夜雨聆风
夜雨聆风在新加坡国立大学学习最大的收获不光是从老师的课堂上汲取营养,开拓视野,更是从优秀的同学们身上提升认知,看到差距。原来在公司里,自认为勉强还算盘菜;到了 Nus,真觉得自己连根葱都不算,这种感觉真好。就像一场激烈的比赛,运动员的潜力会被氛围和节奏激发。
我曾经是一个学体育的学渣,因为女朋友(现在是老婆)而成为羽毛球爱好者,在媳妇本科毕业之后就成家创业,创业十二年之后深刻认知到自身能力的不足,开始奋发图强重新深度学习,带着对行业的浅见回炉深造,从创业酵母-经纬亿万-腾讯青腾-新加坡国立大学,憧憬着这辈子能走出一个大器晚成的剧本。
昨天在新加坡国立大学上课,听到了同学大牛的分享,是我最近2年经常听到关于AI底层介绍和实操最厉害的同学,我很兴奋居然听懂了原理,并不是因为自己多厉害,而是同学是大牛。所以趁热打铁简单给有缘分的朋友们做个分享。我自己目前用得也比较浅,但是我的目标是努力把AI从顾问变成顶级的合伙人
今天我们大部分朋友以为自己在用 AI,其实我们还远没进入 AI 时代,这两年,身边几乎所有人都在谈 AI,有人拿它写周报,有人拿它做 PPT,有人拿它查资料,有人拿它润色文案。很多人会说:“我已经在用 AI 了”。但如果我们诚实一点,就会发现:大多数人其实只是把 AI 当成了一个更聪明的搜索框,或者一个能回应的写作助手,比方说搜集和整理一些资料,这当然有用,但这还不是真正的 AI 时代。
真正的变化,不是“它能回答你”,而是“它开始替你做事”。真正拉开差距的,也不是“你有没有接触过 AI”,而是:你到底有没有理解它是怎么工作的,以及你有没有把它变成生产力。如果要把这件事讲清楚,我想先给出一个可能有点反直觉的结论:今天最强大的大模型,本质上一直在做同一件事:预测下一个 token。Token在我国有个官方的名字叫“词元”,听上去很朴素,甚至有点不值一提。但恰恰是这个看似简单的机制,构成了今天一切能力的起点:写作、翻译、总结、编程、推理、对话,甚至Agent。理解这一点,我们就有机会真正看懂 AI,也只有理解了这一点,我们才知道该怎么把AI用对,我昨天是有点被打通任督二脉的感觉。
一、AI是计算机的应用,在我们跟AI工具聊天的时候,它看见的根本不是“文字”,人看到一句话,会自然理解它的意思。比如这句话:“今天新加坡早上下雨了。”我们看到的是天气、场景、语义。但 AI 不是这么看的。AI的第一步,不是“理解”,而是切分。它会先把这句话切成很多更小的单元,这些单元叫token。token 可以理解为 AI 处理信息时使用的“最小积木”。它不一定等于一个字,也不一定等于一个词:英文里,常常是一个单词或一个单词片段。中文里,可能是一个字,也可能是一个词组。图片、声音、视频,本质上也都可以被切成类似 token 的单位。更重要的是:每一个 token 最后都会变成一个数字编号。这意味着,AI 真正处理的,并不是“今天新加坡早上下雨了”这句话本身,而是一串数字。它看见的不是文字而是编号。它处理的不是语言,它处理的是模式。这件事非常关键。因为它解释了一个常被误解的问题:AI 并不是先像人一样理解世界,然后再组织语言。它首先是在数字空间里做预测,语言只是这个预测过程最后投影出来的表象。
二、为什么 AI 有时聪明得可怕,有时又蠢得离谱?
如果你理解了 token,就会明白很多著名的“翻车现场”。比如以前大家很爱问:为什么 AI 连 Strawberry 里有几个 r 都可能数不清?原因很简单:因为它看到的未必是完整的 Strawberry 这个单词,也未必是逐字母地看。它可能看到的是几个 token 片段。它最擅长的是:根据上下文预测后面最可能出现什么,它不天然擅长的是:对字符做极其精确的逐位操作。这也是为什么它有时会在小数比较、字符统计、格式严格匹配这类问题上翻车。因为这些任务要求的是“机械准确”,而大模型最初学会的是“概率预测”。
所以你可以这样理解:大模型首先是一个概率系统,然后才表现出理解、表达和推理的能力。这一点非常重要。因为如果你把它神化成“什么都懂的电子大脑”,你一定会失望。但如果你把它理解成“一个极其强大的模式引擎”,你就会知道它为什么强,也会知道它为什么会错。
三、既然只是预测下一个 token,为什么它还能写文章、回答问题、甚至像在思考?因为这个“预测下一个 token”,远比想象中复杂。假设一句话前面是:
“新加坡国立大学中文 EMBA……”接下来可能出现的词有很多:“项目”“课程”“招生”“学员”……模型会做的事情是:1、看前面已经出现的所有 token;2、对词表里海量候选 token 分别计算概率;3、选出最可能的那个;4、再把这个新结果接回上下文;5、继续预测下一个 token。于是整个输出过程就变成了:看前文-猜下一个-接回去-再猜下一个,所以你看到 AI 一点一点往外“吐字”,不是它在模仿打字,而是它底层的工作方式本来就是这样。
它不是先把全文在脑子里写好再发给你。它就是一段一段、一步一步生成出来的。
四、那它为什么会“像理解了一样”?因为它把语义变成了向量。接下来是整个大模型最关键、也最容易被讲复杂的概念:向量。别被这个词吓到。你可以把它想成:AI 会把每个词放进一个巨大的语义坐标空间里。比如为了方便理解,我们假设有几个维度:更偏男性还是女性,更偏年长还是年幼,更有权威还是更弱势,那么“男人”“女人”“国王”“女王”“王子”“母亲”这些词,就会落在不同位置。
如果两个词的位置接近,说明语义接近;如果方向相似,说明关系相似。最经典的例子是:国王 - 男人 + 女人 ≈ 女王,这说明 AI 并不是死记“国王对应女王”,而是在一个高维空间里,学会了词和词之间的结构关系。这就是它为什么能做:类比、翻译、改写、归纳、迁移、联想,我们平常说“AI 理解了这个词”,更准确地说,是:它在向量空间里,学到了这个词和其他概念之间的位置关系。这不是人类式的理解,但已经足够形成惊人的能力。

五、真正改变一切的,不是 token,也不是向量,而是 Attention。AI 真正起飞,是因为 Transformer 架构把一个关键机制做对了:Attention,注意力。简单说,注意力机制干的事是:当模型处理某个词时,它不会只盯着前一个词,而会去看整段内容里,谁和我最相关。比如这句话:“新国大 EMBA 今年录取了 116 名学员,他们来自 25 个国家。”当 AI 处理“他们”这个词时,它会自动去问:“他们”指的是谁?和“他们”最相关的是“学员”吗?116 这个数字和它有关吗?25 个国家是不是在描述这批人?于是它就能理解:“他们”不是凭空来的,指的是“116 名学员”。这就是今天的大模型为什么比早期模型强得多。不是因为它背的东西更多,而是因为它更会处理关系。
可以把注意力机制理解成一句话:每个 token 都在问上下文:谁和我最有关?正因为它会不断做这种关系计算,词才不再只是词,而是在上下文里不断被赋予更具体的含义。
六、这也解释了一个现实:AI 不是没有记忆,它是没有“天然记忆”,很多人觉得 ChatGPT 很神奇,因为它好像记得你说过的话、记得你的偏好、甚至记得昨天聊过什么。但模型本身并没有人类那种长期记忆。它更像一个“失忆的天才”:具体表现为每次对话都很强,但每次都只能基于眼前给它的内容来工作。你之所以感觉它“记得”,是因为产品层做了很多工程增强。比如系统会把这些东西一起打包给模型:系统提示词,当前对话历史,近期对话摘要,长期记忆摘要,角色设定与规则,所以你以为你只发了一句:“再帮我改一版。”实际上系统发给模型的,可能是一整包历史上下文。这也带来一个非常现实的问题:上下文不是越长越好。上下文越长,成本越高,注意力越容易分散,模型对中间信息的敏感度还会下降。所以很多人觉得 AI “越聊越不对劲”,不是错觉。很可能是你的上下文已经被污染了。
七、真正会用 AI 的人,已经不再只是“提问”,而是在“管理上下文”。过去大家觉得,用好 AI 的关键是提示词。但现在越来越明显,真正的差距在于:谁更会提供和维护高质量上下文。你可以把 AI 理解成一个能力极强、但极度依赖工作环境的同事。给它清晰背景,它就强;给它混乱信息,它就乱;给它准确资料,它就稳;给它错误历史,它就会一路跑偏。所以真正高水平的使用方式,不是把所有东西都塞进一个聊天框,而是开始像经营操作系统一样经营自己的上下文,像是分组分类管理。这件事在普通聊天阶段不明显,但一旦进入严肃工作,就决定成败。
八、Agent 的出现,意味着 AI 第一次从“回答问题”走向“交付结果”。如果前面讲的是 AI 为什么能“说”,那接下来就该讲,为什么今年以来,AI 突然让人感觉“真能干活了”。答案是:Agent。最简单的定义是:Agent = 大模型 + 工具 + 循环。普通聊天型 AI 的流程是:你问,它答,结束。Agent 的流程是:你提出目标,它思考下一步,它调工具,它获取结果,它继续思考,它再调工具,它持续循环,直到把任务做完。这听起来只是多了几步,但本质上已经不是一个物种。因为从这一刻起,AI 不再只是“生成内容”,而是开始“推进任务”。
九、真正高效的人,不再把信息一股脑喂给 AI,而是会做“渐进式加载”很多企业一接入 AI,就想一步到位:把财报、会议纪要、飞书群记录、邮件、知识库全部扔进去。结果往往不是更聪明,而是更混乱。原因很简单。上下文不是垃圾桶。你塞进去的每一份文档,都会参与后续的注意力竞争。如果资料太多、噪音太大,模型虽然“都看到了”,却未必“抓住了重点”。所以更好的方法,不是全量喂,而是:先给概览,再按需展开。先让 AI 知道:项目是什么,哪些文档最关键,每份文档讲什么,遇到什么问题应该读哪一份,等它有整体框架之后,再按任务需要加载具体资料。这就像一个优秀的仓库管理员,不会让团队每次都从零翻仓库,而是先有地图,再去取货。

十、今天最颠覆的,不是 AI 比人强一点,而是一个人可以同时调动多个 AI。过去我们的智力单元只有一个:就是我们自己。现在不是了。现在我们可以同时拥有多个并行工作的数字执行者:一个帮你查资料、一个帮你写初稿、一个帮你改版式、一个帮你做分析、一个帮你整理会议纪要、一个帮你生成可交付页面。这会带来一个极其现实的结果:未来最强的人,不一定是亲自做得最多的人,而是最会调用 AI 系统的人。这也是为什么,未来组织结构都会变。很多工作不再需要水平分工,而会变成更小颗粒度、更强结果导向的垂直责任制。因为一个会调度 AI 的人,能覆盖的工作半径会变得非常大。
十一、如果把以上文章压缩成最值得记住的 8 个点,那么如下:
1、大模型本质上是在预测下一个 token。
2、AI 看到的首先是数字编号,不是人类语言本身。
3、向量让 AI 获得了语义表示能力。
4、注意力机制让 AI 能理解上下文关系。
5、AI 的“记忆感”大多来自他本身的推理,而不是天然长期记忆。
6、上下文质量,决定 AI 输出质量。
7、Agent 的本质是:大模型 + 工具 + 循环
8、真正的 AI 生产力,不在于多会提问,而在于多会设计任务、管理上下文和交付结果。
十二、我们以为我们在用 AI,其实我们只是在和它聊天。很多人今天最大的误区,是把“能和 AI 对话”误认为“已经完成了 AI 转型”,肯定不是这样的。会聊天,只说明我们摸到了入口。真正的门,在后面。当我们开始:用文档管理 AI 的记忆、用上下文管理 AI 的注意力、用 Agent 让 AI 真正执行任务、用系统思维重构自己的工作方式、我们才算真正进入 AI 时代。
从这个角度看,AI 不是一个新工具,它更像一次新的工业革命,只不过这次被放大的,不是体力,而是认知劳动。所以问题已经不是:“要不要用 AI?”而是:“我们要继续把 AI 当聊天工具,还是开始把它变成你的工作系统?”
这两种选择,会把人带向完全不同的未来。
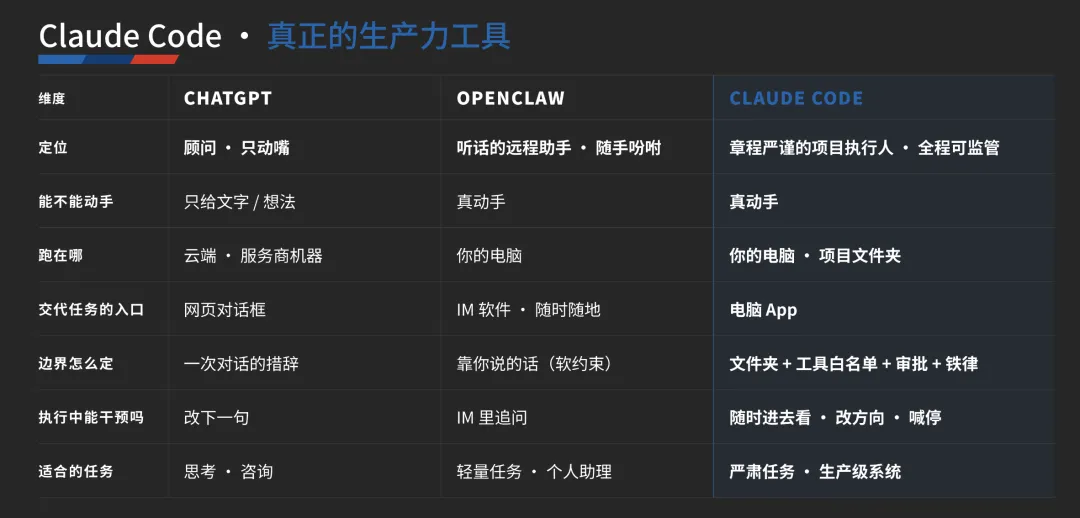
最后同学分享对比了最新的几个模型,供大家参考。