 夜雨聆风
夜雨聆风一、从一份 PDF 开始的故事
2022 年 12 月 13 日,Google Brain 与 Everyday Robots 联合在 arXiv 挂出一篇论文:《RT-1: Robotics Transformer for Real-World Control at Scale》,arXiv 编号 2212.06817。
这篇论文挂出来时几乎没有人注意。同一周,OpenAI 刚刚发布 ChatGPT,整个科技圈的注意力都在那里。Robotic Transformer 这种偏冷门的题目,淹没在每天上千篇 arXiv 投稿里。
但回过头看,那一周其实有两件事同时发生:一件是 LLM 的"ChatGPT 时刻",从此把生成式 AI 推进千家万户;另一件是 Physical AI 的"RT-1 时刻",开启了一条从"机器人控制"走向"机器人基础模型"的全新道路。这两条线在 2022 年 12 月平行起步,三年后会在 GR00T、Helix、π0 这样的工业产品里汇合。
RT-1 这篇文章本身并不惊艳。它的核心模型只有 3500 万参数——比同期的 LLM 小了一千倍以上。它的数据是 13 万条遥操作 demo,覆盖 13 台 Everyday Robots 机械臂上的 700 多种任务。它的"突破"很朴实:让一个 transformer 同时吃图像和语言指令、输出离散化的动作 token,并验证了这种统一架构能在多任务、多场景上工作。
但 方向 是对的。从这一刻起,机器人学界突然有了一个新的范式可以借鉴——把机器人控制当成一个序列建模问题来解。和后来所有 VLA 的差别,只是规模和细节。

▲ VLA 的三年演化:从 35M 到 70B,从单形态到跨形态,从演示到部署
二、史前史:Gato 和 Decision Transformer 的失败尝试
要讲清楚 RT-1 为什么重要,得先讲 RT-1 之前的两次失败的尝试。
2021 年 6 月,UC Berkeley + Facebook AI + Google Brain 的联合团队(Lili Chen 等人)发了《Decision Transformer: Reinforcement Learning via Sequence Modeling》(arXiv 2106.01345)。论文的核心想法很大胆——把强化学习里的"状态、动作、奖励"三元组当成序列,喂给 GPT 风格的 transformer 自回归生成。这是第一次有人把"机器人控制"明确表达成"语言建模"。
但 Decision Transformer 当时只在仿真里跑——MuJoCo、Atari——离真机控制还远。它指出了一条路,但没自己走完。
2022 年 5 月,DeepMind 发布 Gato(arXiv 2205.06175)。这篇文章把"序列建模"的雄心推到了极致——同一个 12 亿参数的 transformer 同时处理玩 Atari、给图片配字幕、和人聊天、用机械臂堆积木 等 604 种任务,称之为"Generalist Agent"。
Gato 的目标很大,结果很尴尬——每件事都能做一点,但每件事都不顶尖。它证明了"通用序列建模"的可能性,但也暴露了一个问题:通用性和单点性能之间,存在 硬 的 trade-off。同一个 12 亿参数同时学这么多东西,每件事都吃不饱。
RT-1 在六个月后选了相反的路线——任务可以多,但形态收敛:13 台几乎一模一样的机械臂、所有数据都是同一个团队收集、所有任务都是物体操作。窄一些,但深。
这个选择决定了后面三年的方向。VLA 的发展不是 Gato 那种"无所不能的小模型",而是"专一的大模型"——先把机器人这一件事做透,再考虑跨域。
三、PaLM-E 与 RT-2:用 VLM 当骨干
2023 年 3 月,Google(Robotics at Google + Google Research)与 TU Berlin 联合发布 PaLM-E(arXiv 2303.03378)。这是一个 5620 亿参数(!)的"具身多模态语言模型"——把 PaLM 这种巨型 LLM 和视觉编码器拼到一起,让它能直接回答"看到这张厨房图,我应该先做什么"这种问题。
PaLM-E 还不是 VLA——它输出文字,文字再交给下游策略翻译成动作。但它做了一件后来证明决定性的事:它证明了 VLM 里学到的世界知识,对机器人决策是有用的。一个见过千万张图、知道"杯子要拿手柄"的 VLM,比一个从零开始学的 policy 网络聪明得多。
四个月后,2023 年 7 月 28 日,RT-2 发布(arXiv 2307.15818)。RT-2 走完了 PaLM-E 没走完的那一步——直接把 VLM 的输出训成动作 token。
具体怎么做?沿用 RT-1 已经实现过的方案——把机器人的关节角度量化成 256 个离散 bin,每个 bin 对应一个 token。然后让 PaLM-E 或 PaLI-X 这样的 VLM 在它的词表里多加这 256 个 token,重新训练时让它学会"看到这张图、听到这句话,输出动作 token 序列"。RT-2 的真正新意是把这一动作 token 化方案 搬到了一个上百亿参数的 VLM 上。
听起来简单,但效果震撼——RT-2 第一次显示出 emergent capability:能做训练数据里没出现过的组合任务("把可乐罐放到 泰勒·斯威夫特 的图片上"——它没见过泰勒·斯威夫特,但它从 VLM 里知道这是谁)。这是经典机器人学完全做不到的事。
VLA 这个术语,是这篇论文正式立起来的。从此机器人圈终于有了一个简洁的名字,可以指代这种 vision in, language in, action out 的架构。
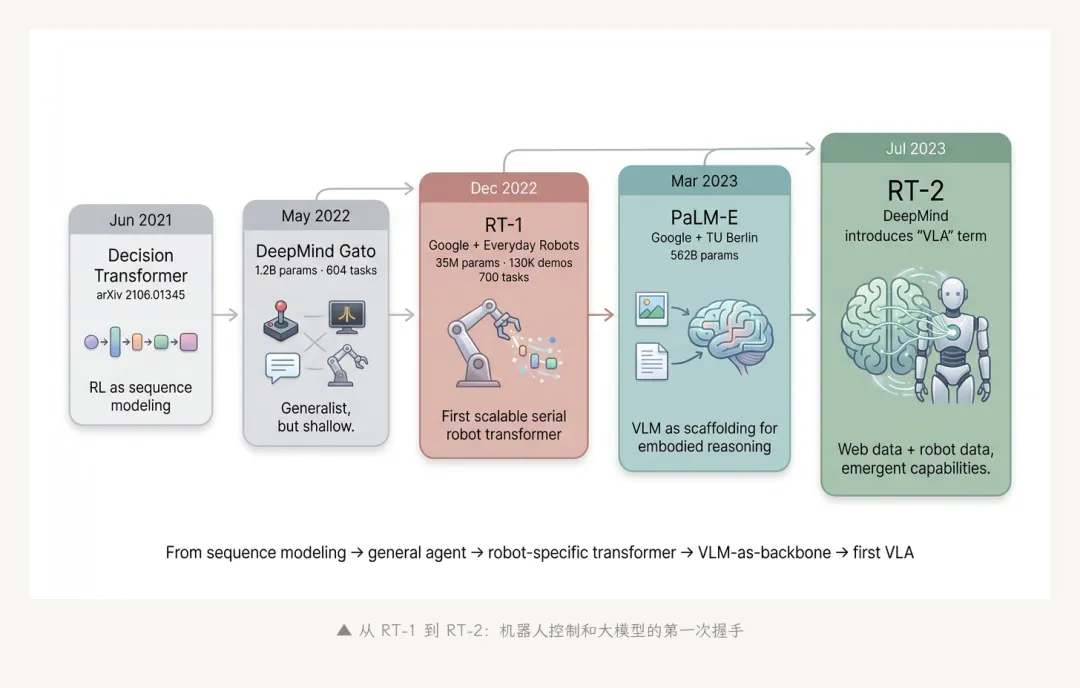
▲ 从 RT-1 到 RT-2:机器人控制和大模型的第一次握手
四、Open X-Embodiment:数据的民主化
2023 年 10 月 3 日,arXiv 2310.08864。
这一篇论文的作者列表写下来要占整整一页——21 个研究机构、近三百位作者(约 293 人)。这是机器人学历史上规模最大的一次国际合作。它的成果叫 Open X-Embodiment,简称 OXE:
22 种机器人形态、527 种技能、160K 任务、超过 100 万条轨迹。
为什么这件事重要?回到第一讲我提到的——LLM 训练用的是全网文字,机器人训练用什么?2023 年之前,每个实验室都各自收集数据、各自存格式、各自训各自的策略。Berkeley 训出来的 policy 拿到 Stanford 用不了,因为数据格式根本对不齐。
OXE 做的事是 统一格式。每一条数据都按同一个 schema 标注,图像、语言、动作、机器人型号、时间戳,所有人都能直接用。
这件事是机器人学的"ImageNet 时刻"——一个 基础数据集 出现后,整个领域才能进入"大模型 + 大数据"的范式。从这之后,几乎所有重要的 VLA 工作——Octo、OpenVLA、RT-X 自身的训练、π0 的初步预训练——都把 OXE 当默认数据底盘。
DROID(2024 年初)、BridgeData V2(2023 年中)这些后续数据集,都是在 OXE 的基础上做的扩展和细化。没有 OXE,就没有后面所有的"通用 VLA"——这是 VLA 三年演化中最低调但最重要的一块基础设施。
五、Diffusion Policy 与 ACT:低层控制的平行突破
VLA 的故事不光是大模型在跑——同一时期还有一条更细腻的平行支线,专攻低层动作的表示。
2023 年 3 月 7 日,Cheng Chi 等人在 arXiv 挂出 Diffusion Policy(arXiv 2303.04137)。这篇论文的核心想法是把图像生成里的扩散模型搬到机器人动作上——给定当前观察,从纯噪声"去噪"出未来一段动作序列。
为什么这件事重要?因为它解决了一个一直困扰机器人学的问题——多模态动作分布。同一个任务可能有几条都对的执行轨迹(左绕、右绕、上抓、下抓),传统的 MSE 损失会把它们平均成一个"骑墙"轨迹,结果哪条都做不好。扩散模型能 同时 表达这些不同选择,每次采样可以走不同的路径。Diffusion Policy 在 12 个标准任务上一举超过当时所有 baseline。
同年 4 月 23 日,Tony Z. Zhao 等人发了 ACT(Action Chunking Transformer,arXiv 2304.13705)。ACT 的贡献有两层:第一层是 动作分块——一次预测接下来的 50 步动作,而不是一步一步走;第二层是配套的 ALOHA 双臂遥操平台——只用约两万美元的硬件就能做出科研级的精细操作演示。
ALOHA 后来变成 mobile ALOHA(2024 年初,arXiv 2401.02117)——把双臂装上移动底盘,让机器人能在家里转。这套廉价 + 开源的硬件方案,让全球几百个学术实验室和创业公司都能跑相同的实验,是 ACT 在学术界爆炸式扩散的关键。
这两条支线——Diffusion Policy 的"动作扩散"和 ACT 的"动作分块"——后来都被吸收进 VLA 的主干。π0 的 flow matching 是扩散的近亲、所有现代 VLA 都默认用 action chunking。如果说 RT-2 给 VLA 提供了"上半身"(VLM 骨干),Diffusion Policy + ACT 给的是"下半身"(精细动作表示)。
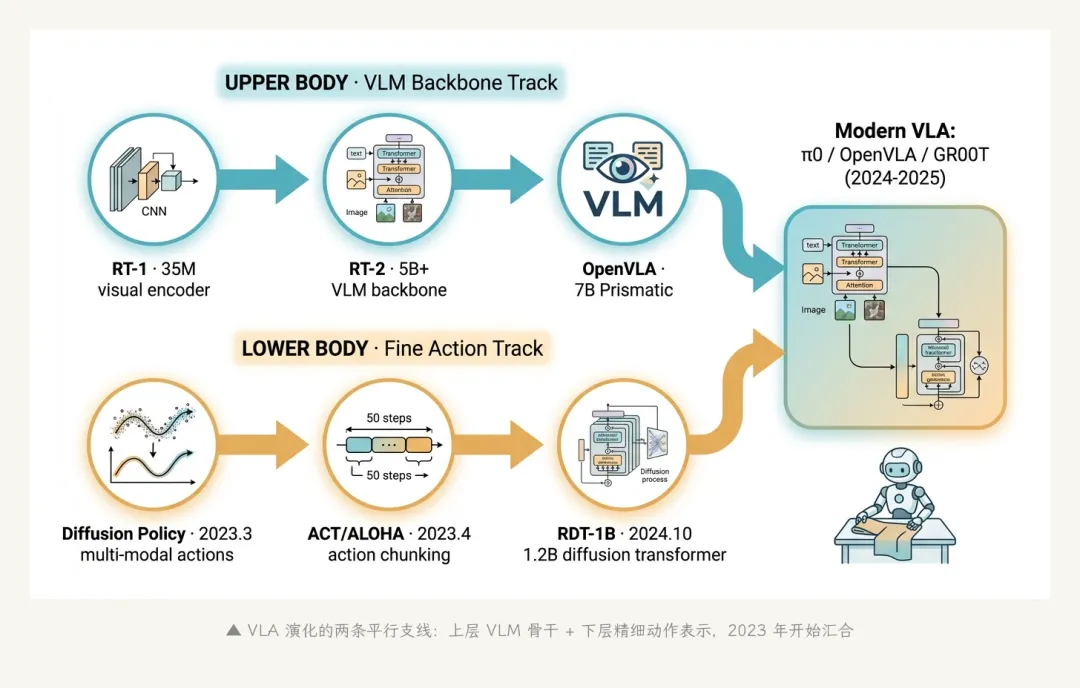
▲ VLA 演化的两条平行支线:上层 VLM 骨干 + 下层精细动作表示,2023 年开始汇合
六、开源轴接力:Octo 与 OpenVLA
2024 年 5 月,Berkeley + Stanford 的开源团队发了 Octo(arXiv 2405.12213)——第一个真正意义上的"开源通用 VLA"。Octo 的最大版本约 9300 万参数,用 OXE 里 80 万条轨迹训练。它的目标不是冲性能,而是冲 可用性——开源权重、开源代码、能在 9 种不同机器人平台上零样本启动。
Octo 让"做 VLA"这件事第一次跳出了大厂——一个普通学术实验室,下载权重、微调几小时,就能跑起一个能用的策略。
但 Octo 还不够大。2024 年 6 月,Stanford / TRI 联合发了 OpenVLA(arXiv 2406.09246)——70 亿参数、MIT 协议、基于 Prismatic-7B 的开源 VLM 骨干。这次的目标变了:不光开源,还要追平闭源 frontier。
OpenVLA 在 BridgeData V2 等基准上击败了 RT-2-X(55B 参数)——以 1/7 的参数规模。这是一个标志性时刻——开源 VLA 第一次和闭源大模型直接对垒不落下风。MIT 协议加 7B 参数加可用,OpenVLA 几乎成了之后所有学术 VLA 工作的默认起点。
到 2025 年 2 月,OpenVLA-OFT(arXiv 2502.19645)通过精细的微调策略——并行解码 + 优化动作分块 + 连续动作头——把 LIBERO benchmark 的平均成功率从 OpenVLA 的 76.5% 推到了 97.1%,吞吐量提升 26 倍。这是开源 VLA 在标准 benchmark 上彻底超过同期闭源的标志事件。
开源轴和闭源轴这次终于打成平手。机器人学界第一次出现一个像 LLM 圈那样的良性循环——闭源前沿(DeepMind RT 系、Physical Intelligence π 系)vs 开源对标(OpenVLA、Octo),双向竞争、互相借鉴。
七、π0:第一个工业级 VLA
2024 年 10 月 31 日,Physical Intelligence 发了 π0(arXiv 2410.24164)。
要讲清楚 π0 的位置,需要先讲一下 Physical Intelligence 这家公司。它 2024 年成立、坐落在旧金山。创始团队七人,包括 Karol Hausman(CEO、Google Brain 出身、RT-1/RT-2 共同作者)、Sergey Levine(Berkeley、长期机器人 RL 权威)、Chelsea Finn(Stanford、机器人 meta-learning 权威)、Brian Ichter、Quan Vuong、Lachy Groom、Adnan Esmail。这是一个 把 Google Robotics 的核心团队挖出来再做一遍 的创业公司。
他们做 π0 的方式跟所有学术工作不一样——先攒数据、再做模型。在 π0 发布之前,他们花了一年多时间,用十几台不同形态的机器人 24 小时连轴转,自己攒了一万多小时的私有数据,覆盖 68 种任务。这是同期最大的私有机器人数据集。
模型本身的设计精巧。骨干是 Google 的 PaliGemma(约 30 亿参数)。在它后面接一个 动作专家(约 3 亿参数),用 flow matching 生成 50 步的动作序列。整个模型一秒可以跑 50 次推理,足以做出连贯的双臂操作。
π0 的成绩——能 跨 七种不同形态的机器人、做 68 种不同任务,演示视频里第一次出现机器人折叠 任意 衣物、整理 任意 餐桌的画面。这之前没有任何 VLA 能做到这种程度的"放开手"。
π0 在 2024 年 10 月发布之后,VLA 这个赛道的格局变了——它第一次让人看到"通用机器人"不是 五年后 的事,而是 正在发生 的事。后续的所有 frontier VLA 工作,包括 Physical Intelligence 自己的 π0-FAST、π0.5、π*0.6,都是在 π0 的基础上做迭代。
八、长程任务的攻克:FAST、0.5、Gemini Robotics 1.5
π0 解决了"通用性"——能做很多任务、能跨多种机器人。但它还有一个问题:长程任务做不动。让它折一件衬衫可以,但让它"整理整张餐桌、把脏碗洗了"——它会在第三个子任务时崩盘。
整个 2025 年,VLA 圈子最大的工程主题就是攻克这件事。
2025 年 1 月,Physical Intelligence 发布 π0-FAST(arXiv 2501.09747)。FAST 是它的核心贡献——一个基于 DCT(离散余弦变换)的动作 tokenizer。它把连续动作离散化成 token,让 VLA 可以用 next-token 预测的方式生成动作序列,训练速度比当时的扩散类 VLA 快约 5 倍、性能持平。这一改让 VLA 的训练成本骤降,团队可以快速迭代更大的模型。
2025 年 4 月,π0.5 发布(arXiv 2504.16054)。它的核心创新是 分层架构——上层一个高级 policy 先把任务拆成子任务("先把脏碗收集到水槽 → 再开洗碗机"),下层是 π0 风格的执行 policy。这种"先想再做"的两阶段流程,让 VLA 第一次能完成几分钟、几十个子任务的长程操作。π0.5 还有一个突破——它能在陌生家庭、陌生厨房里工作,而不只是在训练时见过的房间。
2025 年 3 月,DeepMind 发布 Gemini Robotics(arXiv 2503.20020),10 月发布 Gemini Robotics 1.5(arXiv 2510.03342)。1.5 的核心创新是 embodied chain-of-thought——VLA 在输出动作之前,先用自然语言"想一想"。这种"思考再行动"的 deliberative VLA 在长程任务上表现出色,同时通过 Motion Transfer 实现了在 ALOHA、双臂 Franka、Apptronik Apollo 人形之间的零样本技能迁移。
到 2025 年 10 月,VLA 已经能可靠处理几分钟到几十分钟的连续作业。长程任务这道关,基本被跨过去了。
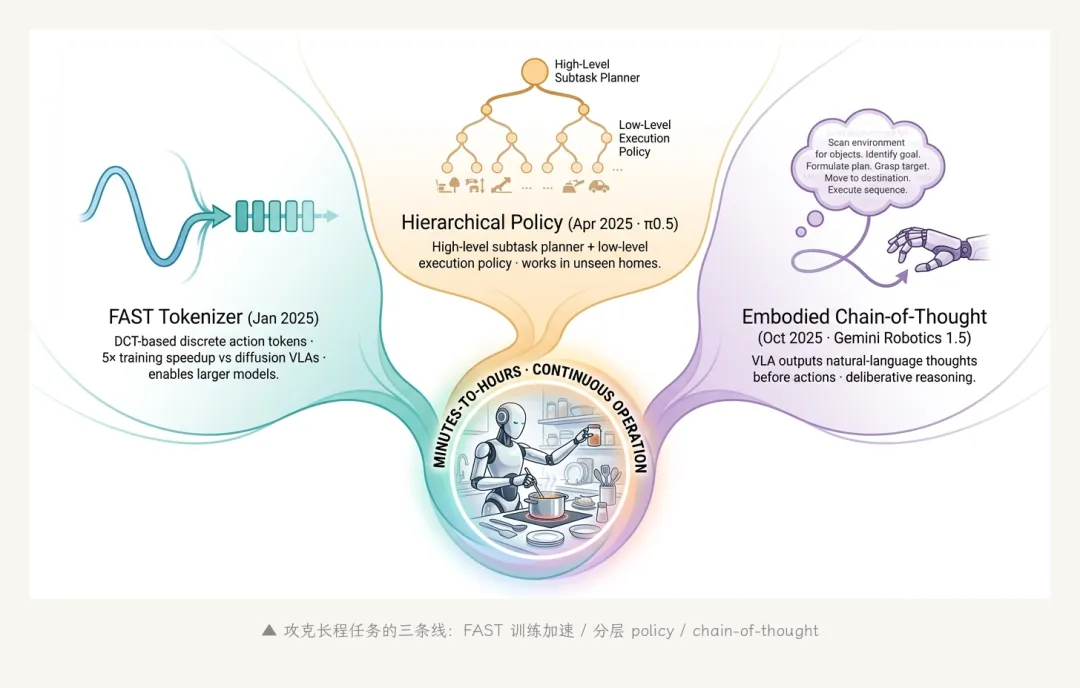
▲ 攻克长程任务的三条线:FAST 训练加速 / 分层 policy / chain-of-thought
九、跨过部署门槛:π*0.6 与 RECAP
2025 年 11 月 18 日,Physical Intelligence 发布 π0.6(arXiv 2511.14759)。这是 VLA 三年演化里我认为 最具标志意义* 的一次发布(直到 5 个月后的 π0.7 才超过它)。
为什么?因为它跨过了一道之前所有 VLA 都没跨过的门槛——从演示到部署。
之前所有 VLA 的"演示视频"都有个共同特点——精心挑选的环境、几次失败的镜头被剪掉、一次成功的镜头被放慢播放。这叫 cherry-picked demos。看着惊艳,但放进真实家庭就崩。
π*0.6 不一样。它在多个真实家庭——不是研究人员的家、不是公司的展示房间,是普通用户的家——做了大规模测试:折满满一筐衣服(不同尺寸、不同颜色、不同布料)、组装亚马逊送来的纸箱、用咖啡机做一杯意式咖啡。论文给出的关键数字是:在最难的几类任务上,RECAP 让任务吞吐量翻倍以上、失败率大约减半。
这个突破的关键是 RECAP——RL with Experience and Corrections via Advantage-conditioned Policies。它的核心想法是 把强化学习用在部署阶段:模型先用模仿学习预训练(学一个能跑的基线),然后在真实家庭部署时持续做 RL 微调(用真实环境的成功/失败信号继续优化)。
这一改动让 VLA 第一次有了 在线进化 的能力。它不光能用 demo 数据训练,还能在 使用过程中 不断变好。这是从"会做事的机器"到"会越做越好的机器"的根本跃迁。
到 2025 年底,第二讲提到的四个标志性问题——跨形态、长程、demo→deploy、sim-to-real——前三个都被推进到了"开始可用"的程度。Physical AI 的"第二档"(Generalist),从 2024 年下半年的概念,变成了 2026 年初的事实。
十、最新进展:π0.7 与"涌现式组合泛化"
写这一讲到此为止,VLA 的故事似乎已经收口。但 2026 年 4 月 16 日 Physical Intelligence 又发了 π0.7(arXiv 2604.15483)——把"通用 VLA"这件事再推了一档。
π0.7 的核心新东西是 涌现式组合泛化(emergent compositional generalization)——给一个模型看过 A 形态做 X 任务 + B 形态做 Y 任务,它能直接做 A 形态 + Y 任务,不需要补数据。
最戏剧化的演示是这样的:π0.7 在训练时 从未 见过 双臂 UR5e 折衣服 的任何示教数据;但它见过其他形态折衣服 + UR5e 做别的任务。部署到 UR5e 双臂之后,它零样本就能折一筐衣服。这是 π0.6 都做不到的。
这意味着 VLA 终于显示出和 LLM 类似的 组合性——能像 GPT 那样把"概念"和"操作"分别学到、需要时再组合。
同期,DeepMind 在 4 月 14 日发布 Gemini Robotics-ER 1.6——具身推理 VLM 的最新版,新增"仪表读数"能力(能读机械表、压力表、玻璃液位计这种工业仪表),并通过 Boston Dynamics Spot 平台演示了 机器狗自主巡检 场景。NVIDIA 的 GR00T N1.7 在 4 月也进入 Early Access——3B 参数、基于 Qwen3-VL / Cosmos-Reason2 骨干、用 EgoScale 框架在 2 万小时第一人称视频上预训练。
三家头部 VLA 同期出手——VLA 这个范式的演化节奏,2026 年中比 2025 年中又快了一倍。
十一、三年时间线收拢
最后把整条 VLA 演化串成一张时间线:
| GR00T N1.7 Early Access | |||
| Gemini Robotics-ER 1.6 | |||
| π0.7 |
三年时间。从 3500 万参数到 100 亿参数,从一种机器人到 20 种形态,从精心剪辑的演示到普通家庭的真实部署。如果你 2022 年 12 月看到 RT-1 那篇论文时,告诉自己同样的范式三年内就能产出 π*0.6,你大概率不信。

▲ VLA 演化的三年时间线:每一次跳跃都对应一个具体的工程瓶颈被攻破
十一、收尾
讲完这条线,我想留两个 reflection。
第一,VLA 的成功,是 LLM 范式的胜利在物理世界的延伸。每一次重大跳跃——RT-2 用 VLM 当骨干、π0 用 PaliGemma 当骨干、OpenVLA 用 Prismatic 当骨干——都是把 LLM 圈成熟的预训练-微调范式搬到机器人上。如果你已经熟悉 LLM 训练,VLA 在概念上不会让你陌生。最不一样的是数据,不是模型。
第二,这条线远没有结束。π*0.6 解决了"折衣服",但还没解决"做饭"——做饭需要更复杂的多步推理、更精细的工具使用、更多变的视觉判断。Atlas、Helix-02 解决了"工厂搬箱子",但还没解决"在客厅照顾老人"——后者需要的不只是动作能力,还有理解人的情绪、辨别紧急情况的能力。
VLA 走了三年,恰好走到一个分水岭——前三年是技术 可行性 的证明,下三年是技术 普及性 的争夺。谁能用 1/10 的成本、1/10 的数据,复现 π*0.6 的能力——谁就能定义下一个三年。
下一讲我们看 谁 在跑这个赛跑。第五讲会讲三大阵营——DeepMind 的 RT/Gemini 系、Physical Intelligence 的 π 系、开源轴(OpenVLA / Octo / LeRobot)。三派的哲学差异、技术押注、商业模式——把它们摆到同一张桌子上看,会有意思得多。
写在这一讲完稿时(2026-05):就在我把这一讲收尾的两个月里,π0.7、GR00T N1.7、Gemini Robotics-ER 1.6 在同一个月(4 月)同时发布。这一节的时间线在你读到时可能已经又落后了——这就是 Physical AI 现在的迭代节奏。
(第四讲完。下一讲:《三大阵营怎么分》——DeepMind / Pi / 开源轴,三派的差异比相似更值得讲。)
