 夜雨聆风
夜雨聆风你们有没有发现一个怪现象——
全行业都在卷上下文长度。200K不够,1M;1M不够,整无限。
大家疯狂往AI嘴里塞东西,仿佛上下文越长,AI就越聪明。
结果呢?
上下文窗口从8K卷到200K,AI回答反而越来越平庸,甚至开始胡言乱语。
这不科学啊。
直到我扒开了Claude Code的源码,才发现了真相——
不是上下文不够长,是你打开的方式不对。
🔥 一个反直觉的发现
先问你一个问题:
你写Prompt的时候,是不是习惯把所有信息一股脑塞进去?
背景文档、示例代码、注意事项、格式要求……能写的全写上,生怕漏了什么。
然后呢?
AI开始:
• 忽略你的关键指令 • 答非所问 • 抓着无关紧要的内容发挥
你以为它在摆烂?不,是你的信息把它淹没了。
Anthropic的工程师们做过一个实验:
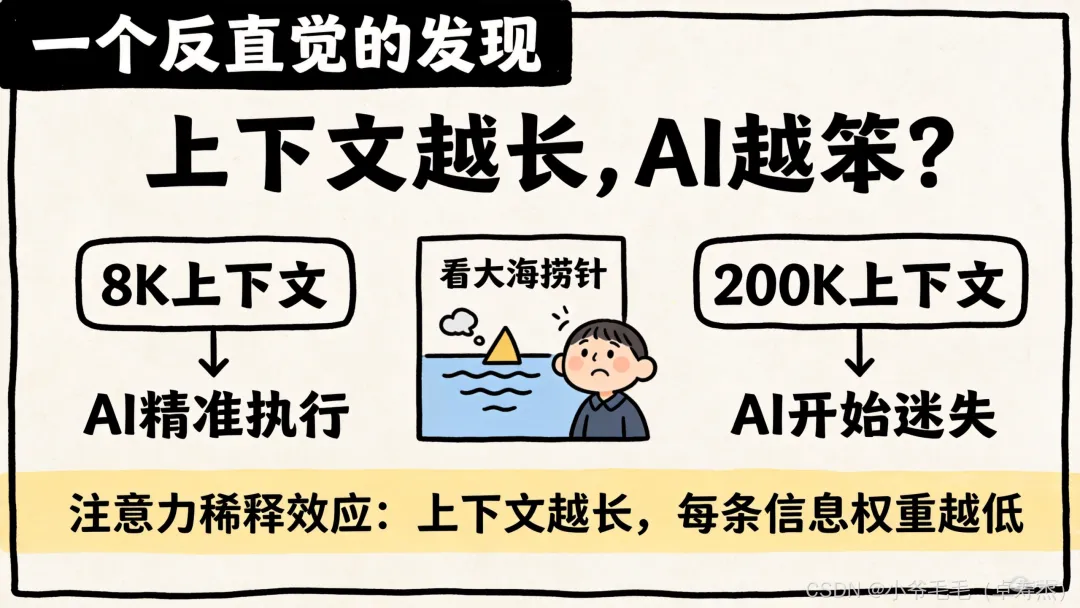
就像你在一群人里喊"抓住那个穿红衣服的",10个人你能抓住;1000个人?算了吧。
💡 那帮"卷王"在卷什么?
既然上下文长度不是解法,那正确的方向在哪?
我扒了Claude Code、OpenClaw、还有国内几个头部Agent框架的源码,发现大佬们都在偷偷"卷"同一件事——
渐进式披露(Progressive Disclosure)。
这个词听起来很玄乎,但原理巨简单:
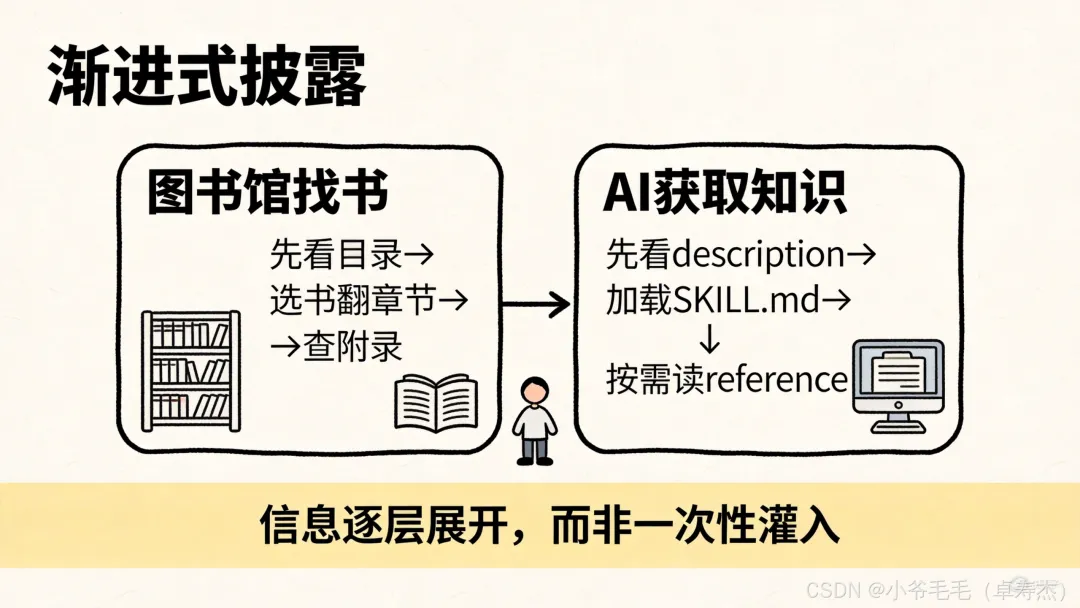
把这个逻辑套到AI上,就是渐进式披露的核心思想。
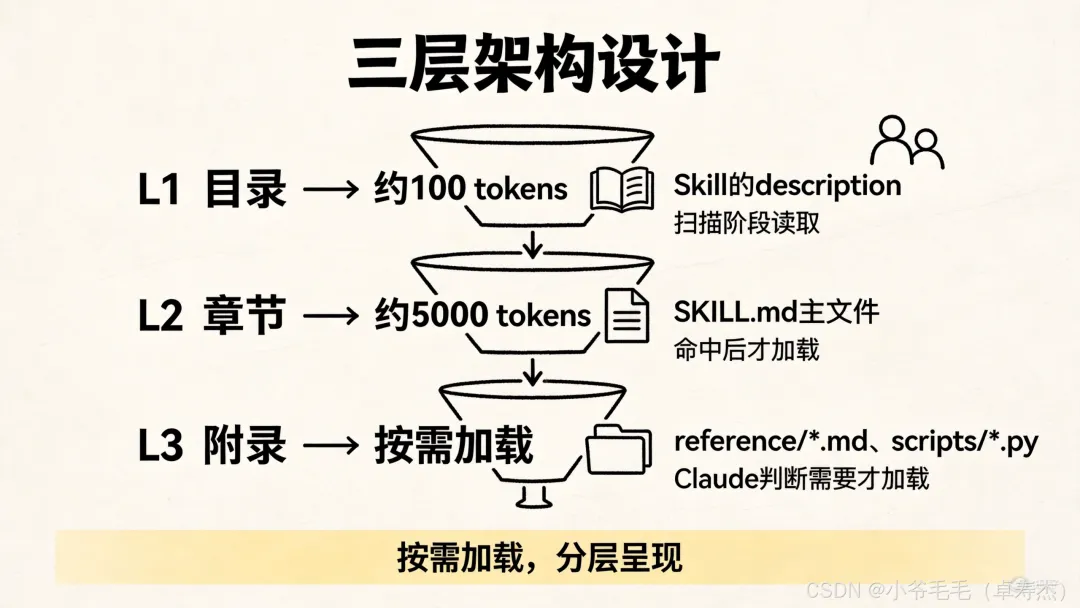
🏗️ 三层架构,手把手教你设计
好,理论讲完了,我们来实战。
我用一个财务分析Skill来演示,完整代码可以直接拿去用。
整体目录结构
1 2 3 4 5 6 7 8 9 10
your-project/.claude/skills/financial-analyzing/
├── SKILL.md # 主文件(总是加载)
├── reference/
│ ├── revenue.md # 收入分析
│ ├── costs.md # 成本分析
│ └── profitability.md # 盈利分析
├── templates/
│ └── analysis_report.md # 报告模板
└── scripts/
└── calculate_ratios.py # 计算脚本
第一层:目录(Description)
这是AI扫描阶段读取的唯一内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
---
name: financial-analyzing
# 描述要丰富,但不能太长
# 所有Skill的description共享15000字符预算
description: |
Analyze financial data, calculate financial ratios, and generate
analysis reports. Use when the user asks about revenue, costs,
profits, margins, ROI, financial metrics, or needs financial
analysis of a company or project.
allowed-tools:
- Read # 允许读取文件
- Grep # 允许搜索
- Glob # 允许文件匹配
- Bash # 允许执行脚本
---
核心原则:用"用户可能说的话"作为路由关键词,而不是技术术语。
1 2
✅ 正确:收入、营收、卖了多少、利润怎么样
❌ 错误:RevenueAnalysis、calculateRevenue
第二层:章节(SKILL.md正文)
这是Skill被激活后才加载的内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
# Financial Analysis Skill
## Quick Reference ← 核心:路由表格
| Analysis Type | When to Use | Reference |
|--------------|-------------|-----------|
| Revenue Analysis | 收入、营收、销售额相关 | `reference/revenue.md` |
| Cost Analysis | 成本、费用、支出相关 | `reference/costs.md` |
| Profitability | 利润、毛利率、净利率相关 | `reference/profitability.md` |
## Analysis Process
### Step 1: Understand the Question
- 用户问的是什么财务问题?
- 有哪些可用数据?
- 需要什么格式的输出?
### Step 2: Gather Data
- 向用户请求必要的财务数据
- 或从提供的文件/来源读取
### Step 3: Calculate Metrics
# 公式只在需要时加载对应文件
- Revenue metrics → see `reference/revenue.md`
- Cost metrics → see `reference/costs.md`
- Profitability metrics → see `reference/profitability.md`
### Step 4: Generate Report
Use the template in `templates/analysis_report.md`
关键技巧:Quick Reference路由表格。
它用约50个token告诉AI五个方向的路由。没有这个表格,AI需要读完整个SKILL.md才能知道"收入问题去找revenue.md"。
第三层:附录(按需加载的资源)
只有当SKILL.md引用了这些文件,AI才会去读。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
# reference/revenue.md ← 按需加载
## Revenue Growth Rate 收入增长率
公式:
Revenue Growth Rate = (本期收入 - 上期收入) / 上期收入 × 100%
解读:
- > 20%: 高增长 🚀
- 10-20%: 稳健增长
- < 10%: 低增长
- < 0%: 下降趋势 ⚠️
## Year-over-Year (YoY) Growth 同比增长率
公式:
YoY Growth = (本年收入 - 上年收入) / 上年收入 × 100%
适用场景:消除季节性波动,横向对比同周期数据
📊 算一笔账:Token省了多少?
假设一个复杂Skill包含以下内容:
| 总计 | 5300 |
不同场景下的Token消耗:
| 98% | |||
| 98% | |||
结论:大多数请求只需要部分资源,渐进式披露能帮你省下90%+的Token。
⚠️ 三个大坑,踩了白干
坑1:Skill数量失控
description有15000字符预算上限。
如果你发现需要20+个Skill,先考虑合并。
一个项目的Skill最好控制在10个以内。
坑2:路由条件写得太技术
1 2
❌ 错误:Router → RevenueAnalysisModule → calculateRevenue()
✅ 正确:收入、营收、卖了多少、利润怎么样
路由条件要用"用户可能说的话"。
坑3:附录文件名太随意
AI是根据文件名判断要不要加载的。
1 2
❌ 错误:ref1.md, data.json, script.py
✅ 正确:revenue.md, industry_benchmarks.json, calculate_ratios.py
文件名要有描述性,Claude能"看懂"文件名。
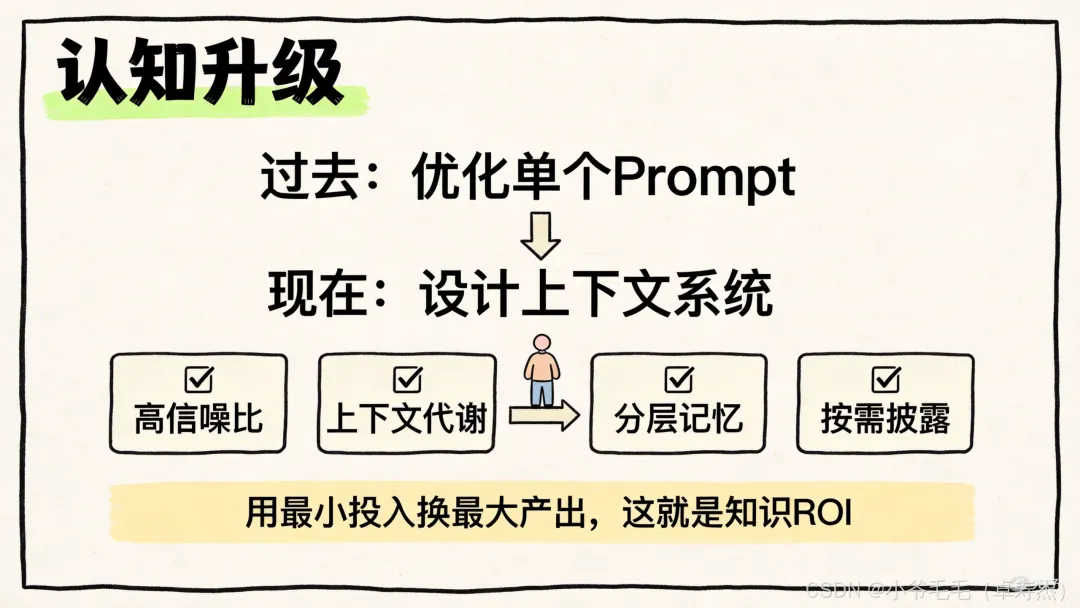
🔮 从"写Prompt"到"设计上下文系统"
说到这里,我想分享一个更深层的认知转变。
过去我们关心的是——"怎么措辞"
现在我们关心的是——"构建什么样的上下文工程架构"
模型能力在增长,但注意力的基本约束不会消失。
就像人类的记忆一样,工作记忆就那么几个槽位,不是塞得越多越好。
Context Engineering之所以重要,是因为它意味着工作重心的转移:
1 2
过去:优化单个Prompt
现在:设计整个信息供给系统
💬 最后说两句
回到开头的问题:还在疯狂调Prompt?
Prompt调到最后,你会发现瓶颈不在于你写得好不好,而在于你给信息的方式对不对。
渐进式披露不只是一种技术,更是一种认知框架——
🗣️ 聊个五毛钱的

是习惯一次性全塞进去,还是已经开始用分层的方式?
评论区来聊聊你的做法~ 👇
