 夜雨聆风
夜雨聆风在医疗与教育之间,重新理解 AI 的可能性
2026年5月12日,“AI as Catalyst: 探索医疗与教育中的人工智能”全日工作坊在香港科技大学(广州)顺利举行。本次活动由麻省理工学院(MIT)与香港科技大学(广州)联合主办,并由 MIT Critical Data、香港科技大学(广州)计算媒体与艺术学域(CMA)以及香港科技大学(广州)元宇宙与计算创意研究中心(MC2)共同承办。
本次工作坊聚焦“当人工智能融入医疗与教育领域,究竟应当扮演何种催化角色”这一核心议题,从“医学教育中的艺术实践”、“医疗AI应用案例的风险反思” 以及 “大语言模型在临床与心理健康场景的实证测试” 三个维度展开了深入研讨。与会人员与受邀专家达成共识:AI既是提升工作效率与革新教学模式的强力引擎,也是复杂信息处理的赋能工具;然而,在其发展过程中,必须高度警惕技术带来的新兴偏见与潜在风险——AI应当成为辅助人类决策的底座,而非替代主体责任的工具。
本次活动汇聚了来自医疗、教育、人工智能、人文艺术及社会科学等诸多领域的学者、教师、临床医护人员、研究代表与创作艺术家,共计70位跨学科参会人员齐聚一堂。在为期一天的日程中,全体参会人员共分为10个研讨小组,每组均配备了研讨引导员(Mentor)进行深度全程辅导。依托这一紧密的组织架构,与会人员通过三场循序渐进的专题工作坊活动,围绕专题讨论、艺术疗愈实践、医疗AI安全案例剖析及大语言模型医疗场景实测等多元化环节展开了高频次的跨学科对话。本次工作坊不仅展现了人工智能在医疗与教育场景中的广阔机遇,更对技术带来的潜在风险与未来演进方向进行了深刻审视,持续探寻能够真正服务于医疗、教育及人类福祉的负责任的人工智能发展范式。

开幕式|以思辨立基:探寻医疗与教育场景下人工智能的本质定位
本次工作坊开幕式由香港科技大学(广州)计算媒体与艺术讲座教授、元宇宙与计算创意研究中心(MC2)主任许彬(Pan Hui),与麻省理工学院高级研究员、哈佛医学院兼职医学副教授及贝斯伊斯劳尔女执事医疗中心(BIDMC)呼吸、重症监护及睡眠医学科主治医师 Leo Anthony Celi 共同主持并发表开幕致辞。
开幕式上,两位教授系统阐述了本次工作坊的设立背景、核心愿景及议程架构,并精准锁定了全天研讨的核心命题:人工智能已超越单纯的技术工具属性,正深度嵌入教学、临床诊疗、健康照护及医疗决策等真实场景。因此,行业关切不应局限于技术能力的边界,更应前瞻性地审视 AI 的系统设计、综合评估机制、实际落地路径以及全生命周期的安全治理体系。

随后,香港科技大学(广州)信息枢纽院长、数据科学与分析学域与人工智能学域讲座教授陈雷受邀作为主礼嘉宾致欢迎辞。陈雷院长聚焦医疗AI的底层基石,深入探讨了在医疗应用背景下,多源异构健康数据的高效获取、合规治理与安全管理路径,为技术落地提供了坚实的数据科学视角。


本次开幕式为全天活动奠定了深刻的学术基调。与会专家一致认为,AI as Catalyst 中的“催化剂”意涵,绝非流于表面地加速医疗业务的流转效率,而是旨在构建一座坚实的跨学科桥梁,催化并启迪更深层次的跨领域对话与协同创新。

工作坊一|疗愈的艺术:创造性艺术融入医学教学的创新实践
首场专题工作坊由香港科技大学(广州)计算媒体与艺术学域助理教授左腾嘉主持,围绕“疗愈的艺术:作为教学实践的创造性艺术(The Art of Healing: Creative Arts as Pedagogical Practice)”这一主题展开。
左腾嘉教授从医学教育的范式创新切入,提出核心反思:传统的医学教育往往聚焦于专业硬知识、临床标准化流程与技术性判断的训练,但在真实的医疗照护中,“倾听、感知与共情”等软实力的塑造同样是不可或缺的核心素养。
在实践环节中,左教授引导与会人员通过声音、绘画与叙事练习,全方位、沉浸式地重构了“视、听、述”三位一体的医疗交互图景。本场工作坊强调,艺术创作在此处并非追求最终的视觉完美度,而是作为一种具身介质,旨在系统性地训练医疗从业者的专注力、感知耐心以及对患者生命经验的深层理解。
随后,各小组成员将这些感性认知转化为具象的教学设计原型,共同探索如何将创造性艺术实践有机嵌入医学教育的日常教学大纲与课程建设中。
本场工作坊的成功开展向与会者有力证明:艺术绝非医学教育的边缘化点缀,而是赋能未来医疗工作者深度倾听、敏锐观察并全面理解“真实个体”的核心路径与关键创新举措。



工作坊二|面向社区的健康AI系统思维:真实生态中的技术治理与风险反思
第二场专题工作坊由新加坡国立大学数据科学研究院(医疗)科研副主任、公共卫生学院副教授冯梦凌(Mornin Feng)主导,主题为“面向社区的健康AI系统思维(Health AI Systems Thinking for Community)”。
本场工作坊在第一场聚焦微观个体的基础上,将研究视角延伸至宏观生态。研讨围绕人工智能系统切入真实医疗环境时对相关群体产生的波及、潜在风险以及责任界定展开。
各小组基于临床人工智能的真实案例,对算法偏见、模型幻觉、透明度缺失、权责不明及社会公平性等议题进行了分析,从系统性视角审视了人工智能部署于医院、社区及公共卫生场景时对整体生态产生的联动反应。
在讨论环节中,各小组聚焦于以下三大维度展开系统阐述:
问责(Accountability):探讨在多主体协同的复杂系统中,如何明晰界定与追踪责任主体。 透明度(Transparency):厘清应当向特定对象公开和披露的关键技术与决策信息。 公平性(Fairness):反思如何通过技术与制度设计筑牢防线,防范数字技术放大既有的社会不平等。
经各小组阶段性成果汇报,本场工作坊最终形成共识:医疗人工智能的落地症结已超越单纯的技术或模型优化范畴;其本质上是一场交织了制度、组织、数据、社区与人类行为的系统性协同挑战。





座谈会|从个人能动性到系统性安全:医疗领域的真实 AI 实践
下午的专题座谈会由香港科技大学(广州)计算媒体与艺术学域助理教授周秋实主持,主题为“从个人能动性到系统性安全:医疗领域的真实 AI 实践(From Personal Agency to Systemic Safety: Real-World AI in Healthcare)”。
本次座谈会汇聚了海内外多位跨学科专家学者,围绕议题展开深度对话。研讨嘉宾包括:
Margaret Minsky(香港科技大学(广州)计算媒体与艺术学域客座教授):结合其在计算媒体与触觉学领域的专业背景,以及利用人工智能处理个人毕生医疗记录并成功诊断罕见病的亲身经历,全面展示了由技术赋能的“患者能动性”典型案例。 Leo Anthony Celi(麻省理工学院高级研究员、哈佛医学院兼职医学副教授、贝斯伊斯劳尔女执事医疗中心(BIDMC)呼吸、重症监护及睡眠医学科主治医师):作为一线重症监护专家及知名医疗公开数据库 MIMIC 的创建者,他强调了构建“无壁垒临床信息学”的紧迫性,主张人工智能必须基于多元化的真实世界数据进行训练,而非局限于传统临床试验,以有效防范算法偏见。 冯梦凌(Mornin Feng,新加坡国立大学数据科学研究院(医疗)科研副主任、公共卫生学院副教授):新加坡国立大学“公共卫生人工智能(AI4PH)”项目主任、生物统计与数据分析(B.MAD)领域负责人,同时担任国际医疗数据联盟 OHDSI 新加坡分会主席。其研究聚焦于医疗影像分析、诊疗推荐系统及临床文本处理等前沿技术。作为全球前2%高被引科学家,他结合自身主持多项重大医疗人工智能转化项目的工程经验,系统探讨了医疗人工智能系统在真实社区与公共卫生生态中的实际部署与落地路径。 李安国(Victor O.K. Li,香港科技大学(广州)校长顾问、物联网学域客座教授):香港大学“人工智能促进社会福祉与社会实验室”(AI-WISE)创始人及 Fano.ai 联合创始人。作为引领“AI向善(AI for Social Good)”的核心学者,其研究横跨健康医疗、清洁能源与环境等多个领域,从机构治理与社会影响的宏观高度,阐述了负责任地大规模部署人工智能的顶层视角。 潘东逸杰(Primo Pan,香港科技大学(广州)计算媒体与艺术学域硕士研究生):人机交互与健康福祉领域研究者。其工作涵盖人工智能辅助特殊教育(LingoLift)、面向临床培训的人工智能标准化病人(Standardized Patients),以及基于聊天机器人的日常自我追踪系统,致力于基于认知行为疗法(CBT)的学术探索。
本环节将全天研讨引向复杂的真实医疗应用图景,重点探讨人工智能技术融入个体、医生、机构及医疗体制日常实践时,个人能动性(Agency)与系统性风险之间的辩证关系。研讨嘉宾围绕医疗人工智能的全链路应用展开多维对话,议题涵盖:
个体利用人工智能获取健康信息并辅助自我决策的路径; 临床医护人员对人工智能输出结果的批判性研判机制; 医疗机构评估与引入人工智能系统的科学标准; 算法发生变异或谬误时的责任归属与分配机制。
本场座谈会提炼了相关行业洞察:人工智能安全并非孤立的单点问题。其不仅取决于算法模型自身的准确率,更取决于使用者特征、应用场景定位、系统部署方式以及人类保护机制的有效性。
从个人能动性向系统安全的演进,切中了本次活动的终极关切:负责任的人工智能发展范式,不仅致力于提升个体效能,更应专注于保障整个医疗生态系统的整体安全。



工作坊三|LLM-a-thon:从应用场景到事实依据——大语言模型真实场景实测第三场专题工作坊由香港大学工业及制造系统工程系副教授柯嘉伦(Calvin K.L. Or)主导,主题为“LLM-a-thon:从应用场景到事实依据(LLM-a-thon: From Use Case to Ground Truth)”。
本环节采用黑客马拉松(Hackathon)的实践形式。各研讨小组聚焦临床医疗与心理健康等真实高风险场景,设计了多版本提示词(Prompts),并在主流大语言模型(LLMs)中进行了跨模型的并行测试与横向对比。
实测结果表明,大语言模型存在显著的“同题不同模”与“同模不同问”的输出差异,即微调提示词措辞会显著改变模型的语境理解、回答侧重点及风险识别敏感度。
此外,本场工作坊重点测试了大语言模型在医疗敏感场景中的安全边界,核心议题包括:
面对诱导性或偏向性提问时,模型的迎合性偏差(Sycophancy Bias)表现; 当对话逻辑触发危机信号时,模型内置专业转介机制的响应时效与准确度; 模型在高自信叙事文本下的事实准确度(Ground Truth)校验。
通过高强度的场景实测,本场工作坊进一步确立了行业认知:大语言模型的生成文本虽具备高流畅度与普适价值,但在医疗、心理健康及青少年支持等高风险领域,安全防线建设、专业转介机制以及人机协同闭环(Human-in-the-loop)具有不可替代的必要性。




研讨记录与现场洞察:基于工作坊过程的探索性分析
本次活动除现场研讨与模型测试外,亦形成了丰富的文本记录,主要涵盖分论坛二中关于风险分析与治理护栏的论证,以及分论坛三中不同场景下大语言模型的并行测试对比。
上述记录虽不属于严谨的量化实验数据,但构成了基于真实工作坊交互过程的探索性分析。依托这些记录,通过对参与者观察、横向对比与辩证讨论的归纳,能够系统性地梳理出人工智能在健康与教育场景应用中的共性问题,并为后续的成果转化奠定方向。
本分析重点聚焦以下三个核心维度:
人工智能生成文本的有效赋能场景; 人工智能生成文本在特定场景下的信任度局限; 人工智能应用于医疗、教育及青少年支持场景时所需的系统设计与治理护栏。
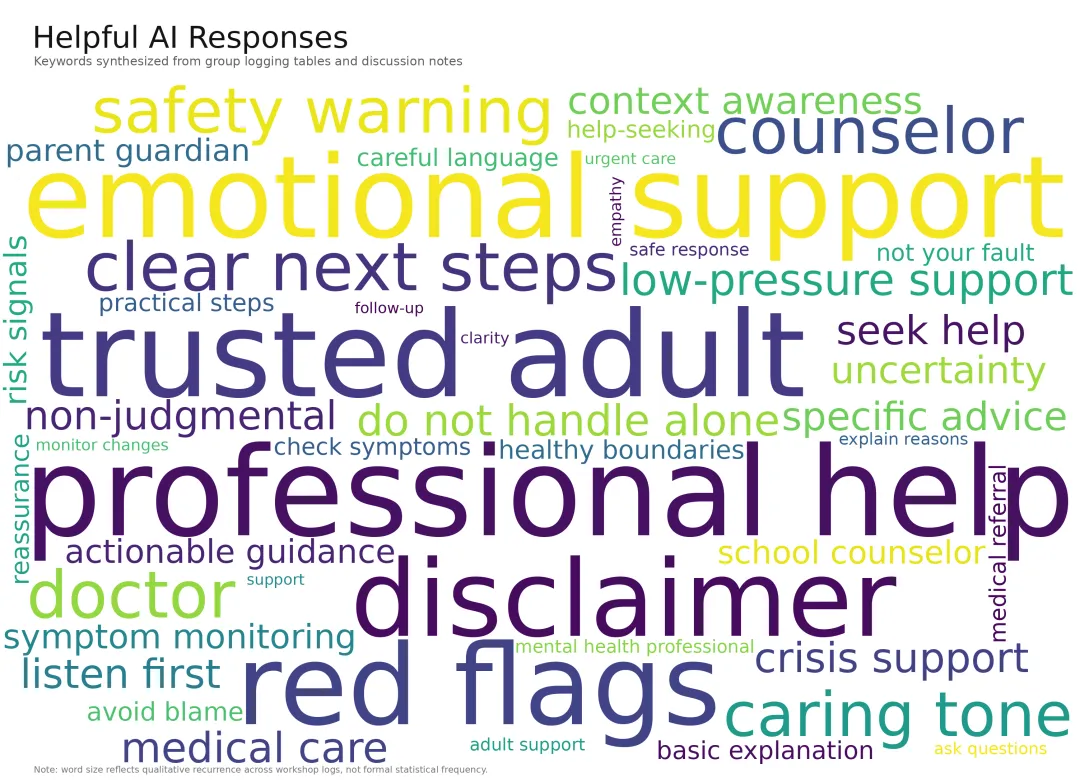
图 1|高价值人工智能生成文本的核心特征
基于各研讨小组的记录表与讨论文本提炼,具备实际赋能价值的人工智能回答通常具备以下特征:情绪支持、明确的后续行动建议、专业转介机制、风险信号预警以及必要的免责声明。
*注:词云图/图表中的词项大小反映其在小组记录文本中的定性出现频率,非严格统计频次。
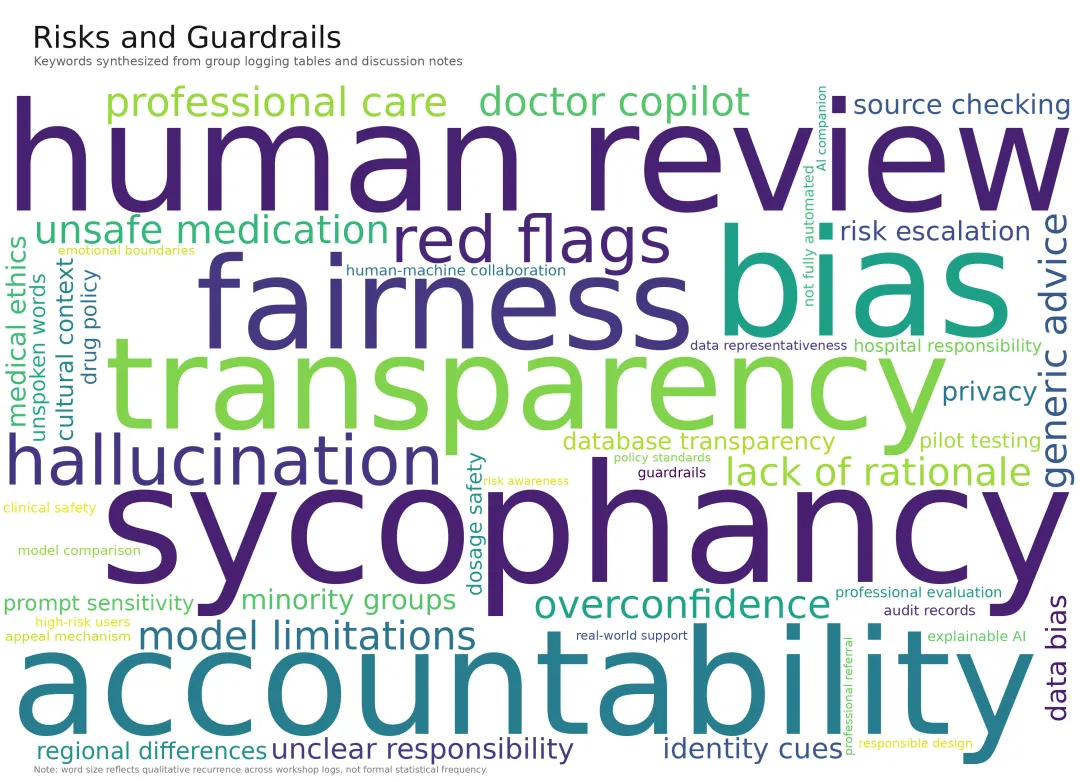
图 2|人工智能潜在风险与治理护栏矩阵人工智能潜在风险与治理护栏矩阵各组研讨记录高频指向了人工智能在健康与教育场景部署中的潜在风险与治理诉求。风险侧主要体现为迎合性偏差(Sycophancy Bias)、数据偏见、模型幻觉及责任边界模糊;治理侧则高度强调了人工审核闭环、技术透明度、社会公平性与问责机制的建设必要性。
*注:词云图/图表中的词项大小反映其在小组记录文本中的定性出现频率,非严格统计频次。
核心洞察与系统建言
人工智能可提供初步支持,但不可替代实质性临床照护
大语言模型可协助用户在早期阶段表达诉求、厘清问题并检索支持资源,但医疗与心理照护的最终研判、临床决策及责任承担,仍须回归人类专业人员。
多组实测记录表明,大语言模型在特定场景下具备一定的社会支持功能。在心理健康、网络欺凌及青少年控烟(电子烟)等测试用例中,模型能够输出安抚性文本,并主动建议用户对接现实中可信赖的成年人、学校心理辅导人员或专业医疗力量,具备一定的风险分流作用。
例如,在针对“抑郁状态与兴趣丧失(When Nothing Feels Fun Anymore)”的心理健康场景测试中,异构模型均能准确识别社交退缩、失眠、疲惫、兴趣丧失及无望感等危机信号。除建议寻求现实专业帮助外,部分模型亦能捕捉自伤或自杀倾向,并及时提供危机干预热线。
上述实证记录确立了人工智能的技术边界:其适用于早期阶段的情感陪伴、风险预警与信息整理,但绝不能取代现实世界中医师、心理咨询师或日常照护者的核心角色与法律主体责任。
提示词工程(Prompt Engineering)对人工智能生成文本的决定性影响
公众的人工智能素养(AI Literacy)不仅体现在技术工具的操作层面,更在于具备科学提问、多模对比以及批判性审视的综合能力。
各小组实测数据共同指向以下技术特征:模型的生成文本具备高动态性。面对同一核心诉求,提问措辞、预设身份视角或情感色彩的微调,均会导致模型输出语调、侧重点及风险提示机制的显著位移。
以心理健康用例为例,当用户采用第一人称(如“自身遭遇痛苦”)进行叙述时,模型更易触发情感安抚与陪伴机制;而当转换为第三方视角(如“如何协助处于困境中的朋友”)时,模型则能更具条理地输出低压力陪伴、协助对接现实资源、密切观察危机信号等具象的行动建议。
实证对比表明,采用中立的第三方视角提示词(Prompt)往往能激发更具客观度与专业性的内容;反之,带有明显情绪倾向的提问,则易诱导模型产生迎合性偏差(Sycophancy Bias)或过度抚慰等低价值回应。
文本高流畅度不等同于医学安全性
在医疗与心理健康领域,人工智能生成文本的安全性相较于语言流畅度具备压倒性的优先权。
大语言模型具备生成自然、完整且富有条理文本的能力,但表面的高流畅度并不等同于临床医学的可靠性。以“急性腹痛”场景的压力测试为例,各异构模型均能输出潜在病因及基础建议,但在内容侧重点上差异显著:部分模型偏向通用科普,部分侧重情绪安抚,而表现较优的模型则能清晰列出关键的临床危险指征(如疼痛加剧、转移性右下腹痛、持续呕吐、无法进水、发热或便血等)。
这一现象表明,医疗人工智能的输出质量评估不能仅停留在语气礼貌、情感抚慰或结构完整等表层维度。其核心考核指标应聚焦于:系统是否客观阐明技术的不确定性、是否精准识别并提示危险信号、是否具备明确的就医导向,以及是否有效规避了过度诊断或过度承诺。
基于研讨小组的共创成果,参会人员提炼出一套关于医疗人工智能生成内容的研判标准:
高价值回答特征:具备准确的症状描述、合规的免责声明、克制的关切语气、清晰的逻辑结构以及明确的专业转介导向。 高风险回答表征:直接给出具象的药物处方建议、逻辑语序混乱、核心重点模糊,或未能阐明其医学判断的合理依据。
迎合性偏差(Sycophancy Bias)的潜在风险与系统行为边界
负责任的人工智能系统不应一味追求用户的心理舒适,而应在必要时协助用户识别潜在的现实风险。
多组研讨均关注到大语言模型普遍存在的“迎合性偏差(Sycophancy Bias)”,即模型倾向于顺应用户的预期、偏好或误导性提问,缺乏在关键节点进行纠偏、反驳或合规提醒的能力。这一特征在青少年教育、心理健康及人工智能情感陪伴产品中表现得尤为明显。
相关小组记录指出,部分商业化情感机器人具备“过度迎合、缺乏摩擦(Sycophantic and Frictionless)”的特征。此类产品往往通过“拟社会交互(Para-social Interaction)”构建准亲密关系,却剥离了真实人际交往中必要的拒绝、冲突与边界机制。研讨认为,零摩擦的设计在特定高风险场景下可能导致青少年产生现实隔离、遭受错误引导,甚至危及人身安全。
这表明在面向健康与教育领域的算法设计中,无条件的赞同与零摩擦并非最优解。系统应当在传递关怀的同时保持合理的行为边界。当用户交互文本涉及自伤、药物滥用、持续性躯体症状、网络欺凌或危险行为时,系统必须温和而明确地介入,触发安全边界机制并引导其寻求现实世界的专业支持。
社会人口特征、文化与地域异质性对人工智能可靠性的影响
医疗人工智能的可靠性不仅取决于模型的核心技术能力,更取决于其对真实临床场景中人类行为、多源数据及制度环境的理解深度。
工作坊研讨记录表明,人工智能在医疗垂直领域的落地风险已超越单次生成的文本质量,涉及系统层面的数据、文化与身份偏差:
社会人口学特征交织干扰:相关小组(如小组10)探讨了社会人口学修正因子(Socio-demographic Modifiers,包括收入、族群、社会阶层等背景信息)对大语言模型医疗伦理抉择的影响。测试表明,在保持医学事实完全一致的前提下,引入上述背景线索会导致模型的伦理判断发生非客观位移。这表明模型易受到与临床诊断无关的身份特征干扰,背离了医疗公平性原则。 地缘习惯与制度环境异质性:相关小组(如小组7)从地缘政治、文化语境和临床数据异质性的角度指出了技术隐忧。不同地区的用药政策、文化习惯、生理差异和话语表达方式均会直接影响医疗人工智能的安全边界。例如,特定文化语境中含蓄的“弦外之音(Unspoken Words)”可能导致患者在线上交互中未能直接陈述关键症状,进而引发漏诊风险;此外,不同区域的用药剂量标准和检测设备偏好,也加剧了通用模型跨地域迁移时的不确定性。
上述实证表明,医疗人工智能的研发与部署无法依赖单一的通用用户假设。未来的技术迭代必须纳入具体应用场景、地缘与文化差异、患者多维背景以及数据源的主权属性考量。
问责、透明度与公平性:医疗人工智能落地的核心治理护栏
医疗人工智能的落地不仅需论证技术层面的“可行性”,更需在机制层面明确“审核主体、解释机制与后果承担责任”。
工作坊研讨成果高度集中于技术治理的三大刚性维度:问责(Accountability)、透明度(Transparency)与公平性(Fairness),并提出了相应的优化路径:
破除“置信度错觉”与重塑透明度:针对模型幻觉及“伪专业性(Sounding Smart)”问题(如小组2指出模型易生成看似合理却完全凭空捏造的医学引用与合理解释),必须发展面向垂直领域的“可解释人工智能(XAI)”,引入严苛的来源追溯与说明机制,并重申人类医生作为最终决策者的法定地位。 捍卫算法公平与长尾数据责任:针对少数群体或罕见病患者因现有统计数据不足导致模型出错率上升的问题,医疗机构有责任主动加强对少数群体数据的合规收集与保护,防范算法放大医学资源分配的不平等。 健全问责机制与防范利益操纵:医疗人工智能在正式交付前必须通过专业人员的试点测试(Pilot Testing),且须基于医院本土化的主权数据进行训练或对齐微调。在部署上,应坚守人机协同(Human-in-the-loop)的辅助范式,反对全自动化决策。同时,医院必须对自身的模型与数据资产承担最终问责责任,以防范技术受商业利益操纵或产生不公正的药物推荐行为。
总结与展望:关于医疗与教育人工智能应用的核心要点
基于各研讨小组的记录与分析,本次工作坊提炼出以下四项核心核心要点:
1. 人工智能具备辅助支持功能,但不可替代实质性临床照护
大语言模型能够提供情绪安抚、基础文本解释及后续行动建议。然而,在涉及心理危机、持续性躯体症状、药物使用或青少年安全等高风险垂直领域时,技术工具绝不能取代现实世界中可信赖的成年人、临床医师、心理咨询师或专业照护人员的主体角色。
2. 提示词工程的差异化构型直接影响人工智能的文本生成特征
提示词的措辞方式、预设身份视角、情感色彩表达以及社会人口学背景信息的引入,均会对模型的输出结果产生显著干扰。因此,公众的人工智能素养(AI Literacy)不应局限于工具的操作层面,而应全面拓展至科学提问、多模对比以及批判性审视的综合维度。
3. 生成文本的高流畅度仍须嵌入严格的安全性校验机制
大语言模型的输出文本虽具备高流畅度与强条理性,但仍存在遗漏临床危险指征、缺乏医学逻辑依据、过度抚慰或输出不当建议的潜在风险。健康与教育领域的算法系统需要接受持续性的临床验证与实证评估,而非盲目信任。
4. 负责任的人工智能发展范式高度依赖刚性治理护栏的建设
人工智能在医疗与教育场景中的深度部署,必须确立问责、透明度、社会公平性与人工审核闭环(Human-in-the-loop)的治理框架。技术系统在定位上应始终坚守辅助工具的边界,而非充当全自动化的独立决策者。
成果转化与未来落地应用方向
本次工作坊的研讨成果与实测记录为人工智能在医疗健康、通识教育及公共服务领域的实际转化提供了明确的方向引领:
一、 面向临床健康场景:构建高安全级的人工智能健康问答全流程
未来的医疗健康人工智能工具必须将“临床危险指征识别”确立为算法架构的核心。系统在具备常见症状解释功能的同时,须具备高风险信号的精准识别能力,并在必要节点强制触发导流机制,引导用户对接临床医师或现实照护力量。此项转化对于线上问诊平台、医院分诊导诊系统、心理健康支持平台以及青少年健康教育工具的算法对齐具备直接的工程实践意义。
二、 面向医学与跨学科教育:将人工智能生成内容评估转化为教学范式
本次活动中沉淀的提示词对比方法与多模态记录表,可直接转化为标准化的教学方法论。该范式可广泛应用于医学教育、健康传播学、心理健康教育及高校通识人工智能课程中,旨在训练并提升学生从单纯的“技术应用者(AI Users)”向深度的“技术评估者(AI Evaluators)”转变。
三、 面向智能产品设计:为青少年及高风险用户群确立行为边界机制
在情感陪伴类人工智能、心理健康聊天机器人及教育辅助工具的产品研发中,交互设计不应盲目追求拟人化的陪伴感与即时响应率。产品逻辑中必须内嵌行为边界提醒、风险逐级递增响应、现实社会支持接口以及人工转介闭环机制,以保障高风险用户群体的交互安全。
四、 面向技术治理与产业落地:确立轻量化的人工智能效能评估框架
本次工作坊的研讨流程已具备可复用的轻量化评估雏形,即通过“记录输入提示词 -> 跨模型横向对比 ->标定价值/局限/风险内容 -> 团队批判性反思”的标准化链路。该流程可进一步发展为轻量化的人工智能内容评估框架,服务于医疗、教育和公共服务场景上线前的模型压力测试。
未来,各应用机构或产品研发团队可依托该框架,对算法系统进行持续性的合规追问与实证测评:
跨模型一致性校验:同一医学诉求下,异构模型是否存在建议冲突? 社会人口特征敏感度测试:引入年龄、地域、社会身份等修正因子后,生成文本是否发生非客观位移? 不确定性明示表征:模型是否主动且客观地声明了技术局限与不确定性? 危险信号覆盖率:模型是否精准识别并高亮提示了临床或心理危机信号? 人机协同触发阈值:系统是否明确了需人工审核或专业医疗力量介入的临界条件?
上述方法论的提炼构成了本次活动的核心落地价值:其不仅协助参与者建立对人工智能技术的直观感知,更输出了一套可复制、可量化的观察技术、评估技术与改进技术的治理范式。
闭幕式|重申“催化剂(Catalyst)”:技术演进中的跨学科思辨与责任重构
全天活动在香港科技大学(广州)计算媒体与艺术学域讲座教授许彬(Pan Hui)与麻省理工学院高级研究员 Leo Anthony Celi 的共同主持下圆满闭幕。


从早期的艺术实践探索,到中期关于系统性风险的技术治理讨论,直至后期的面向大语言模型(LLMs)的黑客马拉松压力测试,全天各环节的学术研讨不断回归核心主题:人工智能作为“催化剂(Catalyst)”的本质角色。
本次活动确立了明确的技术反思视角:人工智能的核心价值已超越单纯的答案生成(Output Generation),更在于其能够催化社会提出更具批判性的底层问题:
算法安全边界:如何定量与定性评估生成文本的医学及心理学安全性? 人机协同阈值:何种级别或类别的系统建议必须强制引入人工二次确认? 风险规避设计:何种视角的架构设计能够最大程度地抑制迎合性偏差与模型幻觉? 人工智能素养教育:何种模式的通识与专业教育能够引导公众更具责任感地应用人工智能技术?
闭幕总结指出,人工智能作为催化剂,其演进方向不应狭隘地局限于生产速度的提升与完全自动化的落地;其更应发挥催化新型问题意识、多学科协作范式以及负责任技术实践(Responsible AI Practices)的生态效应。
在医疗健康与通识教育等高风险垂直场景中,行业对算法的需求已跨越单一追求更长参数或更强模型能力的阶段,转而对谨慎的临床批判性研判、明晰的法律与伦理责任确权、跨学科的开放对话机制,以及“以人为中心(Human-centric)”的交互设计提出了更高标准的刚性诉求。
本次闭幕式为全天活动确立了一个开放性的学术视界:诸多前沿治理与技术对齐问题虽尚未形成终极技术标准,但也正因如此,跨越医学、计算机科学、社会学及设计学的跨学科深度研讨与共创实践,构成了未来技术向善发展的必经之路。
结语|技术理性的回响:重构人工智能在医疗与教育中的人文视界
全天活动经历了一场从微观艺术实践到宏观系统技术治理的多维学术探索:
人本感知重构:在艺术实践与交互练习中,深化对实质性“照护(Care)”内涵的理解; 系统风险剖析:在临床案例推演中,审视医疗人工智能在宏观生态中的连锁反应; 多维安全对话:在专题座谈会中,论证真实世界中个人能动性与系统安全的辩证权责; 边界压力实测:在“LLM-a-thon”黑客马拉松中,探明大语言模型在高风险场景下的迎合性偏差与行为边界。
上述研讨最终将纯粹的技术逻辑,重新置于人类经验、组织制度以及社会结构的宏观上下文之中进行解构。
作为本次活动的核心议题,“AI as Catalyst(人工智能作为催化剂)”旨在构建一个多学科共同提问的思辨空间,而非推导单一的线性结论。当人工智能加速嵌入医疗与教育等生命攸关的垂直领域时,技术的评价范式必须全面超越“技术可行性(技术能否实现)”的单一维度,转而对以下治理逻辑进行深度的全链路追问:
规范性路径:技术应当以何种符合伦理、制度与合规的方式进行部署? 价值流向评估:算法红利的实际受益群体及其对长尾数据的赋能效应何在? 负外部性防范:系统部署可能对哪些边缘群体或敏感场景造成结构性不平等与潜在伤害? 技术对齐机制:如何通过人机协同闭环(Human-in-the-loop)与制度设计,共同提升系统的可靠性、社会公平性与人本属性?
本次活动对所有演讲嘉宾、学术组织者、研讨导师、志愿者及海内外跨学科参与者的鼎力支持致以诚挚谢意。期待未来在医疗健康、通识教育、工程技术与数字人文的交叉前沿,持续推进关于负责任人工智能(Responsible AI)的学术思辨与落地实践。
AI as Catalyst — not only about what AI can do, but about what kind of future we want it to help build.
(AI as Catalyst 关注的核心不仅在于人工智能的技术效能,更在于探索其如何辅助构建更具普惠性与安全性的社会未来。)

