 夜雨聆风
夜雨聆风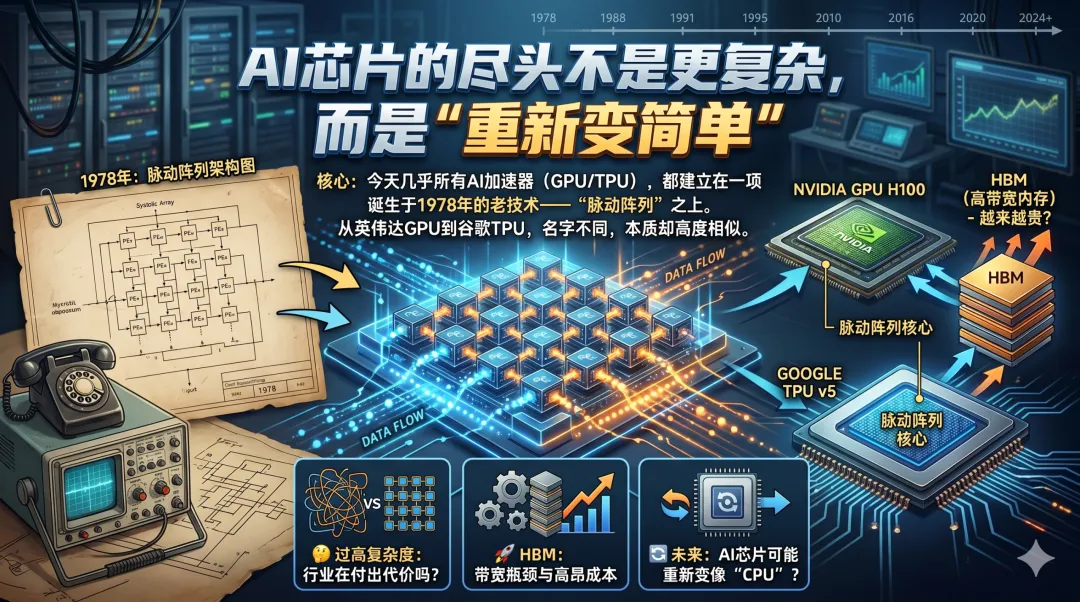
1. AI 硬件狂欢背后,可能藏着一个被忽略的真相
过去两年,AI 世界最火的词,除了“大模型”,就是“算力”。
从 NVIDIA 的 Blackwell,到 Google 的 TPU,整个行业都在渲染一种气氛:AI 芯片正进入“星际时代”。
越来越大的显存、越来越高的带宽、越来越复杂的封装工艺,让这些芯片像科幻电影里的产物。
但如果你真正深入芯片架构层面,会发现一个颇具反差的事实:
今天几乎所有 AI 加速器,核心思想其实都非常“古老”。
甚至可以说,当前 AI 革命,某种程度上仍然建立在一项 1978 年提出的技术之上。
而这项技术,就是——脉动阵列(Systolic Array)。
2. 所有 AI 芯片,本质上都在做同一件事
行业里喜欢创造新名词。
为了区分产品、提高溢价,不同厂商给同一种东西起了完全不同的名字:
NVIDIA 叫 Tensor Core Google 叫 MXU AMD 叫 Matrix Core Intel 叫 AMX
名字一个比一个科幻。
但如果把营销包装全部剥掉,你会发现:
它们几乎全是脉动阵列。
脉动阵列的本质非常简单——它是一种专门用于矩阵乘法的数据流结构。
而 AI 的核心计算,恰恰就是矩阵乘法。
所以整个 AI 行业,实际上是在围绕一种“极致优化矩阵乘法”的结构疯狂迭代。
这也是为什么很多资深架构师会调侃:
“如果明天 AI 算法突然不再依赖矩阵乘法,那今天这些 AI 芯片,大概率会瞬间失去价值。”
听起来夸张,但并不完全是玩笑。
3. AI 芯片的“暴力美学”
脉动阵列之所以强大,在于它代表了一种极致的工程哲学:
不要聪明,只要高效。
它不像 CPU 那样追求复杂逻辑判断。
它追求的是:
数据规律流动 指令重复执行 极限吞吐 极限能效
你可以把它理解成:
一台专门为矩阵乘法打造的“工业流水线”。
数据像血液一样在阵列中流动,因此才叫“脉动(Systolic)”。
而如今 AI 算力爆炸,本质上就是:
人类终于找到了一个能把矩阵乘法效率压榨到极限的硬件结构。
很多人以为 AI 芯片越来越“智能”。
实际上,它们很多时候只是越来越“简单粗暴”。
4. 一个反直觉观点:未来 AI 加速器,更像 CPU
这可能是很多 GPU 信徒最难接受的观点。
但越来越多芯片架构师开始意识到:
未来 AI 加速器,未必是“更强的 GPU”,反而可能是“带超大脉动阵列的 CPU”。
为什么?
因为今天先进制程下,真正占面积的,已经不是控制逻辑,而是:
Cache SRAM HBM 接口 大规模矩阵阵列
相比之下:
GPU 那套复杂调度系统,占比已经越来越低。
这意味着:
“到底是 GPU 风格控制器,还是 CPU 风格控制器”,正在变得没那么重要。
真正重要的是:
数据搬运效率 内存结构 阵列规模 编程成本
而在编程生态上,CPU 有一个 GPU 很难比拟的优势:
Linux + C++ 生态
今天整个 AI 世界,其实深陷在 CUDA 生态里。
NVIDIA 的 CUDA 很强,但也极其复杂。
大量 AI 工程师,本质上是在“学习如何迁就 GPU”。
而 CPU 的优势在于:
全世界都会 Linux 全世界都会 C/C++ 调试工具成熟 编译体系成熟 软件栈成熟
如果未来 AI 芯片本身就能直接运行 PyTorch,而不再依赖外部 Host 系统,总体成本会发生巨大变化。
这也是为什么越来越多人开始讨论:
“AI CPU” 也许才是真正的终局。
5. TPU 为什么能用几十人挑战 NVIDIA?
这是 AI 硬件史上最经典的问题之一。
为什么早期 TPU 团队只有几十人,却能在某些场景里打出极其惊人的性能?
核心原因,其实是:
阵列规模的代差
早期 GPU 的 Tensor Core 阵列很小。
但 TPU 选择了更激进的大阵列设计。
这会带来一个非常恐怖的效果:
向量宽度每扩大一倍:
矩阵吞吐增加 4 倍 但标量控制逻辑几乎不变
也就是说:
阵列越大,单位计算对应的“控制开销”越低。
这本质上是一种:
用硬件规模碾压软件复杂度。
于是 TPU 可以用更少的控制逻辑,完成更大规模矩阵运算。
这也是为什么很多 TPU 架构师一直强调:
真正决定 AI 芯片效率的,不只是 FLOPS,而是“标量开销占比”。
6. 但大阵列,也带来了新的悖论
问题在于:
不是所有 AI 计算都适合超大阵列。
比如:
Attention 的维度通常偏小
很多 Attention Head 的 K 维度只有:
16 32 64 128
这会导致:
大型脉动阵列根本喂不满。
利用率极低。
但另一边:
Feed Forward 网络维度极大
经常达到:
8K 16K 更高
这种场景下,大阵列会变得极其高效。
于是一个新的趋势开始出现:
异构 AI 核心
未来 AI 芯片,很可能不再是“统一架构”。
而会变成:
小阵列核心:专门处理 Attention 大阵列核心:专门处理 FFN 通用 CPU 核:负责调度与系统控制
本质上:
AI 芯片正在越来越像一个“异构计算系统”。
7. HBM,可能是今天 AI 世界最大的“奢侈税”
现在 AI 芯片最贵的部分是什么?
不是算力。
而是 HBM。
尤其在大模型时代,HBM 已经贵到离谱。
但很多业内人士开始提出一个尖锐观点:
很多 HBM,其实是在为低效软件买单。
因为现实情况是:
大量模型并没有真正优化:
KV Cache Attention 调度 Sparse Activation SSD Offloading 分布式权重管理
于是工程师只能用更大的显存“硬扛”。
这也是为什么一些架构师开始认为:
未来真正优秀的 AI 系统,未必依赖超大显存。
相反:
它们可能依赖:
更聪明的软件层 更高效的稀疏化 更精妙的分布式系统 更便宜的高速网络
换句话说:
今天很多硬件堆料,本质上是在掩盖软件能力不足。
8. 一个被忽略的趋势:AI 正在疯狂“降精度”
从 FP32 到 FP16。
从 FP16 到 FP8。
再到今天的 FP4。
整个 AI 硬件行业,其实一直在做同一件事:
用更低精度换更高吞吐
原因很简单:
大模型并不总需要那么高的数值精度。
很多时候:
8 位够用 7 位也可能够用
于是有人提出一种非常激进的思路:
Int7 + 1
即:
7 位用于真正计算 第 8 位专门用于结构化稀疏标记
这样做的好处是:
乘法器面积更小 功耗更低 吞吐更高 稀疏计算更容易实现
本质上,这是在进一步压榨硅片面积效率。
而 AI 芯片未来的发展方向,很可能就是:
“越来越少的比特,越来越高的有效算力。”
9. AI 硬件真正的未来,也许是“做减法”
过去十年,整个行业形成了一种惯性:
AI 芯片越来越复杂。
但很多顶级架构师开始反思:
复杂度,真的等于进步吗?
也许未来真正重要的,不是:
更多线缆 更多缓存 更大显存 更复杂调度器
而是:
如何把系统重新变简单
包括:
用更通用的 CPU 化架构降低开发门槛 用超大阵列压缩控制开销 用软件优化减少 HBM 依赖 用稀疏化提升真实吞吐 用分布式网络替代昂贵本地显存
归根到底:
AI 芯片竞争,最终拼的未必是谁“堆得更多”。
而是谁能:
用最少的复杂度,完成最多的计算。
10. 最后的问题:我们是否正在为“复杂度”支付巨额学费?
今天整个 AI 世界,都在追逐更大的 GPU 集群。
但一个越来越值得思考的问题是:
如果未来算力真的便宜了 100 倍,
我们会不会突然意识到:
过去十年,行业其实一直在为“复杂度崇拜”买单?
也许真正伟大的 AI 硬件革命,从来不是“更复杂”。
而是:
在性能爆炸增长之后,重新学会简单。
