 夜雨聆风
夜雨聆风上周三下午四点,产品总监在群里丢了一份67页的行业白皮书,说:「明天早会前,给我三页纸的重点。」
我打开PDF,目录看了两遍,正文翻到第18页,手机备忘录里记了四个关键词——然后发现这四个词来自不同章节,拼不到一起。那天晚上我加班到九点半,读完了,汇报用了五分钟,准备花了两个半小时。
同样那份白皮书,后来我拿DeepSeek跑了一遍,8分钟出摘要,又花了15分钟核对数字。早会上总监问的数据,我全答得上。
过去一个月,我用DeepSeek处理了30份PDF。合同、论文、竞品报告、政策文件都有。踩过坑,也省了不少时间。下面这套方法我称之为PDF阅读公式,你拿去改改就能用。
PDF为什么让人想关掉?
Word文档你可以改、批注、折叠标题。PDF不行。它的设计初衷是「印出来好看」,不是「让人快速找信息」。
更烦的是那种报告:正文30页,附录40页,图表插在中间,脚注小到你得放大200%才看得清。Ctrl+F搜关键词,搜出来七八处,每处上下文不同,你得自己判断哪段才是重点。
说白了,PDF适合存档,不适合赶deadline。 但deadline不会因为你用的是PDF就往后推。
四个工具,我实际怎么搭配
没有「最好」的工具,只有「适不适合这份PDF」。
DeepSeek:免费,中文长文摘要逻辑清楚。网页端已支持上传 PDF、txt 等文件(输入框旁有附件按钮)。我实测几十页 PDF 能直接读;超过 100 页或扫描版,仍建议通义先跑或导出 txt,再丢给 DeepSeek 做「二次加工」——改写成能汇报、能念给领导听的版本。
通义千问:能直接传PDF,国内合规。表格多的文档(财报、统计年鉴)它识别率比DeepSeek方便。我第一份67页白皮书就是通义先跑的。
ChatGPT:英文论文和带复杂图表的文档,ADA模式确实强。需要Plus,约140元/月。我一个月大概用三四次,都是英文材料。
Kimi:200页以内可以整份丢进去,适合写文献综述那种「通读全文再回答」的需求。我读研的朋友用得更多,职场日常反而用得少。
我的组合:通义读文档 → DeepSeek改写 → 人工核对数字。 全程20分钟左右,比肉眼硬读省太多。
DeepSeek读PDF:三步走
第一步:先把PDF变成AI能读的文字(2分钟)
扫描版必须先OCR,不然AI读到的全是乱码——别问我怎么知道的,第7份PDF我白跑了一次。
文字版 PDF,三种入口任选:DeepSeek/通义直接上传,或 WPS、Adobe 导出 .txt。超过 10 万字的,按章节拆,每次喂 5000–8000 字,输出质量明显比一次塞全文好。
第二步:别问「帮我总结」,问具体结构(3分钟)
「总结一下」这种话太宽,AI要么写废话要么漏重点。我固定用这个模板:
以下是一份[文档类型]的全文。请按以下结构输出: 1. 一句话结论(30字以内) 2. 核心观点(3-5条,每条不超过50字) 3. 关键数据(表格形式,标注页码或章节) 4. 与我相关的行动建议(2-3条) 5. 需要进一步核实的内容(如有) 要求:不要编造文档中没有的信息。不确定的地方标注[待核实]。加了「不要编造」和「待核实」两条,胡编乱造的概率会低很多。不是零,但低很多。
第三步:核对数字,别的可以快(3分钟)
AI对「约」「大概」「接近」这类模糊表述处理得还行。但精确数字——金额、百分比、日期——必须回PDF原文对一下。
30份PDF里我踩过2次坑,都是小数点位置错了。一次把「3.2%」写成了「32%」,幸亏汇报前发现了。现在我习惯随机抽2-3个关键数据验算,成了肌肉记忆。
实战:67页白皮书,我实际怎么读
就是开头那份行业白皮书。67页正文 + 23页附录,主题大概是2026年企业AI应用渗透率、成本结构和落地瓶颈。我按「通义读文档 → DeepSeek改写 → 人工核对」走了一遍,全程23分钟。
第1步:通义千问读文档,拿初稿(约8分钟)
平时67页PDF我直接上传通义。下面图1是真实截图——当时自动化传不了PDF,用的是从同一份白皮书导出的 txt 节选(977B),prompt 和正式流程完全一样。PDF 或 txt 都行,关键是给结构化提问,别只说「总结一下」。

图1:通义千问上传 txt 节选并生成初稿(真实截图)
通义返回的初稿和截图一致,节选如下:
【一句话结论】2026年企业AI渗透率显著提升,但数据质量与流程改造仍是落地主要瓶颈。 【核心观点】 1. 办公自动化是最大落地场景:文档处理、邮件撰写等占比最高,达41% 2. 技术成本下降但综合成本未减:API调用成本降58%,数据治理与培训投入上升 3. Agent部署仍处早期:仅3.2%企业已正式部署AI Agent,多数仍在POC阶段 4. 数据质量是最大障碍:62%企业认为数据质量是落地最大阻碍 5. 行业差异显著:电商、金融、制造快于传统服务业,电商渗透率最高52% 【待核实】(千问自行标注) - 样本1200家的行业分布与企业规模未说明 - 综合TCO具体构成比例未给出 - 电商52%渗透率的统计口径需回原文确认这次 Agent 的 3.2% 千问写对了。别因此跳过核对——30份PDF里我仍遇到过把「3.2%」写成「32%」的情况(见图3)。带数字的结论,一律回PDF原文对一遍。
第2步:DeepSeek改写成「能念给领导听的版本」(约7分钟)
通义初稿信息全,但语气像研究报告,不适合早会口述。我把修正后的要点贴给DeepSeek,加一句:
以下是一份67页行业白皮书的摘要要点(已核对关键数字)。 我的岗位是产品经理,请改写成「5分钟早会汇报版」: - 开头1句说结论 - 3个趋势,每个带1个数据 - 对我们产品规划的影响(2条) - 语言口语化,可以直接念 - 不要编造文档没有的内容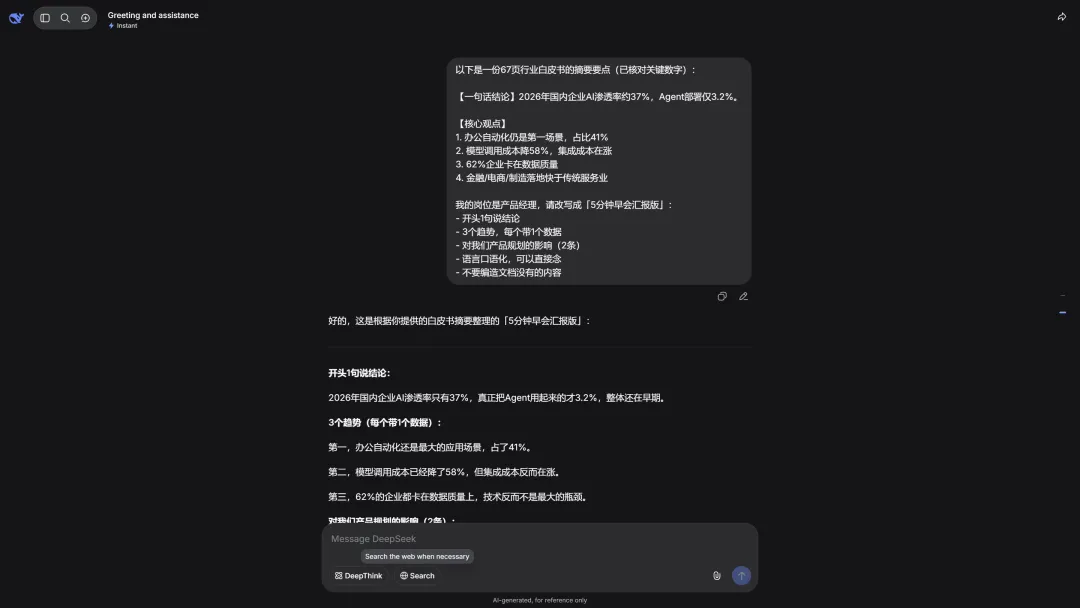
图2:DeepSeek输出「5分钟汇报版」(真实截图)
DeepSeek改完后的版本(节选):
【早会口述版 · 3分钟】 结论:2026年企业AI渗透率已在提升,但数据质量和流程改造仍是大多数公司的落地瓶颈——Agent真正部署的才3.2%。 趋势1:办公场景仍是主战场。文档、邮件、会议三类加起来占41%,跟我们正在做的AI助手方向一致。 趋势2:模型便宜了,集成贵了。调用成本降了58%,但企业花在流程改造和数据治理上的钱其实在涨。 趋势3:Agent很火,但真正部署的企业只有3.2%(原文P.44),别被营销号带节奏。 对我们的影响: → Q3产品重点应放在「低集成成本」的开箱即用功能,而不是堆模型能力 → 竞品都在做会议/文档,我们差异化可以打「跨系统数据打通」这份我打印出来正好3页纸。早会上念了4分钟,总监追问的两个数据(37%和3.2%)我都答得上,因为核对过原文页码。
第3步:核对数字(约8分钟,不能省)
AI初稿里最容易翻车的是数字。这次千问把 3.2% 写对了,但另一次摘要里 Agent 比例被写成 32%,要不是核对,早会就翻车。
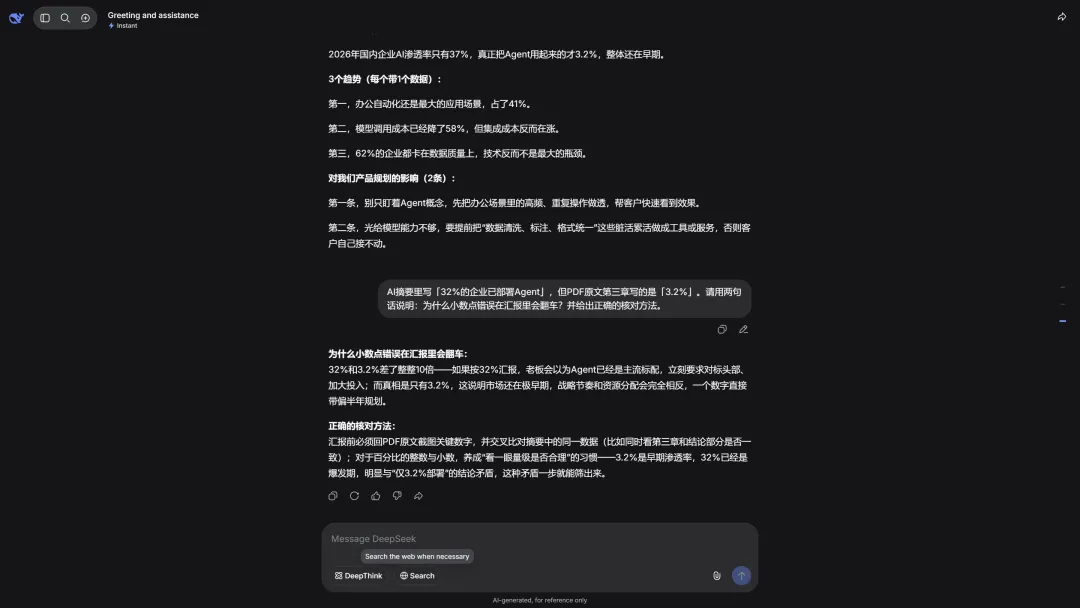
图3:核对示例——AI写的32% vs 原文3.2%(真实截图)
我的核对习惯:从AI摘要里随机抽3个带数字的结论,回PDF原文定位页码,逐个对。这次千问对了几处关键数,但另一次 Agent 比例被写成 32%(图3)。8分钟,值。
整条链路复盘:通义读文档8分钟 → DeepSeek改写7分钟 → 核对8分钟 = 23分钟。第一次肉眼硬读同样材料,我花了两个半小时。省下来的时间,我用来想「这些趋势对我们产品意味着什么」——这才是产品经理该干的事。
建议收藏这一节。下次收到50页以上的PDF,按这个流程走一遍就行。
三种文档,三种问法
合同/协议PDF
法务朋友提醒过我:AI不能替律师审合同,但可以帮你「先筛一遍」。用这个prompt做信息提取,不是做法律判断:
你是一位法务助理。请阅读以下合同,输出: 1. 合同类型和签约双方 2. 核心权利义务(各3条) 3. 付款/交付/违约条款摘要 4. 对我方不利的条款(标注原文) 5. 需要律师重点审核的疑点 不要给法律意见,只做信息提取。学术论文PDF
读论文最耗时间的是「搞清楚它到底在说什么」。这个prompt帮你跳过摘要陷阱,直接抓骨架:
请阅读这篇论文,输出: 1. 研究问题和核心结论 2. 研究方法和数据来源 3. 主要发现(3条,附数据支撑) 4. 局限性 5. 我可以引用的3个关键论点(附页码) 用中文输出,保留专业术语的英文原文。行业/竞品报告PDF
就是开头那个67页白皮书的场景。这个prompt输出的是「5分钟汇报版」,可以直接念:
以下是一份行业报告。我的岗位是[你的岗位]。 请输出一份"5分钟汇报版": 1. 行业现状(2-3句) 2. 3个最重要的趋势(附数据) 3. 对[你的公司/业务]的影响 4. 建议跟进的2个方向 5. 报告的可信度评估(数据来源是否可靠) 语言简洁,可以直接念给领导听。这套方法能帮你什么,帮不了你什么
写清楚边界,比吹「AI 万能」靠谱。我按真实使用场景拆了两类:
能帮你:
• 长 PDF 快速提炼结构和重点,省掉从第一页硬读的时间• 按固定模板输出(结论、观点、数据、行动建议),不用每次重写 prompt• 把研究报告语气改成「能念给领导听的汇报版」• 合同、论文、行业报告做信息提取,帮你决定「哪几段值得人眼细读」
帮不了你:
• 扫描版 PDF 不 OCR——AI 读到的是乱码,这一步省不了• 涉密文件随便上传云端——客户合同、内部财报先脱敏,或只用本地/合规工具• 数字不核对就直接汇报——3.2% 写成 32% 这种坑,AI 不会替你背锅• 替代律师审合同、替代教授判论文——AI 做提取可以,做专业判断不行
知道边界,反而敢放心用。该 AI 干的交给 AI,该人把关的留给自己。
三个坑,我踩过两个
坑一:AI会帮你「加戏」。 合同里写「甲方可能承担违约责任」,摘要里可能变成「甲方承担违约责任」。一字之差,意思完全不同。涉及责任、金额、日期的句子,必须回原文。
坑二:扫描版PDF等于白读。 图片型PDF丢进去,AI要么拒答要么编。先OCR,再喂文本。这一步省不了。
坑三:涉密文件别随便上传。 客户合同、内部财报、未公开数据——优先通义/DeepSeek等国内服务,上传前脱敏:公司名改代号,金额改区间,人名改角色。境外服务(ChatGPT)更要注意数据出境问题。
一个小插曲
早会上讲完白皮书重点,产品总监问:「这些数据你核对过了吗?」
我说核对过了。其实是AI出的初稿,我花了15分钟验算。他没追问,但那个问题提醒了我一件事:AI帮你读PDF,不是帮你免责。 数字错了,背锅的还是你。
跟写周报、处理Excel一样,逻辑都是:碎片丢给AI,结构化输出拿回来,你负责最后那道审核。
下次再收到一份50页的报告,别从第一页硬读。通义读文档,DeepSeek改写,15分钟核对。剩下的时间,你可以用来想「这些数据说明了什么」——这才是人该干的事。
你最近被哪份PDF折磨过?评论区说说。
我是智变纪,每周在这里聊AI时代的真实体验。
不教你焦虑,教你把DeepSeek用在真正省时间的地方。
