 夜雨聆风
夜雨聆风华为正在重新定义“芯片新范式”,在超节点上收获未来,迎来新一轮算力架构重构的机会窗口。
华为Fellow,半导体首席科学家廖恒,在鲲鹏昇腾开发者大会2026(KADC2026)上给出了一个公式:系统业务性能=超节点规格x单颗芯片规格。在这种范式里,单芯片不再是决定算力的唯一因素。
在智能体式AI时代,竞争已经越来越从追求单芯片的绝对算力,转向适合不同场景与业务需求的比较优势。在推理解码/后训练阶段,内存带宽>内存容量>算力。
所以廖恒说,在Agentic AI时代,就要在系统层面重构计算机,把更多NPU、CPU、内存、网络和软件栈,通过灵衢互联组织成一个更大的逻辑机器。这就是昇腾超节点与鲲鹏超节点的底层逻辑。
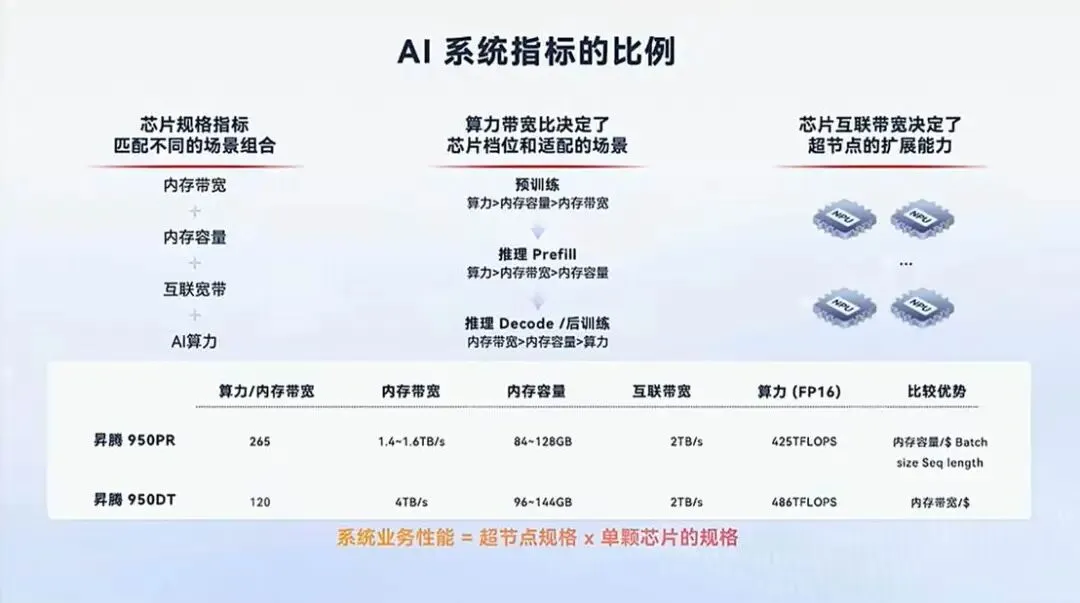
(来源:廖恒在KADC2026演讲PPT )
芯片的先进性仍然是基石。昇腾950PR与950DT的突破,首先体现在低精度格式。自主创新HiF8,实现显存减半,算力翻倍。950系列兼容多元,支持FP8、MXFP8、HiF8、MXFP4等低精度格式,单芯片FP8算力达到1PFLOPS、FP4算力达到2PFLOPS,互联带宽提升至2TB/s。
微架构的设计,原生实现 了SIMD 与SIMT 双编程模式一体化融合,让昇腾芯片从专用化进一步走向GPU式灵活性 + NPU式高能效。这一设计给开发者带来更友好的开发体验, 以Transformer经典算子Softmax为例,开发所需的代码量减少了70%。配合SIMD+SIMT融合后的更细粒度执行模式,昇腾950将内存访问粒度从512B缩小到128B,提升MoE路由、KV cache、嵌入、解码等不连续访问场景下的有效内存带宽。
950PR与950DT的分工,也显示出昇腾对AI负载比较优势的把握。950PR更偏推理预填充、推荐业务和容量性价比,强调内存容量、批次大小和序列长度;950DT则更偏解码、训练和带宽敏感负载,其内存容量144GB、带宽4TB/s,高于950PR的128GB和1.6TB/s。
这些是面向智能体时代的架构调整,业务需求将会制造更多长上下文、多轮调用、工具返回和持续记忆,解码与缓存管理的重要性上升。昇腾超节点的最佳实践,也正围绕这些瓶颈展开,以单柜64卡为基本单元,最大支持8192张NPU卡高速互联,面向超大规模训练和海量推理并发;相比传统集群,大模型训练效率、可靠性和推理性能均有提升。廖恒还展示了正在实际部署的 1.6 万卡柜内(Scale-Up)加柜外(Scale-Out)混合系统,
如果说昇腾解决的问题是智能从哪里算出来,鲲鹏要提供智能体在哪里运行的答案。智能体群长时复杂的工作中,GPU/NPU负责模型计算,CPU发挥着控制中心、环境执行器和系统调度器的关键作用,大量任务如控制流、工具执行、容器沙箱、RPC通信、状态回滚和内存管理,天然属于通用计算。
在KADC2026上,华为公司Fellow、ICT操作系统副首席科学家胡欣蔚提出,CPU正在回到舞台中央,智能体的爆发,正将CPU从过去的“辅助角色”推至“核心调度器”的位置。
鲲鹏超节点的价值,正是把传统CPU服务器从松散集群升级为低时延、大带宽、统一内存的逻辑通用计算机。它支持百纳秒级低时延、TB级带宽和内存池化,通过内存语义通信实现跨节点数据以读写方式高效传输,解决了通用计算场景中高时延、数据搬移开销大、协同效率低的问题。
例如,鲲鹏超节点依托多级缓存共享、增量快照共享和远程分叉(remote-fork)能力,可实现十毫秒级回滚,并支撑智能体任务成功率提升10%以上。
鲲鹏之上,构建了三层智能体系:底层是鲲鹏超节点与灵衢互联,提供24TB统一内存池;中间层是openEuler异构融合操作系统,打通CPU与AI加速器;上层Agent Infra提供轻量沙箱、记忆服务和全链路安全能力。
鲲鹏与昇腾之间,形成了一种新的异构融合关系。灵衢互联协议是超节点的共同底座,它统一了内存语义、IO语义和网络通信语义,让CPU、NPU、内存、SSD、DPU、网络设备不再只是通过传统以太网松散协作,而是在超节点内部以更接近大型计算机的方式运行。CPU与GPU协同作战,体现出胡欣蔚所说的追求“智能体扩展”(Agentic Scaling)。
真正让昇腾从硬件产品变成生态底座的,是CANN软件。2025年8月以来,CANN加快全面开源开放,兼容主流开源生态,让开发者尽量保持原有习惯。CANN通过分层解耦,将算子库、加速库、图计算、编程语言等软件代码开源,支持PyTorch、vLLM、SGLang、xLLM、VeRL、Triton、TileLang等社区和项目。
在 PyTorch 生态适配方面,昇腾通过 torch_npu 等组件对齐 PyTorch 开源社区的 2300 多个常用 API,降低开发者代码迁移成本;在分布式训练方面,已适配 PyTorch FSDP2,即全分片数据并行第二代,使 20 多个主流大模型能够在昇腾平台上以较少改动实现开箱即用;同时,昇腾还与多个强化学习开源社区合作,持续合入训练加速和适配代码。
这一步非常关键。CANN要追赶的是一整套生产体系,模型要快速迁移、算子要快速补齐、推理框架要直接适配、强化学习社区能跑起来。CANN是在开源AI生态的主流工作方式之上,建立起昇腾生态的开发者入口。
openEuler是面向超节点的操作系统。它向下连接CPU、NPU、内存、存储和网络资源,向上支撑容器、沙箱、数据库、推理服务和智能体运行时。在鲲鹏三层智能体系中,openEuler处于中间层,用来打通CPU与AI加速器之间的协同,构筑“通智网存”融合的智能体运行底座。
智能体要规模落地,必须跨过三道坎:token及内存资源消耗高、沙箱环境启动慢、存在越权与数据泄露风险。 鲲鹏通过软硬件协同,为这三大挑战提供了解决方案。基于CCA架构的机密智能体,实现Agent可信授权、安全隔离、记忆加密存储和秒级恢复;基于鲲鹏超节点打造的AI数据底座极具性价比,实现Agent业务Token开销降低50%;基于超节点和多级存储技术,实现了沙箱百毫秒启动,秒级千并发。

(来源:胡欣蔚在KADC2026演讲PPT)
鲲鹏和昇腾生态所带来的好用与易用,正体现为推动上下游协同适配,为产业落地提供支撑,并且成为开发者的入口。鲲鹏已发展7000多家合作伙伴、415万开发者,openEuler系操作系统累计装机量超过1600万套;昇腾已发展3000多家合作伙伴、超410万开发者。
当初中国科技企业不抱任何幻想,坚决开辟系统级创新的战场。从遭遇的技术断点出发,华为的鲲鹏超节点和昇腾超节点,共同支撑了这个转折点:昇腾让模型算得起来,鲲鹏让智能体跑得起来,灵衢让异构资源连成一台更大的机器,扩展智能的边界。
自主生态站立起来,在自主的道路上演进。硬件可用性、软件成熟度、开发者习惯、全球开源影响力、云端运维经验,都是持续完善的结果。在软件的层面,也如廖恒所说,在兼容和无所不包的同时,在做厚的同时,也要做薄。
未来半导体竞争的核心,或许不再是制程精度的极限,而是谁能以最低的时间成本,组织最大规模的计算资源。在这一工艺路径上,华为已经提前起步了。
华为提出“时间(τ)缩微”,替代传统的“几何缩微”,作为半导体与电子系统演进的新主线,更是迈向了中国新范式。
