 夜雨聆风
夜雨聆风荐读
AI赋能高校图书馆特藏资源元数据生成的实践与启示*
陈若韵,张谙宁,张欢庆,周丹燕,张倩,周文琦
深圳大学图书馆
摘要:调查分析国内外高校图书馆应用人工智能生成特藏资源元数据的实践案例,为高校图书馆推进特藏资源建设提供借鉴。本研究通过文献和网络调研,从特藏资源类型、元数据生成流程、AI工具、元数据内容以及成效挑战等方面分析21个国内外高校图书馆的典型案例。建议高校图书馆基于资源特性和服务场景来适配AI应用路径、依据技术效能选取AI工具,完善质量保障、版权合规与伦理治理等配套制度,推动AI赋能特藏资源元数据生成实践。
关键词:人工智能;元数据;高校图书馆;特藏资源;资源建设
中图分类号:G254
引文格式:陈若韵,张谙宁,张欢庆,等. AI赋能高校图书馆特藏资源元数据生成的实践与启示[J]. 数字图书馆论坛,2026,22(2):11-21.
元数据建设质量直接影响资源描述与组织的规范性,更是提升资源可发现、可访问、可互操作及可重用水平的重要基础。基于人工智能的元数据生成,是指利用AI自动提取或创建描述图书、文件、图像、音频、视频、数据集等资源的元数据。国际图联IFLA在《图书馆对人工智能的战略响应》报告中指出,AI在图书馆领域强大的应用之一是“描述性AI应用”,包括馆藏资源的规模化描述、AI增强或创建元数据等方向[1]。
特藏资源(以下简称“特藏”)是图书馆馆藏体系中极具特色的组成部分[2],涵盖珍稀文献、特色文献、专题实物等资源,其独特的文化价值与稀缺性,直接奠定了它在高校图书馆中的重要地位。这种价值与地位在国际图书馆界的共识中尤为凸显。美国研究型图书馆协会在《特藏原则声明》中指出,特藏不仅是图书馆履行使命的核心内容,更是研究型图书馆区别于其他机构的重要标识[3]。英国国家和大学图书馆协会在《学术图书馆的未来地图》报告中强调,特藏是图书馆最不可替代性的资产,直接体现图书馆的核心竞争力[4]。当前图书馆界普遍面临馆藏资源同质化的挑战,在此背景下,加强特藏建设已成为高校图书馆突破同质化困境、提升自身特色、构建差异化服务格局的核心方向。
特藏的类型包括文本类(手稿、古籍、学位论文等)、图像类(老照片、历史地图等)、音视频类(历史录音、新闻影片等)及文化实物类(历史服饰等)。不同类型的特藏,对元数据的描述精度与组织方式需求差异明显。传统依赖人工标注、建立索引的元数据生成模式,难以满足多样化需求,直接导致特藏建设中普遍存在元数据缺失、标注错误、生成效率低等问题,进而降低了资源的可发现性,限制其实际利用价值。随着AI的快速发展,这一局面得到改善。AI赋能的元数据生成,既为优化特藏的发现与利用提供了新契机,也为高校图书馆特藏建设拓展了实践路径。
本研究通过分析国内外高校图书馆应用AI生成特藏元数据的典型案例,为高校图书馆更好地运用AI提升特藏建设水平,提供可参考的实践经验。
1 相关研究
近年来,国内外学者持续探索AI特藏建设中的应用,相关研究已覆盖特藏数字化加工、描述与组织、检索与利用等多个环节。
在特藏数字化环节,多项研究指出,AI可显著提升实体资源数字化转换效率,尤其在历史文献与图像类资源处理中成效突出。例如,将光学字符识别(OCR)技术与图像处理算法相结合,将扫描版历史报纸图像转化为可搜索的结构化文本,为后续资源利用奠定基础[5]。有研究[6]进一步采用机器学习模型,对明信片、报纸图像开展质量检测与自动修复,同步识别标题、正文等结构性特征,助力数字资源的长期保存与持续使用。针对中文报纸图像版面复杂的问题,有研究[7]提出基于改进Mask R-CNN的图像内容分割方案,该方案能精准提取文本区域和图像元素,提升文字识别准确率,为后续自动描述与组织工作奠定基础。
在特藏描述与组织环节,AI的应用是当前相关研究聚焦的重点方向。在自动描述方面,相关研究[8]表明,大语言模型的引入为文本类特藏(如学位论文等)的元数据抽取提供了新路径,即通过自动识别资源标题、责任者、出版时间等元数据,可有效简化特藏的描述流程;另有研究[9]尝试拓展传统描述维度,通过识别近代教科书中的时间与空间信息,实现资源内容层面的细颗粒度揭示。在结构化组织方面,有研究[10]结合语义理解与本地化权威词表构建,实现特藏主题元数据的自动生成,进而提升特藏主题组织水平。
在特藏检索与利用环节,AI生成的元数据是提升效率、释放资源价值的关键支撑,相关研究多围绕实体识别与语义结构构建展开。实体识别研究聚焦精准捕捉特藏核心信息单元,既涵盖人名、地名、机构等通用实体,也针对古籍年号、碑帖刻工等特色场景优化识别方式,确保提取的实体信息可用于后续关联分析,为语义检索奠定基础[11]。语义结构构建研究侧重将分散信息转化为结构化知识,通过语义网络或知识图谱打破特藏孤立存储的状态,使分散资源形成语义关联,进而实现深度检索。两类研究的实践价值已通过典型案例印证:MapReader系统融合图像识别与地名链接技术,能在历史地图中自动定位地理实体、生成位置标签,提升空间检索能力[12];上海图书馆碑帖知识库借助AI提取碑帖的实体信息并进行智慧化加工与语义组织,既支持资源检索与呈现,也拓展了内容理解、比对及再利用方式[13]。
现有研究表明,应用AI能提升特藏的保存与加工效率、内容描述组织能力及检索利用水平,特藏元数据建设正从人工主导逐步向AI辅助转型。目前,该领域研究多停留在技术可行性验证与个案介绍层面,且主要面向公共图书馆、综合档案馆等公共文化机构,针对高校图书馆的系统性研究较少。因此,本研究聚焦高校图书馆的特藏元数据生成实践,梳理AI赋能高校图书馆特藏元数据生成的典型实践案例,分析现状、成效与挑战并提出相应建议。
2 调查方法与案例选取
为探究AI在高校图书馆特藏元数据生成中的实践应用,本研究采用文献调研与网络调研相结合的方法。案例来源主要包括3个渠道。①为全面检索生成式AI兴起前OCR、自然语言处理等机器学习应用和生成式AI爆发后衍生的新兴实践成果,通过中国知网、Web of Science等学术数据库检索相关研究论文,检索范围限定为2019—2025年发表的中英文文献。中文检索词包括人工智能、元数据生成、特藏资源、高校图书馆、数字特藏等,英文检索词包括artificial intelligence、metadata generation、special collections、academic libraries、digital collections等。②2022年11月ChatGPT的发布,标志着生成式AI迈入规模化普及的新阶段,为及时把握ChatGPT发布后AI在特藏元数据生成领域的最新实践,本研究同步检索2023—2025年都柏林核心元数据倡议(DCMI)年会[14]、AI4LAM的Fantastic Futures年会[15]、数字图书馆联盟(DLF)论坛[16]、Code4Lib年会[17]发布的会议论文。③访问国内外高校图书馆官网,查阅其特藏部门及数字化项目页面发布的实践案例。案例筛选遵循标准:选取高校图书馆主导的项目,确保案例贴合其实际业务需求;兼顾文本、图像、音频、视频等不同类型的特藏,确保案例的借鉴范围更具广度;聚焦案例所采用的AI工具与方法是否适配特藏的描述与组织需求;选取具有明确交付成果的案例(如已发表论文、公开研究报告、项目建成的数字化展示等),以体现应用AI的效果与实际价值。最终筛选得到21个具有代表性的国内外案例(中国3个、美国17个、加拿大1个),案例时间跨度为2019—2025年。
3 案例分析
3.1 特藏资源类型
调研案例应用AI处理的特藏主要分为文本、图像、音视频、文化实物4类,其中部分案例同时涉及2种或2种以上类型。
3.1.1 文本类特藏
11个案例涉及AI在文本类特藏元数据生成中的应用,包括原生数字文本与纸质文本。原生数字文本可直接被机器读取理解,适合运用AI开展元数据提取与生成。例如:加州大学戴维斯分校图书馆[18]、俄克拉荷马州立大学图书馆[19]应用AI提取电子学位论文元数据,圣地亚哥州立大学图书馆凭借AI实现电子政府报告的元数据自动生成[20]。纸质文本需先经数字化转为机器可读形式,再将所含信息转换为机器可理解的数据,整体处理流程更复杂。例如罗格斯大学图书处理含手写与印刷内容的纸本文献时,结合多种识别技术应对文本的多样性与复杂性馆[21]。
3.1.2 图像类特藏
8个案例涉及AI在图像类特藏元数据生成中的应用。其中,6个案例涉及实体图像资料,例如东北大学图书馆用AI处理特藏《波士顿环球报》中的印刷照片[22];2个案例涉及数字图像文件,例如卡内基梅隆大学图书馆分析数字化校园照片的图像相似度等特征,优化图像资源的组织与管理[23]。
3.1.3 音视频类特藏
4个案例涉及AI在音视频类特藏元数据生成中的应用。所有案例均涉及音频资源,例如印第安纳大学图书馆用AI自动识别并标注音乐资源,提取音乐流派、掌声、静音等特征信息[24]。3个案例涉及视频资源,如范德比尔特大学图书馆依靠自动语音识别技术提取新闻视频发言内容,结合画面人物信息标记发言人姓名,同时识别事件的时间演变过程,实现新闻视频的多维语义标注[25]。
3.1.4 文化实物类特藏
文化实物类特藏是指具有历史、艺术价值的文物类藏品,例如服饰、工艺品、古地图等。本次调研中仅弗吉尼亚理工大学图书馆运用AI生成历史服饰的材质、颜色、纹饰、用途等描述元数据,并邀请服饰领域专家完成元数据的审核与校验工作[26]。
3.2 AI赋能的特藏元数据生成流程
调研发现,高校图书馆依据特藏的类型、规模及揭示与利用需求,应用AI开展适配的元数据生成工作。本研究所称AI工具,是指利用AI开发或集成AI能力的软件应用、平台、算法及模型等。各类型资源的元数据生成过程大致包含数据获取、数据质量优化、数据分析、数据组织以及数据语义增强5个阶段,在各阶段中,所选择的AI工具不同,承担的角色与发挥的作用各有差异。
3.2.1 数据获取
特藏生成元数据的第一步是数据获取,以多模态内容识别为核心。特藏经过数字化加工后进行内容识别,包括文本、图像、音视频和文化实物的识别。识别的原始文字、图像或转录文本,构成了元数据生成流程的数据基础。各类型特藏所用的数据获取工具各不相同,不同模态的处理有专门开发的AI工具。如表1所示,对于文本类特藏,利用eScriptorium进行手写体光学字符识别,利用Google Lens进行印刷体光学字符识别;借助Google Cloud Vision识别图像类特藏的表层视觉元素;利用Whisper自动语音识别工具将音视频类特藏转化为转录文本;通过扫描获取文化实物的形态特征。
表1 AI赋能数据获取的表现及工具

3.2.2 数据质量优化
数据获取后需进行数据质量优化。这是由于部分特藏的特殊性质,包括年代久远导致的数据缺失、手写文稿易发生的数据识别错误,以及数据多语言的情况等,需对数据进行优化补全或翻译,确保数据质量,才便于进行下一步利用。常见的是利用AI对文本获取数据进行优化或翻译,例如:香港浸会大学图书馆借助Gemini工具补全华人剪报资料的文本缺漏,修复历史剪报因破损、印刷模糊导致的信息缺失[27];罗格斯大学图书馆用Google Translation工具将日语文本译为英语,促进更多读者对特藏内容的理解与利用[21]。
3.2.3 数据分析
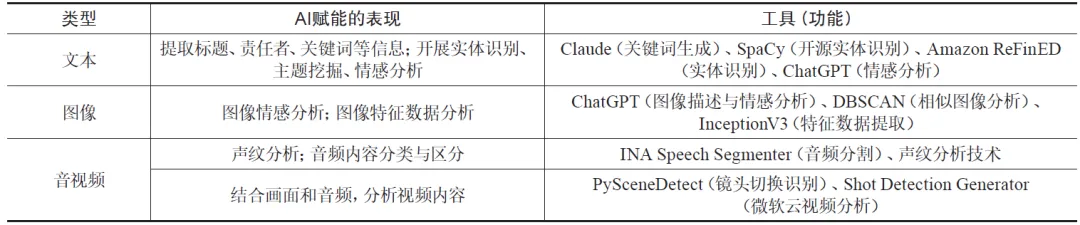
在获得经过优化的数据后,需运用AI进行数据分析与内容理解,通过信息提取、主题挖掘、情感分析、声纹分析等手段提取具有描述价值的特藏特征。如表2所示,AI能提取文本类特藏的标题、责任者、关键词等信息,以及开展主题挖掘、实体识别及情感分析,如罗格斯大学图书馆用ChatGPT分析历史日记的文本情感[21]。AI能为图像中的物体自动生成关键词及标签,以及基于图像特征数据解析更多信息。例如得克萨斯大学奥斯汀分校图书馆通过提取地图特征数据,解析街道交叉点以识别历史地图信息[28]。AI可完成音视频数据的声纹分割与镜头切换识别,例如范德比尔特大学图书馆用声纹数据区分电视新闻播报者[25],印第安纳大学图书馆用INA Speech Segmenter基于声纹分析自动分割音频并将结果自动标注为音乐、语音、噪音、静音[24]。
表2 AI赋能数据分析的表现及工具
3.2.4 数据组织
在数据组织阶段,部分案例中的高校图书馆应用AI依据相关标引规范与元数据标准对数据进行规范化组织,包括基于受控词表标引主题词或分类号,以及按照机读目录格式(MARC)、都柏林核心元数据集等通用元数据标准形成结构化描述(见表3)。例如:中佛罗里达大学图书馆使用ChatGPT检索比对《分面应用主题词表》,生成FAST主题词[29];圣地亚哥州立大学图书馆利用Python和OpenAI学习MARC规则,使电子政府出版物元数据生成与编目工作在一定程度上自动化,从而提高MARC格式编目效率[20]。
表3 AI赋能数据组织表现及工具

3.2.5 数据语义增强
在完成数据组织,资源基本可检索利用的情况下,部分案例中的高校图书馆利用AI进行数据语义增强,进一步关联元数据或标签内容,实现资源结构化和语义化表示(见表4)。一方面,部分高校图书馆利用大语言模型开发生成式语义搜索工具,例如西北大学图书馆利用大语言模型生成馆藏历史图像资源的描述信息并基于用户查询提供问答式检索服务[30];另一方面,借助AI对元数据展开语义建构或关联,例如加州大学洛杉矶分校图书馆选用亚马逊(Amazon)的ReFinED提取标注地点、组织、人物等常见实体信息,并链接到维基数据(Wikidata)、虚拟国际规范文档(VIAF)和其他权威数据[31]。
表4 AI赋能数据语义增强的表现及工具

总体来看,AI在特藏元数据生成不同环节中的应用各有侧重,可与人工专业力量形成优势互补的协同机制。在数据获取、数据质量优化阶段,面对海量、多模态的特藏,AI发挥了人工难以替代的效用,大幅降低了海量特藏数字化处理的人力成本:一方面,AI能以远超人工的速度完成印刷/手写文本、图像、音视频等不同模态资源的识别与转化;另一方面,AI具备处理数据缺损、字迹模糊、多语言混杂等复杂状态资源的能力。在数据分析、数据组织以及数据语义增强阶段,AI凭借其推理与预测能力,能自动完成信息提取、主题挖掘、实体识别、受控标引、知识关联等专业性较强的任务,但这些工作高度依赖规则、标准和专业判断,人工介入的必要性也随之增强。
调研发现,多数高校图书馆配备元数据管理与支持人员,负责提供元数据描述与支持(包括对元数据字段的描述,提供分类、标引等专业知识),构建元数据生成机制,对AI生成的元数据进行审核、校正、评价、管理。少数案例还设有特定学科领域专家,承担学科领域专业术语的创建、筛选、审核任务,对AI生成的元数据内容的学科专业性进行评价,进一步解决AI生成元数据存在的质量问题和规避侵权风险。
3.3 生成的元数据内容
高校图书馆根据不同特藏类型的特点,结合相应的元数据生成目标,应用AI生成结构化、语义化的元数据内容,有效支撑特藏的发现、管理与应用。文本类特藏主要生成题名、作者、出版时间等基本描述性元数据,以及通过语义分析提取的情感标签、主题词、关键词及摘要等语义元数据。图像类特藏可分为两类:一是基于图像中的文字内容进行识别与转录,生成与文本资源相似的元数据;二是通过图像识别提取画面中的人物、场景、物体、地理位置等信息,生成与图像内容相关的语义元数据。对于音频类特藏,一般通过语音识别技术将语音转为文本,再按文本处理流程生成描述性和语义性元数据,还能生成播报者或声音分类(如音乐、语音、噪音和静音)元数据。视频类特藏融合了音频与图像信息,除可生成与图像和音频相关的元数据外,还可识别镜头切换、场景变化、人物出场顺序等动态特征,生成时间轴式的多维元数据,支持结构化导航与深度检索。对于文化实物类特藏,以生成描述性元数据为主,涵盖材质、颜色、纹饰、用途等多维属性,并结合领域专家知识,采用扩展的专业元数据标准进行精细化描述,提升资源的可理解性与学术价值。
3.4 成效与挑战
调研发现,国内外高校图书馆用AI生成特藏元数据时,在取得显著进展的同时也面临着技术、著作权和伦理等方面的挑战。
3.4.1 实践成效
(1)提高特藏元数据生成效率。AI对效率的提升主要体现在将人工逐件识别、转录等流程转化为可批量运行、重复调用的自动化流程。对于规模大、格式一致的特藏,AI能在较短时间内完成基础识别、文本转录、信息抽取和标注,从而缓解长期存在的资源积压问题。例如:华东师范大学图书馆调用腾讯AI完成2 800本近代教科书内容的分类与识别,图片总量约35万张[9];范德比尔特大学图书馆依靠自动语音转录,完成6.2万小时新闻音视频编目,将原本需要数年完成的人工编目工作压缩至数月完成[25];加州大学伯克利分校班克罗夫特图书馆应用机器学习模型,从22万余张结构化纸表中提取人员信息,批量数据处理速度较人工提升数十倍[32];得克萨斯大学奥斯汀分校图书馆为约1.4万张消防地图自动匹配地理坐标,累计节约工时约300小时[28]。
(2)丰富特藏描述维度。传统的特藏元数据多以题名、责任者、时间等基本描述字段为主,对图像、音视频和实物类资源中的内容特征揭示不足。AI能从文本、图像、声音和视频等不同模态中提取更多细粒度信息,扩展元数据的描述范围。例如:弗吉尼亚理工大学图书馆为5 000件历史服饰特藏新增描述词汇,提升描述精细度与规范性[26];斯坦福大学图书馆从本科生论文中提取生物多样性观察记录的科学实体,增加物种、位置和栖息地类型等描述维度[33];印第安纳大学图书馆对数字馆藏视频识别镜头切换点,增加静帧或无效帧的描述维度,为视频剪辑或内容导航提供参考[24];上海交通大学图书馆提取口述历史档案中人物、机构、事件等知识单元并构建知识单元间的语义关联[34]。
(3)推动特藏项目成果的开放共享。部分高校图书馆通过公开测试数据、元数据示例与处理流程,使个案经验可以被其他机构参考和复用。例如罗格斯大学图书馆[21]、加州大学洛杉矶分校图书馆[31]发布了相关的元数据提取流程和实验数据。另有一些图书馆通过平台化、规范化方式推广实践成果,例如:斯坦福大学图书馆将提取的生物多样性元数据共享至全球生物多样性信息机构[33];印第安纳大学图书馆发布了开源音视频管理平台,供其他机构部署,助力数据开放与资源共建[24]。
3.4.2 实践挑战
(1)技术挑战。部分面向通用场景训练的AI对特藏的适应性有限,难以准确提取关键信息,直接导致元数据特征描述失真、标引缺失等,影响资源检索与利用。卡内基梅隆大学图书馆发现,基于彩色图像训练的计算机视觉模型在处理黑白历史照片时图像标注效果不佳[23]。此外,多伦多大学图书馆使用AI进行文本识别时发现,AI会遗漏特定单词或将字母“O”误认为数字“0”,且ChatGPT 3.5在处理多语种和复杂翻译标题时准确率明显低于ChatGPT 4[35]。同时,部分AI的使用对技术能力有较高要求。eScriptorium等手写文本转录工具需具备Linux环境配置能力,Google翻译API也需一定编程基础。多数馆藏编目人员缺乏相应技术素养与实操能力,中小馆藏机构也面临设备环境适配不足、技术运维成本增加等现实问题,严重限制了AI在特藏编目工作中的落地应用与常态化推广。
(2)著作权挑战。著作权问题主要体现在特藏著作权受限和AI生成元数据著作权属不明两方面。在特藏的著作权限制方面,受原有著作权约束,特藏的数字化利用与深度标引受到严格限制,影响元数据的采集范围与著录。例如:范德比尔特大学图书馆因原始资源受限,仅公开音视频转录内容的前500个字符作为摘要[25];得克萨斯大学奥斯汀分校图书馆明确不处理存在著作权问题的地图资源,以避免侵权风险[28]。在AI生成元数据的权属问题方面,现阶段相关法律法规尚未形成明确界定,模糊的著作权归属易引发纠纷,增加图书馆馆藏编目的合规风险。俄克拉荷马州立大学图书馆在将AI生成的元数据导入图书馆目录前,还需进行版权评估以确保合规[19]。这会额外增加了馆藏编目工作的审核流程与管理成本,阻碍AI元数据生成模式的高效落地。
(3)伦理挑战。隐私保护和伦理风险是需要考量的重要方面,两者将影响特藏的开放利用、元数据生产效率与服务公正性。在隐私保护层面,AI处理易引发信息泄露与隐私侵犯风险。例如:加州大学伯克利分校班克罗夫特图书馆在处理含个人身份信息、宗教信仰、健康状况等敏感信息的历史档案时,因暂未建立伦理访问机制,对相关资源访问设限[32];范德比尔特大学图书馆因公众人物识别涉及隐私,暂停新闻视频的人脸识别项目[25]。在伦理规范层面,AI易引发偏见、歧视等问题,影响元数据的客观性与公正性。例如俄克拉荷马州立大学图书馆出于防范偏见或歧视的考虑,在批量生成学位论文元数据过程中需引入严格的人工审核机制[19]。
4 AI赋能特藏元数据建设的启示与建议
AI赋能的元数据生成已逐渐成为特藏描述与组织的重要方式,更有望推动特藏元数据生成从人工编辑转向智能化、自动化模式。国内高校图书馆应立足自身实际,积极应对技术变革,充分挖掘AI在特藏建设中的应用潜力,进一步提升特藏组织效率、开放共享水平及服务教学科研的能力。根据案例调研分析,本研究从资源特性研判、工具选取与配套保障机制3个方面提出建议,为国内高校图书馆有序推进AI赋能特藏资源元数据建设提供参考。
4.1 根据资源特性与服务场景选择AI应用路径
高校图书馆开展AI赋能特藏元数据建设,首先需要从资源本身出发,研判特藏的类型特性,以及资源揭示利用的服务场景,为后续工具选取与流程设计提供决策依据。
4.1.1 按资源特性确定适配的AI应用路径
资源的载体类型与数字化程度,决定了AI能否直接介入以及适配路径是否成熟。文本类特藏因AI适配性高、实践案例丰富,是当前最适合应用AI进行元数据生成的特藏类型:原生数字文本(如电子学位论文)本身具备结构化格式,可直接用AI提取标题、作者、关键词等元数据,适配效率高、效果稳定;纸质文本(如印刷版古籍、手写手稿、纸质档案)虽需先通过OCR完成数字化加工,但当前印刷体与手写体识别工具已较为成熟,数字化加工后可复用AI生成文本类特藏元数据的路径,技术路径清晰。非文本类特藏可根据自身特点匹配特定AI并逐步推进:图像类特藏(如历史照片、地图、碑帖拓片)因数字化基础较好、相关技术工具较成熟、处理流程较易标准化,落地门槛相对较低;音频类特藏(如口述史料、历史录音)可经语音识别转录后复用AI生成文本类特藏元数据的路径提取关键信息;视频类特藏(如新闻影像、学术会议视频)需融合镜头检测、画面识别、语音转写等多模态技术;实物类特藏(如服饰)需基于立体三维信息进行识别。后两者处理流程较复杂,但随着多模态AI的发展,已具备探索基础。
4.1.2 按服务场景确定元数据生成深度
特藏的服务场景直接决定了AI生成元数据的层次与粒度,应避免脱离服务场景盲目追求全面覆盖。对于以基本检索和可访问为服务场景的特藏,可利用AI生成或补全标识符、责任者、出版信息等基础描述性元数据;对于以专题检索和分类标引为服务场景的特藏,可进一步利用AI生成主题词、分类号、摘要等内容语义元数据;对于以知识发现、数字人文研究和智慧服务为服务场景的复杂专题资源,可利用AI生成内容语义结构、视频场景描述、关键帧摘要等增强型元数据,支持资源之间的关联组织与深度利用。国内高校图书馆可根据特藏服务场景确定AI生成元数据深度,在保障揭示质量的同时合理控制建设成本,实现资源投入与服务效益的最优配比。
4.2 依据技术效能选取AI工具
在明确资源特性与服务需求之后,AI工具的选取是将方案落地的关键环节。工具选择不仅涉及功能适配,更需结合不同工具在处理精度和稳健性上的实际表现,进行科学评估与合理配置。
4.2.1 以准确性为核心标准
AI在处理不同资源时的准确性存在显著差异,这是AI工具选取的首要依据。不同工具处理同一类资源的效果可能差距明显,例如Google Lens识别印刷文本的准确率可达99%,远高于通用大语言模型在同类任务上的表现。同一工具处理不同资源的精度同样参差不齐,例如Google Lens处理印刷文本准确率(99%)远高于手写文本(74%),而引入ChatGPT等大模型后,手写文本识别准确率提升至81%[21]。同时,准确性还涉及历史语境的正确理解。佛罗里达南方学院图书馆利用ChatGPT 4.0识别图片时无法准确识别特定的历史人物(如学校创始人),导致标题虽然“视觉准确”但“历史错误”[36]。因此,AI工具选取应综合测评识别精度与语境理解能力,建议针对馆藏主要资源类型分别测试,既横向比较不同工具,也尝试将在某类资源上表现不佳的工具迁移至其他资源类型,以寻找最优匹配。国内高校图书馆可借鉴加州大学洛杉矶分校图书馆在GitHub公开测试数据和评估流程的做法,通过图书馆联盟等平台共享测试报告,避免重复投入,提升整体工具评测水平。
4.2.2 立足实际权衡工具成本效益
成本效益是国内高校图书馆在AI工具选取中普遍面临的重要考量,须结合馆内经费与人力配置综合权衡。就工具类型而言,开源工具因免费使用、支持本地部署、可按馆藏需求二次开发,是当前首选方案。例如:eScriptorium在手写文本识别方面表现优异,适合历史手稿等特藏文献的处理;Whisper可用于口述史料、历史录音等音频资源的转录。商业服务在处理精度、数据规模和技术支持上更有保障,例如商业转录工具Otter相比开源Whisper,准确率更优但长期订阅成本较高,适合对质量要求高、批量处理规模大的核心特藏项目。对于经费有限的高校图书馆,可优先使用免费工具,针对部分核心或高价值特藏则引入商业服务或定制化解决方案。同时,国内高校图书馆可通过与本校计算机、信息管理等院系建立长期合作,借助产学研协作以数据资源换取技术支持,降低自主维护成本。
4.3 构建质量管控、著作权合规与伦理治理机制
AI的引入并不意味着完全自动,高质量的特藏元数据生成有赖于系统性的配套保障机制。人机协同质量管控、著作权合规路径以及伦理风险防控构成这一保障体系的3个核心支柱。
4.3.1 建立质量评估标准,嵌入人工审校环节
AI生成的元数据在规范性、准确性、完整性和一致性方面存在不确定性,须依托系统化的质量控制机制加以管理。考虑到特藏往往具有唯一性、历史语境复杂、载体形态多样、专名和地名变体较多等特点,质量评估标准还应重点关注历史语境准确性、专名规范性和敏感信息处理合理性等问题。在此基础上,应将人工审核与修订环节嵌入AI生成元数据的工作流程。人工审校工作应优先覆盖高价值、高敏感和高复杂度资源,如特定历史人物识别、学科专业术语核验,以确保元数据最终满足服务要求。
4.3.2 明晰权利边界,制定著作权合规路径
特藏的著作权状态往往较为复杂,AI介入后进一步放大了权属不确定风险,须在处理前建立系统性的合规机制。图书馆应用AI前,应对特藏著作权状态进行系统梳理,区分已进入公有领域、获得授权使用以及仍受著作权法保护的资源,并制定差异化处理策略。对受著作权保护的资源通过有限展示与合规使用相结合,在元数据层面提供摘要性描述或部分内容预览,同时建立面向研究人员的申请与审批机制。针对AI生成元数据本身的权属不确定问题,批量入库前应开展著作权评估,并在元数据中标注生成方式和参与工具,增强透明度与可追溯性。国内高校图书馆可联合教育部高等学校图书情报工作指导委员会、中国高等教育文献保障系统等机构共同研究制定AI生成元数据著作权指南,为行业提供参考依据。
4.3.3 建立多主体协同的伦理审查机制,应对潜在社会风险
特藏在内容上更易涉及个人隐私、群体记忆及敏感历史情境,AI在识别与生成过程中若缺乏伦理约束,容易引发误读乃至伤害。图书馆应将伦理审查纳入AI处理的前置条件,组建评审团队,并根据敏感程度对特藏制定差异化的访问管理策略:对高敏感资源访问限制或延迟开放,对中低敏感资源在明确使用规范后有序开放。在批量生成元数据过程中,应保留人工复核环节,重点审查可能存在偏见或失真表述的内容,结合编目伦理原则[37]制定本机构AI赋能特藏元数据生成实践的编目伦理规范。此外,单馆探索难以支撑复杂的著作权治理与长期运维需求,建议积极联合校内职能部门、行业组织及社会机构,在用户需求调研、项目评估与成果传播等环节形成协同机制,推动特藏元数据生成的AI应用从单点试验走向可复制、可持续的发展路径。
5 结语
本研究共调研了21所国内外高校图书馆AI赋能特藏元数据生成的典型案例,从特藏类型、AI赋能的元数据生成流程、元数据内容及成效与挑战等维度展开分析。研究发现,AI正在推动特藏元数据生成由人工主导向人机协同转型,但仍需面对技术适配、质量控制、著作权合规和伦理治理等问题。未来应在明确资源特性和服务场景的基础上,审慎选择AI工具,建立系统性的配套保障机制。然而,本研究仍存在一定局限性:一方面,案例主要来源于北美地区,案例区域代表性仍有不足;另一方面,随着AI的快速迭代,部分分析结论具有阶段性特征,仍需在后续研究中结合更多实践案例加以验证和深化。未来研究可在扩大案例区域覆盖的基础上,分析AI赋能特藏元数据生成在质量、成本与治理层面的长期影响,为高校图书馆相关决策提供更具实证支撑的依据。
参考文献
[1]Developing a library strategic response to Artificial Intelligence[EB/OL]. [2026-01-10]. https://www.ifla.org/g/ai/developing-a-library-strategic-response-to-artificial-intelligence/.
[2]孙文佳,常娥. 国内外高校图书馆特藏资源组织现状探析[J]. 图书情报工作,2017,61(19):6-12.
[3]Special collections: statement of principles[EB/OL]. [2026-01-10]. https://www.arl.org/resources/special-collections-statementof-principles-research-libraries-and-the-commitment-to-special collections/.
[4] PINFIELD S,COX A,RUTTER S. Mapping the future of academic libraries: a report for SCONUL[EB/OL]. [2026-01-10]. https://eprints.whiterose.ac.uk/id/eprint/125508 .
[5]ALI D,MILLEVILLE K,VERSTOCKT S,et al. Computer vision and machine learning approaches for metadata enrichment to improve searchability of historical newspaper collections[J]. Journal of Documentation,2024,80(5):1031-1056.
[6] HAFFENDEN C,FANO E,MALMSTEN M,et al. Making and using AI in the library: creating a BERT model at the national library of Sweden[J]. College & Research Libraries,2023,84(1):30-48.
[7]倪劼,叶江松,谢恩泽. 改进Mask R-CNN的馆藏报纸图像内容分割[J]. 图书馆论坛,2024,44(6):110-118.
[8]SUOMINEN O. Extracting metadata from grey literature using large language models [EB/OL]. [2026-01-10].https://www.doria.fi/handle/10024/188075 .
[9]张毅,陈丹. 基于Omeka与IIIF的特藏资源库建设研究与实践:以华东师范大学近代教科书数据库为例[J]. 大学图书馆学报,2021,39(3):52-58.
[10]HLAVA M M K,RUSSELL J C,HANSEN D. Inverting the library cataloguing process to streamline technical services and significantly increase discoverability and search for special collections [EB/OL]. [2026-01-10]. https://library.ifla.org/id/eprint/2219.
[11]DAMJANOVIC V,KURZ T,WESTENTHALER R,et al. Semantic enhancement: the key to massive and heterogeneous data pools[C]// Proceedings of the 20th International Conference on Information Technology Interfaces(ITI 2011). Piscataway, NJ:IEEE,2011:413-416.
[12]HOSSEINI K,WILSON D C S,BEELEN K,et al. MapReader: a computer vision pipeline for the semantic exploration of
maps at scale[C]// Proceedings of the 6th ACM SIGSPATIAL International Workshop on Geospatial Humanities. New York: ACM,2022:8-19.
[13]仇开域,夏翠娟. 碑帖知识库构建:从智慧化加工到智慧化服务[J]. 图书馆论坛,2024,44(6):99-109.
[14]DCMI Annual Conferences [EB/OL]. [2026-01-10]. https:// www.dublincore.org/conferences.
[15]AI4LAM Fantastic Futures[EB/OL]. [2026-01-10]. https://ai4lam.org/fantastic-futures/.
[16]Digital Library Federation Past Forum[EB/OL].[2026-01-10]. https://www.diglib.org/dlf-events/past/.
[17]Code4Lib conference[EB/OL]. [2026-01-10]. https://code4lib. org/conference.
[18]CHOW E H C,KAO T J,LI X. An experiment with the use of ChatGPT for LCSH subject assignment on electronic theses and dissertations[J]. Cataloging & Classification Quarterly,2024,62(5):574-588.
[19]Oklahoma State University. Teaching student workers to use Generative AI to create metadata[EB/OL]. [2026-01-10]. https://www.xcdsystem.com/tla/program/pAJExb8/index.cfm?pgid=806&sid=38182&abid=113425 .
[20]San Diego State University. Enhancing cataloging of electronic government documents with programming and OpenAI[EB/OL]. [2026-01-10].https://osf.io/39bws.
[21]Rutgers University Libraries. Using AI with manuscript collections for librarians and scholars [EB/OL]. [2026-01-10]. https://osf.io/dt3hs.
[22]Northeastern University Library. A brief overview of machine learning practices for digital collections[EB/OL]. [2024-12-04]. https://librarynews.northeastern.edu/?p=275774 .
[23]Carnegie Mellon University Libraries. CAMPI: ComputerAided metadata generation for photo archives initiative [EB/OL].[2026-01-10]. https://kilthub.cmu.edu/articles/preprint/CAMPI_Computer-Aided_Metadata_Generation_for_Photo_archives_Initiative/12791807?file=25011017.
[24]Indiana University Libraries. Audiovisual Metadata Platform(AMP)planning project: progress report and next steps[EB/OL]. [2026-01-10]. https://hdl.handle.net/2022/21982 .
[25]ANDERSON C B,DURAN J. Responsible AI at the Vanderbilt Television News Archive: a case study[J]. Journal of eScience Librarianship,2024,13(1):e805 .
[26]MCIRVIN C,MILLER C,SMITH-GLAVIANA D,et al. Automatic expansion of metadata standards for historic costume collections[J]. Journal of eScience Librarianship,2024,13(1):e845 .
[27]华人剪报资料库[EB/OL]. [2026-01-10]. https://digital.lib.hkbu. edu.hk/newsclipping.
[28]University of Texas at Austin Library. Scaling a collections as data workflow with machine learning: automating processing of a large collection of scanned maps[EB/OL]. [2026-01-10]. https://osf.io/v56k3 .
[29]University of Central Florida. Teach with AI[EB/OL]. [2026 -01-10]. https://stars.library.ucf.edu/cgi/viewcontent.cgi?article=1232&context=teachwithai.
[30]Northwestern Libraries. Grant supports Northwestern Libraries launch of generative AI-based chat search[EB/OL]. [2026-01-10]. https://www.library.northwestern.edu/about/news/library news/2024/grant-supports-northwestern-libraries-launch-of
generative-ai-based-chat-search.html.
[31]UCLA Library. Leveraging AI tools for automating metadata extraction[EB/OL]. [2026-01-10]. https://osf.io/hdfgr.
[32] ELINGS M,FRIEDMAN M,SINGH V. Using AI/Machine Learning to extract data from Japanese American confinement records[J].Journal of eScience Librarianship,2024,13(1):e850 .
[33]Stanford Libraries. AI Projects[EB/OL]. [2026-01-10]. https://sul-dlss-labs.github.io/ai-projects/.
[34]孙翌,刘音. 基于知识图谱和大语言模型的口述历史资源的问答应用研究[J]. 图书馆杂志,2025,44(1):98-107,119.
[35]MASON J,JEMISON K. Streamlining Metadata Creation: Implementing and Assessing AI Workflows to Improve Discoverability[EB/OL].[2026 -01-10]. https://dcpapers . dublincore.org/article/952526168 .
[36]MORGAN M. AI and metadata:Bridging the gap between digital images and human understanding [EB/OL]. [2026-01-10]. https://dcpapers.dublincore.org/article/952471681.
[37]DOVER A,GRZEGORSKI J. Artificial Intelligence Through the Lens of the Cataloguing Code of Ethics[J]. Cataloging &Classification Quarterly,2025,63(6/7):600-620.
*本研究得到高校图书馆数字资源采购联盟(DRAA)研究项目“学术资源库创新发展”(编号:2025DRAA12)资助。
作者简介
陈若韵,女,硕士,副研究馆员,研究方向:信息描述与组织、阅读推广。
张谙宁,女,硕士,馆员,通信作者,研究方向:信息描述与组织,E-mail:zhanganning@szu.edu.cn。
张欢庆,女,硕士,助理馆员,研究方向:信息描述与组织。
周丹燕,女,硕士,助理馆员,研究方向:信息描述与组织。
张倩,女,硕士,馆员,研究方向:信息描述与组织。
周文琦,女,硕士,馆员,研究方向:信息描述与组织。
原文载于《数字图书馆论坛》2026年第2期,欢迎个人转发,公众号转载请联系编辑部
往期推荐
END
制版编辑:郑敏悦
审核:王玮

数字图书馆论坛官网丨https://dlf.istic.ac.cn
邮箱丨DLF@istic.ac.cn
电话丨010-58882324
欢迎投稿!
