 夜雨聆风
夜雨聆风AI理财师来了:帮你管钱的同时,也收割你的数据从行业数据、企业案例与经济学理论的多维审视
一、当你的理财师“比你更懂你”
晚上十一点,你刷开手机里的理财App,一个微笑的机器人头像弹出:“您好,根据您的风险偏好和财务状况,我为您推荐以下三只基金……”你没有填过任何问卷,没有做过任何风险评估,它却知道你的风险偏好、财务状况、甚至你昨晚在电商平台上犹豫了半小时没下单的那双鞋子。这不是科幻电影,这是2026年每天都在发生的真实场景。
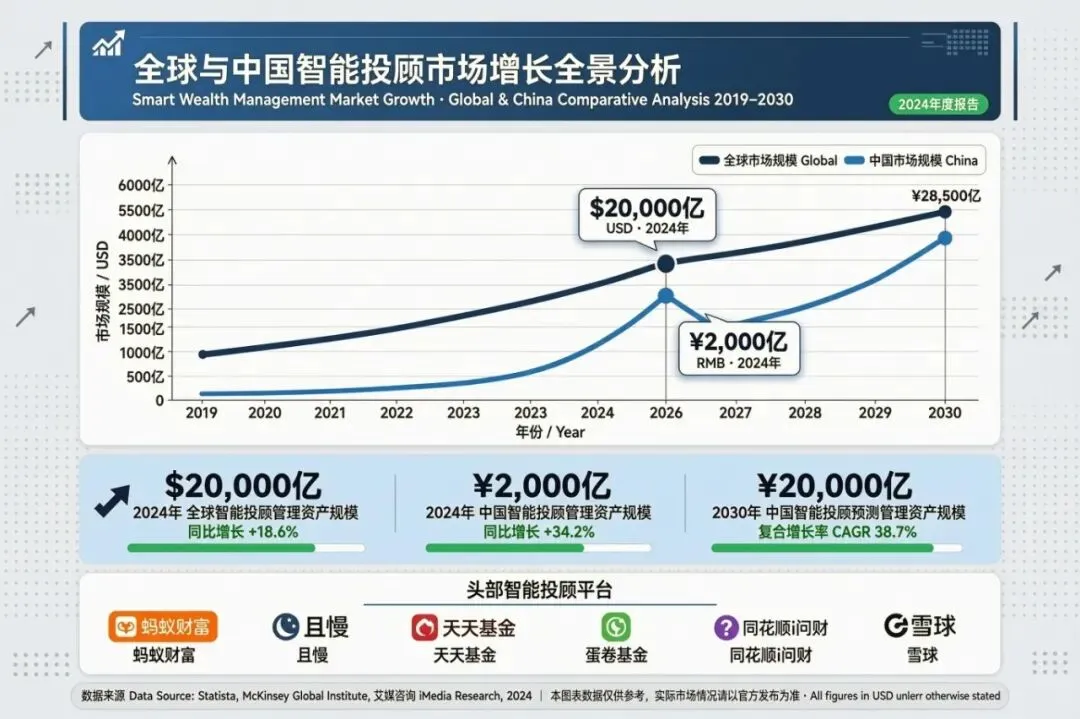
AI理财师——或者用行业术语叫“智能投顾”(robo-advisor)——正在以前所未有的速度重塑普通人的财务决策方式。根据Statista的数据,2024年全球智能投顾管理的资产规模已突破2万亿美元,较上一年增长超过30%。在中国,中研普华预测,智能投顾市场规模将在2030年突破2000亿元人民币大关。从蚂蚁基金到且慢,从天天基金到盈米基金,几乎每一家头部理财平台都在推出自己的AI理财师。低门槛、零费用、全天候在线——这些标签让AI理财师看起来像是普通人的福音。
但是,当你兴冲冲地把自己的财务数据交给一个算法的时候,你有没有想过一个问题:它到底是在帮你管钱,还是在收割你的数据?这个问题并非危言耸听。事实上,当我们深入审视AI理财师的商业模式、数据流向和算法逻辑时,会发现一个令人不安的真相:“免费”的理财服务背后,是一套精密而隐蔽的数据收割体系。你的收入、支出、风险偏好、消费习惯、甚至你的情绪波动,都在被系统地采集、分析和变现。
本文将从行业数据、企业案例、学术研究和监管框架四个维度,深入剖析AI理财师如何在“帮你管钱”的同时“收割你的数据”,以及这一现象背后更深层的经济学逻辑和制度困境。

二、AI理财师的崛起:从“智能投顾”到“超级助手”
2.1 全球智能投顾的爆发式增长
2008年金融危机之后,一批以Betterment和Wealthfront为代表的初创企业开始用算法替代人类理财顾问,智能投顾行业由此诞生。当时的逻辑很简单:传统理财顾问收取1%的管理费,门槛高达百万美元,普通人根本享受不到专业的资产配置服务。智能投顾把这个门槛降到了几百美元,管理费只要0.25%左右,用算法替代人力,用规模效应压低成本。这个故事在过去十几年里被反复讲述,但它只是开胃菜。
真正的爆发发生在大语言模型(LLM)崛起之后。从2023年开始,AI理财师不再只是一个冷冰冰的风险评估问卷加一个资产配置算法,而是变成了能用自然语言和你对话的“超级助手”。它可以解读你的财务报表,可以分析你的消费习惯,可以根据你的“情绪状态”调整投资策略。它甚至会在你情绪低落的时候主动关心你:“我注意到您近期的消费有些冲动,是否需要调整投资计划?”这种“情感化”的交互方式,让用户产生了前所未有的亲密感和信任感。
根据Statista的数据,2024年全球智能投顾的用户数已突破1.5亿人,管理资产规模突破2万亿美元。在中国,虽然智能投顾的渗透率远低于欧美,但增速惊人。国信证券的研究报告显示,中国智能投顾市场规模有望在2028年突破20亿美元,2030年突破40亿美元。更重要的是,这些平台所积累的用户数据,已经远远超过了传统金融机构几十年的积累。

2.2 为什么大厂都在做AI理财师
理解AI理财师的数据收割逻辑,首先要理解为什么大厂都在做这件事。答案并不是“为了帮助普通人理财”这么简单。从商业模式的角度看,AI理财师对平台的价值主要体现在三个层面。第一层是显性收入:管理费、交易佣金、产品代销费。这是最容易理解的部分,也是平台自己宣传最多的部分。第二层是隐性收入:通过用户数据优化产品推荐,提高转化率,从而获得更多的代销佣金和流量变现收入。第三层则是最隐蔽也最丰厚的:数据资产本身的价值。
宾夕法尼亚大学法学院教授Jill Fisch等人在其开创性研究中指出,智能投顾平台的商业模式本质上是一种“数据变现”模式,其核心逻辑是用低价甚至免费的理财服务吸引用户,然后通过采集和加工用户数据来实现商业变现。这与社交媒体平台的逻辑如出一辙:免费的最贵,因为你本身就是产品。但与社交媒体不同的是,金融数据的敏感度和商业价值远远超过了你的点赞和转发。你的收入水平、消费习惯、风险偏好、投资经历——这些信息的组合可以精确地描绘出你的“财务DNA”,而这种DNA在数据市场上的价格是极其高昂的。
三、“免费”的代价:数据收割的三层逻辑
3.1 第一层:显性数据采集——你主动交出的一切
当你注册一个AI理财平台时,你需要填写什么?姓名、身份证号、手机号、银行卡号、收入范围、投资经验、风险偏好——这些是最基本的。但很多平台还会要求你授权查询银行流水、上传财务报表、绑定第三方支付账户。你以为这是为了“更好地服务你”,但实际上,每一项数据都在丰富你的“财务画像”。这个画像的精细程度,远超你的想象。
以某头部理财App为例,其用户注册时需要填写的信息包括:基本个人信息(姓名、身份证、手机号)、职业信息(行业、职位、工作年限)、财务信息(年收入、年支出、房贷、车贷、存款余额)、投资信息(持有基金、股票、保险、理财产品的详细列表)、风险偏好(通过长达几十题的问卷确定)。这些信息单独拿出来任何一项都不算什么,但当它们被组合在一起时,就构成了一个极其精准的用户画像。知道你的收入、支出和风险偏好,就能推断你的消费能力、借贷能力和投资潜力。知道你的职业和行业,就能推断你的收入稳定性和职业风险。这些信息的组合,对于任何一个想要向你推销金融产品的机构来说,都是无价之宝。
3.2 第二层:隐性行为追踪——你以为你没有说的,它都知道
如果说显性数据采集是“你告诉它的”,那么隐性行为追踪就是“它偷看的”。当你在理财App里浏览基金详情页时,平台在记录什么?你的点击路径、停留时间、滑动速度、返回次数、收藏行为、分享行为——每一个微小的交互动作都被忠实地记录下来。你在某只基金的详情页停留了三分钟但最终没有购买,这个信息的价值并不低于你实际购买的那只基金。因为它揭示了你的“犹豫”——而犹豫意味着意向,意向意味着转化的可能。
Privacy International的一项调查研究揭示,金融科技应用正在收集和利用越来越多关于用户行为、兴趣、社交网络和个性的数据,以用于商业目的。该报告指出,许多金融科技公司的数据采集范围远超了提供服务所必需的范围,而用户对此几乎一无所知。更值得警惕的是,这种行为追踪并不仅仅是“记录”,而是“解读”。通过自然语言处理和情感分析技术,AI可以从你的浏览行为中推断你的情绪状态。你在晚间十一点到凌晨两点之间频繁打开理财App?你可能有失眠焦虑。你反复查看同一只基金的收益率但从不赎回?你可能是“损失厌恶”型投资者。这些推断结果,会被用于优化产品推荐策略——但优化的目标不一定是你的收益最大化,而是平台的转化率最大化。
3.3 第三层:衍生数据加工——从数据到“武器”
如果说显性采集和隐性追踪还只是“原材料”,那么衍生数据加工就是“精炼”。AI理财师的算法不仅仅是在原始数据的基础上做简单的统计分析,而是通过深度学习模型生成全新的衍生变量。你的收入和支出数据可以被用来计算你的“财务压力指数”,你的浏览行为可以被用来计算你的“冲动消费倾向”,你的交易频率可以被用来计算你的“过度交易风险”。这些衍生变量对于用户来说是不可见的,但对于平台来说却是极其有价值的。
哈佛商学院教授Shoshana Zuboff在其开创性著作《监视资本主义》中提出,当代经济中出现了一种全新的资本主义形态,其核心逻辑不是生产商品,而是提取和变现人类行为数据。她将这种数据提取过程称为“行为剩余”(behavioral surplus)——即超出提供服务所必需的那部分数据。在AI理财师的场景中,“行为剩余”的提取规模和深度远超社交媒体。因为金融数据不仅反映你的行为,还反映你的财富、信用、风险承受能力——这些都是可以被精确变现的经济属性。
更关键的是,这种衍生数据加工往往发生在用户完全不知情的情况下。你知道你填了风险评估问卷,但你不知道平台从你的回答中提取了多少衍生变量。你知道你的交易被记录了,但你不知道平台用这些数据训练了什么样的模型。这种不对称信息——平台对你了如指掌,你对平台一无所知——正是数据收割的核心机制。
四、数据变现的隐秘链条:从“帮你管钱”到“卖你的画像”
4.1 数据经纪商的灰色产业链
你的金融数据到底去了哪里?这个问题的答案比你想象的更复杂。在金融科技生态中,存在着一条隐秘的数据流转链条:AI理财平台采集原始数据,经过加工生成用户画像,然后通过数据经纪商向下游买家出售。数据经纪商是这条链条中的关键环节——它们从多个渠道聚合数据,清洗、标准化、增强,然后卖给广告商、保险公司、贷款机构、甚至雇主。
根据Sigma Computing的研究,金融服务行业的数据变现已经形成了一个庞大的产业。金融机构可以通过多种方式变现其数据资产:内部使用(优化自己的产品和服务)、数据共享(与合作伙伴共享脱敏数据)、以及外部出售(直接向第三方出售用户数据)。其中,内部使用是最常见也是最隐蔽的,因为它不涉及数据的外部转移,仅仅是在平台内部将用户数据用于优化产品推荐和广告投放。但无论哪种方式,用户通常都不知道自己的数据被如何使用。
特别值得关注的是,金融数据在数据市场上的价格远高于其他类型的个人数据。根据哥伦比亚法学院的研究,金融数据的单价可以是普通社交数据的数十倍乃至数百倍。一条包含收入、消费习惯和信用状况的金融画像,在数据市场上的价格可以高达数百美元。而一条普通的社交媒体用户画像,可能只值几美分。这就解释了为什么AI理财师愿意提供“免费”服务——因为你的数据本身就是最有价值的产品。
4.2 “内部使用”的隐蔽性
在所有数据变现方式中,“内部使用”是最难被监管也是最广泛存在的。当一个AI理财平台用你的数据来优化其推荐算法时,这算不算“出售”你的数据?从法律角度看,这可能不算,因为数据没有转移给第三方。但从经济学角度看,这完全是一种变现行为——平台用你的数据训练了算法,算法又被用来服务其他用户,产生了商业价值。你的数据成了平台的“免费劳动”,而你没有得到任何补偿。
更深层的问题在于,“内部使用”的边界极其模糊。当一个集团下属的理财平台和保险公司“共享”用户数据时,这算“内部使用”还是“外部出售”?在中国,许多金融科技集团都是“金融持牌+理财平台+保险代销”的综合体,用户在理财平台上留下的数据,可以被无缝地用于保险产品的精准营销。用户以为自己只是在买基金,但实际上已经被当作了保险客户来培育。这种跨业务的数据流转,在现行法律框架下往往处于灰色地带。
五、算法偏见与金融歧视:当算法“看不见”性别却“看见”了更多
5.1 Apple Card事件:一场关于算法歧视的警示
2019年11月,一条推文引爆了全球关于算法歧视的讨论。苹果公司联合高盛推出的Apple Card被曝光存在性别歧视:多位女性用户发现,尽管自己的信用评分和收入高于丈夫,但获得的信用额度却远低于丈夫。最著名的案例是苹果联合创始人Steve Wozniak的妻子,她的信用额度只有丈夫的十分之一,尽管两人共享财产且她没有任何不良信用记录。
高盛的回应是:算法不会考虑性别因素。这句话本身是真的——Apple Card的信用评估算法确实没有直接使用性别作为变量。但问题的关键在于,算法不需要“看见”性别,就能“看见”性别的代理变量。当算法使用你的消费记录、购物商家、支出模式等数据时,它可以通过这些变量间接地推断出你的性别。比如,经常在女装店消费的人大概率是女性,而算法会据此调整信用额度。纽约州金融服务局(NYSDFS)历时两年的调查最终认定,虽然没有发现故意歧视的证据,但算法的“不可解释性”本身就是问题的核心。
5.2 “数学杀伤性武器”的三重标准
MIT数据科学家Cathy O’Neil在其影响深远的著作《数学杀伤性武器》(Weapons of Math Destruction)中,提出了识别“有害算法”的三重标准:不透明性(opacity)、不公平性(unfairness)和规模性(scale)。当一个算法同时满足这三个条件时,它就成了一件“数学杀伤性武器”。用这个框架来审视AI理财师,我们会发现令人不安的对应关系。
首先是不透明性。AI理财师的推荐算法是典型的“黑箱”,用户无法知道为什么被推荐某只基金而不是另一只。其次是不公平性。算法可能对某些群体系统性地推荐更高风险的产品,或者对某些群体系统性地给予更低的信用额度,就像Apple Card事件所揭示的那样。最后是规模性。AI理财师的用户数以亿计,一个微小的算法偏差就可能影响数百万人的财务决策。当这三个条件叠加在一起时,AI理财师就不仅仅是一个“工具”,而是一个可能系统性地制造不公平的“武器”。
O’Neil特别强调,算法偏见的危险之处不在于它是“故意的”,而在于它是“无意的”。没有人故意设计一个歧视女性的算法,但当算法从历史数据中学习时,它会自然而然地再生产已有的社会偏见。在金融领域,这种“无意偏见”的后果尤其严重:它可能导致某些群体系统性地获得更少的投资机会、更高的贷款利率、更低的信用额度,从而形成一个自我强化的恶性循环。
六、监管的追赶:全球数据保护框架的进展与局限
6.1 欧盟:GDPR与EU AI Act的双重防线
在全球数据保护的版图中,欧盟无疑走在了最前列。《通用数据保护条例》(GDPR)自2018年生效以来,已经成为全球数据保护的金标准。它确立了“数据最小化”原则、“明确同意”要求和“被遗忘权”,为用户提供了强有力的数据权利保障。但GDPR主要针对的是数据采集和处理行为,对于算法本身的透明度和公平性,其约束力相对有限。
2024年正式生效的《欧盟人工智能法案》(EU AI Act,法规编号2024/1689)则填补了这一空白。该法案将AI系统按风险等级分为四类,其中金融服务领域有两个明确的“高风险”用例:用于评估个人信用资质的AI系统,以及用于风险评估和定价的AI系统。这意味着,如果一个AI理财师的算法涉及信用评估或风险定价,它就必须满足严格的透明度、数据质量和人工监督要求。这是全球首个对AI在金融领域的应用进行系统性立法的尝试,其影响将是深远的。
但欧盟的双重防线也并非万无一失。GDPR的执行依赖于各成员国的监管机构,执行力度参差不齐。EU AI Act的完整实施时间表延至2026年乃至2027年,而技术的发展速度远远超过了立法的速度。更重要的是,欧盟的监管框架主要是“约束性”的,而非“激励性”的——它告诉企业不能做什么,但没有告诉企业应该做什么才能真正保护用户权益。
6.2 中国:三法并行与执行挑战
中国的数据保护立法以《网络安全法》《数据安全法》《个人信息保护法》三部法律为核心,形成了“三法并行”的格局。其中,《个人信息保护法》确立了“最小必要”原则和“单独同意”要求,《数据安全法》将数据分为三级并对重要数据实施重点保护,《网络安全法》则从网络运行安全的角度提出了数据安全要求。2025年1月,《网络数据安全管理条例》正式施行,从行政法规层面将三部法律的要求细化落实。
然而,执行层面的挑战依然巨大。根据KPMG的报告,2024年人民银行及金融监管总局向银行、保险、证券等金融机构相关责任人员共开出罚单1491张,处罚金5866.42万元,涉及1844人。这个数字看起来不小,但相比于金融机构的巨额利润和数据违规的普遍程度,实际上只是“九牛一毛”。更关键的问题在于,现行监管主要关注的是“数据泄露”和“数据安全事件”,而对于“数据收割”和“算法偏见”这类更隐蔽的问题,监管的精力和工具都还远远不够。
具体到AI理财师领域,监管的困境更加突出。目前中国尚未出台专门针对智能投顾的监管规则,现有的证券投资顾问业务规定主要针对的是人类顾问,对算法顾问的约束力有限。当一个AI理财师向你推荐一只基金时,谁来判断这个推荐是出于你的最佳利益,还是出于平台的代销佣金最大化?这个问题在人类顾问时代就存在,但在AI时代变得更加难以回答,因为算法的决策过程是不透明的。
6.3 监管滞后性:技术迭代与制度追赶的永恒张力
无论是欧盟还是中国,监管都面临一个结构性的困境:技术的迭代速度远远超过制度的追赶速度。当监管机构终于理解了一种技术的风险并制定了相应规则时,技术已经发展到了下一个阶段。以大语言模型为例,当监管机构还在讨论如何监管基于规则的智能投顾时,基于LLM的AI理财师已经大规模上线。这种监管滞后性不是某个国家或某个机构的问题,而是制度设计本身的局限性。立法需要时间、学术研究需要时间、公众讨论需要时间,而技术的发展不等人。
更深层的问题在于,监管机构往往缺乏与技术发展匹配的专业能力。理解一个深度学习模型的决策逻辑需要专业的技术能力,而监管机构很难招到和留住这样的人才——他们在市场上的薪资远高于监管机构能够提供的。这就形成了一个恶性循环:监管能力不足导致监管滞后,监管滞后又进一步削弱了监管的威慑力,企业因此更加胆大地试探红线。
七、谁在为“免费”买单:消费者行为经济学的解读
7.1 隐私悖论:口头上说在乎,身体却很诚实
经济学家Alessandro Acquisti等人在其经典论文《隐私的经济学》中提出了著名的“隐私悖论”:消费者在问卷调查中表达了对隐私的高度重视,但在实际行为中却轻易地放弃隐私。这个悖论在AI理财师领域表现得淋漓尽致。大多数用户在注册理财App时,会直接点击“同意”按钮,而不会仔细阅读那些冗长的条款。即使他们阅读了,也很难理解其中的技术细节和潜在含义。
这种现象的根源在于三个因素的交织。第一是信息不对称:平台知道数据的真实价值,用户不知道。第二是认知偏差:人们往往低估数据泄露的概率和后果,高估自己控制数据的能力。第三是缺乏替代选择:当几乎所有理财平台都采用相似的数据采集策略时,用户实际上没有“不同意”的选择——不同意就意味着放弃使用这个服务。
Acquisti等人的研究进一步指出,当个人数据的价值被“拆分”成小块时,消费者很难对其进行正确的估价。你可能觉得“告诉一个App我的收入范围”不是什么大事,但当这个信息与你的消费记录、浏览行为、风险偏好等数据组合在一起时,它的价值就发生了质的飞跃。这就像一块拼图的每一小块都不值钱,但拼在一起却是一幅无价的画作。而用户永远只看到了单独的小块,看不到整幅画作。
7.2 注意力经济与数据经济的双重套利
AI理财师的商业模式本质上是注意力经济和数据经济的双重套利。在注意力经济层面,AI理财师通过个性化推荐和情感化交互来吸引和保持用户的注意力,让他们在App上花更多的时间、做更多的交易。在数据经济层面,用户的每一次交互都在产生数据,这些数据又被用来优化推荐算法,进一步提高用户的粘性和转化率。这是一个自我强化的正循环——对平台来说。
但对用户来说,这个循环可能是恶性的。当AI理财师越来越“懂你”时,它也越来越擅长操控你的决策。它知道什么时候推荐高佣金产品你不会拒绝,什么时候用“情感关怀”的话术能让你加大投入,什么时候用“恐惧营销”能让你不得不行动。这已经不是简单的“信息不对称”问题,而是一种系统性的“决策操控”。你以为你是在自主地做财务决策,但实际上你的决策环境已经被精心设计过了。
八、出路何在:从个人觉醒到制度重构
8.1 数据可携带权:让数据回到它的主人身边
在所有可能的制度改革中,数据可携带权(data portability)是最直接也最有效的。GDPR第20条已经赋予了用户将个人数据从一个服务提供者转移到另一个的权利,但实际执行中这个权利的实现程度还很低。在AI理财师领域,数据可携带权的意义尤其重大。如果用户可以轻松地将自己的财务数据从一个平台转移到另一个平台,那么平台就不能再用“数据锁定”来维持用户关系,而必须通过真正优质的服务来竞争用户。这将从根本上改变AI理财师的竞争逻辑。
但数据可携带权的实现面临技术和制度的双重挑战。技术上,不同平台的数据格式和接口标准不统一,数据转移的成本很高。制度上,平台没有动力主动支持数据可携带,因为数据锁定正是它们的竞争壁垒。这需要监管机构强制推行统一的数据标准和接口规范,就像欧盟在支付领域推动PSD2开放银行API那样。
8.2 算法透明度:打开黑箱的必要性
Schwarcz、Baker和Logue三位法学教授在其发表于《华盛顿与李大学法学评论》的重要论文中指出,生成式AI的出现使得智能投顾的监管问题变得更加紧迫。传统的智能投顾基于规则的算法,其决策逻辑是可以被审计和解释的。但基于大语言模型的AI理财师是“黑箱”的,连开发者自己都无法完全解释其决策过程。这就使得传统的监管工具——如适当性审计和信息披露要求——失去了效力。
解决这个问题的路径之一是“可解释AI”(explainable AI)技术的发展。如果AI理财师能够在每次推荐时提供清晰的解释——“为什么推荐这只基金而不是那只”——那么用户和监管机构就能更好地判断推荐的合理性。但可解释AI本身也面临技术挑战:模型的表现力和可解释性之间往往存在权衡,越复杂的模型越难解释。此外,即使技术上可以实现解释,平台也可能不愿意披露其算法的内部逻辑,因为这涉及商业秘密。这里需要监管机构在保护用户权益和保护商业创新之间找到平衡。
8.3 数据信托:一种新的治理可能
在所有提议中,最具前瞻性的可能是“数据信托”(data trust)模式。数据信托是一种法律架构,用户将自己的数据权利委托给一个独立的信托机构,由该机构代表用户与平台谈判数据的使用条件和补偿机制。这种模式的核心优势在于改变了力量对比——单个用户在与平台的单独博弈中毫无议价能力,但一个代表数百万用户的信托机构就完全不同了。
数据信托的理念已经在英国等国家得到了初步实践。英国的《数据信托框架》提供了一套法律和治理模板,使得数据信托能够在明确的法律框架下运作。在AI理财师领域,数据信托可以帮助解决几个关键问题:一是确保用户数据只被用于用户同意的目的,二是为用户数据的商业使用争取合理的补偿,三是对算法的公平性进行独立审计。当然,数据信托也不是万能药。它需要成熟的法律框架、专业的信托机构和广泛的用户参与,这些条件目前都还不具备。但它指向了一个重要的方向:从“用户被动接受”转向“用户主动授权”,从“平台单方决定”转向“多方協商”。
8.4 个人层面的自我保护
在制度层面的改革到来之前,个人能做什么?首先,要建立“数据最小化”的意识。注册理财App时,只提供服务所必需的最少信息,不要因为“方便”而授权查询银行流水或上传全量财务报表。其次,要学会阅读隐私条款,特别关注数据采集范围、使用目的和分享对象。再次,要利用现有的法律权利,包括查看、更正、删除个人信息的权利。最后,要对“免费”保持警觉——当一个服务是免费的时候,你很可能就是产品本身。
但我们也必须承认,个人层面的自我保护是有局限的。当整个行业都采用相似的数据采集策略时,个人的“不同意”就意味着“不能用”。这就是为什么制度层面的改革是不可替代的。只有当监管机构强制要求平台提供真正的选择权——不仅仅是“同意或不同意”的二元选择,而是“可以选择哪些数据被采集、用于什么目的、分享给谁”的精细化控制——用户才能真正地掌握自己的数据命运。
结语:你的财务DNA,谁来做主?
AI理财师的出现,确实让更多人获得了专业的财务建议,降低了理财服务的门槛。这是它的积极面,也是不容否认的事实。但我们必须清醒地看到另一面:在“普惠金融”的旗帜下,一套精密的数据收割体系正在默默运转。你的收入、支出、风险偏好、消费习惯、情绪状态——这些构成你“财务DNA”的信息,正在被系统地采集、加工和变现,而你对此几乎一无所知。
最终,我们需要回到一个根本性的问题:你的财务DNA,谁来做主?是你自己,还是那个每天对你微笑的AI理财师?答案应该是你自己。但要让这个答案从理想变为现实,需要技术的进步、制度的改革和每一个用户的觉醒。在这个数据就是资产的时代,保护自己的数据权利,就是保护自己的财产。
END
关注我们
