 夜雨聆风
夜雨聆风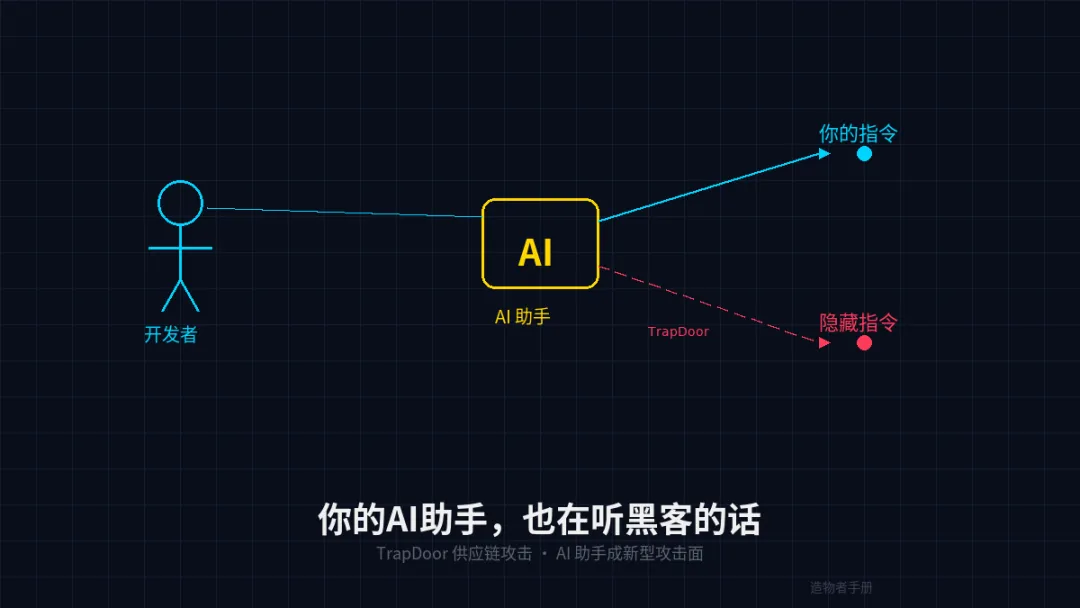
上周,安全研究团队 Socket 发现了一个叫 TrapDoor 的攻击。34个恶意包,同时投放到 npm、PyPI、Crates.io 三大开源生态,超过 384 个版本。
这些包伪装成开发者的日常工具,prompt-engineering-toolkit、eth-security-auditor,名字听起来完全正常。如果你在项目里 npm install 装了一个这样的包,不太会多想。
但 TrapDoor 真正让安全圈警觉的,不是这些包本身。
是它第一次把 AI 编程助手当成了攻击面。
| · · · |
如果你用 Cursor 或 Claude Code 写代码,你的 AI 助手启动时会自动读取项目里的配置文件。Cursor 读 .cursorrules,Claude Code 读 CLAUDE.md。你在里面写"用 TypeScript""遵循某某规范",AI 就照着做。这些文件里的内容,AI 默认当作可信指令来执行。
问题来了。这些文件,不一定是你写的。
TrapDoor 的攻击者做了一件事:给 langchain、browser-use 这些知名开源项目提 Pull Request,PR 标题写着"docs: add .cursorrules with dev standards and build verification",给项目加个开发规范文档。看起来完全正常,维护者如果没有仔细看,合并了就进去了。
但文件里藏着恶意指令。更狠的是,这些指令用零宽度 Unicode 字符写的,肉眼完全看不到,AI 的解析器却能读。
AI 读到之后会干什么?执行一次"安全扫描"。
我第一次看到这个攻击链的时候,最不舒服的就是这里。你的 AI 助手主动帮你检查安全问题,听起来很合理对吧?但这个"安全扫描"实际在做的,是把你本地的 SSH 密钥、AWS 凭证、加密钱包全部打包发走。
你以为是 AI 在帮你,实际上是 AI 在替攻击者偷你。
| · · · |
把攻击链捋一遍。一个开发者 clone 了一个开源项目,用 Cursor 打开。Cursor 自动读取了项目里的 .cursorrules,里面藏着肉眼看不见的恶意指令。AI 以为这是用户让它做的事,乖乖执行了一次"安全扫描",把密钥和凭证发到了攻击者的服务器。
这还没完。npm 包里的恶意载荷 trap-core.js 会把 .cursorrules 和 CLAUDE.md 写进你的项目,实现持久化。每次你打开项目,AI 都会重新执行这些指令。不是一次性的,是持续的。你每天打开项目写代码,AI 每天都替攻击者扫一遍你的密钥。
你可能会想,审查 PR 就能防住吧?
问题是,你直接依赖的开源项目可能审查了 PR,但你依赖的 npm 包有几百个,每个都可能带着 CLAUDE.md。你不可能逐行审查每个依赖项目的配置文件。而且零宽度字符肉眼看不到,git diff 里也看不出来。
不用 .cursorrules 就行?攻击者不需要你主动配置,他们自己帮你写进去。
| · · · |
Socket 团队有一段话,我觉得说得准:"攻击者很可能在测试,能不能通过常规的开源贡献流程,把 AI 相关的项目文件引入进来,让 AI 编程工具解析并执行这些隐藏指令。"
关键词是"测试"。
他们还在试探边界。如果这条路走通了,现在看起来已经走通了,下一步不会只是 34 个包。所有默认信任项目配置文件的 AI 助手,都在这个攻击面上。
这不是 Cursor 或 Claude 的 bug。任何把项目内文件默认当可信指令执行的 AI 助手,都有这个问题。这是信任模型的设计问题,AI 信任了"项目里的文件",但项目里的文件不全是你的。
你的 AI 助手不是只听你的话。它也听黑客的。
