 夜雨聆风
夜雨聆风告别碎片化工具!这个开源 Skill 把 AI 变成你的内容生产流水线
作为内容创作者,你是不是每天都在被一套碎片化流程反复折磨:
先用 AI 写完初稿 → 切到设计工具做封面 → 再画架构图、补示意图 → 把复杂概念做成示意图 → 最后进行内容排版发布。
工具来回切换、步骤零散琐碎,明明 AI 已经能搞定大部分创作,却被低效的人工衔接拖垮整体效率。
最近我挖到一个专为内容创作者打造的效率神器—— 开源项目 baoyu-skills
(https://github.com/JimLiu/baoyu-skills)。
它不只是 Claude、Codex 能用的一组 Prompt 模板,而是把内容生产里所有零散环节打包成可复用、可配置、可一键交付的完整工作流。
它让 AI Agent 彻底告别 “陪聊助手” 的定位,直接升级成能按流程自动干活的专属内容生产工作台。
今天这篇,就带你彻底搞懂 baoyu-skills 怎么用,如何用它把内容生产效率直接拉满。
这个项目是什么?
baoyu-skills 是一组 AI Agent 技能集,适用于 Claude Code、Codex 等支持 skill/plugin 机制的环境。项目 README 里把 skills 分成内容技能、AI 生成技能和日常效率工具技能,安装方式既支持 npx skills add jimliu/baoyu-skills,也支持通过插件市场安装。
它的特点有三个。
第一,它面向真实创作流程,而不是单点能力。比如不是只告诉模型“帮我画图”,而是定义了图表类型、输出目录、SVG 规范、PNG 转换脚本和结果报告。
第二,它强调可复现。很多图像类 skill 都要求先把完整 prompt 保存到 prompts/ 目录,再调用图像生成后端。这样下次要换模型、重跑、微调,至少知道上一版到底是怎么生成的。
第三,它默认带有“确认门”。封面、漫画、文章配图这类结果主观性很强的任务,skill 通常会先确认比例、风格、配色、语言和输出密度,而不是直接生成一堆不可控结果。
这个项目里面有很多个skill,通常不建议大家全部安装,挑几个对自己有用的安装就行。我目前只安装了其中四个:baoyu-diagram、baoyu-cover-image、baoyu-comic、baoyu-article-illustrator。这个工具在我平时的工作和创作中非常有帮助。
下面对这几个skill做一个简单的介绍。
1. baoyu-diagram:把复杂概念画成 SVG 图解
baoyu-diagram 适合做技术文章里的结构图、流程图、时序图、状态机、架构图、时间线和概念图。它的输出的是一个 .svg 文件。
这个设计很关键。技术图最怕两件事:文字糊、结构错。普通图像生成模型容易把箭头、标签、组件名画乱,而 baoyu-diagram 的思路是让 Agent 直接写 SVG。它会按照统一的深色设计系统,手算布局、连线、边距和图层顺序。
常见触发方式很自然:
帮我画一个 OAuth 2.0 授权码流程图或者更明确一点:
/baoyu-diagram "OAuth 2.0 授权码流程" --type sequence --lang zh如果输入是一篇文章,也可以让它从文章里提取最适合图解的部分:
/baoyu-diagram articles/oauth.md --type auto它支持的核心类型包括:
architecture:系统架构、服务关系、云资源分层。flowchart:流程、判断、工作流。sequence:谁调用谁、请求和响应顺序。structural:类图、ER 图、组织结构。timeline:时间线和演进过程。state machine:状态和转换。illustrative:解释一个机制“到底怎么工作”。实际使用案例:
假设我写了一篇《从零理解 RAG 应用架构》,正文讲到了用户查询、向量检索、重排序、上下文拼接、模型生成和结果引用。我可以这样用:
/baoyu-diagram "RAG 应用从用户问题到带引用回答的完整链路" --type architecture --lang zh --out diagrams/rag-pipeline.svg预期产物是一张深色 SVG 架构图,下图是实际生成的效果:
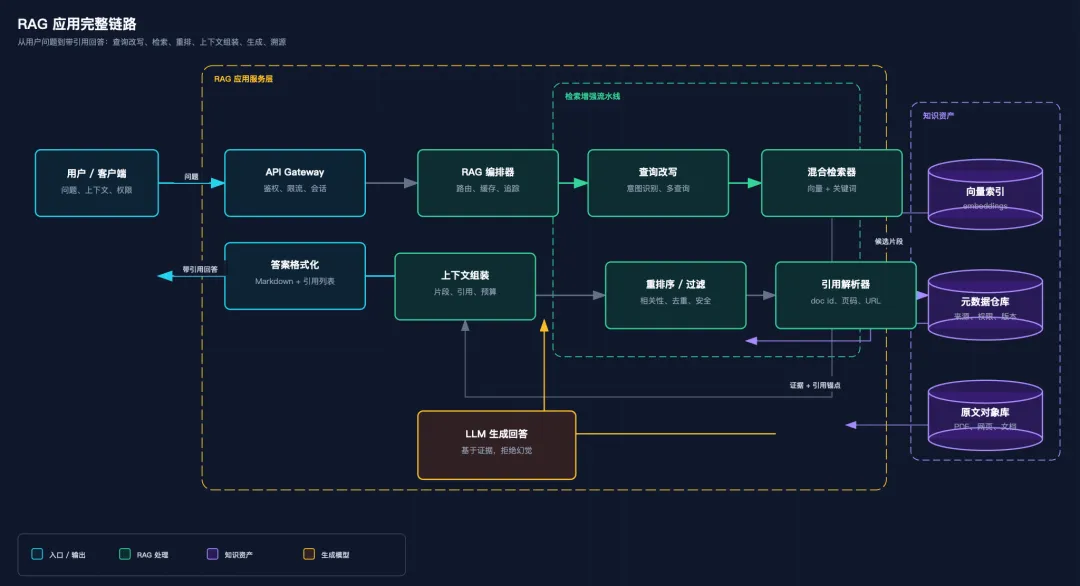
2. baoyu-cover-image:给文章生成封面
baoyu-cover-image 是文章封面图生成器。它不是简单说“生成一张封面”,而是把封面拆成五个维度:
hero、conceptual、typography、metaphor、scene、minimal。warm、elegant、cool、dark、earth、vivid、pastel、mono、retro、duotone、macaron。flat-vector、hand-drawn、painterly、digital、pixel、chalk、screen-print。none、title-only、title-subtitle、text-rich。subtle、balanced、bold。它默认会先确认选项,然后把完整 prompt 保存到 prompts/,再调用图像后端。这个步骤看似麻烦,但对封面很重要,因为封面经常需要重试、换标题、换比例、保留某个构图方向。
常见用法:
/baoyu-cover-image articles/rag.md --aspect 16:9如果你已经知道想要的风格,可以直接指定:
/baoyu-cover-image "AI Agent 的内容生产流水线" --type conceptual --palette elegant --rendering digital --text title-only --aspect 2.35:1实际使用案例:
我准备发一篇文章,标题是《内容创作者的新工具箱:baoyu-skills 怎么用?》。我希望封面不要太技术文档化,而是有“工具箱”和“创作流程”的视觉隐喻,可以这样提需求:
/baoyu-cover-image "内容创作者的新工具箱:baoyu-skills 怎么用?" --type metaphor --palette elegant --rendering digital --text title-only --mood balanced --aspect 2.35:1实际生成效果:

3. baoyu-comic:把知识点改成知识漫画
baoyu-comic 是一个知识漫画生成器,适合把抽象概念、人物故事、教程、方法论改成漫画。它的强项不是随便画几张图,而是完整处理“分析内容、确定风格、写分镜、生成角色、保存 prompt、批量生成页面、合并 PDF”的流程。
它支持多种艺术风格:
ligne-claire:清晰线条,适合知识解释。manga:漫画风,适合人物和故事。realistic:更接近写实插画。ink-brush:水墨和武侠感。chalk:黑板粉笔风。minimalist:极简表达。也支持不同语气:
neutral:中性解释。warm:温暖、亲和。dramatic:戏剧化。energetic:节奏更快。vintage:复古感。action:动作感更强。常见用法:
/baoyu-comic articles/what-is-rag.md --art manga --tone warm --layout standard --lang zh如果只想先看分镜,不想立刻生成图片:
/baoyu-comic articles/what-is-rag.md --storyboard-only如果已经有分镜和 prompt,只想补图:
/baoyu-comic comic/rag-explained --images-only实际使用案例:
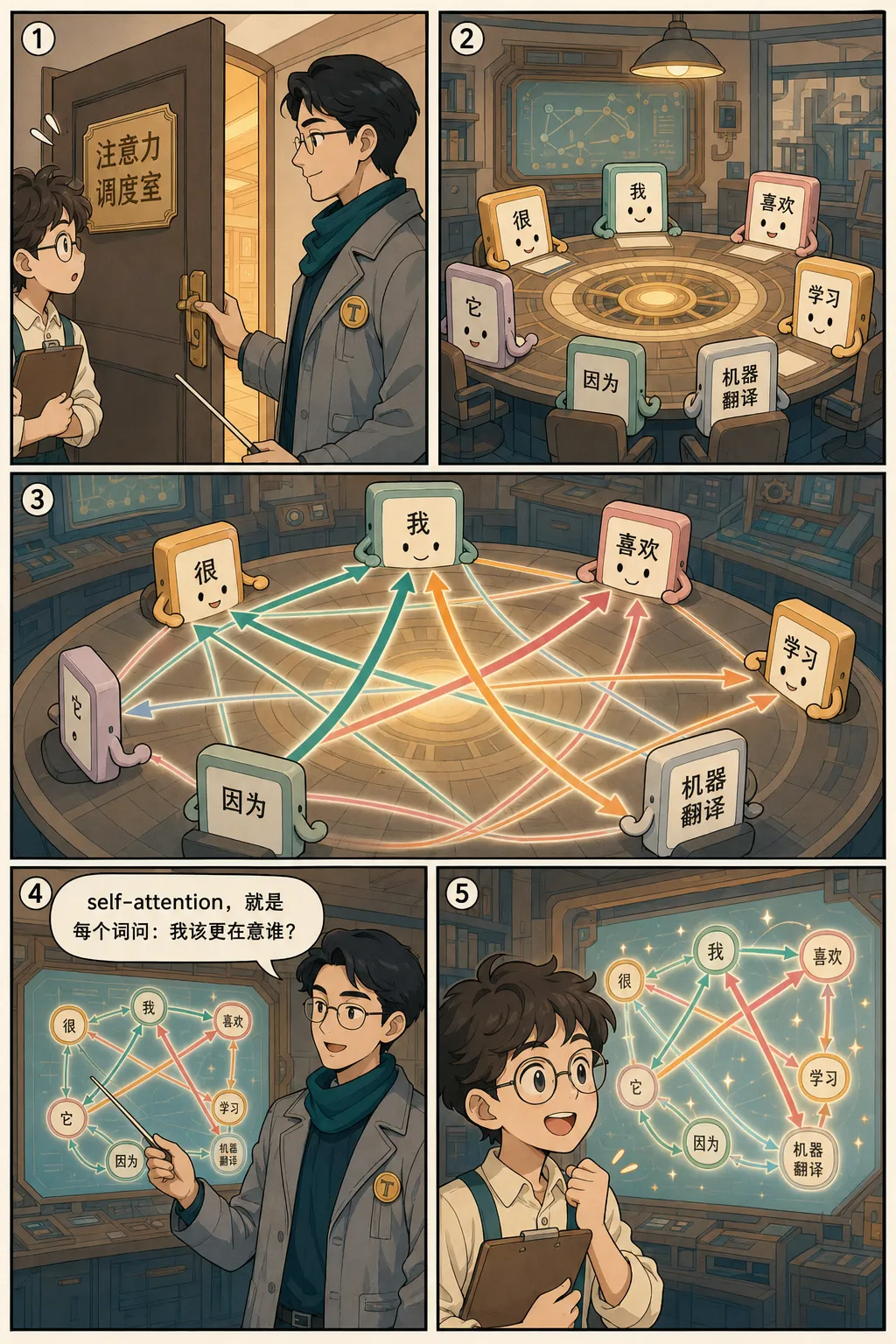
假设我要把《Transformer 为什么改变了 NLP?》做成一篇适合朋友圈传播的知识漫画。我不想让它变成论文摘要,而是希望通过“旧式翻译工厂”和“注意力调度室”的故事来解释 self-attention。
可以这样启动:
/baoyu-comic "用一个翻译工厂的故事解释 Transformer 和 self-attention" --art ligne-claire --tone warm --layout mixed --aspect 3:4 --lang zh它会先拆故事:传统 RNN 像一条传送带,信息要按顺序传;Transformer 像一个调度室,每个词可以同时查看其他词的重要性。最后生成多页竖版漫画,适合公众号正文或做成 PDF 附件。
实际生成效果:
 |  |
 |  |
 |
4. baoyu-article-illustrator:给文章自动配图
baoyu-article-illustrator 解决的是另一个痛点:文章写完了,但不知道哪里该加图、加什么图、风格怎么统一。
它会先分析文章结构,识别哪些位置需要视觉辅助,再根据 Type × Style × Palette 生成配图方案。这里的 Type 不是封面的类型,而是文章内部插图的信息结构:
infographic:适合数据、指标、技术点。scene:适合叙事和情绪。flowchart:适合流程。comparison:适合对比。framework:适合模型和架构。timeline:适合历史和演进。Style 可以是 notion、minimal、blueprint、watercolor、editorial 等;Palette 可以覆盖为 macaron、warm、neon 等。
常见用法:
/baoyu-article-illustrator articles/agent-workflow.md如果你想指定密度和风格:
/baoyu-article-illustrator articles/agent-workflow.md --type framework --style notion --palette macaron它的工作流通常包括:读取配置、分析文章、确认插图密度、生成 outline、为每张图保存 prompt、批量生成图片,最后把 Markdown 图片链接插回文章。
实际使用案例:
比如这篇文章本身就很适合配三张图:
可以这样调用:
/baoyu-article-illustrator articles/baoyu-skills-wechat.md --type mixed --style notion --palette macaron如果我只想要 3 到 5 张图,而不是每一节都配图,就在确认阶段选择 balanced 密度。这样文章不会变成图片堆砌,阅读节奏更稳。
多个 skill 怎么组合?
单独看,每个 skill 都是一个功能;组合起来,它们更像一条内容生产流水线。
第一步,先写文章草稿。这个阶段不一定需要 skill,重点是把观点写清楚。
第二步,用 baoyu-diagram 处理需要精确解释的概念。凡是流程、架构、时序、状态转换,优先用 SVG 图解,不要交给随机性强的图片模型。
第三步,用 baoyu-article-illustrator 判断正文哪里需要配图。它适合做文章内部的视觉辅助,补的是阅读理解,不是装饰。
第四步,如果文章里有一个特别适合传播的知识点,用 baoyu-comic 单独改成漫画版。漫画不一定放进原文,也可以作为二次传播素材。
第五步,用 baoyu-cover-image 做封面。封面是入口,不是正文插图,应该单独考虑标题、比例和视觉隐喻。
这套流程最大的价值,不是让 AI “一次性替你完成所有创作”,而是把内容生产中那些重复、繁琐、容易丢上下文的步骤标准化。
我的判断
baoyu-skills 适合三类人。
第一类是技术内容创作者。架构图、流程图、解释图、教程漫画,这些都是技术文章里真正能提升理解效率的东西。
第二类是已经在用 Claude Code 或 Codex 的人。因为这套 skills 的假设不是“你在一个网页聊天框里提问”,而是“你和 Agent 共享一个工作目录,Agent 可以读写文件、保存 prompt、调用脚本、生成交付物”。
它也有代价。第一次使用图像生成类 skill 时,通常需要配置 EXTEND.md、选择后端、确认风格。可以自行选择图像生成的api后端。我自己是开通了ChatGPT的Plus订阅,平时开发用的是Codex,自带的有Openai的生图工具,非常方便。如果你需要相关开通方法,可以在评论区留言,我会统一解答。
但如果你经常写文章、做解释图,这个代价是值得的。
baoyu-skills 这套工作流,还能继续适配公众号、小红书、知乎等多平台内容生产。后续我会分享更多好用的内容创作的工具,帮你真正把 AI 用成生产力外挂。
关注我,第一时间拿到实战教程,内容创作少走 90% 的弯路。
