 夜雨聆风
夜雨聆风工程师的第二曲线
读完需要
速读仅需 3 分钟
/做了一个线上故障排查 AI 工具,才真正想清楚 Agent 的边界在哪里/
这篇文章想复盘一个我以前做过的线上故障排查 AI 工具。
这个工具来自一个很高频的后端研发场景:线上接口报错后,工程师需要根据 trace_id、错误码或者异常栈,快速找到问题发生在哪里、可能原因是什么、代码应该怎么改。
在做这个工具的时候,我给每个功能模块都起了一个 *_agent.py 的名字。
但最近重新整理这版代码时,我意识到一件事:这些模块里,没有一个符合今天 Agent 工程的定义。它们是工具、是 workflow step,但不是 Agent。
这不只是一个命名问题。它让我重新想清楚了一个更根本的工程问题:tool、workflow 和 Agent,在工程上到底怎么区分?
这篇文章先不急着给定义,而是按真实顺序讲:这个工具是为了解决什么问题、当时怎么实现、它做对了什么,最后再回头用 V1 的真实案例,把这三个概念的工程边界说清楚。
1
线上故障排查到底麻烦在哪
后端工程师都知道,线上故障排查很多时候不是“不知道理论”,而是信息太散。
一个问题来了,入口可能很简单:
一个 trace_id一个接口路径和错误码 一段异常栈 一条用户反馈 一个报警信息
但真正开始排查后,工程师要在很多地方来回切换。
比如,拿到一个 trace_id 后,通常要去日志平台查请求日志。日志里会有大量字段:请求参数、响应结果、错误码、异常信息、调用链、服务名、时间戳。工程师需要从这些字段里挑出真正有用的信息。
如果拿到的是异常栈,也不是简单看第一行就能结束。真实项目里的异常栈经常混着业务代码、Spring AOP、事务拦截、RPC 框架、线程池和各种基础设施调用。你需要判断哪个栈帧才是业务代码,哪个方法、哪一行最可能是问题现场。
找到可疑代码后,还要回到本地代码库,根据类名、文件名和行号定位源码,查看异常行附近的上下文。很多问题不能只看一行代码,还要看前后变量怎么来、参数是否可能为空、状态流转是否完整。
这些工作有两个特点:
很重复。 很依赖上下文。
所以我当时想做的不是“让 AI 替代工程师”,而是先让 AI 帮工程师完成第一轮排查,把最机械、最耗时的步骤串起来。
我希望这个工具至少能做这些事:
1拿到 trace_id / 错误码 / 异常栈2-> 自动查询日志3-> 提取关键异常和请求上下文4-> 分析异常栈5-> 定位源码文件和行号6-> 汇总证据7-> 给出初步根因和修复建议这就是 V1 的起点。
2
V1 做成了什么样
当时团队只给员工开通了 Claude Code 订阅,并没有提供可供程序调用的 LLM API。基于这个约束,V1 的分工很直接:日志查询、异常栈解析、代码定位由 Python 程序完成;根因分析和修复建议交给 Claude Code。
虽然工程师只能在终端里与 Claude Code 手动交互,但 V1 没有做成一个只能在终端里运行的脚本。
原因很简单:线上故障排查本身就是一个需要反复查看信息的过程。如果只在命令行里输出一大段文本,使用起来并不方便。工程师需要一个页面来输入 trace_id、错误码或者异常栈,也需要一个页面把日志、异常分析、代码定位、根因分析和修复建议分块展示出来。
所以 V1 做了一个可视化页面。技术上用的是 Streamlit,它适合快速搭建内部工具页面。
用户打开页面后,可以选择诊断方式:
trace_id诊断接口路径 + 错误码诊断 异常栈诊断
输入信息后,系统会按照固定流程执行诊断,并把每一步结果展示出来。
整体流程大致是:
1输入 trace_id / 错误码 / 异常栈2-> 查询日志3-> 提取异常、请求参数、服务调用信息4-> 分析异常栈5-> 定位源码文件和行号6-> 调用 Claude Code 做根因分析7-> 调用 Claude Code 生成修复建议8-> 在 Web UI 展示结果并生成报告换成流程图,大概是这样:
1flowchart TD2 A["用户输入:trace_id / 错误码 / 异常栈"] --> B["可视化诊断页面"]3 B --> C["固定诊断流程"]4 C --> D["日志查询"]5 D --> E["异常栈分析"]6 E --> F["代码定位"]7 F --> G["Claude Code 根因分析"]8 G --> H["Claude Code 修复建议"]9 H --> I["结果展示 / JSON 报告"]这个 Web UI 的价值是,它让工具从“我本地跑一个脚本”变成了“工程师可以打开页面使用的内部工具”。
页面里可以看到日志查询结果、异常分析、代码定位、根因分析、解决方案和详细信息,也可以下载诊断报告。
下面是 V1 当时的几个页面示例,截图已经做过脱敏处理。
异常栈诊断入口:
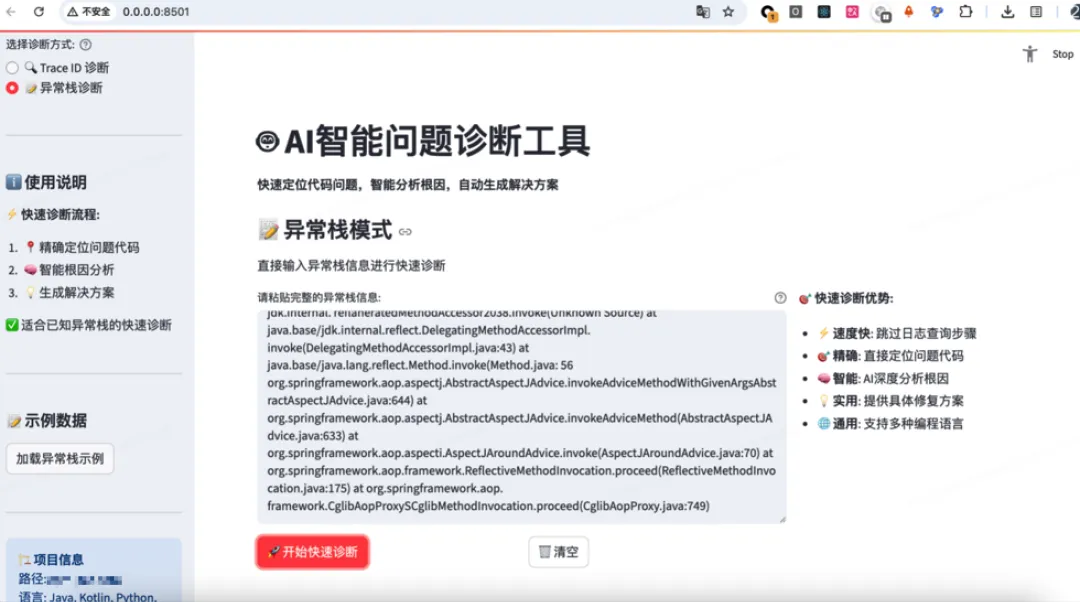
代码定位结果:
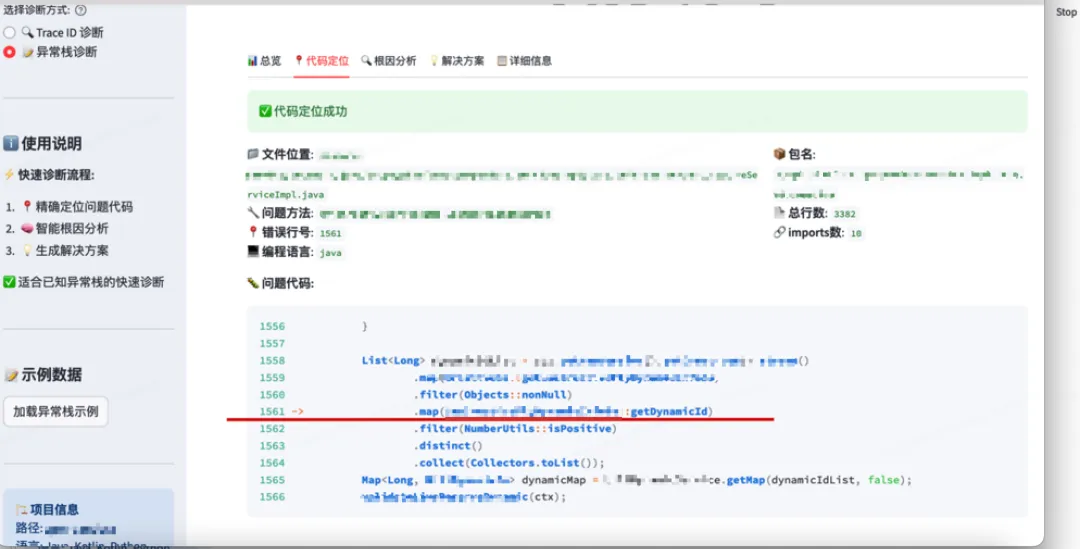
修复建议结果:
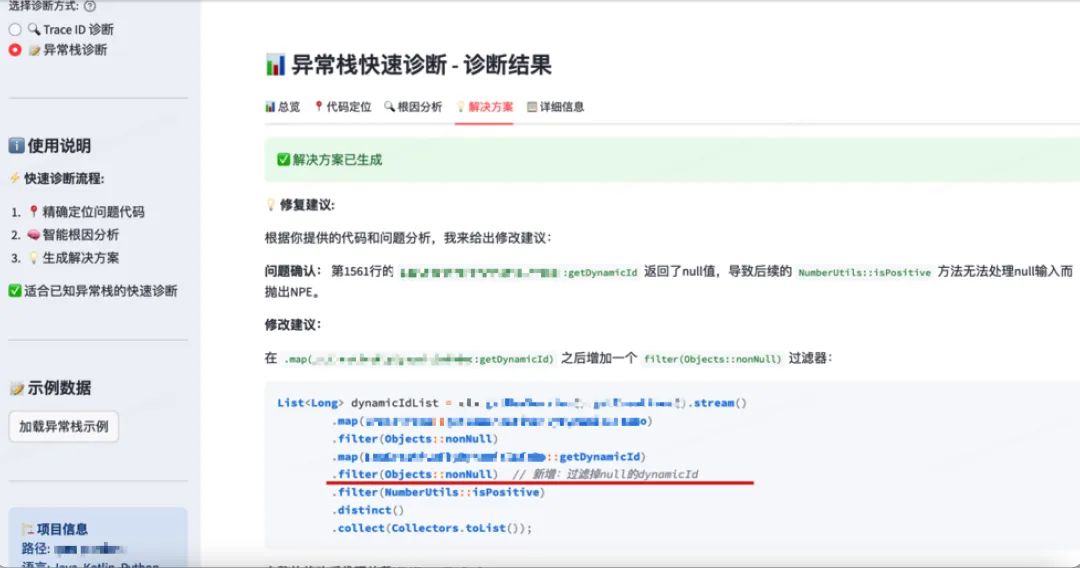
3
V1 的代码结构
V1 的代码结构大致是这样:
1v1-ai-assisted-workflow/2├── src/3│ ├── app.py # Streamlit UI + workflow 编排4│ └── agents/5│ ├── trace_log_query_agent.py6│ ├── stack_trace_analyze_agent.py7│ ├── code_locator_agent.py8│ ├── root_cause_analysis_agent.py9│ └── solution_suggest_agent.py10├── config.example.json11├── requirements.txt12└── start_app.sh这里先不急着讨论这些文件名里的 agent 是否准确,先看每个模块做了什么。
3.1
日志查询
trace_log_query_agent.py 负责根据 trace_id 或错误码查询日志。
它做的是确定性检索,不是模型推理:
拼接日志查询条件。 请求日志平台。 提取异常信息。 提取请求参数。 提取服务调用信息。 从错误码日志里反查 trace_id。
3.2
异常栈分析
stack_trace_analyze_agent.py 负责分析异常栈。
它会根据包名、类名、方法名和栈帧位置,判断哪些栈帧更像业务代码,哪些更像框架调用。
它的目标不是解释所有栈帧,而是尽快找到最可能有价值的业务栈帧,比如某个 service 方法和具体行号。
3.3
代码定位
code_locator_agent.py 负责根据异常栈定位源码。
它会根据类名、文件名、行号和本地项目路径,找到对应源码文件,并提取问题行附近的代码上下文。
今天看,Claude Code 本身已经有很强的代码库理解能力,所以这个模块确实有一部分重复造轮子的成分。
但它也有工程价值。
它做的是 code grounding:先用确定性程序把异常栈定位到具体文件、行号和代码片段,再把压缩后的上下文交给 Claude Code。
这比把一堆日志和代码全部丢给模型更可控。
3.4
根因分析和修复建议
真正调用 Claude Code 的地方主要是两个模块:
root_cause_analysis_agent.pysolution_suggest_agent.py
根因分析模块会把日志、异常栈和源码上下文组织成提示词,让 Claude Code 分析可能原因。
修复建议模块会把问题文件、问题行、根因描述和代码片段交给 Claude Code,让它生成修改建议。
当时的提示词很朴素,但方向是对的:
不是空问模型,而是把日志、异常栈和源码作为证据交给模型。
4
V1 做对了什么
V1 现在看很粗糙,但它有几个方向是对的。
第一,它解决的是一个真实工程问题。
线上故障排查不是聊天 demo,它涉及日志、异常栈、源码、请求参数、服务调用链和报告输出。V1 至少证明了这条流程可以被自动化一部分。
第二,它没有空问模型。
在调用 Claude Code 前,系统会先收集日志、异常栈和源码上下文。给模型的不是一句"帮我看看哪里出错了",而是日志、栈、代码都备齐的上下文。
第三,它把确定性任务和 LLM 任务做了初步分工。
日志查询、异常栈解析、代码定位主要由 Python 程序完成;根因分析和修复建议交给 Claude Code。
这给后续版本留下了一个很重要的设计原则:
工具负责收集和约束上下文,模型负责理解和生成。
5
tool、workflow 和 Agent,工程上怎么区分
讲完背景和实现,再回头看当时的命名问题就比较自然了。
V1 里很多文件都叫 *_agent.py。要判断这个命名是否准确,先要说清楚这三个概念在工程上的区别。
Tool(工具)
确定性执行,输入输出固定,没有自主决策。给定相同的输入,每次返回相同类型的结果。日志查询、代码检索、异常栈解析,都是这类。
Workflow Step(工作流步骤)
由编排层按固定顺序调用的执行单元。可以包含 LLM 调用,但执行路径是开发时写死的,不会根据中间结果自主调整下一步做什么。
Agent
有自主决策能力。能根据当前上下文选择调用哪个工具、决定下一步做什么、判断什么时候可以停止。执行路径是运行时动态决定的,不是提前写死的。
判断一个模块是不是 Agent,可以问三个问题:
它的执行路径是开发时写死的,还是运行时自主决定的? 它能根据中间结果调整下一步做什么吗? 它知道什么时候该停止吗?
用这三个问题重新审视 V1 的每个模块:
trace_log_query_agent.py | ||
stack_trace_analyze_agent.py | ||
code_locator_agent.py | ||
root_cause_analysis_agent.py | ||
solution_suggest_agent.py | ||
app.py |
V1 里没有一个模块能对这三个问题给出肯定答案。所以它是一个 AI-assisted workflow,而不是 Agent Harness。
这不是说 V1 做错了。对一个验证阶段的工具来说,固定 workflow 是务实的选择。但它暴露出几个工程化不足的地方,值得逐一复盘。
5.1
Workflow 是写死的
trace_id 怎么诊断、错误码怎么诊断、异常栈怎么诊断,都是代码里固定好的函数调用。
这适合快速验证,但还不是一个可配置、可追踪、可评测的 Agent Harness。
5.2
工具没有统一 schema 和边界
V1 中每个模块都有自己的输入输出格式,主要靠 Python dict 串联。
它没有统一的 tool schema,也没有工具注册中心、工具白名单和权限边界。
在线上故障排查场景里,这个问题很关键。因为工具可能访问日志、数据库、配置、监控系统和代码库。工具越强,越需要边界。
5.3
LLM 调用缺少治理
V1 是通过 subprocess 调用 Claude Code CLI。
这在当时是可行方案,但工程化能力不足:
没有统一 LLM client。 没有 timeout。 没有 retry。 没有 fallback。 没有 token、cost、latency 记录。 没有结构化输出约束。 没有 prompt 版本记录。
系统能跑,不代表它已经可治理。
5.4
Prompt 还比较朴素
V1 的提示词只是把日志、异常栈和代码片段交给 Claude Code,让它总结根因和修改建议。
它没有进一步要求模型:
区分事实、推测和置信度。 引用日志、异常栈和源码证据。 在证据不足时不要强行下结论。 把修复建议拆成临时止血、长期修复和验证步骤。 输出固定结构,方便后续解析和评估。
5.5
Trace 和 eval 不是一等公民
V1 可以生成最终诊断报告,但这不等于 Agent trace。
更成熟的系统应该记录:
每一步什么时候开始、什么时候结束。 每一步输入了什么、输出了什么。 调用了哪些工具。 调用了哪次 LLM。 使用了哪个 prompt 版本。 失败在哪里,是否重试,是否 fallback。 最终结果是否命中预期。
没有 trace,就很难复盘。没有 eval,就很难判断一次修改到底让系统变好了还是变差了。
Agent 系统里,不是什么都应该交给模型。
尤其是线上故障排查这种生产场景。
日志查询、异常栈解析、代码定位、上下文裁剪、权限控制、执行记录,这些事情更适合由工具和 harness 控制。
LLM 更适合做基于证据的理解、归纳、解释和建议生成。
如果让模型完全自由发挥,它可能看起来很智能,但系统很难稳定、可控、可审计。
所以我现在更倾向于把这类系统设计成 workflow-first:
1问题分类2-> 上下文解析3-> workflow 路由4-> 受控工具调用5-> LLM 基于证据分析6-> trace 记录7-> eval 回归这不是为了限制模型,而是为了让模型在正确的边界内发挥作用。
6
V1 如何引出后续优化
V1 的价值是跑通了真实场景的最小闭环。
但它暴露出来的问题,也自然引出了后续优化方向。
V2 的重点是尝试框架化。
当工具越来越多、场景越来越多时,硬编码 workflow 很难继续扩展。所以 V2 尝试使用开源 Agent 框架,把日志查询、代码分析、数据库诊断等能力做成更明确的 tools,并构建一个更像 workbench 的使用体验。
V3 的重点则是回到 lightweight harness。
因为生产故障排查不是完全自由聊天场景,它更需要:
问题分类。 上下文预解析。 workflow 路由。 step 级工具白名单。 prompt builder。 trace 持久化。 eval 回归。
这三版并不是“一开始就做对了”,而是从真实问题出发,不断修正 Agent 工程认知。
7
结尾
这个项目已整理成脱敏公开仓库,感兴趣可以看:https://github.com/second-curve-engineer/sre-troubleshooting-agent-evolution
我刻意没有把 V1 包装成成熟 Agent。对一个工程项目来说,说清楚它不是什么,和说清楚它是什么一样重要。
V1 不是成熟 Agent,但它是一个真实问题驱动的 AI 工程原型。
它让我更清楚地区分了几件事:
tool 不等于 Agent。 workflow step 不等于 Agent。 LLM 调用不等于 Agent。 能跑通不等于可观测、可评测、可治理。
对线上故障排查这类场景来说,Agent 工程化的关键不是让模型自由发挥,而是让模型在可控 workflow、明确工具边界和可追踪证据链里发挥作用。
这也是我后续继续打磨这个项目的方向。
