 夜雨聆风
夜雨聆风这两天了解了一下国外比较流行的 Agent 工具 Pi(读 π),用下来之后有个明显的感受:对国内用户而言,它或许上手门槛不低、但却是能用到的效率极高的 Vibe Coding 工具。
目前,随着 vibe coding、harness engineering 这些概念逐渐走热,加上 openclaw、hermes 等工具带来的理念冲击,相信不少人已经开始真正用上 AI Agent 了。
一个很明显的变化是:过去大家习惯在在线 AI 平台上直接交互,完成一些简单任务;现在越来越多人开始用 Claude Code、Codex、opencode、openclaw、hermes、Trae 这类工具去做更复杂的工作。
以上这些工具我基本都试过。个人用得最多的是 opencode 和 Trae。原因也很简单:opencode 是这类开源工具中最有名的,很多项目、技能都默认适配它;而 Trae 虽然相对普通,但胜在图形界面友好、国内可用,对刚入门的小白来说,是个不错的起点,用这个也方便我线下对初学者进行指导。

不过各种工具用多了之后会发现,Agent 和 Agent 之间的效果差异,其实很大。
个人观点,这种差异主要来自两个方面:
使用的模型
工具本身对任务的处理方式
大家都说 Claude Code 强,但它的强大很大程度上依赖 Claude 系列模型本身的能力,再加上其工程实现也很出色,两者共同支撑了它的表现。对国内普通用户来说,因为各种原因,基本很难用上Claude系列模型。也有人会说,可以用 CC-Switch 这类工具让 Claude Code 接入 DeepSeek。我认可的是 CC 对任务的处理方式,而不是模型本身。但问题在于,Claude Code 的处理方式其实是围绕 Claude 系列模型专门适配过的,换成其他模型,效果未必好。
有博主研究发现,在Claude Code中调用Deepseek,明显消耗更多tokens,不是因为Deepseek太蠢,而是CC的一些设置会让它发更多上下文内容给Deeeseek处理,而用Claude的模型就不会。当然这个问题有待进一步验证。
其实,Claude Code、opencode 这类工具的核心逻辑并不复杂:把用户指令 + 自己的提示词一起发给 LLM,让模型通过指令调用本地电脑资源。其中最核心的四个工具是:读、写、编辑、执行 bash。有了这四个工具,就能衍生出一系列操作。
Claude Code 为了做到强大的功能,每次发给 LLM 的提示词 tokens 量非常大。但我们知道,提示词里掺入太多额外内容,反而可能会影响原始指令的执行效果——尤其是对于能力一般的模型,过长的提示词更容易造成注意力分散或指令覆盖。所以这里其实要把握好一个平衡。传统和在线AI平台交互,自己手动去执行命令的方式太麻烦,而使用Agent又可能面临着注意力分散。
但是,说到底,大道至简。对于一个 Agent 工具来说,真正需要的其实就是 读、写、编辑、执行 bash。工具介绍内容越少、越干净,对模型最终效果的影响就越小。
比如说,待会我说的案例,全程就用了这四个工具。
Agent读文件

Agent编辑文件
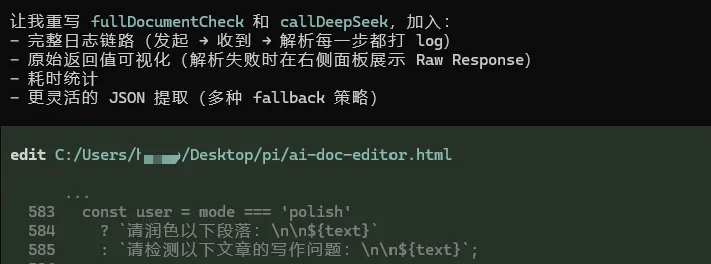
Agent执行Bash命令

最终也能高效地把任务完成,所以国内用户真想用 AI Agents 做 Vibe Coding,不一定追求Claude Code ,它未必是最适合的。当然,如果你有便捷的使用途径,那就当我没说。
总体上,如果把Harness Engineering比作AI的“道”,那么“读、写、编辑、执行 bash”则是“一”。
我们不妨回归 Agent 工具最核心的那个“一”——也就是读、写、编辑、执行 bash。工具越克制,对模型本身的干扰就越小,特别是国内普通人难以接触到Claude系列最顶级模型的情况下,对模型干扰越少可能效率越高。
而 Pi,正是这样一个回归本质的设计。用它来测试之前那篇 AI 润色工具的文章任务,只花了几毛钱,缓存命中率很高,而且几乎没有反复调试,基本一次性完成。


npm install -g --ignore-scripts @earendil-works/pi-coding-agent随后在项目文件夹打开powershell,输入指令:
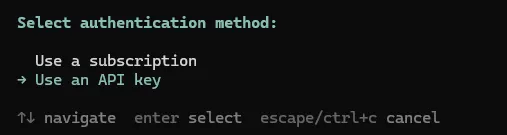
pi登录Pi后,输入/login,选择API key配置Deepseek模型就可以正式使用了。
顺说一句,openclaw是基于pi的内核开发的,在这基础上加了许多功能,导致每次对话都消耗大量tokens,这也是之前openclaw受到诟病的原因之一。
