 夜雨聆风
夜雨聆风data matters
文档是知识系统和大语言模型系统的核心输入,但PDF/图片解析一直是一个头疼的问题,真实业务里经常遇到:
缺一层稳定的文档解析,下游的大模型能力、知识系统、自动化流程就很难真正落地。PPX 解决的就是这件事。
我们做文档解析这件事已经十年。十年里一直在 AI+金融方向深耕,服务上交所、北交所、深交所等监管机构,也服务多家头部银行和券商。PPX 是这些年在真实业务里沉淀下来的一套系统——在效果、可调动资源、成本之间反复权衡之后,得出的工程实践。
PPX 是一个面向真实生产环境的 PDF / 图片解析引擎,把输入文档转换为结构化 Markdown 和 JSON,保留文本、表格、图形、公式、页面坐标和版面层次。既能作为命令行工具使用,也能作为 Python 库集成到更大的文档理解系统中。
中文叫"皮皮虾",希望这只虾,在复杂信息环境里高速感知、精准捕捉,把混乱内容拆成大模型好消化调用的结构化数据。
今天我们把它开源,欢迎大家使用。

01━━━如何安装使用
支持 uv 和 pip:
uv pip install memect-ppx onnxruntime opencv-contrib-python# 或pip install memect-ppx onnxruntime opencv-contrib-python基础用法:
# 解析单文件ppx parse document.pdf -o output/# 批量处理目录ppx parse docs/ -o output/# 指定页码范围ppx parse report.pdf --pages "1-5,10,15-20"# 强制 OCRppx parse scan.pdf --ocr yes输出结构:
document.pdf.out/├── doc.md # 完整 Markdown├── doc.json # 结构化 JSON,含对象级 bbox├── pages/ # 逐页拆分└── images/ # 提取的图片区域02━━━核心能力
colspan / rowspan03━━━一个直观的例子
真实业务里常见、也比较难处理的一类混合场景:表格主体是可编辑文字,但表头大部分区域是图片。只做纯文本提取会丢表头;只当图片处理又会损失主体里的可用文字。PPX 要做的是同时保留结构和可用内容。
输入文档局部
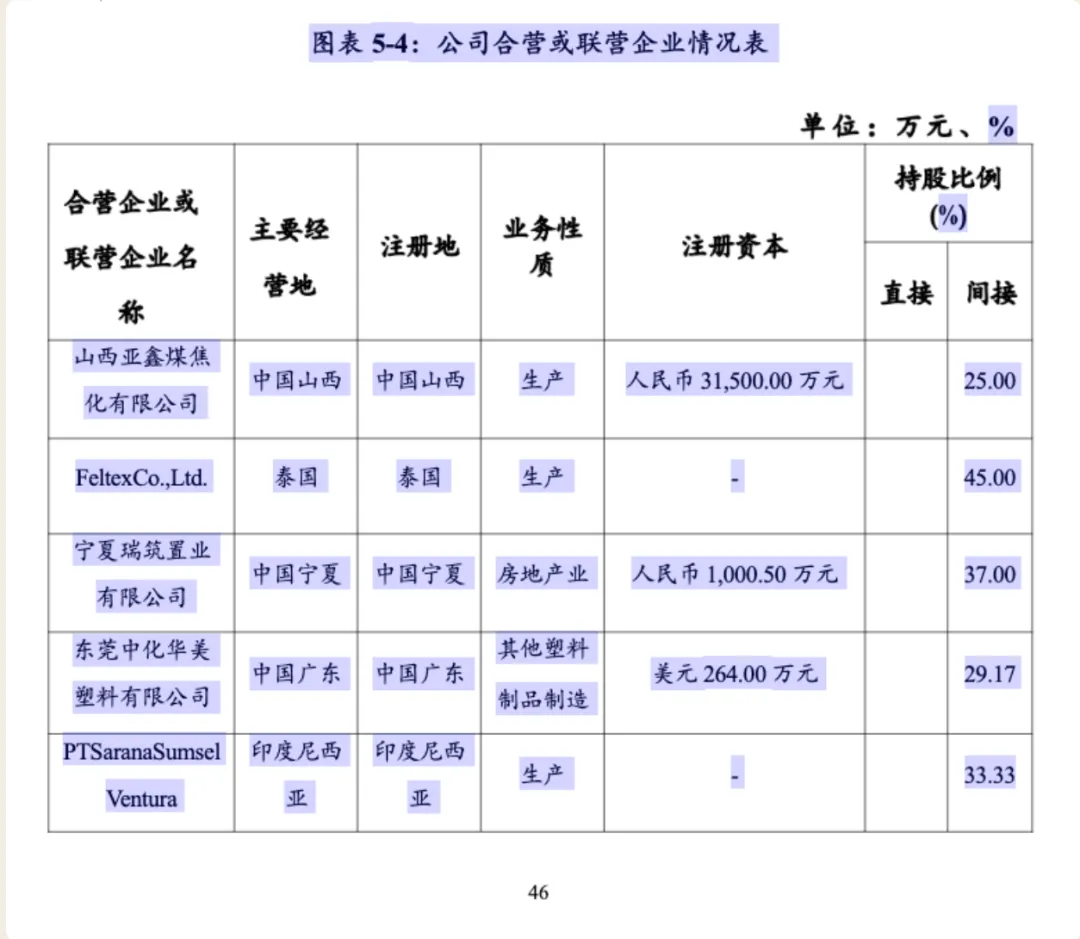
Markdown 输出
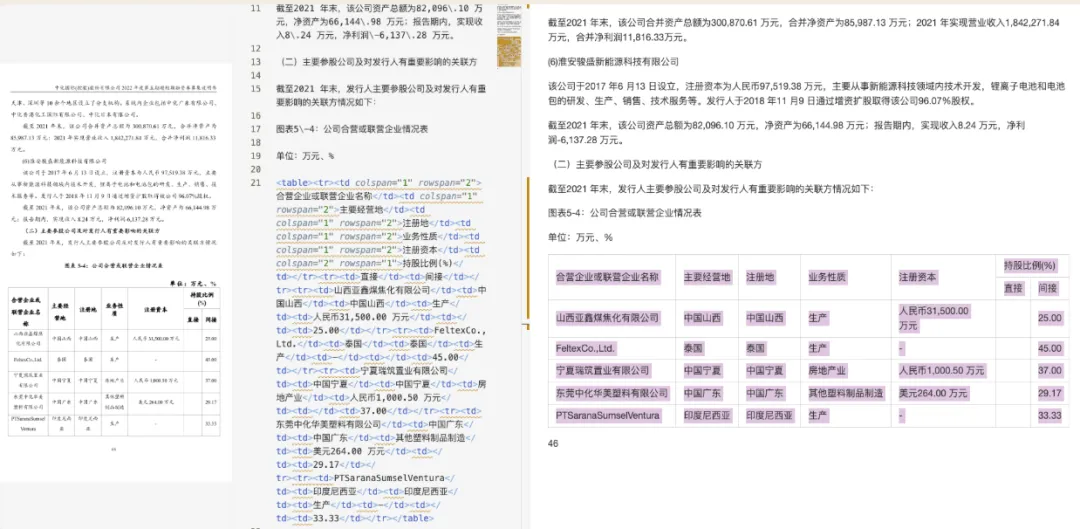
JSON 输出
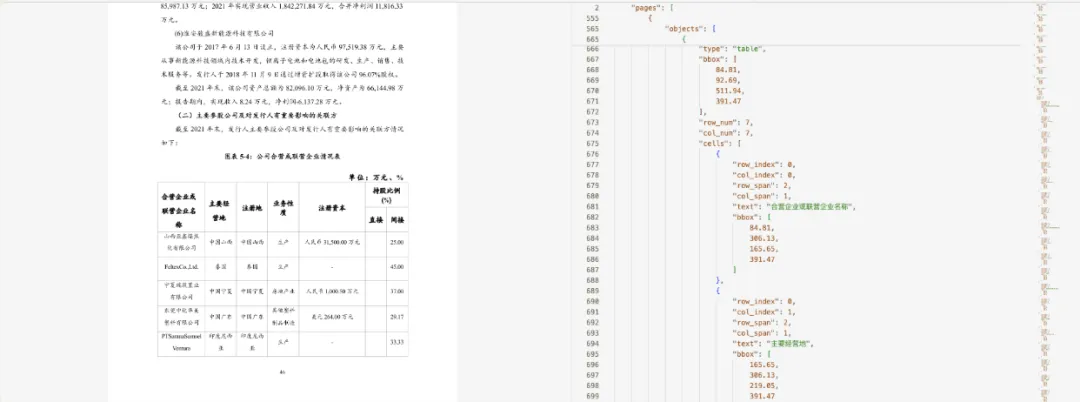
04━━━再看一个扫描件表格
扫描件表格也是常见输入。难点不在于"有没有文字",而在扫描质量、版面结构、表格边界和内容重建能不能稳定。
Markdown 输出
JSON 输出
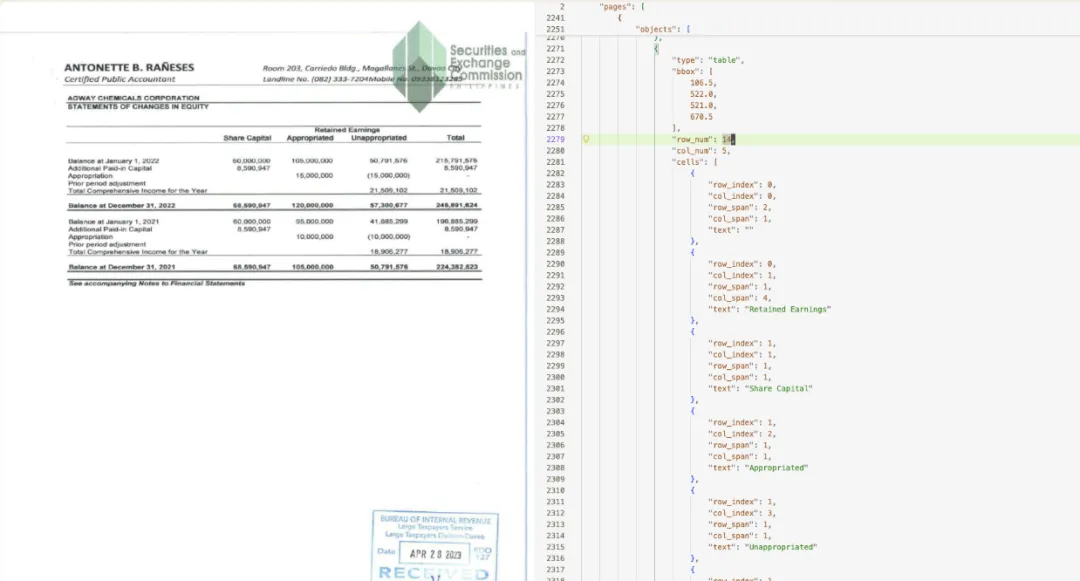
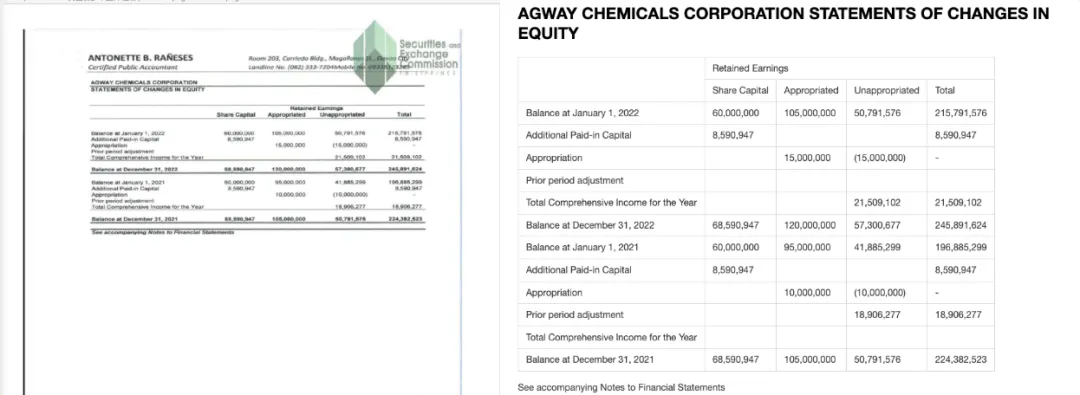
这类场景贴近知识库录入、历史资料数字化、报表归档和批量文档处理——扫描件中的表格能被恢复成结构化数据,下游检索、切分、问答链路才会稳定。
05━━━评测:OmniDocBench 上的数字
我们在 OmniDocBench(OpenDataLab 公开文档解析评测集,arXiv:2412.07626)上做了完整对比,截取 Overall 78 分以上的方案:
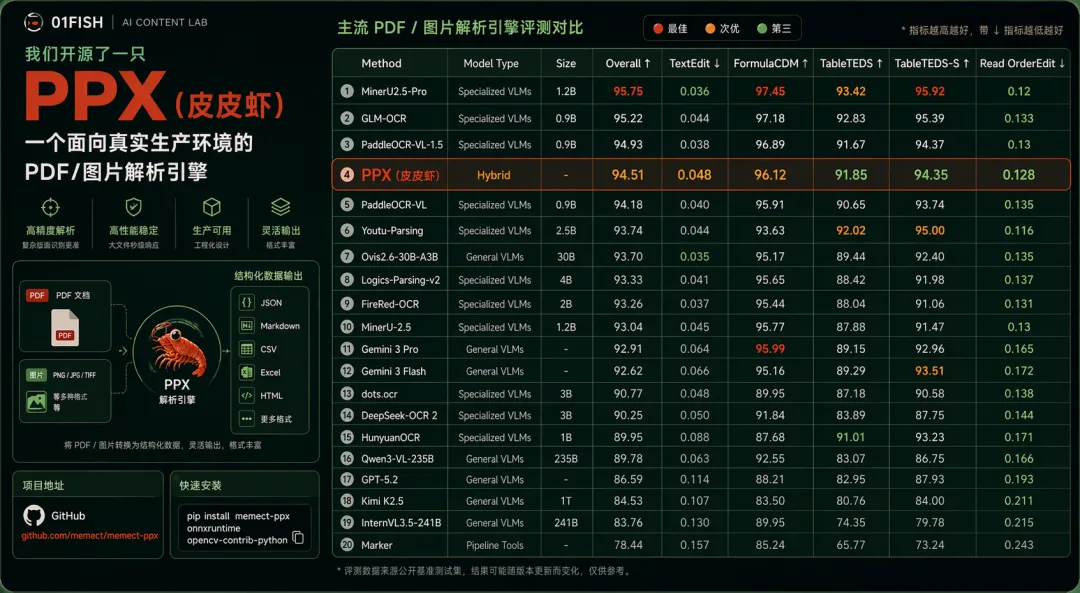
几个对着数字看的点:
PPX 的 Model Size 栏是「-」,零专用模型权重,CPU 可跑
Overall 94.51,榜单第 4 位,高于多个 0.9B–4B 的专用 VLM
高于 Gemini 3 Pro / Flash,也高于 235B 的 Qwen3-VL、241B 的 InternVL3.5、1T 的 Kimi K2.5
传统 Pipeline 方案 Marker 的参照位置是 78.44
PPX 在零权重、CPU 可跑的前提下到 94.51,走的是工程路径,在效率,可调配资源(很多场景无法调配GPU)以及成本当中权衡迭代。无需加载大模型,你无需消耗token,成本最低,若你想要再把效果提升,我们也配置了扩展,对应你需要配置API key。
榜单之外的实战
公开评测集终究只是一个切片。OmniDocBench 覆盖的文档类型和真实业务里遇到的文档还是有差距——尤其是复杂金融文档:跨页的合并单元格报表、附注脚注穿插的风险提示、带印章水印的监管披露、几十页连着的明细科目表。这类材料既考验版面分析,也考验对噪声的容忍度,公开榜单里不太容易见到。
这些年我们处理的大多是这类文档,所以优化也一直是冲着"榜单看不到但真实业务里会爆的地方"去的——无边框表格的新策略、跨页表格的续接、页眉页脚脚注的剥离、Wingdings 和老 Word 的字符映射、扫描件里印章水印的规避、财务报表里空值单元格的语义识别。这些能力不一定在公开 benchmark 上体现得很明显,但一跑上市公司年报、募集说明书、监管披露,差距立刻就出来。
更靠谱的判断方式是:把你手头最难啃的那份文档扔进去跑一遍,看输出结果下游能不能直接用。
Benchmark 基于 OmniDocBench ↗,数据集仅限研究用途。
06━━━一个真实文档的实测:markitdown 对比
公开榜单之外,我们还用一份真实业务文档做了端到端对比。
测试文档:中化国际 2022 年度第五期超短期融资券募集说明书,190 页 PDF。这类募集说明书是知识库、合规检索、RAG 问答非常典型的输入——有目录、有大量跨页表格、有扫描件插页、有财务报表、有风险提示。
同一份文档分别喂给 microsoft/markitdown(40k star,定位是 utility for converting various files to Markdown)和 PPX:

▴ 测试对比示意
markitdown:
190 页 1 秒内跑完,速度快
表格结构乱,没还原成可用的 markdown 表格
没有暴露指定页码解析的参数
版面格式不保证,不支持 bbox
默认不支持扫描件,全扫描 PDF 输出是空的,必须接入大模型走 OCR
PPX:
文本、表格、扫描件插页都进入结构化输出
表格保留 colspan / rowspan,RAG / 知识库可直接消费
每个对象带 bbox 坐标,支持回到原文定位
扫描件走本地 RapidOCR,不需要外部大模型
支持 --pages 指定页码范围
markitdown 的 README 写得很清楚:一个格式转换 utility,底下用 pdfminer、openpyxl,定位是"能跑、能看、够演示"。表格结构、扫描件 OCR、版面分析、坐标输出,不在它的设计范围里。
但下游要做 RAG、知识库、Agent 文档接入——需要可消费、可切分、可引用、可回溯原文的结构化输出——utility 层面就不够。这也是我们把 PPX 独立做出来、并开源的直接原因。
07━━━为什么它适合当前的热点场景
今天很多团队做的事情本质上都依赖文档结构化:
共同点是结果要稳定、可消费、适合下游继续处理。PPX 的设计围绕这个目标展开。
08━━━设计思路
"默认本地 + 可选大模型增强"的双路径:
隐私敏感、离线部署、快速接入 → 默认本地后端
复杂版面、高精度 → 切到 DeepSeek-OCR / PaddleOCR-VL / GLM-OCR
不绑死单一推理栈,也让开发者先低门槛跑通,再按需升级。
09━━━架构:分层流水线
PDF / Image │ ▼[PyMuPDF] ←── 原生文本提取 + 坐标 │ ├── 文本层完整? ──Yes──▶ 直接结构化 │ └── No(扫描件 / 乱码) │ ▼ [RapidOCR + RapidLayout] ←── 本地 CPU OCR + 版面分析 │ ├── 表格区域 ──▶ [table-cls 分类] ──▶ 有边框/无边框/LLM ├── 公式区域 ──▶ [rapid-latex-ocr] └── 图片区域 ──▶ 裁剪保存 │ ▼ [可选 LLM 后端] DeepSeek-OCR / PaddleOCR-VL / GLM-OCR │ ▼ Markdown + JSON(含 bbox 坐标)每一层都可独立替换。--backend 参数决定识别层走本地模型还是 vLLM 托管的视觉大模型。
10━━━数据模型:对象级结构
解析结果不是一段字符串,而是一棵对象树:
KDocument └── KPage[] ├── pdf_chars: KChar[] # PDF 原始字符,含逐字符坐标 ├── vobjects: VObject[] # 版面识别结果 └── objects: KObject[] # 最终解析对象KObject 子类:
KTextbox | |
KTable | row_num、col_num、cells[]、grid[][] |
KFormula | latex 字段和 inline 标记 |
KFigure | |
KPageHeader / Footer / Footnote | |
KChar | bold、italic、source(PDF/OCR)、quad 坐标 |
版面识别枚举(VObjectType):
TEXT / TITLE / TOC / CODE / FIGURE / CHART / TABLE / SEALFORMULA / INLINE_FORMULA / HEADER / FOOTER / FOOTNOTE保留这些结构,下游可以直接按段落切分、按表格重建、按公式 LaTeX 渲染、按页眉页脚过滤,不需要再反推。
11━━━几个工程决策
1. opencv 和 onnxruntime 不写进依赖
刻意的工程决策,不是疏漏。onnxruntime 有 cpu / gpu / directml 多个变体,opencv 有 headless / contrib 之分。写死任意一个,都会在用户环境里制造冲突。做法是把选择权交给用户:
# CPUuv pip install onnxruntime opencv-contrib-python# GPUuv pip install onnxruntime-gpu opencv-contrib-python# Linux headlessuv pip install opencv-python-headless2. cv2 的 TYPE_CHECKING 懒加载
from __future__ import annotationsfrom typing import TYPE_CHECKINGif TYPE_CHECKING: from cv2.typing import MatLike运行时不 import cv2,只在真正调用相关函数时才触发。纯 PIL 场景启动更快,cv2 未装时也不会在模块加载阶段报错。
3. 表格解析三档策略
ybk | |
wbk | |
llm | |
auto |
无边框表格是最近新增的支持——这类表格在政府文件、学术论文里极其常见,传统线检测完全失效。
4. Wingdings 字符处理
旧版 Word 导出的 PDF 里,Wingdings 编码的符号提取时会变乱码。PPX 在 src/memect/pdf/wingdings.py 内置了 Wingdings → Unicode 的完整映射,并内嵌 Source Han Sans、Noto Symbols 等开源字体。这类问题不在主流 benchmark 覆盖范围内,但在政府文件、律所合同、老版 Word 材料里极其常见。
12━━━坐标是一等公民
JSON 输出里每个对象都带 bbox:
{ "type": "table", "page": 1, "bbox": [72.0, 120.5, 540.0, 380.2], "content": "| 列1 | 列2 |\n|-----|-----|\n| A | B |", "cells": [ {"row": 0, "col": 0, "rowspan": 1, "colspan": 2, "text": "标题行"} ]}对 RAG、文档审计、合规检查等场景,"这段文字在第几页哪个位置"和"这段文字说了什么"同样重要。
仓库实测文件的输出规模:
5000 页 PDF 一次跑完、输出 13 万行;字符编码异常的文件不崩溃、产出 8 千行可用结果。
13━━━LLM 后端:OpenAI 兼容接口,本地 vLLM 托管
PPX 不绑定任何云服务。LLM 后端通过 OpenAI 兼容接口接入,vLLM 本地托管:
# DeepSeek-OCR-2,约需 20GB 显存vllm serve ./hub/deepseek-ai/DeepSeek-OCR-2 \ --served-model-name deepseek-ocr-2 \ --port 4000ppx parse report.pdf --backend deepseek \ --deepseek '{"base_url":"http://127.0.0.1:4000/v1","model":"deepseek-ocr-2"}'不接后端也行,本地 CPU 默认模式在 OmniDocBench 上跑到 94.51。本地模式还有一个 LLM 后端做不到的事:逐字符坐标——LLM 后端只能给块级 bbox,本地 OCR 精确到每个字符,对 PDF 审计、合规检查、签名定位等场景更友好。
14━━━SDK 用法
Parser 作为 context manager 管理模型生命周期,批量处理时避免显存泄漏:
from memect.pdf.parser import Parserfrom memect.pdf.base import KDocument, KDocumentFactory# 单文件with Parser() as parser: doc = KDocument("/path/your.pdf") parser.parse(doc)# 批量,多进程docs = [KDocumentFactory(p, params=None) for p in pdf_paths]Parser.batch(docs, max_workers=4)15━━━能力矩阵与平台支持
16━━━项目入口
pip install memect-ppxPDF2x快速体验走产品站或小程序;本地部署、二次开发、集成到自有系统,走开源仓库或 PyPI。
17━━━为什么选择现在开源
我们希望 PPX 不只是一个内部工具,而是能在更广文档场景中被验证、被改进、被复用的开源基础能力。
让更多开发者直接试用、部署、接入
让问题暴露得更充分,能力迭代更快
让文档解析这类底层能力更透明、更可复现
让项目逐步沉淀成可持续维护的基础设施
18━━━欢迎一起参与
如果你正在做这些方向,欢迎关注和参与:
参与方式:
19━━━交流群
扫码加入 PPX 开发者交流群,一起聊文档解析、RAG、知识库、AI+金融等话题。

─ ─ ─ ■ ─ ─ ─
调研 & 撰写:AI(Claude)协作整理主导 & 审校:01fish(memect)
