 夜雨聆风
夜雨聆风曾经看到过⼀个观点“⽬前 AI 真正落地的⽅向其实就 2.5 个——聊天(1)、编程(1)和短视频制作(0.5)”
(个⼈观点:也许 Seedance 2.0/HappyHorse 1.0 的出现会将 0.5 的阵地补齐,成为下⼀个 1)
声明
本⽂分享的⼯具、模型、⼯作流全部开源免费。相⽐于闭源优势在于:可玩性⾼、可控性强、⽆需考虑试错成本,也许还能体验⼀些在闭源平台⽆法体验的创意。关键是,通过抽卡未必不能创造出优于闭源模型的作品。
运⾏配置建议
显卡:建议 N 卡 3060 以上,>= 12G(简单任务 6G,甚⾄ 4G 都能玩),⽐较理想 > 24G内存:>= 32G
⽂档定位
AIGC 主流开源模型字典
从一个DEMO讲起
Wan2.1 + InfiniteTalk(或 Wan2.2+s2v)
拆解DEMO
⻆⾊设计(⽂⽣图、服饰设计)
场景设计(图⽣图——⻆⾊+姿势+背景、光照+⻆度调整)
⾳⾊设计(⾳⾊克隆、⾃定义⾳⾊)
[ 分镜制作 ](复杂场景,本⽂不展开)
视频⽣成(⾳频+图像⽣视频、图⽣视频+⾳频对⼝型)
角色设计
传统的⻆⾊设计就是在⼀堆⼈中选⻆,或者直接找符合条件的,成本⾼、效率低。在 AI 加持下的⻆⾊设计就简单多了,在选择上有以下⼏种常⻅玩法:
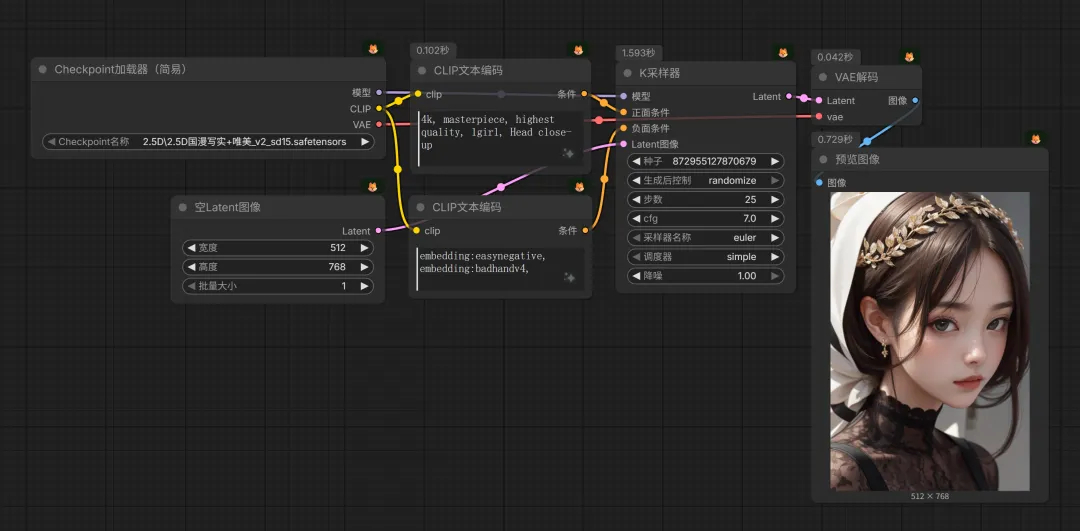
纯“⽂⽣图”,靠⾼质量的提示词控制画⻛、景别、主体的姿态等。这种⽅式随机性⼤、稳定性差,需要反复抽卡。参考⼯作流(初代产物 SD1.5):
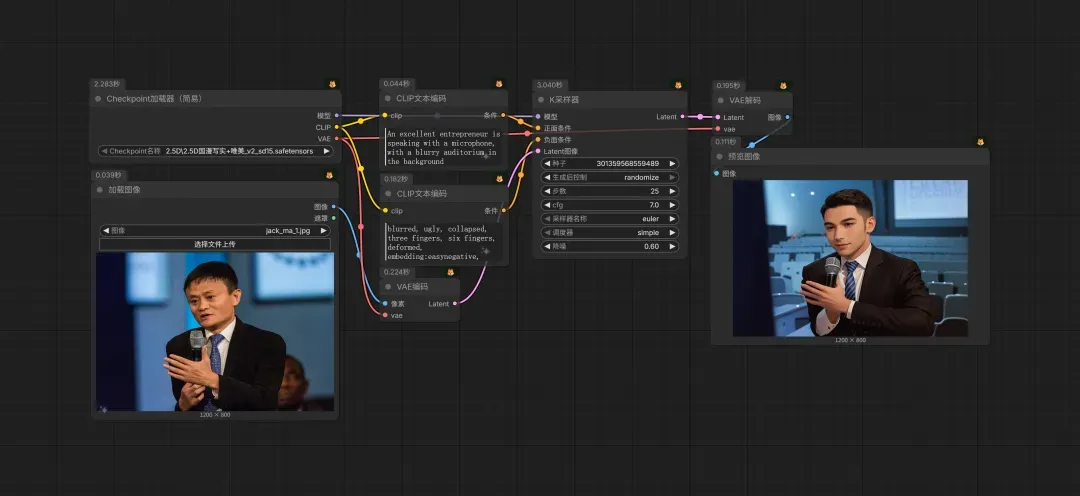
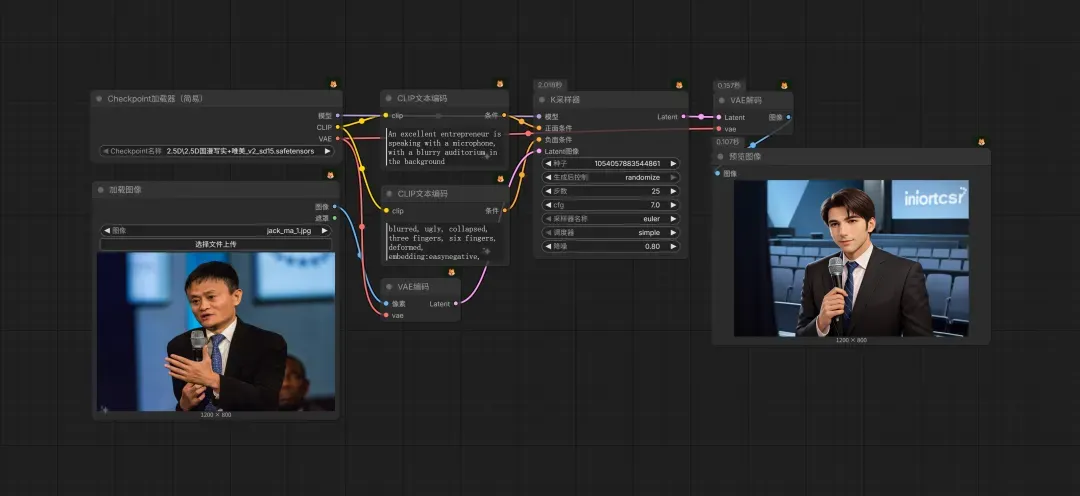
“图⽣图”,参考⽹上公开的名⼈、明星的照⽚,使⽤⼤模型重新采样后,⽣成新的⻆⾊照⽚。这种⽅式⽐纯⽂⽣图有更强的控制能⼒,但也存在⼀些副作⽤——需要反复调测出⼀个合适的降噪因⼦,否则也很难得到理想的结果。⽽且每个⼤模型对于降噪因⼦的处理结果会有差异,因此复⽤性也不够⾼。参考⼯作流(初代产物 SD1.5)
“⽂⽣图”+“Controlnet”(另⼀种形式的图⽣图),设计或寻找⼀个符合要求的参考图(Pose/Depth/Canny...),然后让⼤模型根据该参考图⽣成⽬标⻆⾊。该⽅式显然具备了更强的⾃主控制能⼒,同时也保留了⾜够的 AI 创作空间(⽐如:参考姿势⽣图,服饰、形象、肤⾊等就可以交给 AI 来处理)。参考⼯作流(当下主流 Z-Image):
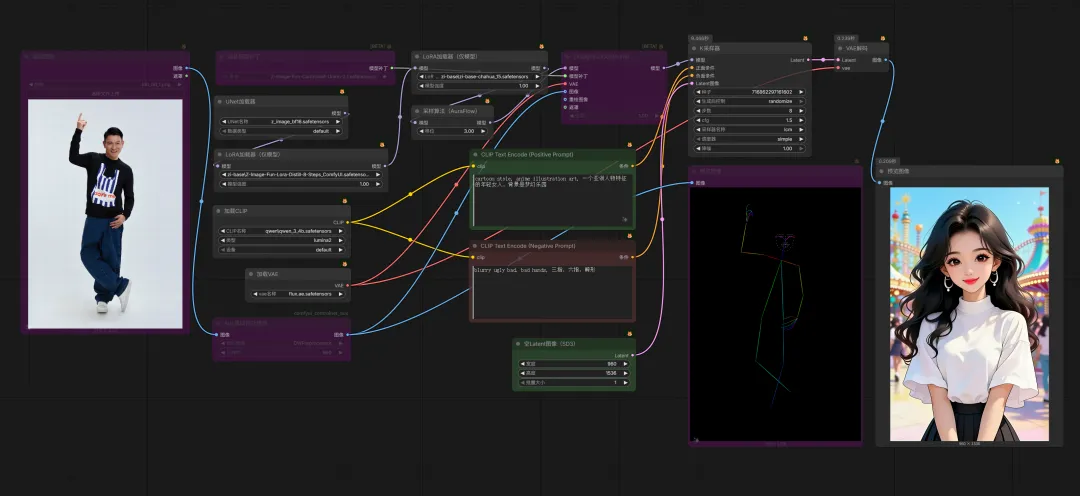
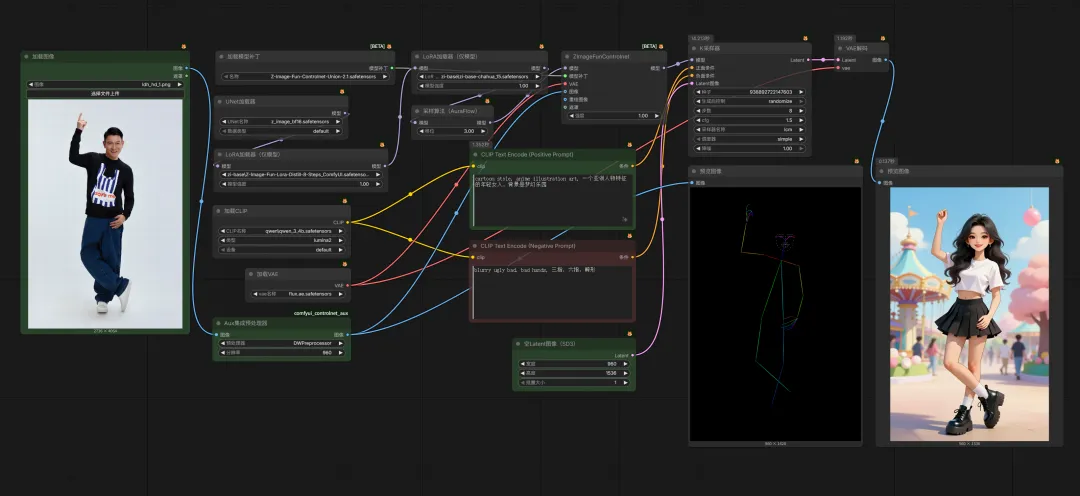
终极(提示词+Controlnet+LoRA),Controlnet 已经很优秀了,但是还有个⽐较致命的问题。如果想要多次创作中⽣成同⼀个⼈物(⻆⾊),Controlnet 还不够。为⻆⾊训练⼀个 LoRA 模型就能完美解决这个问题,有了⻆⾊ LoRA,⽆论⽣成多少次,⽆论换成什么姿势,都能得到同⼀个⻆⾊。参考⼯作流(当下主流 Z-Image):
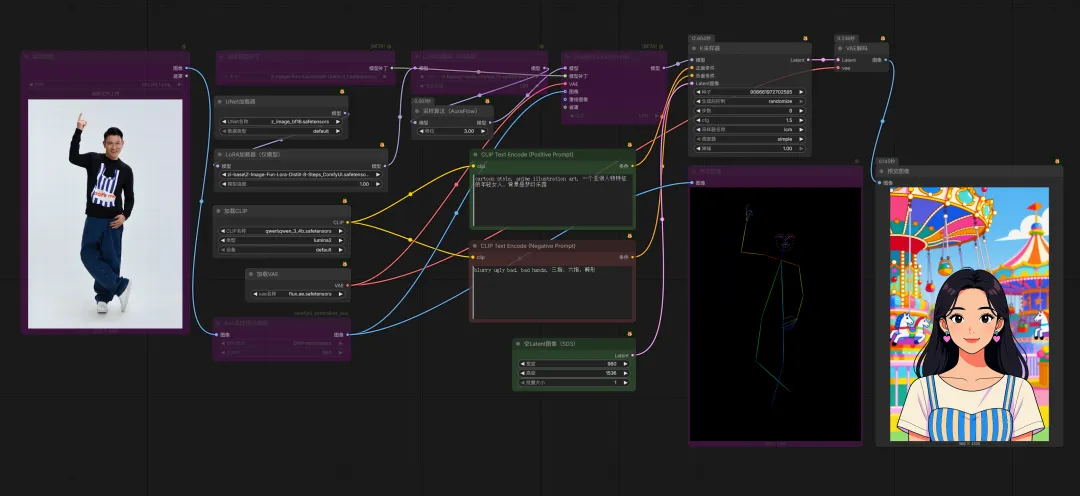
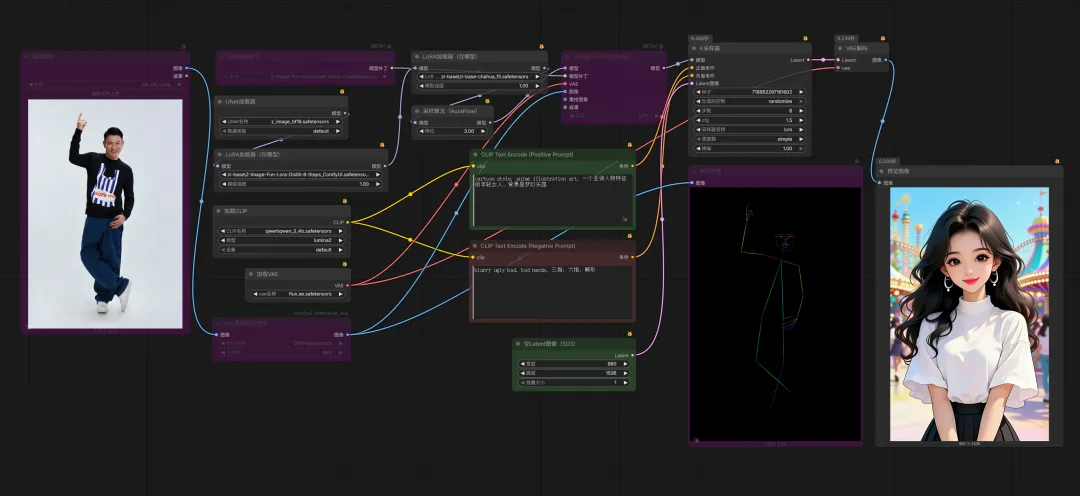
场景设计
场景设计,主要是在⻆⾊基础之上增加环境、道具等视觉元素,同时也可以对⻆⾊形象进⾏再创作。当然,在⽣成⻆⾊的时候,同时将场景设计好也是可以的。只不过:
⼀来模型能⼒有限,越复杂的画⾯,产⽣问题的概率就越⾼,分开处理相对更稳定
⼆来模型能⼒本身有侧重,有的擅⻓⽣成⼈物,有的擅⻓⽣成场景不纠结,这部分主要是为了展示图像编辑⼤模型,实现多图融合、局部调整等玩法。
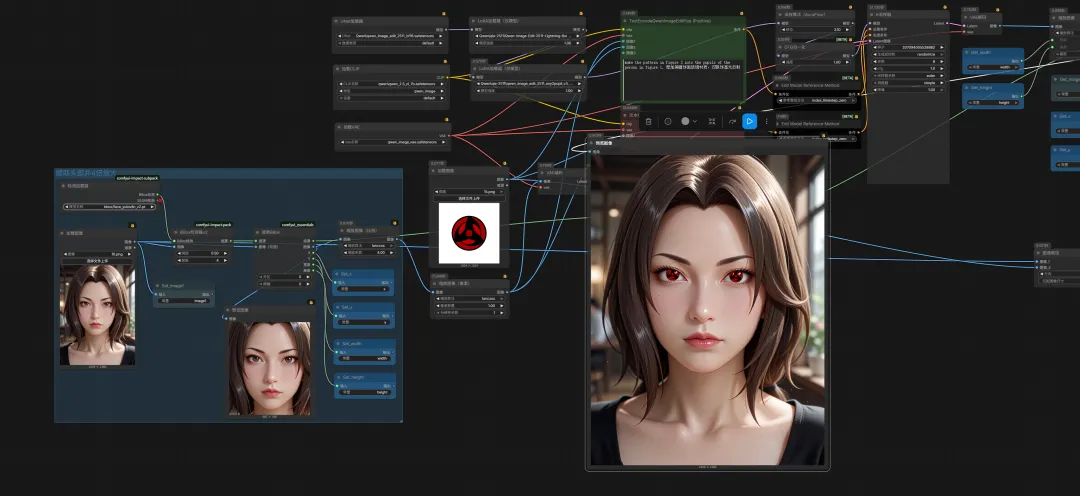
⽐如想要调整⻆⾊的视⻆,使其能与背景融合更协调
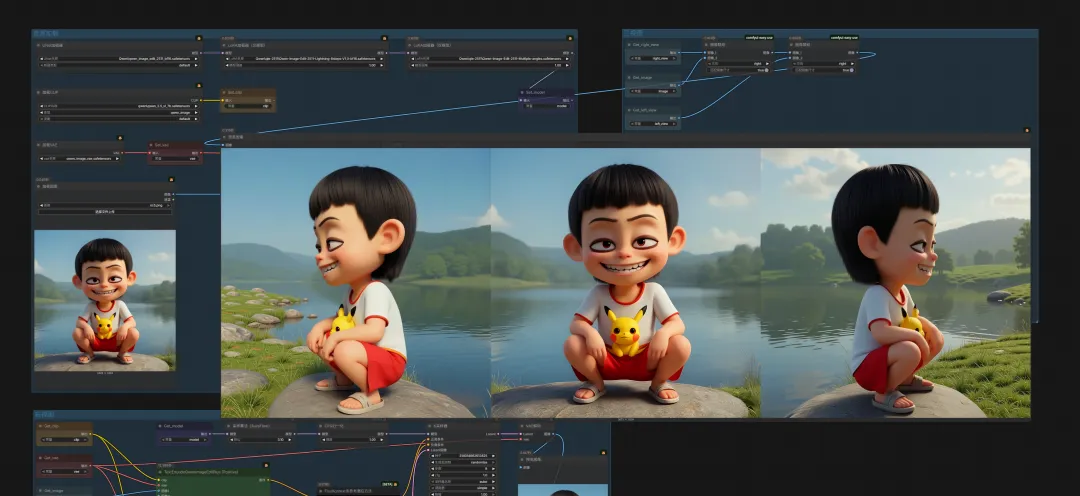
⽐如想调整⼀下⼈物的服饰、给⻆⾊增加⼀些修饰
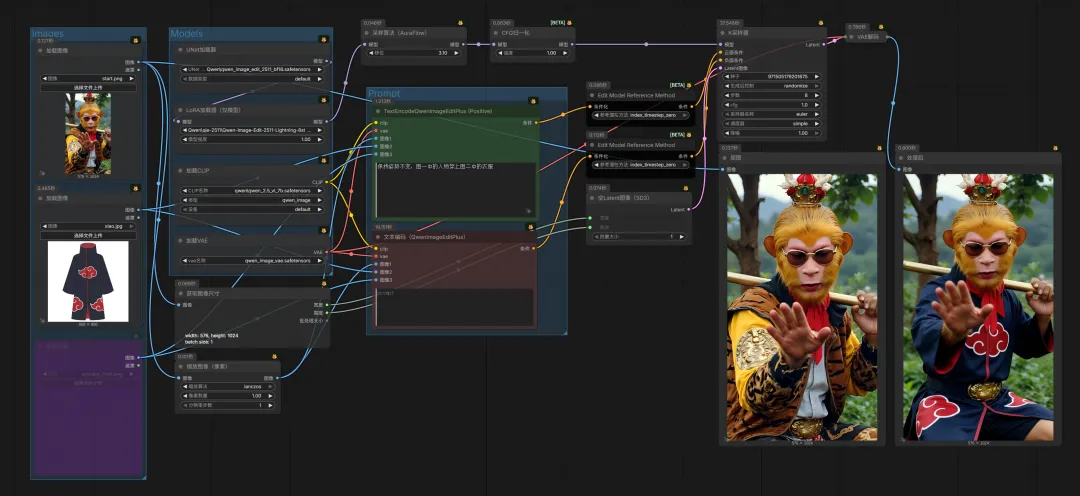
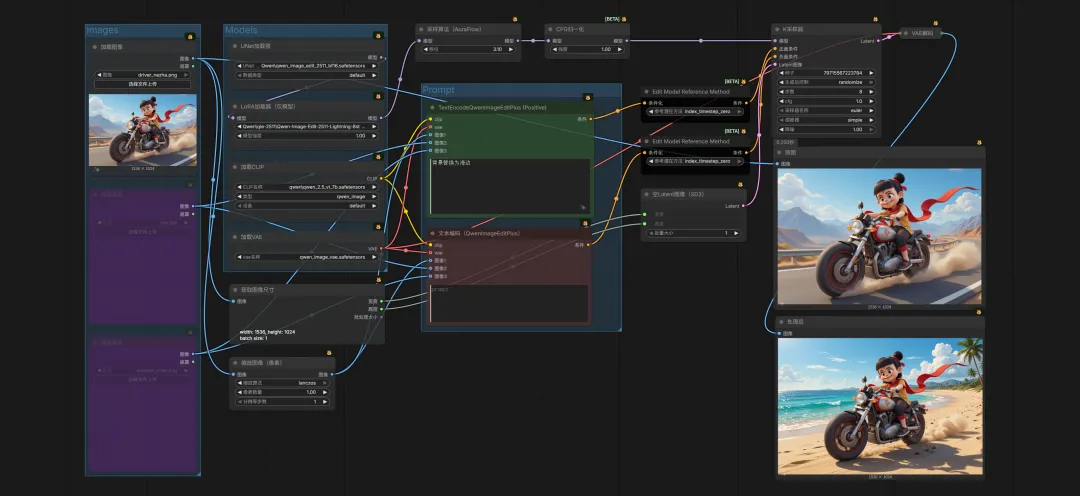
最后,将⻆⾊融⼊到场景中,可以直接改⻆⾊图背景,也可以将⻆⾊迁移到新的场景图⽚中去
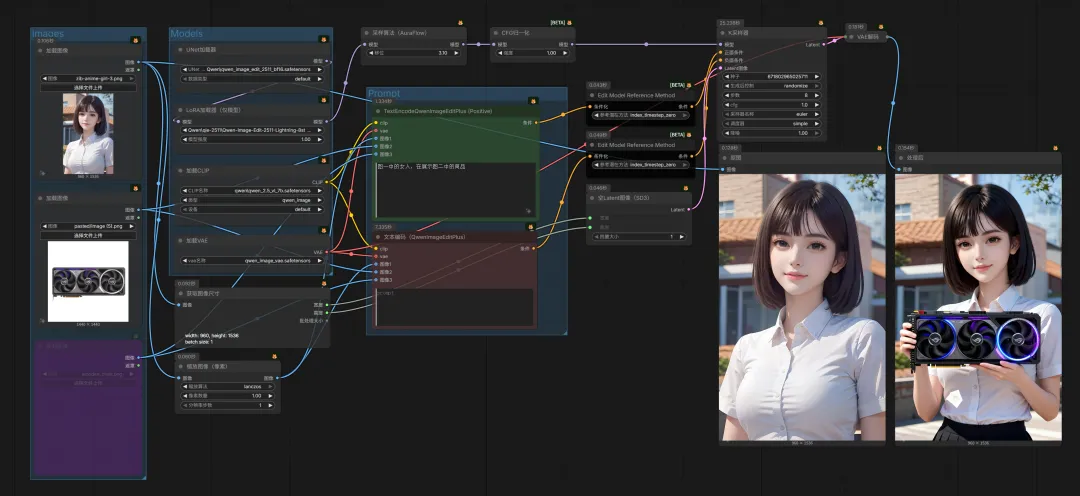
延伸⼀下,在电商场景,如果你是卖货(服装、卖显卡等任何商品)的商家,已经不需要花费⼤量的资⾦去请模特⼉拍试装照⽚了。
 | 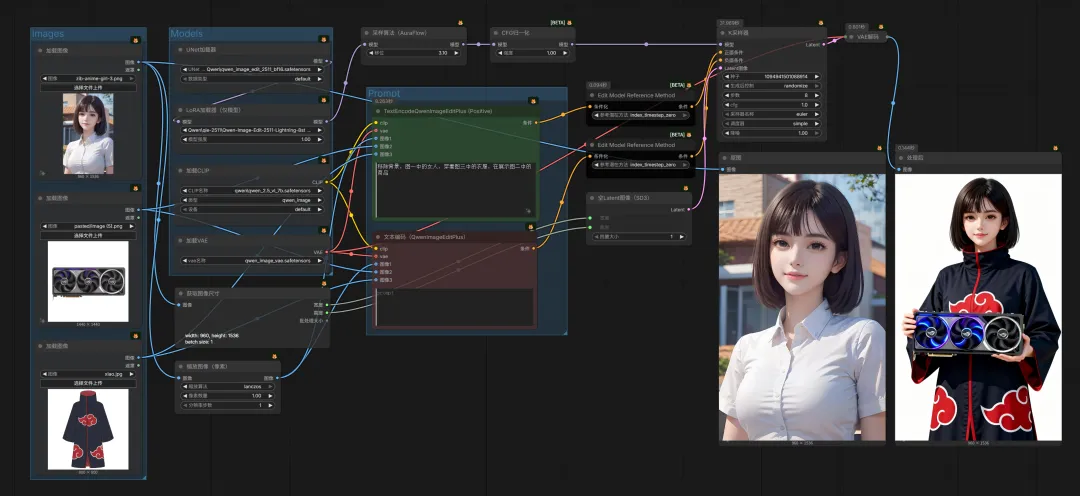 |
此外,图像编辑模型让移除物品、材质替换、⻛格转换等常⻅功能变得⾮常简单。
音色设计
原声配⾳。拿个⻨克⻛,找个安静的环境正常录制就好了,不是本⽂讨论的重点。
⾳⾊克隆。这也是 AI 应⽤的⼀个核⼼领域——通过⼀段简短的原始⾳频(⼀般 3s-30s),克隆后⽤于任何其他⽂本内容转⾳频输出,⾳⾊与原声接近。虚拟直播、录播必备!常⽤的开源⾳⾊克隆⼤模型有:Qwen3-TTS(通义)、IndexTTS2(B 站)、MegaTTS3(字节)、VibeVoice(微软)。
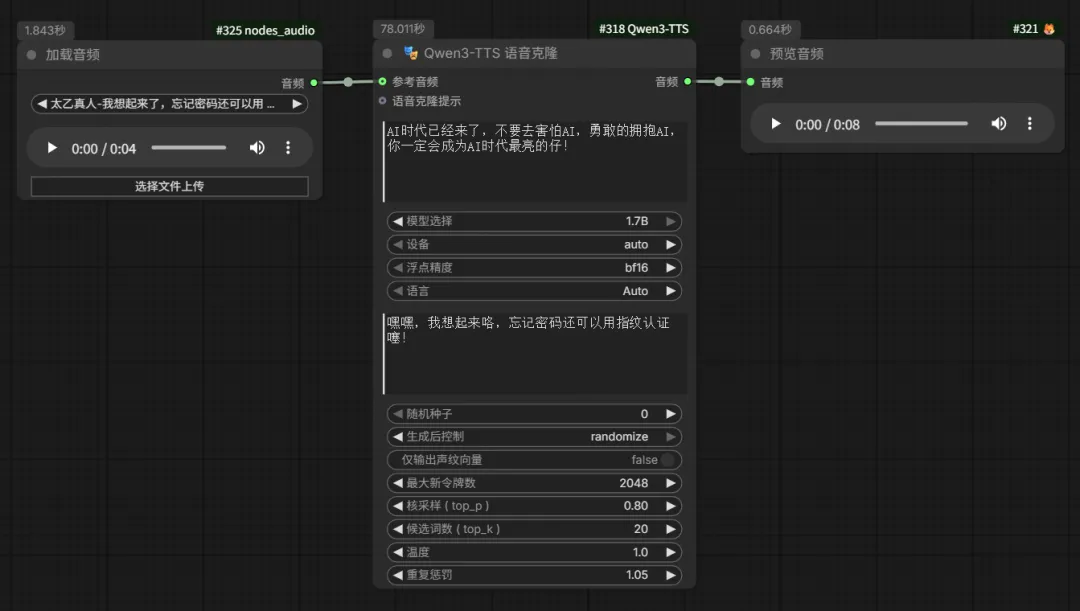
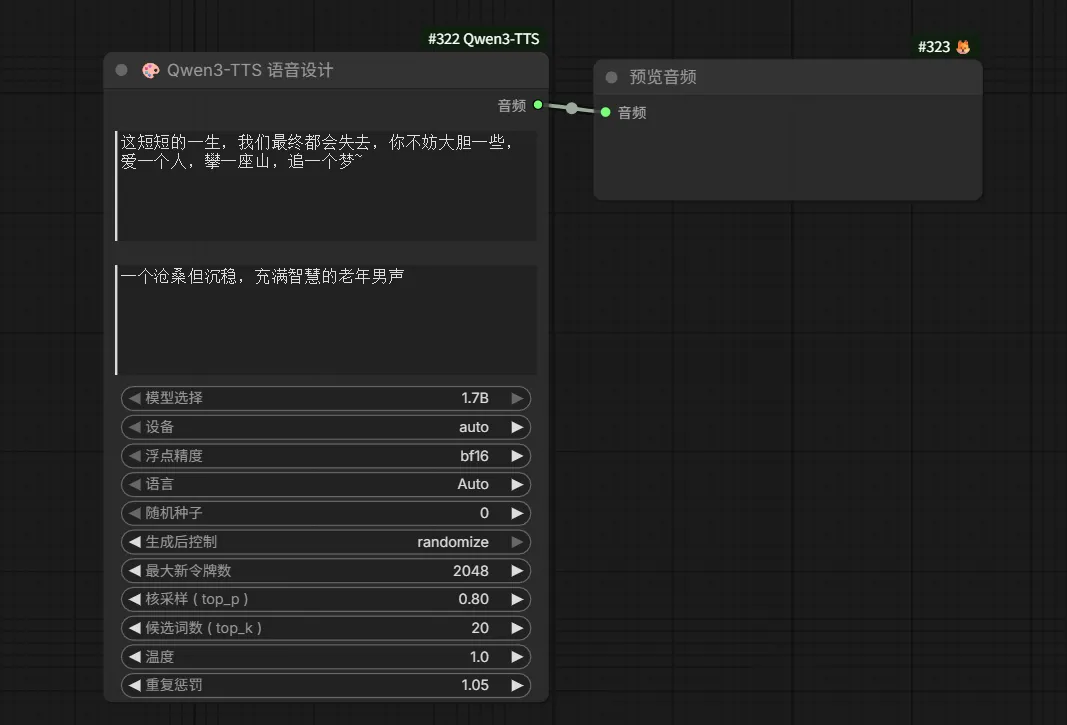
⾳⾊设计。这个更加灵活,⽬前开源模型中,继 Qwen3-TTS 之后,越来越多⼤模型提供了该能力——⼀句话创造(VoiceDesign)⾳⾊。然后使⽤独特的⾳⾊制作⽂本转语⾳。
⽽对于背景⾳,有⼀⼿原始素材⾃然最好。不过有时候也可以使⽤⼤模型直接⽣成纯⾳乐(⽐如:stable-audio-open),或者也可以从⼀些公开⾳频中分离背景⾳,可实现将⼀段合成⾳频分离出:背景⾳(纯⾳乐)、乐器、⼈声。
视频生成
⽬前主流的开源视频⽣成⼤模型有:万相(Wan2.1/2.2)、LTX-2/2.3、SkyReels-V3、混元。闭源的话 Seedance 2.0、HappyHorse 1.0、Wan2.5/2.6/2.7。视频⽣成跟图像⽣成⽐较类似,⽀持⽂⽣视频、图⽣视频(⾸帧、⾸尾帧),另外还有⼀种语⾳⽣视频(A2V、S2V)。⾯临的问题也跟图像类似——⼀致性。有少量模型也⽀持视频⽣视频(V2V),效果都不太好、VACE 参考⽣视频、Wan-Animate 视频⼈物替换。截⽌本⽂整理到该阶段的时候,LTX2.3 已经强势崛起,⼤有超越 Wan2.2 成为开源视频⽣成⼤模型⼀哥的趋势。
⽂⽣视频⼀个⼯作流,同时⽀持⽂⽣视频、图⽣视频、⾳频+图像⽣视频
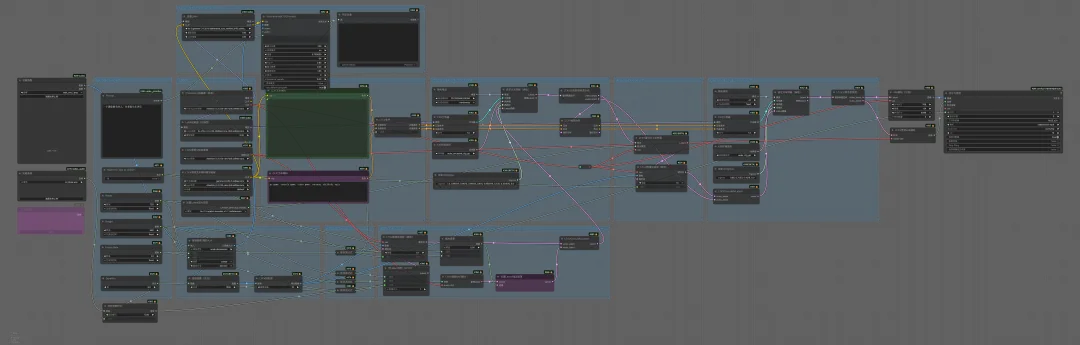
图生视频只需关闭“Switch to Text to Video”即可切换为图⽣视频模式
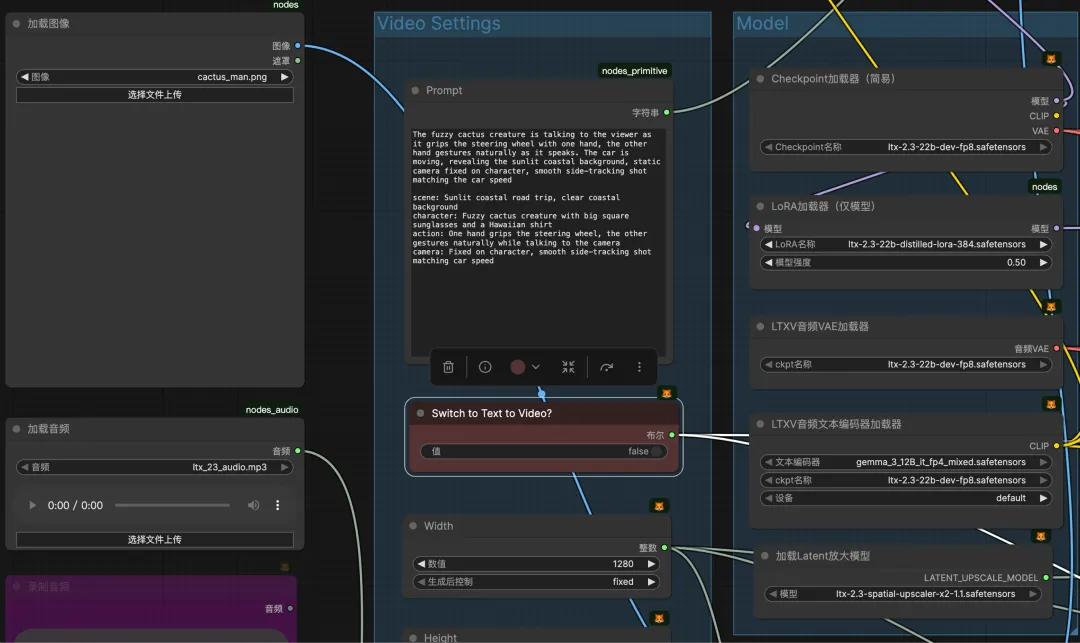
⾳频⽣视频只需加载/录制⾳频,即可启⽤⾳频⽣视频模式
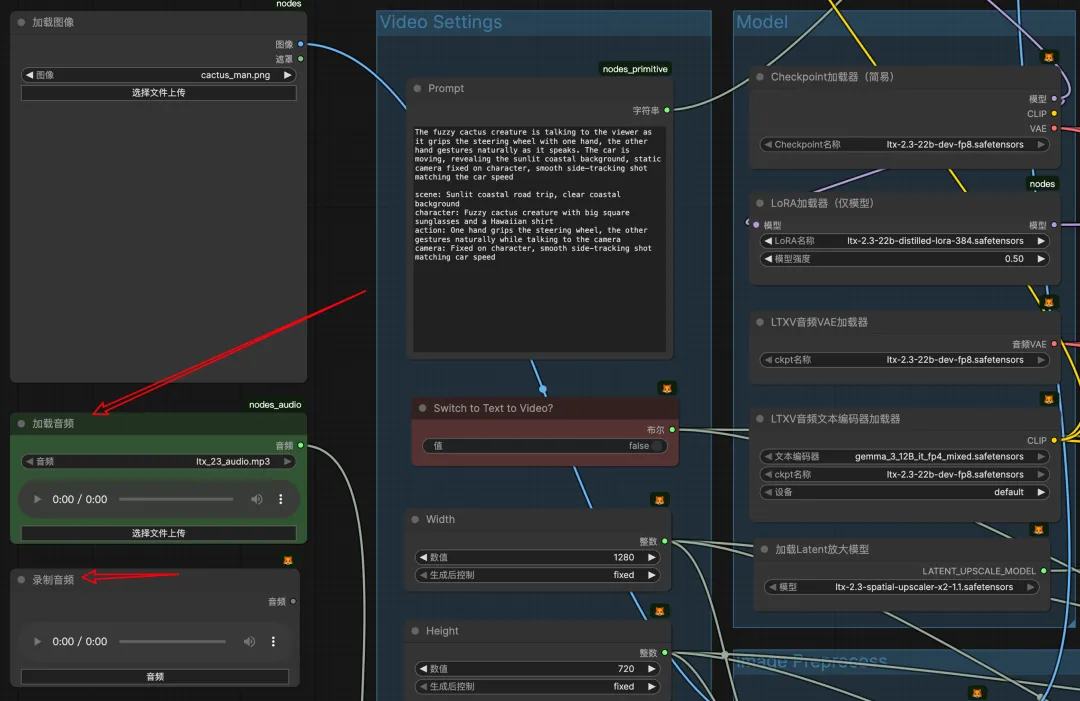
更多案例
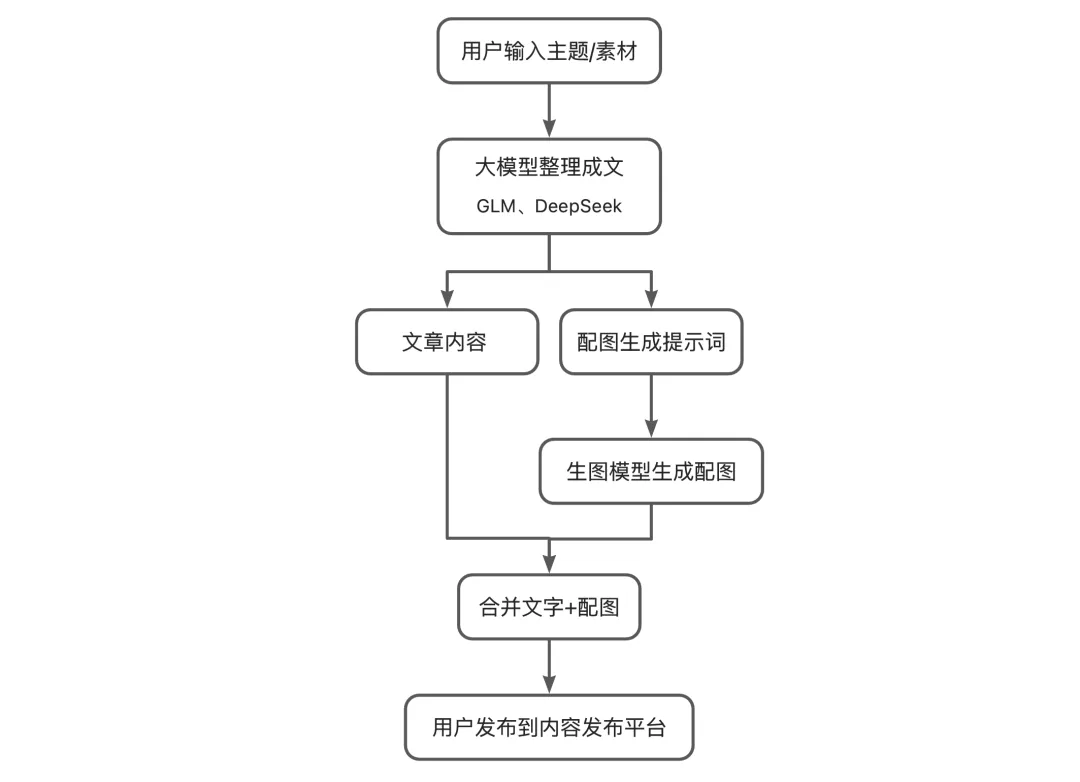
案例⼀:内容⽣产

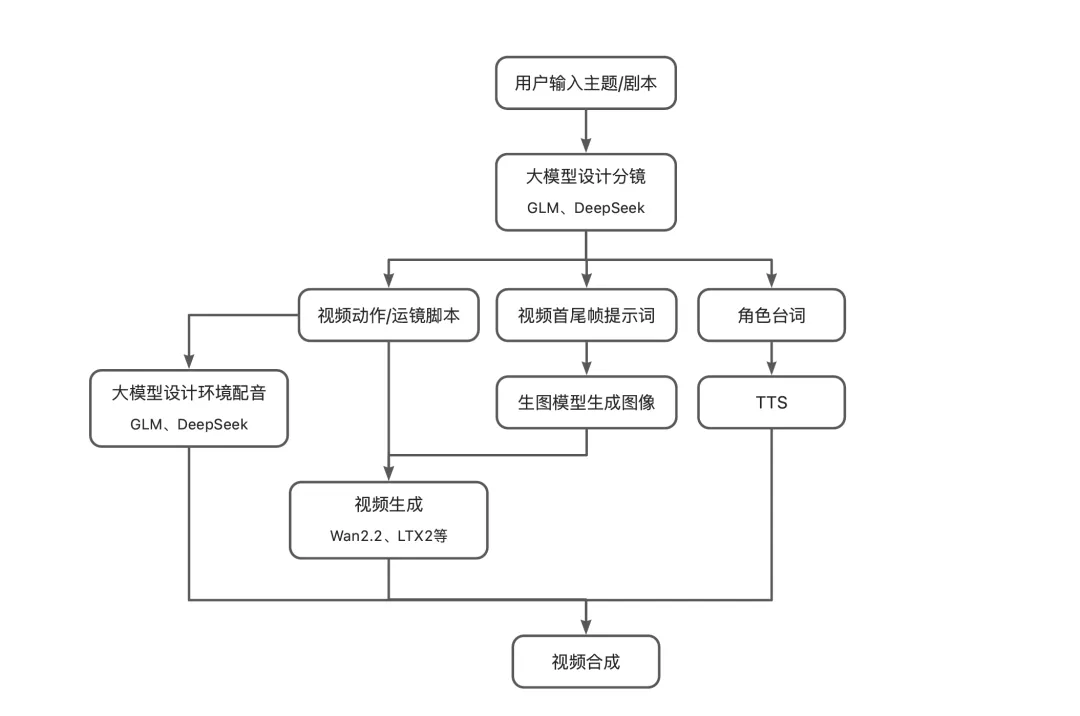
案例⼆:短视频制作
主角登场
ComfyUI ,⼀个从个⼈开源项⽬成⻓为正规军的 AIGC ⽣产⼒⼯具。
更多/附录
了解到的主流模型汇总:
⽂本(提示词辅助⽣成):Qwen3-VL、Deepseek-R1 < 32B、GLM-4.x-flash、Qwen3.5 系列
提示词反推:Qwen3-VL、JoyCaption
⽂⽣图/图⽣图:Z-Image(base、turbo)、Qwen-Image-2512、Flux.2-klein(9B、4B)、Flux.1-dev
图像编辑:Qwen-Image-Edit-2511、FireRed-Image-Edit-1.0(1.1)、Flux.2-klein(9B、4B)、Flux.1-Kontext-dev
图⽣视频/⽂⽣视频:LTX2.3、Wan2.1/2.2、SkyReels-V3、HunyuanVideo 1.5
ASR & TTS:Qwen3-ASR、Whisper、Qwen3-TTS、IndexTTS2、MegaTTS3、VibeVoice
⾳频⽣成:Stable-audio-open、HeartMula、ACE-Step-1.5
模型来源:
魔搭:https://modelscope.cn/
HF-Mirror:https://hf-mirror.com/
Huggingface:https://huggingface.co/
C 站:https://civitai.com/
体验渠道:
仙宫云:https://www.xiangongyun.com/register/9AWIBI,独享GPU,不排队。
(使用邀请码注册(9AWIBI),送8元体验金,可畅玩2-3小时)
RunningHUB: https://www.runninghub.cn/?inviteCode=1j3wz6sr(普通⽤户每⽇免费赠送 100 积分,按运⾏时⻓扣除积分,可以使⽤邀请码注册,邀请⼈和注册者可分别获得 500 体验积分)
LibLib: https://www.liblib.art/viphome?referralCode=KnvxCGWz(普通⽤户每⽇免费赠送 20 积分,按运⾏次数扣除积分)
