 夜雨聆风
夜雨聆风一、简单聊聊MinerU是什么
MinerU 是上海人工智能实验室(OpenDataLab)开源的高质量文档智能解析工具,专门解决「把 PDF、扫描件、图片等非结构化文档转换成大模型可用结构化数据」的问题,比如将PDF转成MD文档,这更适合喂给RAG系统。 开源项目地址:https://github.com/opendatalab/MinerU
核心能力
PDF 转 Markdown / JSON:保留标题层级、段落、列表等结构 公式识别:数学公式自动转 LaTeX 表格识别:复杂表格转 HTML / Markdown OCR 支持:扫描件、图片型 PDF 也能解析(支持 80+ 语种) 版面分析:自动识别正文、页眉页脚、图注、参考文献等 阅读顺序还原:多栏排版自动按人类阅读顺序输出
典型应用场景
RAG 知识库预处理 学术论文批量解析 合同 / 财报内容抽取 大模型训练语料清洗
二、部署环境介绍
查看当前系统及显卡版本:
lsb_release -anvidia-smi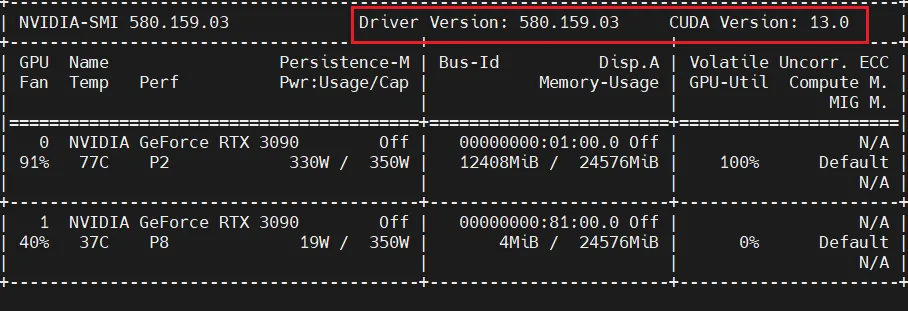
说明:宿主机 CUDA 13.0 向下兼容容器内的 CUDA 12.x,MinerU 镜像可正常运行,无需重装驱动。
三、部署
部署架构
本方案采用前后端分离的双容器架构:
mineru-api:后端服务,负责加载模型,提供 REST API(端口 8000)。可供 OpenWebUI / Hermes 等 Agent 框架调用。 mineru-gradio:前端 WEB UI(端口 7860),方便用户手动上传 PDF 等文档直接转换为 Markdown,可直观查看解析效果。
两个容器共享同一镜像,Gradio 通过 --api-url 复用 API 容器的模型,不会重复加载模型,节省显存。
3.1 Docker 与 Docker Compose 安装
本文重点介绍 MinerU 的部署,Docker 及 Docker Compose 的安装不再赘述。请确保已正确安装:
Docker(建议 24.0+) Docker Compose Plugin(建议 v2.20+) NVIDIA Container Toolkit(**1.17+**,新驱动需要)
可通过以下命令快速验证:
docker --versiondocker compose versionnvidia-ctk --versiondocker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smi最后一条命令应能在容器内列出显卡信息,表示 GPU 直通就绪。
3.2 添加 compose.yaml 文件
新建并编辑 compose.yaml 文件:
nano compose.yaml填入以下内容:
services:mineru-api:image:mineru:latestcontainer_name:mineru-apirestart:unless-stoppedports:-"8000:8000"volumes:-/mnt/ds/mineru/output:/output# 挂载路径请自行切换成自己的!!!-/mnt/ds/mineru/models:/root/.cache/modelscope# 模型缓存持久化environment:-MINERU_MODEL_SOURCE=modelscope# 国内用 modelscope,国外用 huggingface-NVIDIA_VISIBLE_DEVICES=0,1-CUDA_VISIBLE_DEVICES=0,1entrypoint:mineru-apicommand:--host0.0.0.0--port8000deploy:resources:reservations:devices:-driver:nvidiacount:allcapabilities:[gpu]shm_size:"16gb"# vLLM 需要较大共享内存ulimits:memlock:-1stack:67108864mineru-gradio:image:mineru:latestcontainer_name:mineru-gradiorestart:unless-stoppedports:-"7860:7860"volumes:-/mnt/ds/mineru/output:/outputentrypoint:mineru-gradiocommand:> --server-name 0.0.0.0 --server-port 7860 --api-url http://mineru-api:8000 --max-convert-pages 50depends_on:-mineru-api关键参数说明
MINERU_MODEL_SOURCE=modelscope | |
models | |
NVIDIA_VISIBLE_DEVICES=0,1 | |
shm_size: 16gb | |
--max-convert-pages 50 | |
depends_on |
注意:如果只有单卡,把
NVIDIA_VISIBLE_DEVICES改为0即可。
3.3 启动服务
# 执行该命令,请保证与 compose.yaml 文件在同一个目录下docker compose up -d# 跟踪 API 日志,确认服务启动状态docker logs -f mineru-api
当日志输出 Uvicorn running on http://0.0.0.0:8000 时,表示服务启动成功。
四、测试使用
4.1 访问 WEB UI
浏览器打开(IP 及端口请根据自定义设置更改):
http://<服务器IP>:7860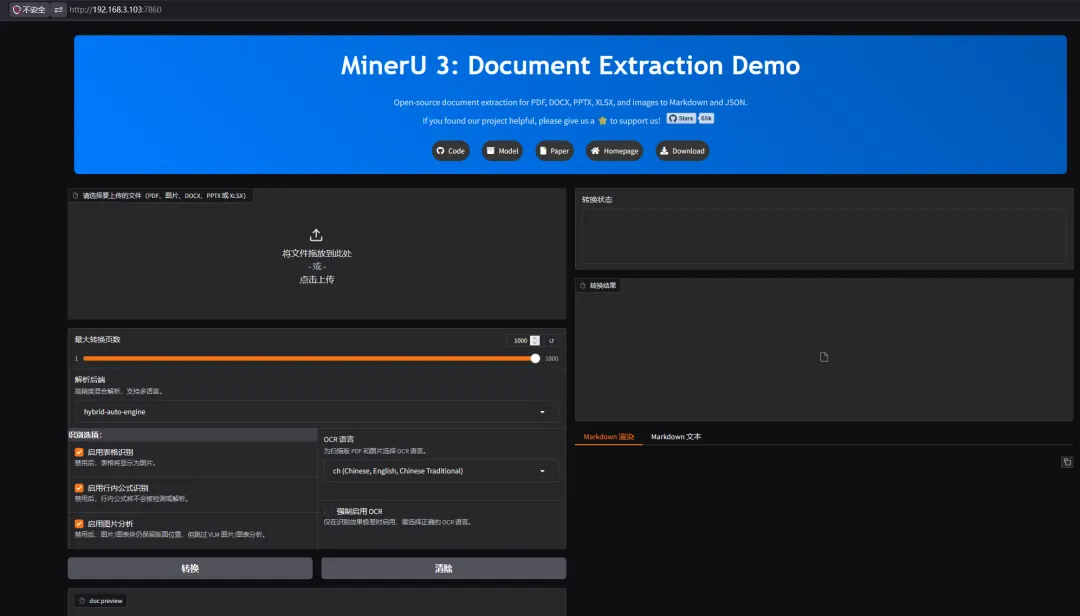
提示:第一次解析时会下载模型,比较慢,请耐心等待。后续因有缓存持久化,会直接加载。
4.2 界面操作介绍
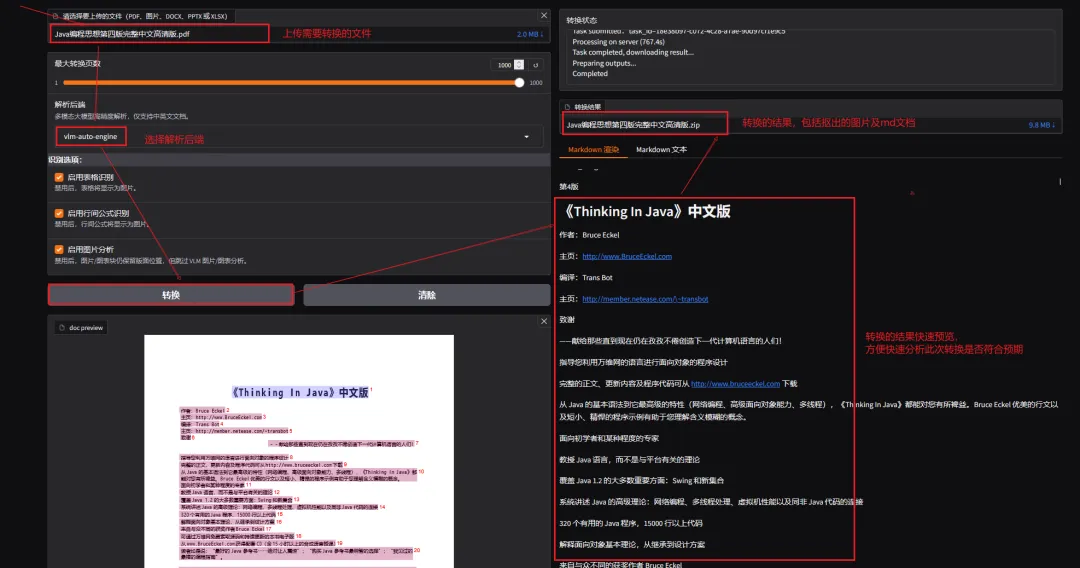
4.3 查看转换进度
如果转换比较慢,想查看解析进度,可执行以下命令实时查看日志:
# 查看 API 日志docker logs -f mineru-api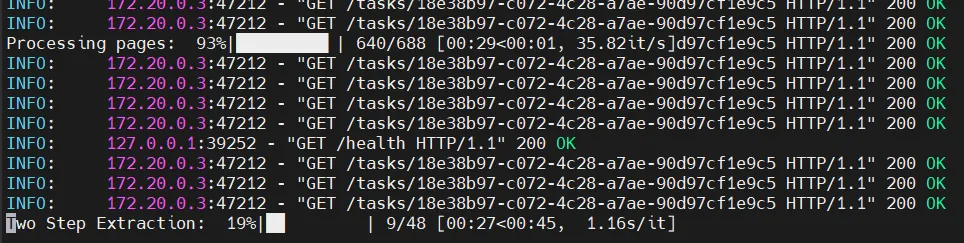
4.4 解析后端选择说明
MinerU 提供三种解析后端,可在 WEB UI 下拉框中切换:
三种后端对比
| pipeline | |||||
| vlm-auto-engine | |||||
| hybrid-auto-engine | 大部分实际场景的推荐选择 |
选择建议
pipeline:把文档解析拆成多个独立模型串行处理,需要的缓存最少(6–8GB),速度最快,精度一般,适用于已经验证过的大批量场景。 vlm-auto-engine:全部使用 VLM 模型来处理,需要的显存最多(12–20GB),速度最慢,但精度最高,通常是用于需要高精度的需求。 hybrid-auto-engine:结合 pipeline 和 vlm 的优点,是一种「智能调度」策略,显存占用 10–16GB,速度比 VLM 快但比 pipeline 慢,精度高且稳定,适合大部分场景。
五、常用运维命令
# 启动全部服务docker compose up -d# 停止全部服务docker compose down# 重启某个服务docker compose restart mineru-api# 查看运行状态docker compose ps# 查看实时日志docker compose logs -fdocker logs -f mineru-apidocker logs -f mineru-gradio# 查看资源占用docker stats mineru-api mineru-gradio# 进入容器排查问题docker exec -it mineru-api bash# 修改 compose 后完全重建docker compose downdocker compose up -d --force-recreate六、常见问题排查
Failed to initialize NVML: Driver/library version mismatch | sudo apt upgrade nvidia-container-toolkit | |
CUDA error: no kernel image is available | ||
nvidia-smi 显示 CUDA 13.0 但 PyTorch 报 CUDA 12.x | 正常现象 | |
MINERU_MODEL_SOURCE=modelscope,或挂代理 | ||
shm_size | ||
--max-convert-pages,或换 pipeline 后端 | ||
ports 映射,如 "18000:8000" | ||
sudo ufw allow 7860/tcp |
七、API 调用示例
除了 WEB UI,也可通过 REST API 调用解析服务,适合与 Agent / RAG 系统集成。
7.1 curl 调用
# pipeline 后端curl -X POST "http://localhost:8000/file_parse" \ -F "files=@/path/to/test.pdf" \ -F "backend=pipeline" \ -F "return_md=true"# hybrid 后端(推荐)curl -X POST "http://localhost:8000/file_parse" \ -F "files=@/path/to/test.pdf" \ -F "backend=hybrid-auto-engine" \ -F "return_md=true"# vlm 后端curl -X POST "http://localhost:8000/file_parse" \ -F "files=@/path/to/test.pdf" \ -F "backend=vlm-auto-engine" \ -F "return_md=true"API 在线文档地址:http://<服务器IP>:8000/docs
7.2 Python 批量调用示例
import requestsfrom pathlib import PathAPI_URL = "http://localhost:8000/file_parse"defparse_pdf(pdf_path: str, backend: str = "hybrid-auto-engine") -> str:"""调用 MinerU API 解析单个 PDF,返回 Markdown 内容"""with open(pdf_path, "rb") as f: files = {"files": (Path(pdf_path).name, f, "application/pdf")} data = {"backend": backend, "return_md": "true"} resp = requests.post(API_URL, files=files, data=data, timeout=600) resp.raise_for_status()return resp.json()["md_content"]# 批量处理pdf_dir = Path("/data/pdfs")out_dir = Path("/data/markdowns")out_dir.mkdir(exist_ok=True)for pdf in pdf_dir.glob("*.pdf"): md = parse_pdf(str(pdf)) (out_dir / f"{pdf.stem}.md").write_text(md, encoding="utf-8") print(f"✅ {pdf.name}")八、后续扩展方向
接入 RAG 系统:将 MinerU 输出的 Markdown 喂给 LangChain / LlamaIndex / Dify 构建知识库 Openclaw/Hermes Agent:与IMA、其他个人知识库或者RAG系统,配合使用。直接通过Agent管理知识库。 联动本地大模型:与 Ollama / vLLM 部署的 Qwen、Llama 等模型组合,构建完整离线问答系统
