 夜雨聆风
夜雨聆风
本周科技圈两件事同时发生,很难说哪个更炸裂:Google I/O 2026 三连发,Gemini 3.5 Flash、Gemini Omni、Antigravity 2.0 一口气落地,把"Agent 时代到来"从 PPT 变成了产品;与此同时,Anthropic 周一宣布收购 SDK 工具公司 Stainless,周二 Karpathy 发推宣布加入 Anthropic。更离谱的是,OpenAI 同期发布一个模型,顺手解决了 Erdős 在 1946 年留下的几何猜想。Agent 军备竞赛已经从比模型变成了比生态、比工具链、比基础研究——本周 10 大技术动态,一文打尽。
🔥 本周头条
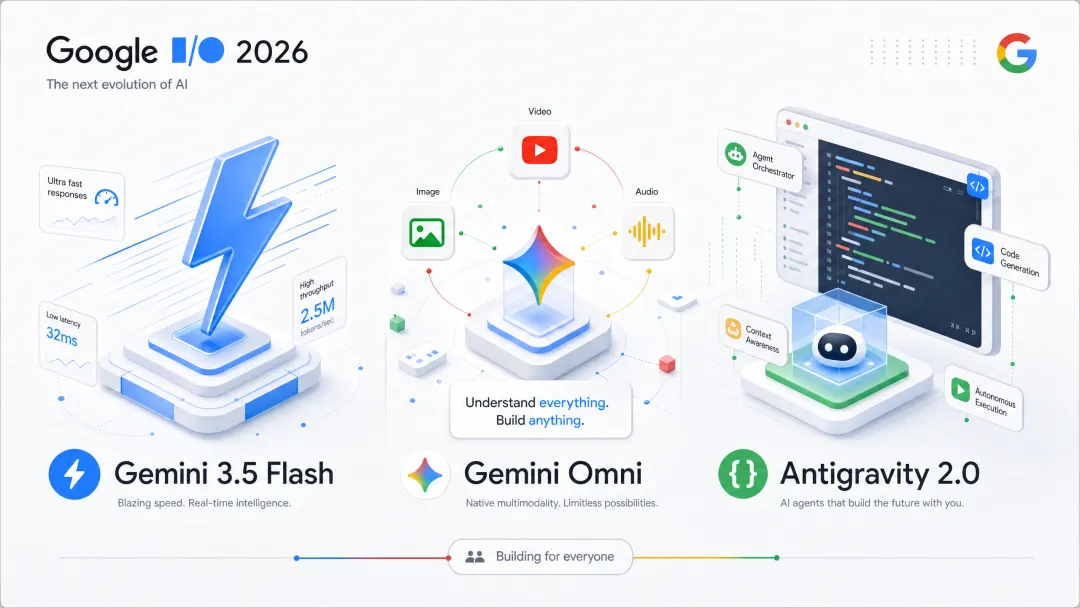
1 Google I/O 2026 三连发 — 从 Flash 到 Omni,Agent 时代全面开工
🚀 [产品发布]
Google I/O 是每年科技圈最重要的发布节点之一,今年格外扎实——一场发布会,三张王牌同时亮相。
Gemini 3.5 Flash:给 Agent 用的速度怪兽
说白了,Gemini 3.5 Flash 是专门为 Agent 场景设计的推理引擎。官方数据:比其他前沿模型快 4 倍,价格不到竞品的一半。它的定位不是拿分数的模型,而是跑任务的引擎——特别适合需要高频调用、低延迟响应的 Agent 工作流。
技术机制方面,Google 强调了在编码和"现实世界经济价值任务"(real-world economically valuable tasks)上的优化,但具体架构细节未披露。
Gemini Omni:"从任意输入生成任意输出"
Omni 是本次发布中最具野心的一个。Google 给它的定位是:"Generate samples in any output modality from any input"——视频、图片、文字、音频,全打通。
核心能力:
- 迭代式视频编辑:用自然语言对话一步步修改视频,保持场景一致性
- 物理感知生成:理解重力、动能、流体动力学
- 多参考融合:把视频、图片、草图、音频混合输入,输出统一内容
- Sketch-to-Video:手绘草图直接变成写实影像
目前通过 Gemini app、Google Flow 和 YouTube Shorts 三个入口接入,所有内容带 SynthID 水印和 C2PA 溯源标记。
Antigravity 2.0:从代码助手升级为 Agent 平台
Antigravity 1.0 定位是 AI 编程工具,2.0 直接变成了"自治 Agent 开发平台"。桌面端作为中央枢纽编排多个 Agent,搭载优化版 Flash 模型,速度达到"比其他前沿模型快 12 倍"。
顺带一提,Google 还发布了 TPU 第 8 代芯片(8t 用于训练,8i 用于推理),单次训练可跨 100 万个 TPU,性能每瓦提升 2 倍。
配套的 Agent 生态:
- Gemini Spark:7×24 小时个人 AI Agent,处理邮件、日历、长期任务
- Search 信息 Agent:后台收集信息并主动触发行动
- Daily Brief:自动汇总收件箱+日历+待办的个性化摘要
💡 洞察:Google 这次不是在发模型,是在铺管道。Gemini 3.5 Flash 的"快 4 倍"不是为了榜单,是为了让 Agent 调用的边际成本降到足够低,从而使高频自主任务变得经济可行。当模型调用成本降到接近零,Agent 的价值就不再取决于"能不能做",而是"做多少次"。
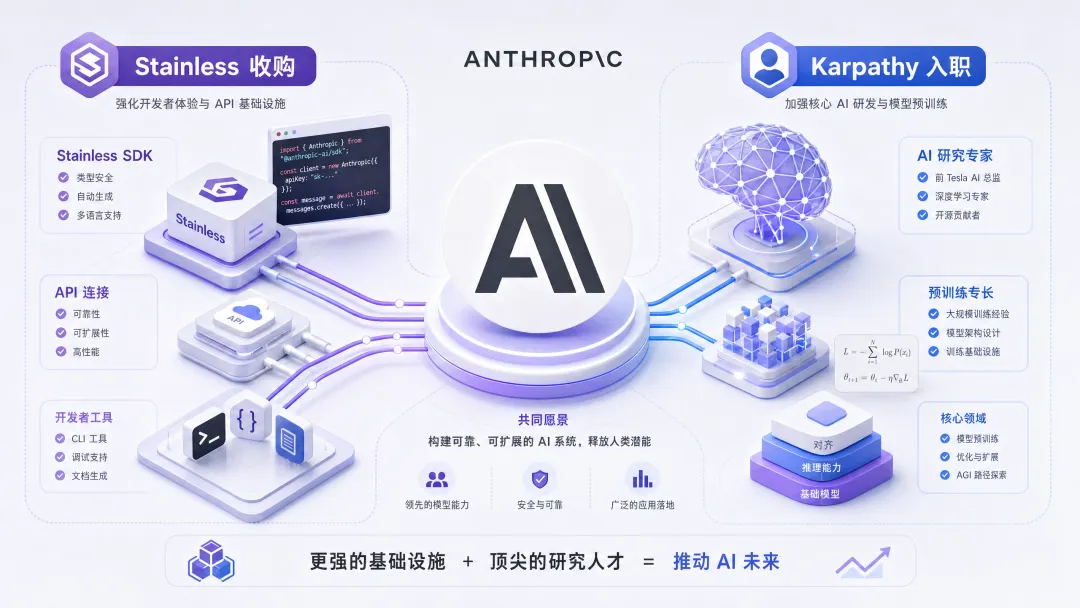
2 Anthropic 双重加注 — 收购 Stainless + Karpathy 入职同一周
📋 [战略动作]
单独一件可以说是"好消息",两件撞在同一周就是信号了。
收购 Stainless:把开发者工具链攥在自己手里
Stainless 是一家成立于 2022 年的开发工具公司,做的事情是:从 API 规范自动生成多语言 SDK(TypeScript、Python、Go、Java 等)和 MCP Server 连接器。它服务过 OpenAI、Google、Cloudflare——包括 Anthropic 自家所有官方 SDK,背后都是 Stainless 在生成。
Anthropic CEO 的表态很直接:"Agents are only as useful as what they can connect to."
收购之后的走向:把 SDK 生成能力和 MCP(Model Context Protocol)工具链整合进 Anthropic 体系,专注于让 Claude Agent 能够更顺畅地连接外部系统。
对现有客户(OpenAI、Google、Cloudflare)的影响?官方公告没说,但 Forbes 的标题直接写了:"Anthropic Buys Stainless To Cut Off OpenAI And Google SDK Access"。
Karpathy 加入 Anthropic 预训练团队
OpenAI 联合创始人、特斯拉前 AI 负责人 Andrej Karpathy 于 5 月 19 日在 X 宣布加入 Anthropic。他将加入预训练(Pre-training)团队,负责人是 Nick Joseph,并牵头一支新团队——专门用 Claude 本身来加速预训练研究。
他的原话很有意思:"I think the next few years at the frontier of LLMs will be especially formative."
Karpathy 没有跳槽到某家初创公司,也没有继续独立。他选了一家对手公司的预训练核心部门——这个选择本身就说明了他认为 Anthropic 的研究路线值得押注。他也补充说,教育方向的工作会在未来某个时间点继续。
💡 洞察:Stainless 收购 + Karpathy 入职,暴露了 Anthropic 的两条并行战略:一条是向下夯实基础设施(SDK 工具链、开发者体验),一条是向上拔高研究天花板(预训练团队引入顶尖人才)。当一家公司同时在两端发力,通常意味着它认为自己正处于关键的加速窗口期。
⭐ 精选动态
1 OpenAI 用 AI 解决了 Erdős 80 年悬案 — 不是噱头,这次是真的
📄 [研究突破]

Paul Erdős 在 1946 年提出了一个离散几何猜想,数学界研究了近 80 年,一直认为最优解的形态"大致像正方形网格"。上周 OpenAI 宣布,一个通用推理模型推翻了这个猜想——发现了一族全新的构造方式,比之前所有已知解都更优。
OpenAI 强调,这不是专门为数学设计的系统,而是一个通用推理模型"顺手"解决的。这是 AI 首次自主解决一个数学领域的核心开放问题。
值得注意的是,OpenAI 7 个月前曾经声称解决过 Erdős 猜想,后来被数学社区打脸。这次他们明显更谨慎,引用了数学家 Thomas Bloom 的评语:"AI 正在帮助我们更充分地探索人类几百年来建造的数学大教堂。"剑桥菲尔兹奖得主 Timothy Gowers 的评价更直接:"达到顶级期刊发表水准"。
技术机制:模型能够"将跨领域的想法长链连接起来",具体推理轨迹 OpenAI 未公开,但官方技术论文已同步发布。整个推理过程成本不到 1000 美元。
💡 洞察:如果这次结果经过数学社区严格验证,它标志的不只是一道题解开了,而是 AI 在"开放式探索"场景下的推理能力第一次触及前沿数学的天花板。数学是人类最严格的思维工具——AI 在这里的突破,比任何 benchmark 都更有说服力。
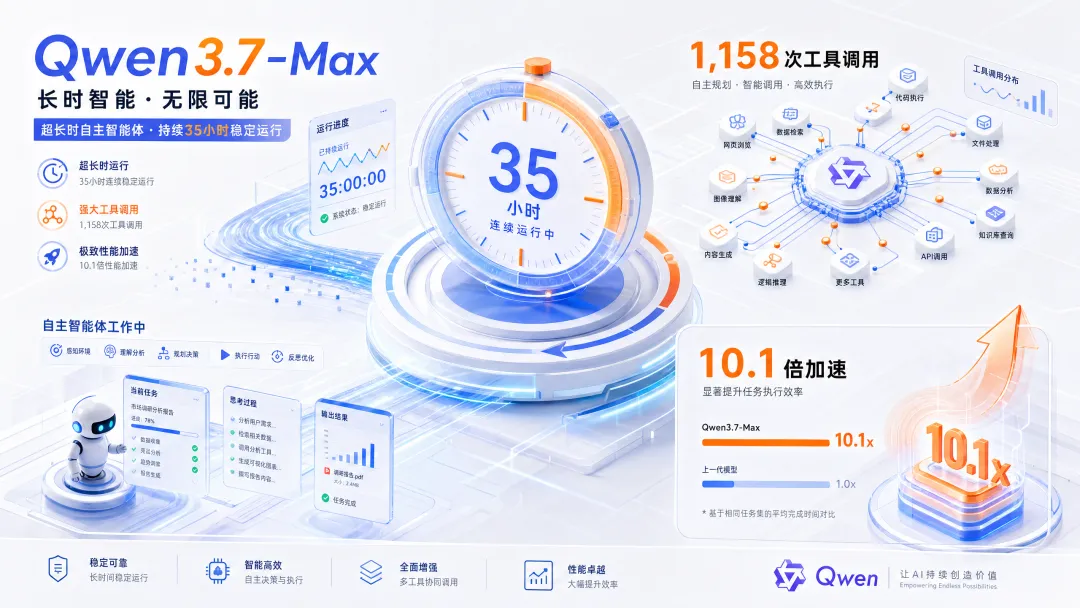
2 Qwen3.7-Max 连跑 35 小时、调用 1158 次工具 — Agent 耐力新基准
💻 [模型发布]
Alibaba 发布 Qwen3.7-Max,主打"长时程 Agent 可靠性"。最吸引眼球的演示:让它优化一块它从未见过的硬件(T-Head ZW-M890 平台的 Extend Attention kernel)——它跑了 35 小时,调用工具 1,158 次,最终实现 10.1 倍几何平均加速,全程自主从段错误和性能回归中恢复。
关键技术:Environment Scaling(环境扩展)
Alibaba 的创新不在于模型架构本身,而在于训练数据构造:把训练分解为三个维度——
- Task(任务目标)
- Harness(执行环境和工具集)
- Verifier(成功标准)
数字上:1,000 种任务 × 50 种执行环境 × 10 种验证器 = 50 万种独特训练实例。结果是模型学会了泛化的问题解决策略,而非记住特定工具的捷径。
Benchmark 数据(有基线对比):
| 69.7 | ||
| 60.6 | ||
不足之处:多模态能力较弱,创意任务表现不及 GPT-5.5。
💡 洞察:Qwen3.7-Max 的意义不是"又一个性能超 Claude 的模型",而是"Environment Scaling"这条训练路线的验证——通过构造多样化的执行环境来提升泛化能力,而不是靠更大的模型或更多的数据。这给整个行业提供了一个可复制的 Agent 训练范式。
3 Cursor Composer 2.5 — 用 RL 训练出来的编程 Agent
💻 [产品发布]
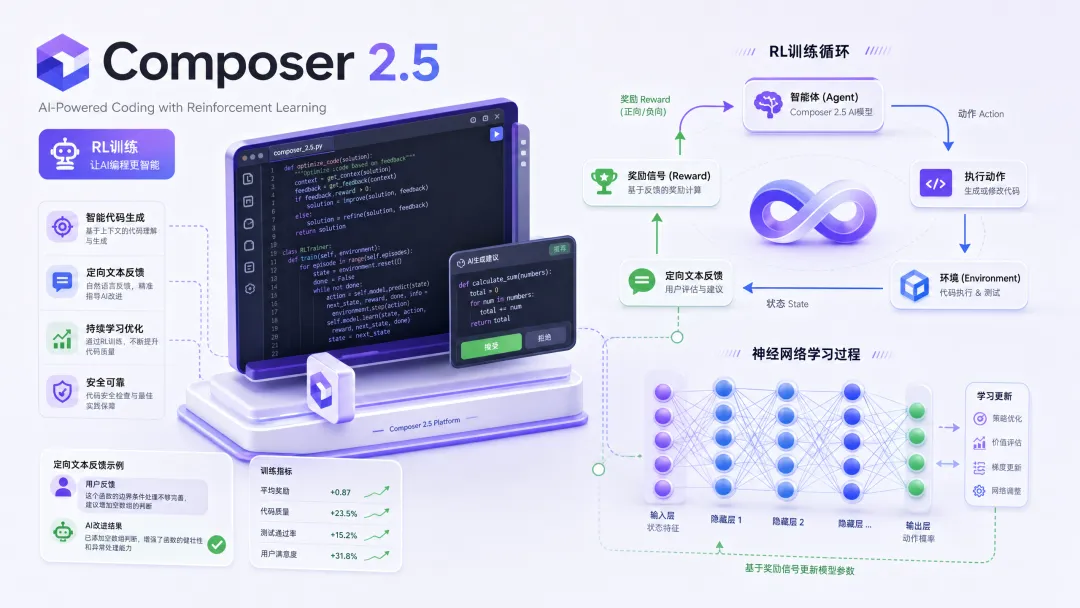
Cursor 发布 Composer 2.5,这次不是调参,是换了训练范式。
三项核心技术创新:
1. 定向文本反馈强化学习(Targeted Text Feedback RL)传统 RL 只给整体奖励信号,Composer 2.5 在训练轨迹的特定位置插入文本提示,让模型针对局部行为(比如某次工具调用出错、沟通风格不对)进行精准学习。说白了,就是把"哪里错了"直接告诉模型,而不是只说"这次整体不好"。
2. 大规模合成数据(25 倍训练任务量)相比 Composer 2,训练任务数量增加了 25 倍。方法是"功能删除"——从真实代码库中删除功能,让模型重新实现,生成更贴近真实场景的挑战性训练数据。
3. 优化的分布式训练架构分片 Muon 优化器 + 双网格 HSDP 并行策略,在 1T 参数模型上每步优化耗时仅 0.2 秒。
定价:标准版 $0.50/M 输入 + $2.50/M 输出,快速版 $3.00/$15.00,首周双倍用量。
💡 洞察:Composer 2.5 的"定向文本反馈 RL"是一个值得关注的训练信号设计——它把人类对代码 Agent 的反馈从"整体评分"细化到"行为级别"。这个方向如果成立,意味着 Agent 的改进不再依赖更大的模型,而是更精准的反馈信号。
4 Cohere Command A+ — 218B 参数,Apache 2.0,企业级开源新标杆
💻 [开源发布]

Cohere 在 5 月 20 日发布 Command A+,218B 参数稀疏 MoE 架构,激活参数 25B,完整 Apache 2.0 开源——这是目前企业级 AI 模型中许可证最宽松的一个。
关键技术参数:
- 架构:稀疏 MoE,218B 总参数 / 25B 激活参数
- 上下文:128K 输入 / 64K 输出
- 语言:48 种
- 最低硬件:2 × H100 或 1 × Blackwell B200
- 量化:BF16 / FP8 / W4A4,官方称"近无损"
Benchmark(有基线对比):
| 85% | ||
Apache 2.0 意味着:可商用、可修改、可分发,只需署名。这对主权 AI 部署(不想数据出境的政府/金融机构)是重大利好。
💡 洞察:Cohere 用 Apache 2.0 打了一张差异化牌——它不跟 OpenAI/Anthropic 比闭源性能,而是把"数据主权"和"部署自由度"作为核心卖点。在欧盟 AI 法案和各国数据本地化要求收紧的背景下,这个时机选得很准。
5 OpenAI Codex 双更新 — Appshots 截图上下文 + /goal 长任务模式 GA
🚀 [产品更新]

OpenAI 给 Codex 同时推了两个功能,一个解决"上下文输入"问题,一个解决"任务持续性"问题。
Appshots:Command+Command 截图入 Codex在 Mac 上按 Command+Command,当前应用窗口的截图和文字内容(包括屏幕外的内容)直接附加到 Codex 对话线程。Codex 同时获得视觉信息和底层文本,不需要手动复制粘贴。
/goal 模式正式 GA/goal 从实验功能毕业,现在可以通过 Codex app、IDE 插件或 CLI 分配里程碑式任务,系统自主执行直到完成——可以跨小时甚至跨天。用户可以随时监控进度、调整方向或暂停。
有人测试:把 /goal 放了 18 小时,它独立完成了 18 个功能中的 14 个。
💡 洞察:
/goal的 GA 是一个里程碑——它把 AI 编程助手从"问答工具"变成了"异步执行者"。当你可以把一个多小时的任务交给 AI 然后去睡觉,开发者的工作模式就从"人机协作"变成了"人机分工"。
6 把 Agent 工作流"编译"进模型权重 — 成本降 100 倍的新范式
📄 [研究论文]
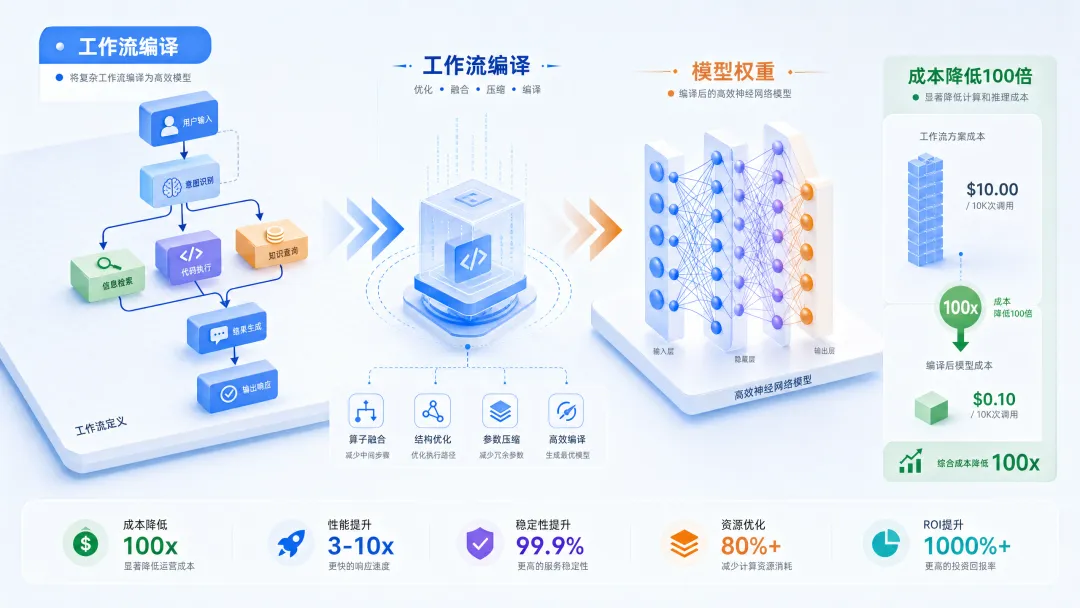
本周 arXiv 上有一篇值得认真读的论文:Compiling Agentic Workflows into LLM Weights。
核心思路:把 Agent 的"编排逻辑"从运行时的 LangGraph/提示词注入,变成训练时直接烧进模型权重——作者称之为"subterranean agents"(地下 Agent)。
技术路线:
- 用 Claude Sonnet 4.5 遍历业务流程图,生成合成训练对话
- 对 3B-8B 小模型做全参数微调
- 运行时:无编排层,模型自己知道下一步做什么
实验数据(有基线对比):
| 1/128 ~ 1/462 | ||
| 4/5 指标更优 |
重新编译一次(流程图变更时):30-50 分钟,相当于一次 CI/CD 部署。
测试场景:旅行预订(14 节点)、Zoom 技术支持(14 节点)、保险理赔(55 节点,6 个决策枢纽)。
💡 洞察:这篇论文挑战了"Agent = 大模型 + 编排框架"的默认假设。如果业务流程相对稳定,把逻辑编译进小模型比每次调用大模型便宜 100 倍以上,且质量损失可接受。这对企业级 Agent 部署是个很实际的工程选项——不是所有场景都需要 GPT-5 级别的通用推理。
📢 快讯速览
- PEEK(MIT CSAIL):为长上下文 LLM Agent 引入"方向缓存"(Orientation Cache),固定大小的上下文地图记录"这段上下文里有什么、怎么组织的",在 TREC-Q 和 CL-bench 上提升 6.3-34%,迭代次数减少 93-145 次,成本降低 1.7-5.8 倍(vs ACE 基线)→ arXiv
- SaaS-Bench:用 23 个真实 SaaS 系统、106 个专业工作流任务测试 9 个顶级 Agent。最强模型 Claude Opus 4.6 完整任务完成率仅 1.9%,暴露了 Agent 在多应用协作场景下的系统性瓶颈 → arXiv
- Qwen3.5-LiveTranslate:阿里通义发布实时翻译模型,支持多语言实时语音翻译 → X
- Manus Schedules:Manus 上线定时任务功能,Agent 可以按计划自动执行任务 → Manus 博客
- Shopify UCP(统一商务协议):Shopify 发布 Agent 接入文档,定义 AI Agent 如何与 Shopify 商店交互 → Shopify Docs
- Chronicles-OCR:清华团队开源古籍 OCR 工具,专门处理中文历史文献 → GitHub
- NVlabs SANA-WM:NVIDIA 发布世界模型版 SANA,支持视频生成 → 项目页
- Runway Edit Studio:Runway 上线视频编辑工作室功能 → Runway
- Nebius × LangChain:Nebius 与 LangChain 合作,在开源模型上构建生产级 AI Agent → Nebius 博客
- OpenAI 个人理财功能:ChatGPT 上线个人财务管理功能 → OpenAI
- Heuristic Learning for Fluid Dynamics:用启发式学习方法解决流体动力学问题的研究 → 博客
结语:Agent 时代的三条分叉路
本周的动态,勾勒出 AI 行业正在走向的三条路:
- 基础设施之争:Google 用 Gemini 3.5 Flash 把 Agent 调用成本打下来,Anthropic 收购 Stainless 把 SDK 工具链攥在手里——谁控制了 Agent 的"水电煤",谁就有定价权
- 研究能力之争:OpenAI 破解 Erdős 猜想、Karpathy 加入 Anthropic 预训练团队——顶尖人才和基础研究能力,正在成为新的护城河
- 工程效率之争:Cursor Composer 2.5 的 RL 训练、"编译 Agent 工作流"论文的 100 倍降本——不是所有问题都需要更大的模型,更聪明的工程方案同样有效
SaaS-Bench 的数据提醒我们:最强模型在真实工作流上的完成率还不到 2%。Agent 时代已经开始,但距离"真正能干活",还有很长的路要走。
