时候的 AI 工具是"代码生成是博士生水平,代码修改是实习生水平"。
但最近,情况悄悄发生了变化。现在再让 AI 修改代码,它能精准找到要改的位置,依赖包自动补齐,语法基本一次过。这种进步是真实的,不是营销吹出来的。
这种进步从哪来的?模型变聪明了?工具做得好?还是人类学会怎么提问了?
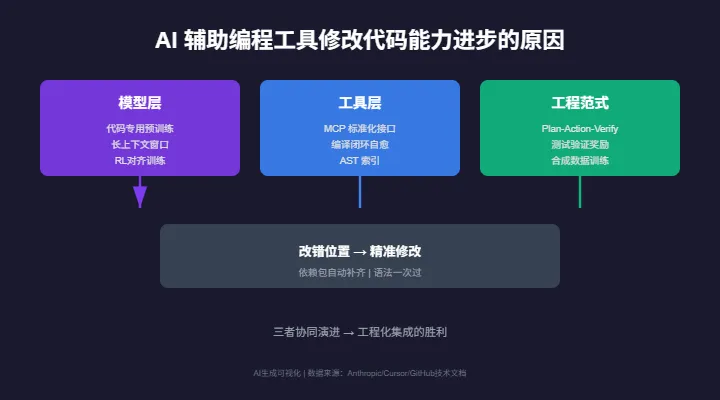 本文综合了多个主流 AI 编程团队(Anthropic、Cursor、GitHub Copilot 等)披露的技术资料,从模型、工具、工程范式三个层面,解析这次能力跃升的真实原因。
本文综合了多个主流 AI 编程团队(Anthropic、Cursor、GitHub Copilot 等)披露的技术资料,从模型、工具、工程范式三个层面,解析这次能力跃升的真实原因。
二、模型层进步:训练方式变了
训练数据不对,模型就懵
2026 年 5 月,Anthropic 在官方博客《Teaching Claude why》中说了个大实话:早期模型改代码不行,问题不在模型不够聪明,而在训练数据不对。
之前训练用的是纯聊天数据(RLHF),模型学的是"怎么对话",但真要让它改代码,它就懵了——不知道有哪些工具,也不知道怎么调用。
他们想了个办法:引入"difficult advice"数据集,专门教模型在工具使用场景下怎么推理。效果比直接针对评估场景训练好 28 倍。

大模型负责想,小模型负责改
Cursor 团队在 Composer 2.5 的技术博客中披露了另一种思路:工业界现在广泛采用"专用合并模型"架构。
具体怎么做的呢?让最聪明的大模型只负责理解修改意图并生成"粗糙的修改方案",然后把这个方案交给一个专门训练过的 3B~8B 小模型来执行合并操作。这个小模型只干一件事——把修改意图和原代码结合,生成完全正确的合并代码。
为什么要这么分?因为大模型做精确的行列定位时容易"漂移",但小模型经过专项训练后,反而能更稳定地完成合并任务。两者配合,大模型负责"想清楚改什么",小模型负责"精准改到位"。
在实战中学习纠错
在模型训练阶段,现在的做法是直接让模型接触真实的开发环境——编译器、Linter、测试框架。当模型生成的代码语法不通或编译失败时,它会受到惩罚,从而学会"怎么不把代码改坏"。
SWE-bench 是代码修复的基准测试,后期模型在这个测试上的表现确实比早期强很多。
三、工具层进步:工具变聪明了
MCP 协议:AI 和工具之间有了"标准普通话"
2026 年初,Model Context Protocol(MCP)正式发布并被 VS Code、Cursor、ChatGPT、Claude 等广泛支持。
用个形象的比喻:MCP 就像 AI 应用程序的 USB-C。以往,AI 工具调用 IDE 功能时需要"猜"——猜有哪些功能、怎么调用、参数是什么。MCP 把这些信息标准化了,AI 能稳定地知道有哪些工具可用、如何调用。
这解决了一个根本问题:模型对自己工具调用行为缺乏正确的对齐。而这个问题的解决,首先是工具接口的标准化,而不是模型本身的改变。

编译闭环:工具在后台自动纠错
现在的 AI 编程工具已经进化为一个"Agent 运行底座",而不仅仅是一个编辑器插件。
当 AI 尝试修改某段代码时,工具链会在后台自动运行静态分析、Linter(如 ESLint、Ruff)或编译器。如果发生"语法通不过"或"缺少依赖",工具端会截获报错日志,在人类完全不知情的情况下,自动作为下一轮的输入重新喂给模型进行"自我纠错",直到编译通过。
这个过程不需要人类介入,AI 自己就能完成多轮迭代修正——工具已经在后台把这件事做掉了。
全库 AST 索引:依赖包自动补齐
工具在后台对整个 Codebase 进行了深度索引,建立起跨文件的依赖关系图谱。当大模型试图使用一个新函数或第三方库时,工具底座会根据 AST 分析,自动在文件顶部补齐缺失的 import 语句,或在包管理文件中添加依赖。
这就是为什么现在的 AI 很少再出现"缺少依赖包"的问题。
四、工程范式进步:别直接信输出
旧范式:直接替换
过去 AI 修改代码的流程很简单:给一段代码,让它替换某个区域的代码。这种"单向覆盖"模式容错率极低——一旦改错位置,整段代码就废了,而且很难追踪问题出在哪里。

新范式:Plan → Action → Verify
现在主流的 AI 编程工作流已经演变为严格的闭环:
Plan(计划):AI 先在上下文中写出修改计划,说明要改什么、为什么这样改 Action(执行):基于计划执行局部精准 Diff Verify(验证):自动运行单元测试,测试通过才是修改成功的标准
说白了就是:别直接信 AI 的输出,让它自己在测试环境里跑一遍。
Cursor Composer 2.5 还采用了"功能删除"任务——让 AI 删除代码但保持测试通过。这种训练方式通过测试验证奖励来优化模型行为,直接对应了"语法通不过/缺少依赖"的问题。
同时,训练数据量增加了 25 倍,包含更多真实开发场景,让模型见过更多"坑"。
五、现状与展望:战术层已解决,战略层仍有挑战

战术层面:基本解决了
在局部 Bug 修复、工程环境自愈、标准模式迁移这些场景中,AI 的代码修改能力已经达到可以交付工业使用的标准。定位精准,很少再出现"改错位置"这类低级错误。
AI 就像一个配有高精度显微镜的手术医生——你把图纸画得越精确、范围给得越小,它的表现就越完美。
战略层面:还有很长的路
但一旦进入复杂的真实工业级软件系统,AI 工具就会暴露短板:
隐性业务逻辑:AI 修改完代码后,语法完全正确,编译通过,测试全绿,但生产环境崩溃了。AI 很难理解那些没有写进代码、只存在于人类大脑中的业务约束。 雪崩式全局重构:如果发起一个涉及整个 Codebase 的重构任务(如把 SQL 数据库换成 MongoDB),改动会像涟漪一样扩散到所有层级,AI 在第 5、6 步时就会因上下文漂移而迷失方向。 分布式状态推理:在处理高并发、异步队列、分布式事务时,AI 本质上在做静态文本推理,极难对复杂的动态运行时状态进行深度建模。
现在的 AI 修改代码,更像一个超级熟练的蓝领泥瓦匠。你把图纸画得越精确、范围给得越小,它砌出来的墙就越完美。
但它还不是一个总建筑师——在没有弄塌整栋大楼的前提下,它还无法帮你把三楼的承重墙向后挪两米。
六、结语
AI 编程工具修改代码能力的进步,是模型、工具、工程范式三者协同演进的结果:模型提供了精准定位和自我纠错的"大脑",工具提供了编译校验闭环的"躯体",工程范式确立了先计划、后验证的"行为准则"。
三者缺一不可。这种进步不是某一次技术突破带来的,而是工程化集成的胜利。
对于开发者来说,这意味着 AI 辅助编程已经从一个"玩具"变成了一个"可以信赖的工具"。但也别对它期望过高——局部任务找 AI,大局重构还是得靠人。
参考来源
Anthropic Blog — "Teaching Claude why" https://www.anthropic.com/research/teaching-claude-why
Model Context Protocol — 官方文档 https://modelcontextprotocol.org
Cursor Blog — "Introducing Composer 2.5" https://cursor.com/blog/composer-2-5
GitHub Blog — Copilot Changelog https://github.blog/changelog/2026-05-17-copilot-model-update
