 夜雨聆风
夜雨聆风最近,Garry Tan开源的GBrain刷爆AI圈,很多人第一眼把它归为「AI笔记工具」「Obsidian+RAG平替」,但看过官方文档及Karpathy的LLM Wiki原文后会发现:GBrain的核心价值,是把Wiki从「人类知识库」升级为「Agent记忆基础设施」。
Agent时代,AI的痛点早已不是「不够聪明」,而是太健忘。官方README第一句话就戳中本质:Your AI agent is smart but forgetful. 普通RAG、传统Wiki解决不了「知识沉淀、决策延续、长期记忆」的问题,而GBrain要做的,就是给Agent一个真正的「大脑」。

而LLM Wiki换了全新思路:把原始资料「编译」成持续维护的Markdown Wiki。

Karpathy用一句话定义分工:
Obsidian是IDE,LLM是程序员,Wiki是代码库。
人类只负责定方向、选资料、提问题,繁琐的维护交给AI,解决了传统Wiki「维护成本太高、慢慢荒废」的痛点。
但LLM Wiki只是第一步,GBrain在此基础上完成了3次关键进化。
GBrain官方文档明确表态:Not a note-taking app(不是笔记软件),它的定位是——compiled intelligence system(编译型情报系统)。
什么叫情报?在大量证据之上,形成当前最可信的判断,并且保留判断的来源、变化和证据链。情报建立在资料之上,并不等同于资料本身。
GBrain把每个页面拆成两个部分:

这解决了Agent最大的痛点:不是找不到资料,而是不知道该相信什么。
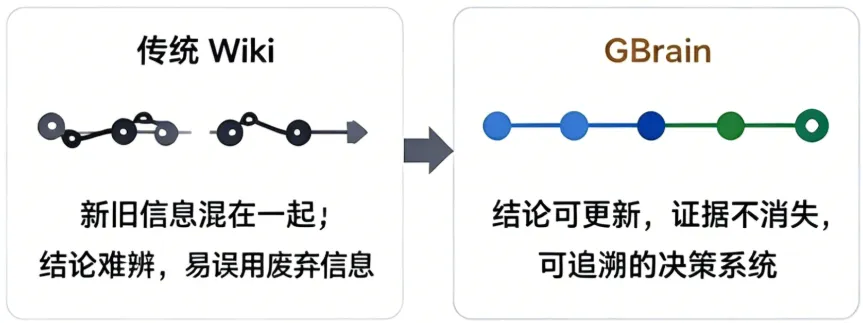
项目方案迭代、决策变更、信息更新后,传统Wiki会把新旧信息混为一谈,Agent极易误用废弃结论;而GBrain让「结论可更新、证据不消失」,变成可追溯的决策系统。
LLM Wiki用Markdown+Git优雅又好用,但规模到顶就崩。

于是GBrain做了关键升级:
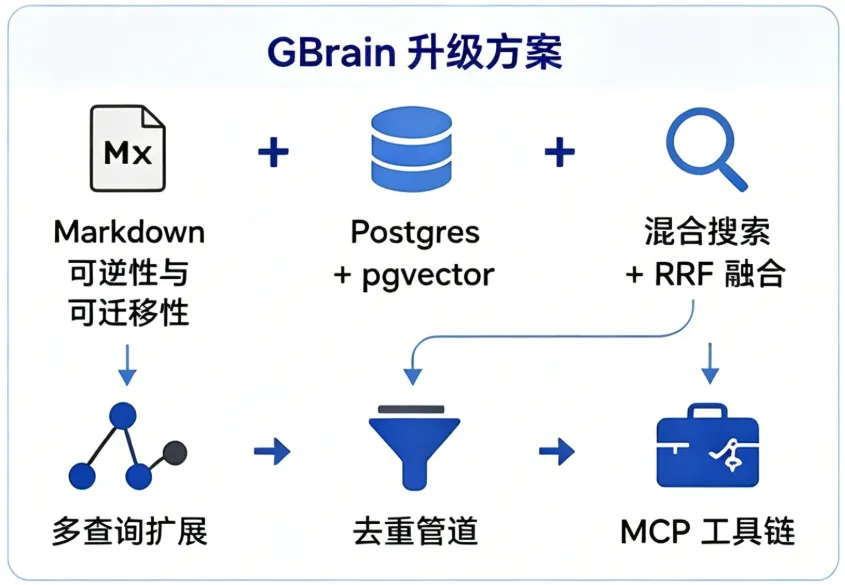
简单说:LLM Wiki负责知识编译,GBrain负责规模化工程落地。很多人讨论LLM Wiki时,会把它说成"RAG过时了"。这个说法太过片面。而真正的结论是:RAG没过时,三者是叠加关系。
- RAG:解决「找得到资料」
- LLM Wiki:解决「知识能沉淀」
- GBrain:解决「Agent长期记忆工程化」

传统Wiki(Obsidian/Notion/Logseq)的核心使用者是人,所有设计服务于人类阅读、检索、整理。它支持MCP协议,Claude Code、Cursor、Hermes等编程Agent可直接把GBrain当作知识后端,查询、写入、维护知识图谱全自动化,成为Agent工作流的核心组件,而非静态资料库。

GBrain实现了The brain wires itself(大脑自我接线):每次写入自动抽取实体,创建typed links(类型化关系):works_at、invested_in、founded、advises……
把原本需要人工整理的关系,变成系统原生能力。
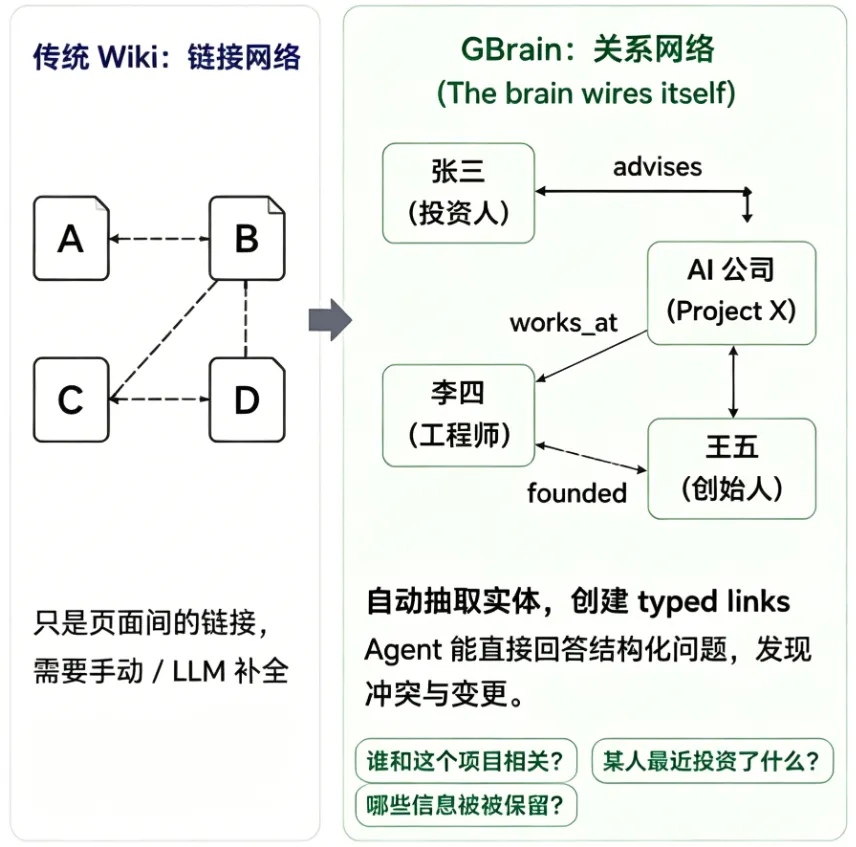
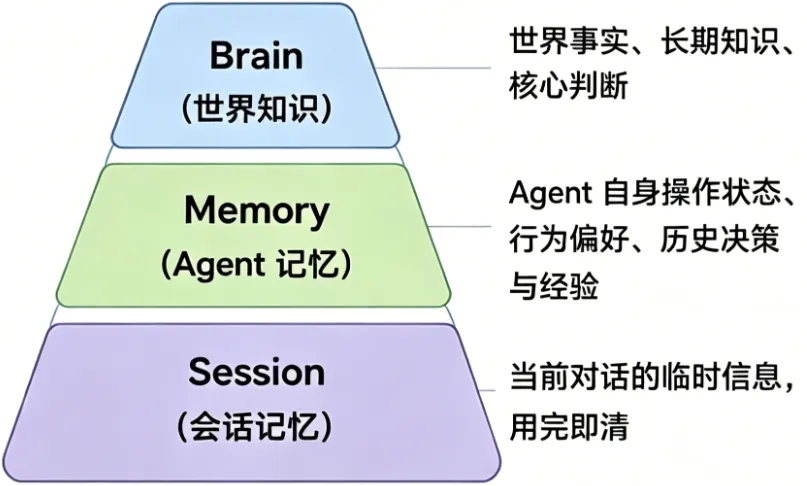
长期记忆的核心不是「记得多」,而是「记得准、记得干净」——这才是Agent长期可用的关键。

GBrain的价值,从来不是一个开源工具,而是指明了Agent时代的核心方向:
未来的AI工作流,不只拼模型能力,更拼记忆结构。模型再强,每次从零开始,只是临时顾问;能持续沉淀背景、决策、教训、资产,才是真正的工作伙伴。
对个人而言,不用急着部署GBrain,但一定要开始为自己的Agent设计长期记忆结构——这才是AI时代,真正的核心竞争力。
Agent时代,AI普遍存在健忘、记忆临时化的问题,导致资料与任务难以长期沉淀、知识易混乱。GBrain的出现,精准填补了这一空白。它并非传统笔记工具,而是面向智能Agent的编译型情报系统,代表了Agent时代长期记忆架构的革新与升级,为智能场景构建出传统Wiki无法实现的大脑级决策系统。
这一技术方向与盛为创新的业务基调高度协同。未来,我们将持续紧跟AI发展,持续在AI创新服务市场深耕突破、稳步发展。
