夜雨聆风
夜雨聆风可验证边界、印钞机效应与去Excel化圣战:AI正在重新丈量人类工作的价值
四条信息,一张地图:Agent 的边界在哪里,Anthropic 的钱从哪里来,安全的刹车片为什么失灵,Excel 凭什么被赶出华尔街。
第一层:肉身觉知
"可验证工作"这个概念,拿在手里,感觉是凉的,但是准的。
代码好不好,跑一下测试就知道。财务分析对不对,你没法立刻买入或做空来验证。这不是新观察,但在 YOLO Agent 狂热了整整一年之后,YC 社区能把这个分水岭说清楚,说明大家开始从情绪回到逻辑了。
Anthropic 首个盈利季度的传闻,比任何估值数字都更有重量。不是因为它证明了什么宏大叙事,而是因为它把一个模糊的商业赌注,变成了一笔清晰的账:Claude Code 在企业端大规模吞噬了基础程序员坑位,这件事产生了真实的毛利,而不是"战略性资本左手倒右手"的假繁荣。这条信息如果属实,它会是 2026 年商业 AI 最重要的分水岭——不是某个 benchmark 跑分,而是第一次真正赚到钱。
然后是去 Excel 化的圣战。Soria 被定位为"AI 原生彭博终端",开源组件曝光之后,黑客们开始把异构数据集融合成行业模型,把 MCP 服务器搬到本地,试图在不联网的前提下解构整个企业 ERP 软件。这场战争的对手,是全球每天被打开几十亿次的电子表格。打 Excel,不是在打一个工具,是在打一种思维方式。
第二层:系统推演
把四条信息的逻辑层展开,会看到一个关于"Agent 能做什么、不能做什么、谁来负责"的完整拷问。
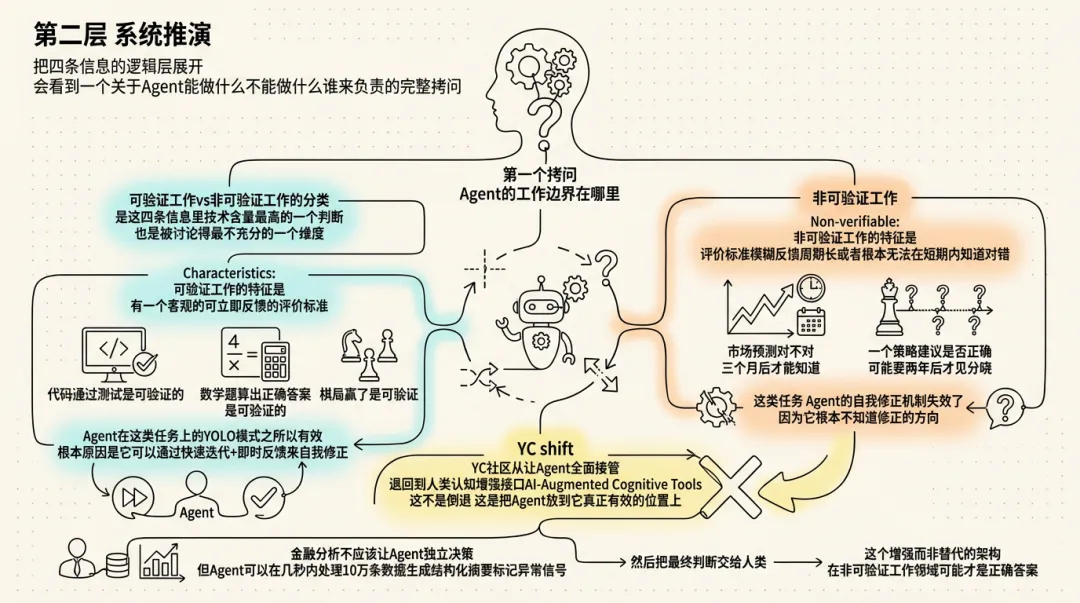
第一个拷问:Agent 的工作边界在哪里
可验证工作 vs 非可验证工作的分类,是这四条信息里技术含量最高的一个判断,也是被讨论得最不充分的一个维度。
可验证工作的特征是:有一个客观的、可立即反馈的评价标准。代码通过测试是可验证的,数学题算出正确答案是可验证的,棋局赢了是可验证的。Agent 在这类任务上的 YOLO 模式之所以有效,根本原因是它可以通过快速迭代 + 即时反馈来自我修正。
非可验证工作的特征是:评价标准模糊、反馈周期长、或者根本无法在短期内知道对错。市场预测对不对,三个月后才能知道。一个策略建议是否正确,可能要两年后才见分晓。这类任务,Agent 的自我修正机制失效了,因为它根本不知道修正的方向。
YC 社区从"让 Agent 全面接管"退回到"人类认知增强接口(AI-Augmented Cognitive Tools)",这不是倒退,这是把 Agent 放到它真正有效的位置上。金融分析不应该让 Agent 独立决策,但 Agent 可以在几秒内处理 10 万条数据、生成结构化摘要、标记异常信号,然后把最终判断交给人类。这个"增强"而非"替代"的架构,在非可验证工作领域可能才是正确答案。
第二个拷问:Anthropic 的钱从哪里来
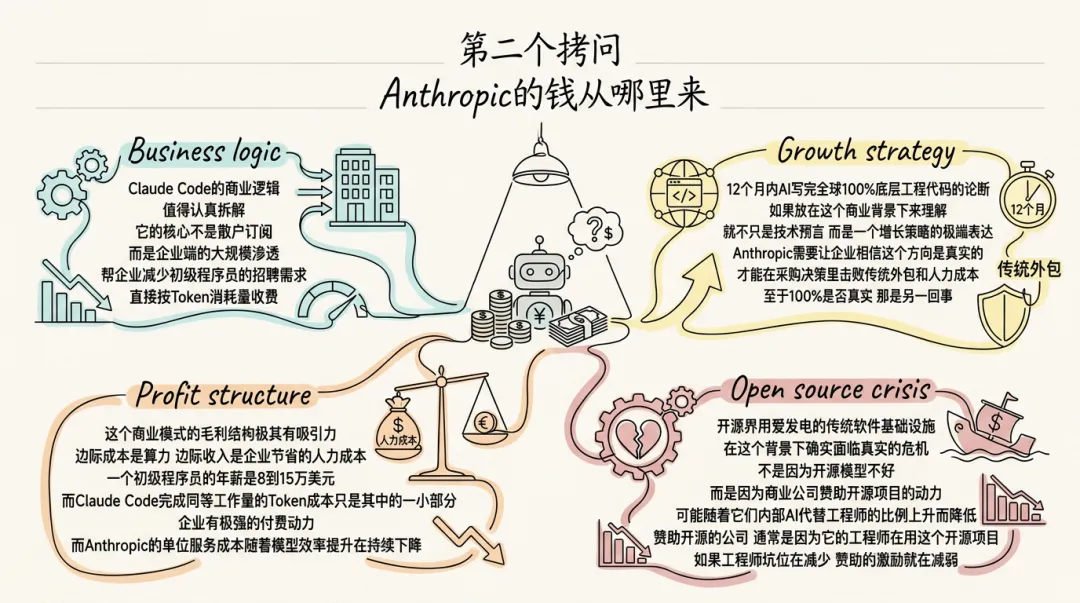
Claude Code 的商业逻辑,值得认真拆解。它的核心不是散户订阅,而是企业端的大规模渗透——帮企业减少初级程序员的招聘需求,直接按 Token 消耗量收费。
这个商业模式的毛利结构极其有吸引力:边际成本是算力,边际收入是企业节省的人力成本。一个初级程序员的年薪是 8 到 15 万美元,而 Claude Code 完成同等工作量的 Token 成本只是其中的一小部分。企业有极强的付费动力,而 Anthropic 的单位服务成本随着模型效率提升在持续下降。
"12 个月内 AI 写完全球 100% 底层工程代码"的论断,如果放在这个商业背景下来理解,就不只是技术预言,而是一个增长策略的极端表达。Anthropic 需要让企业相信这个方向是真实的,才能在采购决策里击败传统外包和人力成本。至于 100% 是否真实,那是另一回事。
开源界"用爱发电"的传统软件基础设施,在这个背景下确实面临真实的危机——不是因为开源模型不好,而是因为商业公司赞助开源项目的动力,可能随着它们内部 AI 代替工程师的比例上升而降低。赞助开源的公司,通常是因为它的工程师在用这个开源项目。如果工程师坑位在减少,赞助的激励就在减弱。
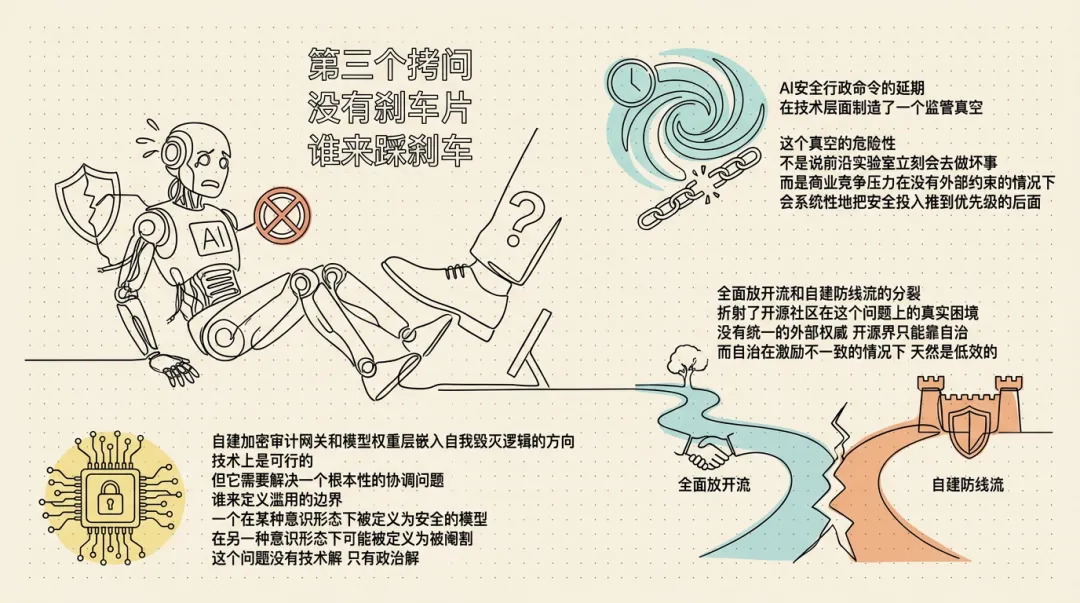
第三个拷问:没有刹车片,谁来踩刹车
AI 安全行政命令的延期,在技术层面制造了一个监管真空。这个真空的危险性,不是说前沿实验室立刻会去做坏事,而是商业竞争压力在没有外部约束的情况下,会系统性地把安全投入推到优先级的后面。
"全面放开流"和"自建防线流"的分裂,折射了开源社区在这个问题上的真实困境:没有统一的外部权威,开源界只能靠自治——而自治在激励不一致的情况下,天然是低效的。
自建加密审计网关和模型权重层嵌入"自我毁灭逻辑"的方向,技术上是可行的,但它需要解决一个根本性的协调问题:谁来定义"滥用"的边界?一个在某种意识形态下被定义为"安全"的模型,在另一种意识形态下可能被定义为"被阉割"。这个问题没有技术解,只有政治解。
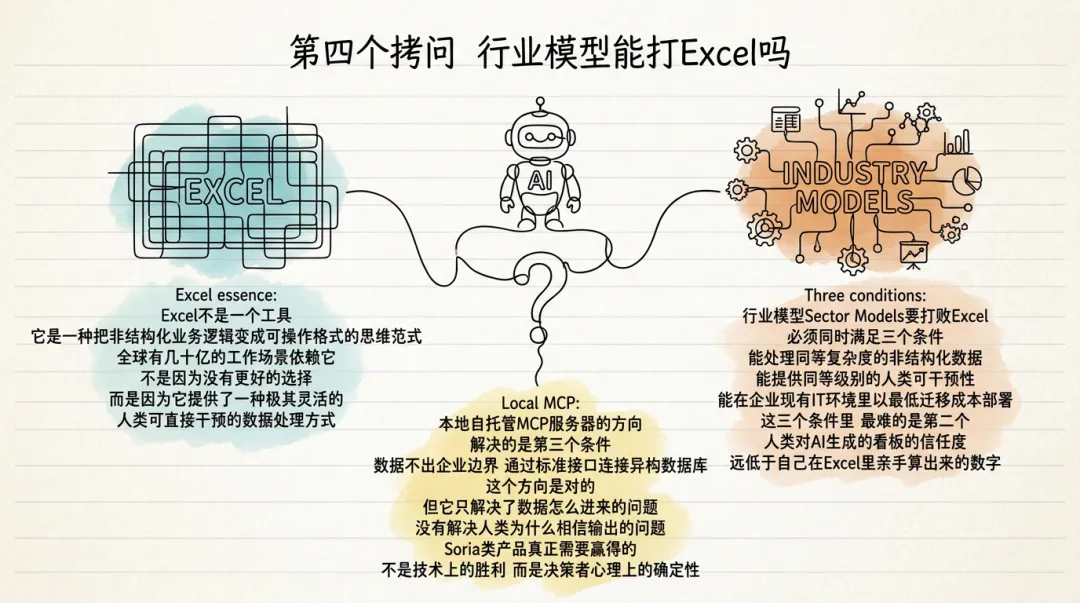
第四个拷问:行业模型能打 Excel 吗
Excel 不是一个工具,它是一种把非结构化业务逻辑变成可操作格式的思维范式。全球有几十亿的工作场景依赖它,不是因为没有更好的选择,而是因为它提供了一种极其灵活的、人类可直接干预的数据处理方式。
行业模型(Sector Models)要打败 Excel,必须同时满足三个条件:能处理同等复杂度的非结构化数据、能提供同等级别的人类可干预性、能在企业现有 IT 环境里以最低迁移成本部署。这三个条件里,最难的是第二个——人类对 AI 生成的看板的信任度,远低于自己在 Excel 里亲手算出来的数字。
本地自托管 MCP 服务器的方向,解决的是第三个条件——数据不出企业边界,通过标准接口连接异构数据库。这个方向是对的,但它只解决了"数据怎么进来"的问题,没有解决"人类为什么相信输出"的问题。Soria 类产品真正需要赢得的,不是技术上的胜利,而是决策者心理上的确定性。
对延展落地方向的判断
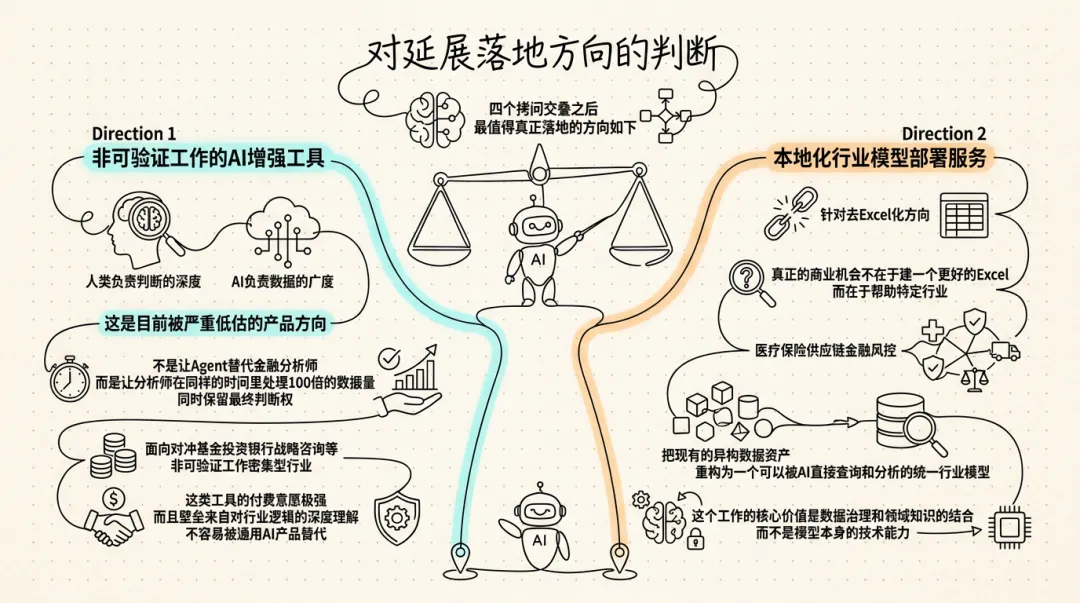
四个拷问交叠之后,最值得真正落地的方向如下:
非可验证工作的 AI 增强工具,这是目前被严重低估的产品方向。不是让 Agent 替代金融分析师,而是让分析师在同样的时间里处理 100 倍的数据量,同时保留最终判断权。这类产品的设计哲学是:AI 负责数据的广度,人类负责判断的深度。面向对冲基金、投资银行、战略咨询等"非可验证工作密集型"行业,这类工具的付费意愿极强,而且壁垒来自对行业逻辑的深度理解,不容易被通用 AI 产品替代。
本地化行业模型部署服务,针对去 Excel 化方向,真正的商业机会不在于建一个"更好的 Excel",而在于帮助特定行业(医疗保险、供应链、金融风控)把现有的异构数据资产,重构为一个可以被 AI 直接查询和分析的统一行业模型。这个工作的核心价值是数据治理和领域知识的结合,而不是模型本身的技术能力。
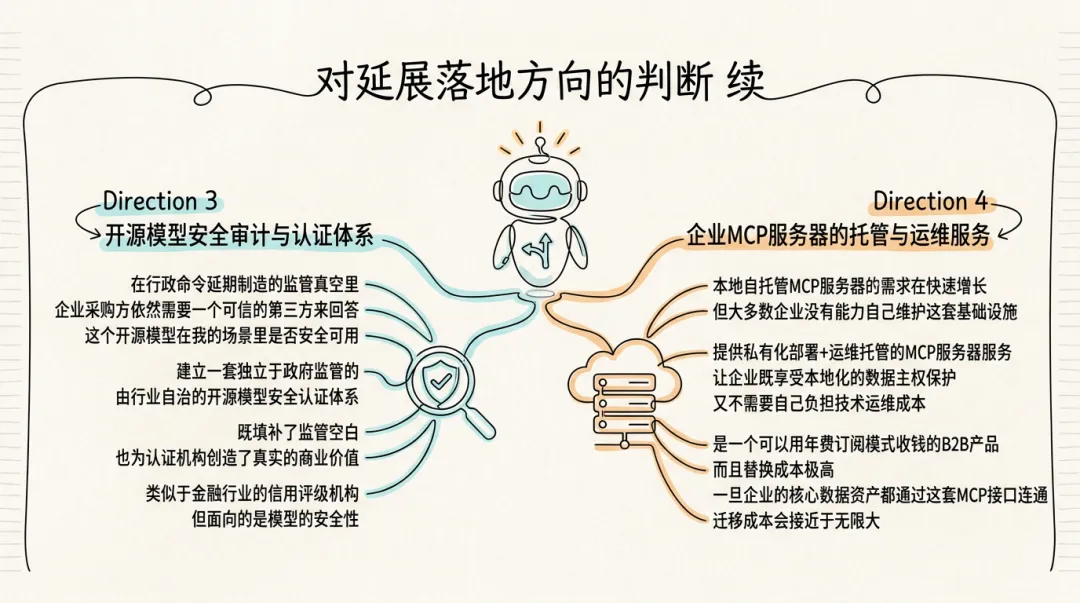
开源模型安全审计与认证体系,在行政命令延期制造的监管真空里,企业采购方依然需要一个可信的第三方来回答:"这个开源模型在我的场景里是否安全可用?"建立一套独立于政府监管的、由行业自治的开源模型安全认证体系,既填补了监管空白,也为认证机构创造了真实的商业价值——类似于金融行业的信用评级机构,但面向的是模型的安全性。
企业 MCP 服务器的托管与运维服务,本地自托管 MCP 服务器的需求在快速增长,但大多数企业没有能力自己维护这套基础设施。提供"私有化部署 + 运维托管"的 MCP 服务器服务,让企业既享受本地化的数据主权保护,又不需要自己负担技术运维成本,是一个可以用年费订阅模式收钱的 B2B 产品,而且替换成本极高——一旦企业的核心数据资产都通过这套 MCP 接口连通,迁移成本会接近于无限大。
Claude Code 竞品的中立化替代方案,随着 Anthropic 在企业代码市场的商业闭环跑通,构建一个不绑定单一模型厂商的企业代码 Agent 平台,让企业可以在 Claude、GPT-5、本地 DeepSeek 等模型之间自由切换,成了一个结构性的市场机会。这类平台的核心竞争力不是模型能力,而是企业代码库的上下文管理、权限控制、和审计日志——这些东西是企业合规的硬需求,而任何单一模型厂商都无法独自满足。