 夜雨聆风
夜雨聆风引子:当AI走进地下三千米
想象一下,在地下三千米的岩层里,一根钻杆正在以每分钟上百转的速度穿透坚硬的岩石。地面上,一组工程师盯着屏幕上的压力曲线、泥浆密度、返出岩屑图像——他们要在"井涌"或"井漏"发生之前,提前做出判断。传统方式下,这个判断依赖资深工程师的经验和直觉,反应窗口往往只有几分钟。
2026年5月28日,中国石油正式发布了昆仑大模型迭代升级成果。发布会上披露了一个数字:钻井风险预警准确率85%以上,上线半年累计预警300余次,超3000口井的参数实现了智能调节。这意味着,AI正在把"几分钟的反应窗口"悄悄拉长到"提前3天"。这不是一个营销话术,而是六大AI高阶能力在工业现场的真实落地。
背景:工业大模型为什么难?
过去三年,通用大模型的故事大家听得太多了。从GPT-3到GPT-4o,从文心一言到通义千问,每次发布都能掀起一阵讨论热潮。但如果你把同样的模型搬进炼油厂、搬上钻井平台,事情就变得完全不一样了。
通用大模型的核心能力是"理解和生成自然语言"。但在工业场景里,没有人关心模型能不能写一首诗。工程师关心的是:模型能不能看懂井下传感器的实时数据流?能不能根据历史事故案例推断出当前的风险概率?能不能在发现异常后自动调用对应的处置工具?能不能告诉我为什么它会得出这个结论?
这四个问号,恰好对应了昆仑大模型此次发布的六大AI高阶能力中的四个:预测预警引擎、工具调度与执行、反演计算、可解释性分析引擎。把这四块拼在一起,你就会发现——昆仑大模型在做的事情,远远超出了"问答"的范畴,它正在把AI从"参谋"变成"副驾驶",甚至在特定场景下成为"主驾驶"。
在此之前,能源化工行业并非没有尝试过AI。但过去的做法是"单点突破":某油田用一个模型预测产量,某炼厂用一个模型优化裂解炉温度。这些模型各自为战,数据不通、能力不共享,维护成本极高。昆仑大模型要做的事情,是用一个统一的AI底座,覆盖从勘探开发到炼化生产、从技术服务到资本金融的全产业链——152个应用场景,这是中国工业AI历史上最大规模的一次"集团军作战"。
技术深度拆解:六大AI高阶能力究竟意味着什么?
让我们逐一拆解昆仑大模型的六大AI高阶能力。这不是一份功能清单,而是一套完整的工业智能"操作系统"的能力边界定义。
① 自主规划与任务拆解
传统工业AI的做法是"你问我答":工程师输入一个参数,模型返回一个预测值。但真实的工业场景是"目标导向"的——比如"把这口井的钻进效率提升15%,同时把风险控制在可接受范围内"。这个目标需要被拆解成一系列子任务:调整钻压、优化泥浆比重、改变钻进参数……昆仑大模型的"自主规划与任务拆解"能力,就是让AI能够把一个高层目标,自动拆解为可执行的动作序列。这听起来像是AI智能体的能力——没错,工业智能体的核心就是这个能力。
② 工具调度与执行
拆解完任务之后,AI需要能够"动手"。在昆仑大模型的架构里,这意味着模型可以自动调用超过1700个工业软件接口:从地质建模软件到钻井参数优化工具,从炼化生产调度系统到设备健康管理平台。更重要的是,这些调用不是"一次性"的,而是可以根据执行结果动态反馈调整的。这相当于给AI配了一个"工具箱",而且它会用。
③ 专业计算引擎
这是昆仑大模型与普通大模型最本质的区别之一。通用大模型的"计算"本质是token预测,而昆仑大模型里的"专业计算引擎"是可以直接求解偏微分方程的。以"智能化声波全波形三维反演"为例:这是一项通过将全波形声波测井数据与市场地质模型进行全波形反演,来获得高精度地下介质参数分布的技术。过去这个计算任务需要在高性能计算集群上跑20天,现在昆仑大模型把它压缩到了3天,综合成本降低30%以上,关键性质预测准确率最高达95%。这种"物理规律+数据驱动"的混合计算范式,才是工业AI的真正护城河。
数据支撑:三组数字背后的故事
以下是三组来自官方发布和权威测评的具体数据,它们可以帮助我们更客观地理解昆仑大模型的能力边界。
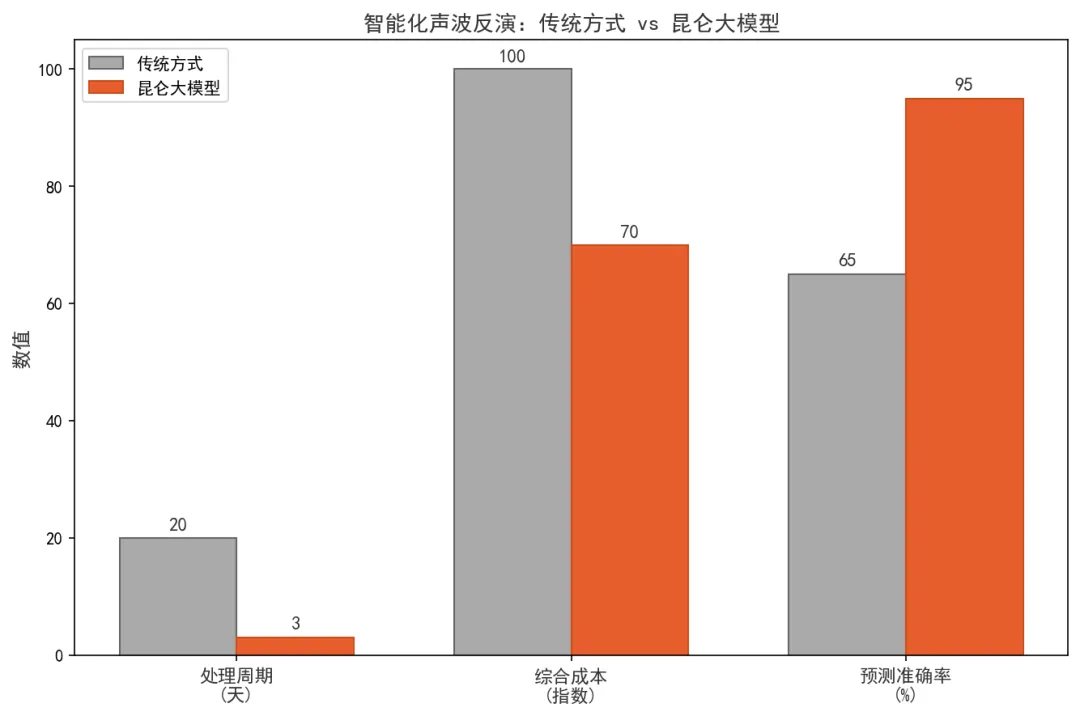
图1-2:智能化声波全波形三维反演——传统方式 vs 昆仑大模型(数据来源:中国石油昆仑大模型发布会,2026年5月)
第一组数字:152个应用场景,覆盖4大业务板块。油气勘探开发板块45个场景,炼化生产板块40个场景,技术服务板块38个场景,资本金融板块29个场景。这种覆盖密度在国内工业AI领域是前所未有的。更重要的是,这152个场景不是"演示用途",而是已经在生产环境里跑了半年的真实应用。以钻井风险预警为例,上线半年累计预警300余次——这意味着平均每家一天就有接近2次的有效预警。对于单口井造价数千万元的深井来说,哪怕只避免一次事故,ROI就已经成立了。
第二组数字:620TB行业数据,质量评分99.8分。这是中国电子技术标准化研究院的权威测评结果。620TB是什么概念?如果把这些数据全部打印成A4纸,叠起来大约有6万公里高——差不多是地球直径的5倍。但数据的"量"不是最关键的,"质"才是。昆仑大模型的训练数据经过了专门的能源化工行业知识清洗和结构化,每一个数值、每一条测井曲线、每一份事故报告都被标注了来源和置信度。这就是为什么它的"关键性质预测准确率"能做到95%——在合成橡胶性能预判这类高价值场景中,这个准确率已经可以支撑直接的工程决策了。
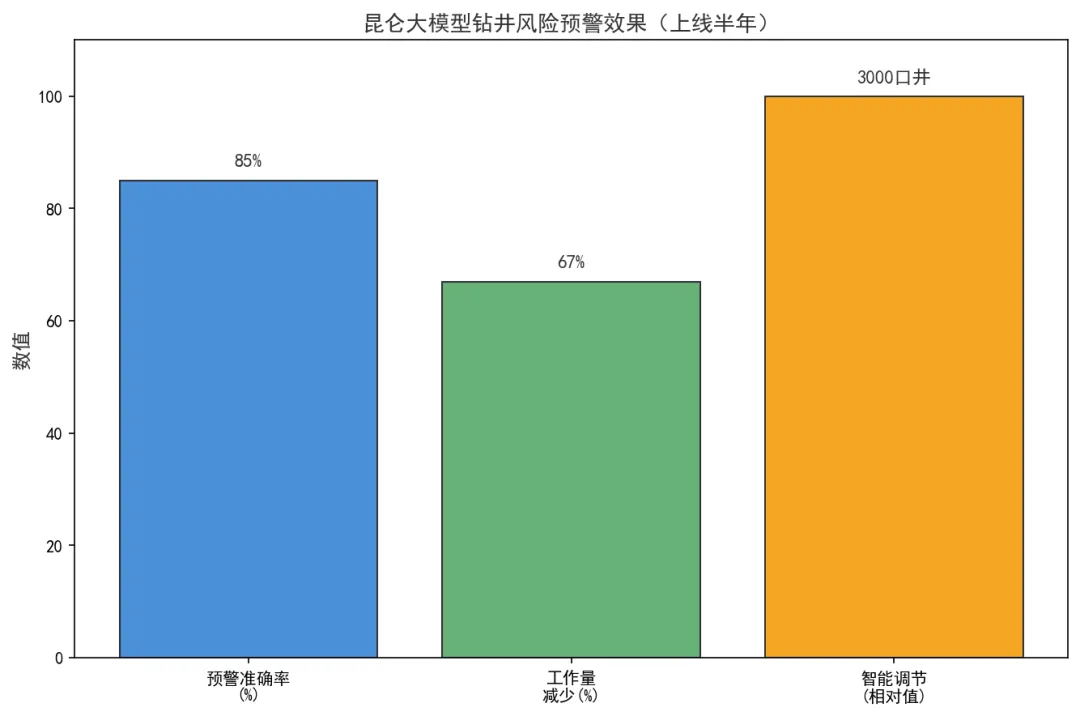
图1-3:昆仑大模型钻井风险预警效果(数据来源:中国石油,2026年5月)
第三组数字:1754P总智能算力,21款大模型在昇腾芯片上的精度与性能双对齐。这里需要解释一下"精度与性能双对齐"是什么意思。简单来说,就是当一个大模型从英伟达GPU环境迁移到昇腾芯片环境时,既要保证模型输出结果的数值精度不下降(精度对齐),又要保证推理速度不出现明显劣化(性能对齐)。过去这个工作是极其耗时的手动调优,昆仑大模型通过自研的"昇腾环境长文本加速架构",把这个过程自动化了。这使得昆仑大模型成为国内首个实现"全栈国产化AI技术底座"的能源化工行业大模型平台。
独家观点:工业大模型与通用大模型的根本分野
写到这里,我想提出一个可能不太主流的判断:昆仑大模型真正的独占价值,不在于它的参数规模有多大,而在于它重新定义了"工业场景需要什么样的AI"这个根本问题。
过去两年,行业里有一种隐含的叙事逻辑:"通用大模型能力越来越强,垂直行业模型迟早被取代"。但这个叙事忽略了一个关键问题——工业场景对AI的核心需求,和自然语言场景有本质差异。在自然语言场景里,"创造性"和"泛化能力"是核心指标;但在工业场景里,"可解释性"、"确定性"和"主动规划能力"才是真正的瓶颈。
昆仑大模型的六大能力里,最值得关注的是"可解释性分析引擎"。这是通用大模型普遍缺乏的能力。当你问一个通用大模型"为什么得出这个结论"的时候,它给出的解释往往是"基于训练数据的统计规律"——这句话等于什么都没说。但昆仑大模型的可解释性分析引擎,会告诉你"因为这个压力传感器的数值在过去4小时内上升了12%,而历史上有73%的类似情况最终演变成了井涌"。这种解释,工程师才敢信,才敢据此做出决策。
从这个角度看,昆仑大模型的发布,标志着中国工业AI从"能力验证阶段"迈入了"价值兑现阶段"。前者关心的是"能不能做出来",后者关心的是"能不能用起来、好不好用、值不值这个投入"。152个应用场景、85%的预警准确率、3000口井的智能调节——这些数字就是"价值兑现"的具体注脚。
展望:从"主动智能"到"自主智能"还有多远?
昆仑大模型此次迭代的核心叙事是"从通用问答向主动智能的关键跨越"。但"主动智能"并不是终点。"主动智能"说的是AI可以主动发现问题、主动提出处置建议;而"自主智能"意味着AI可以在人类设定的安全边界内,自主完成从问题发现到处置执行的全流程,只在遇到超出边界的情况时才向人类求助。
从目前披露的能力来看,昆仑大模型已经具备了"自主智能"的雏形:它可以自主规划任务、自主调度工具、自主执行计算——但在最终决策环节,目前仍然保留了"人在回路"(Human-in-the-Loop)的设计。这是负责任的做法。工业场景里,一个错误的自动决策可能导致数亿元的设备损失甚至环境污染事故。可以预见,随着模型可靠性的持续提升和监管框架的逐步完善,"自主智能"将在未来3-5年内逐步放开手脚。
最后一个值得关注的细节:昆仑大模型国际版支持中文、英语、法语、俄语、阿拉伯语、西班牙语、葡萄牙语共7种语言。这意味着中国能源化工AI能力正在向外输出——不是以"产品"的形式,而是以"平台"的形式。对于那些正在推进能源转型的发展中国家来说,这种"全栈国产化AI技术底座+多语言工业智能服务"的组合,可能比单纯的装备出口更有长期价值。
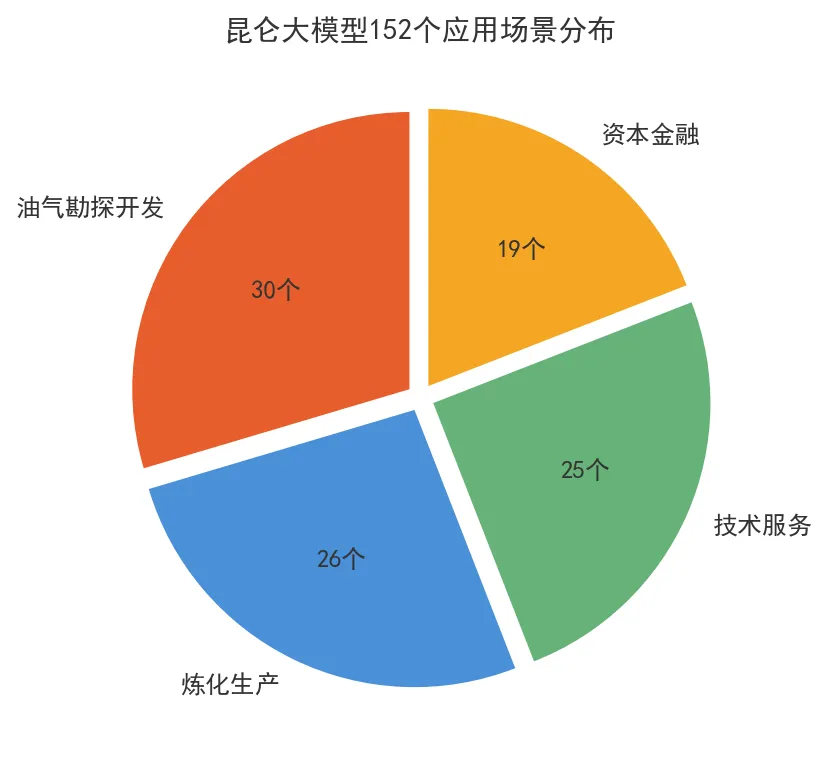
图1-1:昆仑大模型152个应用场景分布(数据来源:中国石油昆仑大模型发布会,2026年5月)
数据来源备注:本文引用的昆仑大模型相关数据均来自中国石油2026年5月28日发布会公开资料、新华财经报道及中国电子技术标准化研究院测评报告。
