 夜雨聆风
夜雨聆风你可能也碰到过这种场景:问 AI 一个问题,它回答得很顺。语气稳,段落整齐,还会顺手举例。看起来像刚刚查完资料。
但过几分钟,你把里面的日期、政策名、人名一查,发现有一处不对。更麻烦的是,它刚才一点也不像在犹豫。
这正是很多人第一次用 AI 时最容易踩到的误会:把它当成一个更会聊天的搜索框。
先说结论:
• 搜索引擎更像“帮你找资料的人”,大模型更像“根据上下文现场组织语言的人”。
• LLM 生成回答时,会根据提示词、前后文和训练中学到的语言模式,连续预测并组织下一个小片段。
• 它擅长写、改、总结,是因为它很会识别语言结构;它会出错,是因为“说得像真的”不等于“事实已经核实”。
• 重要信息,尤其是价格、政策、医疗、法律、财务、日期,最好让 AI 给出处,再回到可靠来源核对。

AI 更像“现场组织答案”的搭子,而不是单纯的搜索框。
1. 你以为它在查,其实它在接着写
先把搜索引擎想成图书馆门口的检索员。你问:“今年杭州有哪些适合亲子玩的地方?”它把网页、攻略、地图、帖子摆出来。接下来,你自己点进去看、比较、判断。
大语言模型不太一样。它更像一个很会接话、很会整理材料的写作搭子。你给它一句话、一个文件、一段聊天记录,它会顺着这些上下文,组织出一段像人写出来的回答。
按 OpenAI Academy 的解释,ChatGPT 背后是大语言模型,也就是在大量数据上训练出来、用来预测和生成类似人类回复的 AI 系统。OpenAI 同时提醒,LLM 并不是像人一样“知道”事情,所以提示词怎么写,会很影响它的回答。
这句话很关键。它不是先打开一个万能数据库,找到唯一标准答案,再照抄给你。很多时候,它是在判断:在当前上下文里,接下来最像一个有用回答的表达是什么。
图 1:搜索引擎偏向“找资料”,大模型偏向“组织回答”。两者可以配合,但不是一回事。
一句话理解:搜索框把你带到资料面前;大模型把资料和语境揉在一起,先给你做一版可读的表达。
2. “预测下一个词”,不是瞎猜
一听“预测”,很多人会以为 AI 只是在玩文字接龙。比如看到“下雨天适合”,就随便接一个“喝奶茶”。
真实情况要细得多。Google 的机器学习课程把语言模型解释为:估计某个 token 或一串 token 出现在更长文本序列里的概率。token 可以理解成语言里的小零件,可能是一个词,也可能是词的一部分。
模型生成回答时,会看你刚刚问了什么,也会看前面的对话、你上传的材料、你规定的口吻和格式。上下文越清楚,它越容易判断“接下来该怎么说”。
可以把它想成厨房。你递进去的不是一道菜名,而是一篮子食材:问题、背景、限制、语气、文件。模型每次往锅里加一点点内容,上一勺会影响下一勺。最后端出来的,就是一段完整回答。
所以,AI 不是一次性从某个抽屉里拿出答案。它更像是不断做小判断:这一句后面接什么更合理?这个例子要不要展开?这里该用“解释给小白听”,还是“写成领导汇报”?
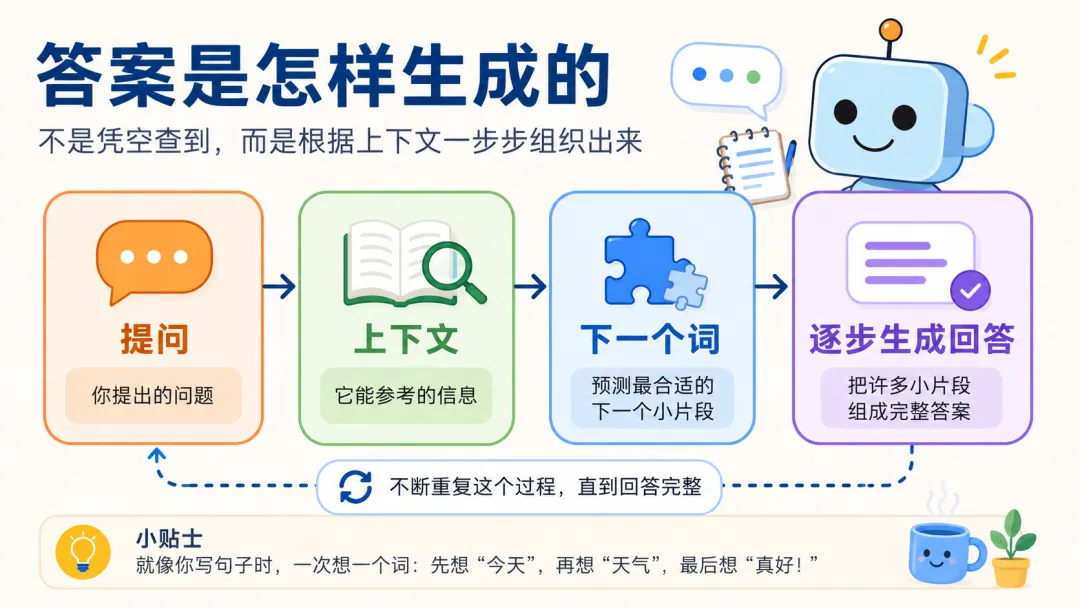
图 2:从提示词到回答,是一个不断利用上下文、生成小片段、再继续生成的过程。
3. 它为什么会写、会改、会总结?
如果 AI 不是“查答案机器”,它为什么能写方案、改文案、总结会议纪要?
原因反而在这里:它很会看语言里的结构。
比如你让它“把这段话改得更口语”,它会识别哪些词太书面,哪些句子太长,哪里可以换成更日常的表达。你让它“总结这份材料”,它会找重复出现的主题、关键行动、人物关系和时间线。你让它“写一封客气但不卑微的催款邮件”,它会把语气拿捏到一个大致合适的位置。
这不是因为它像人一样经历过催款,也不是因为它刚刚查到一封完美模板。更接近的说法是:它在大量文本里学到了“这种场景通常怎么表达”。
普通人用 AI 最顺手的地方,也常常不是问它一个孤零零的事实,而是让它帮你把一堆半成品变成能看的东西。比如:把会议录音整理成纪要,把乱糟糟的想法改成提纲,把一段生硬说明改成客户能看懂的话。
这时候,它像一个不嫌麻烦的初稿助手。你给得越具体,它越少乱发挥。
一个小例子:“帮我解释医保报销”太宽;“根据我上传的这份文件,用 200 字给爸妈解释报销流程,不要新增文件里没有的信息”会稳很多。
4. 为什么它会一本正经地答错?
问题也正出在这里。大模型擅长生成“像回答的回答”,但“像”不是“真”。
OpenAI Help Center 对这个问题说得很直白:ChatGPT 会基于训练数据中的模式给出有用回复,但也可能产生错误或误导性输出;有时它听起来很自信,即使答案是错的。OpenAI 还提醒,重要信息要从可靠来源核查。
Anthropic 的 Claude 文档也提到,即使是先进语言模型,也可能生成与事实不符或与上下文不一致的文本;降低幻觉的方法包括引用核查、让模型承认不知道,以及在高风险决策中验证关键信息。
这就像一个人很会讲故事。你给他几个关键词,他能把场面讲得很完整。但如果他没有真正看过那份合同、没有查当天价格、没有打开最新政策页面,他讲出来的完整感,可能只是语言组织能力带来的完整感。
AI 出错常见在几类地方:时间会变的信息,比如价格、排名、活动日期;需要精确引用的信息,比如法律条款、论文出处、合同原文;还有本来就模糊的问题,比如“最好的方案是什么”。这些地方最容易把“语言顺滑”误看成“事实可靠”。
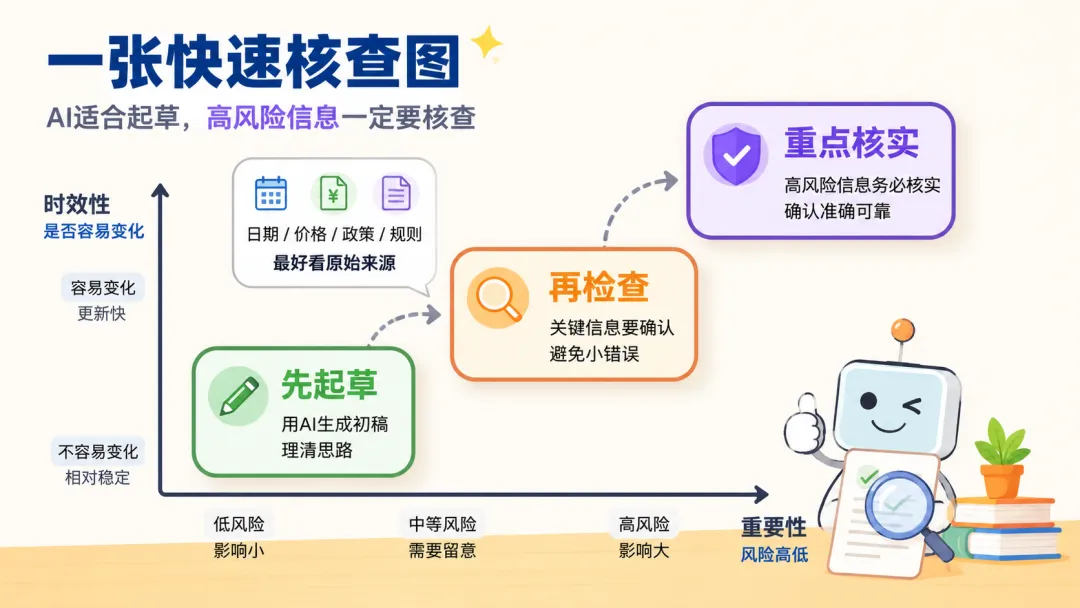
图 3:信息越新、影响越大,越适合要求出处、引用原文或回到官方渠道核对。
5. 更好用 AI 的几个小习惯
把 AI 当搜索框用,常常会别扭。它会回答,但你不知道它有没有查;它会解释,但你不知道解释从哪里来。
一个更轻松的用法,是先分清两件事:事实归事实,表达归表达。事实要有来源;表达可以让 AI 先起草。
查资料时,可以直接说:“请只基于我给你的材料回答,材料里没有的地方标注‘未提到’。”这句话很朴素,却能明显减少胡编。
问新信息时,可以加一句:“请给出出处,并说明哪些内容需要我再核对。”尤其是政策、价格、医学、财务、合同、考试报名、签证规则这些内容,别只看 AI 的语气。
写作时,反而可以放开一点。把你的真实意图、读者是谁、语气偏好、字数范围告诉它。比如:“这段给完全不懂 AI 的家长看,别用术语,像解释手机导航那样讲。”AI 这时候的价值,不是替你决定事实,而是帮你把话说清楚。
还有一个小动作:让它先给结构,再给正文。结构像菜谱,正文像做菜。菜谱错了,后面怎么炒都费劲。
可以这样问:“先列出你会依据哪些信息回答。哪些是我提供的,哪些是你推断的,哪些需要联网或查官方资料?”
6. 搜索框找答案,AI 组织答案
理解这一点后,AI 的很多表现就不神秘了。
它能把一段粗糙文字改顺,因为它熟悉语言的肌肉记忆;它能总结一份长材料,因为它会抓上下文里的重复和重点;它会出错,因为它生成的是“当前上下文下看起来合理的回答”,不天然等于“已经核实过的事实”。
以后再打开 AI,不妨把它想成坐在旁边的写作搭子。你负责给材料、定方向、核事实;它负责把东西先组织出来。
搜索框适合找入口。AI 适合打初稿、改表达、理思路。两者放在一起,工作会顺很多。
资料依据
• OpenAI Academy:Prompting(关于 LLM 根据大量数据预测和生成回复,以及 LLM 不像人一样“知道”事情)
• OpenAI Help Center:Does ChatGPT tell the truth?(关于错误、幻觉、重要信息核查)
• Google for Developers:Introduction to Large Language Models(关于 token、概率、上下文与生成任务)
• Anthropic Claude Docs:Reduce hallucinations(关于引用、核查和高风险场景验证)
