 夜雨聆风
夜雨聆风今日热点解读
1.美光科技受瑞银将其目标价大幅上调至1625美元的推动,股价大涨18%,市值首次突破1万亿美元,且其2026年全年HBM芯片产能已全部售罄。
Andy解读
1.资本向存储环节溢出:AI算力基础设施的投资重心正从单一GPU算力芯片向高带宽存储器扩散,科技巨头的资本开支向HBM产能倾斜,推动纯存储芯片厂商估值重构。
2.供需错配推高半导体估值:HBM产能超前售罄反映出数据中心对高密度、高带宽内存的硬性需求爆发,产能供不应求促使华尔街重塑对存储板块的营收预期。
2. Intel计划在其新墨西哥州Rio Rancho工厂建立全球首个玻璃基板批量生产基地,预计于2030年商业化首款共封装光学玻璃基板原型,并已开始面向外部代工客户提供硅光子制造服务。
Andy解读
1.打破有机基板物理极限:玻璃基板具有极高表面平坦度与接近硅片的热膨胀系数,能显著减少大尺寸封装下的热翘曲变形,支持更高密度的布线与极微细间距凸点连接。
2.加速光电共封装产业化:Rio Rancho工厂开放硅光子制造服务并推进玻璃基板CPO原型,将解决高带宽、低延迟AI算力集群的片间互连瓶颈,推动先进封装从电互连向光互连演进。
3. 评测机构Phoronix公布NVIDIA首批Vera CPU基准测试结果,该处理器凭借88个定制Armv9.2核心与1.2TB/s高带宽LPDDR5X内存,整体几何平均性能分别超越AMD EPYC 9575F约10%和Intel Xeon 6980P约55%,目前已进入客户测试阶段。
Andy解读
1.高带宽低功耗内存架构打破存算墙:Vera集成的第二代LPDDR5X系统在30W功耗下实现1.2TB/s带宽,且STREAM测试维持90%峰值效率,通过超高每瓦带宽直接解决算力集群数据预处理阶段的I/O瓶颈。
2.定制微架构适配具身智能与智能体:Olympus核心针对分支密集型和串行工作负载进行硬件级优化,大幅提升神经网络直出动作等非并行逻辑的执行效率,标志着AI数据中心计算中心正向高带宽、强单核性能的Arm架构演进。
4. AI网关厂商OpenRouter完成由CapitalG领投、NVIDIA与ServiceNow跟投的1.13亿美元B轮融资,估值达13亿美元。该平台目前支持超400个模型,月处理Token量达100万亿个,半年内实现5倍增长。
Andy解读
1.推理流量中心化:OpenRouter通过统一API屏蔽底层模型异构性,其Token吞吐量激增验证了企业应用从单体模型转向动态多模型路由架构,AI基础设施价值链重心正向推理侧接入层偏移。
2.智能体长尾效应:月均百万亿级Token负载反映出自主智能体等高频调用场景进入爆发期,开发者更倾向于通过网关实现低延迟模型切换与推理成本套利,规避单一供应商API停机风险。
5. Serverless AI云初创公司Modal Labs完成3.55亿美元C轮融资,由General Catalyst和Redpoint领投,估值升至46.5亿美元。该公司通过自建底层运行时与调度系统,支持用户在数分钟内将GPU规模从0弹性扩展至1000个。
Andy解读
1.自研低延迟底层构筑算力护城河:Modal自建Runtime、调度器与文件系统,摆脱了传统K8s架构在GPU冷启动与多租户隔离上的性能瓶颈,硬性需求推高了极速弹性基础设施的估值溢价。
2.多云聚合模式解决算力孤岛:通过与13家云服务商合作,Modal在不持有物理资产的前提下实现了跨数据中心的GPU网络协同,有效提升了企业平均仅5%的低效GPU利用率。
6. 宇树科技计划于6月1日接受上交所IPO首发申请审核,拟募集资金42亿元。公司2026年第一季度实现营收4.228亿元,同比增长超68%,但受研发与销售投入加大及行业热度回落影响,扣非净利润同比下降52%至4030万元。
Andy解读
1.营收高增长与利润腰斩:研发与销售投入硬性推高成本,加之行业炒作周期见顶,导致短期利润承压。目前营收仍高度依赖科研与教育市场,大众商业化应用场景尚未实质性打开。
2.资本市场定价风向标:作为国内少数实现盈利的人形机器人企业,其IPO审核结果将直接决定资本市场对具身智能板块后续商业化变现能力与估值锚点的预期。
7. 香港科技大学(广州)联合清华大学、浙江大学等多所高校发布具身智能首个机器人记忆评测基准RoboMemArena,涵盖4大记忆场景与26项长时程任务,并推出双系统VLA基线模型PrediMem。该基准首次系统性量化具身模型长时程任务的记忆能力,解决传统世界模型与VLA模型在大执行步骤下的记忆失效问题。
Andy解读
1.长时程任务量化基准缺失得到解决:RoboMemArena通过提供超1000个执行步骤的专家轨迹,统一了具身智能在长时程控制流中记忆机制的系统性评测标准。
2.双系统架构突破VLA长窗口上下文退化瓶颈:PrediMem基线模型通过双系统分工,缓解了传统注意力机制在极长视觉轨迹输入下的计算复杂度与记忆丢失问题。
目录
1.AI芯片
NVIDIA Vera CPU首批基准测试性能表现优异,超越同类竞品
NVIDIA Rubin CPX推理GPU发布计划存在不确定性,内存与基板订单尚未落实
Intel计划在新墨西哥州Rio Rancho工厂生产首个玻璃基板并提供硅光子制造服务
Marvell联合立讯技术展示用于Scale-Up与内部Scale-Out的224G长距离SerDes技术
世芯-KY董事长表示ASIC市场动能超越GPU,3nm设计需求旺盛
弘塑预期2026年起3D封装需求浮现,扩充产能应对订单
HNS Hi-Tech进军半导体封装薄膜市场,推出多款先进封装材料
SEMI发布玻璃芯基板市场报告,预计2028年启动初期生产
2.存储半导体
三星电子斥资15亿美元在越南建设半导体测试工厂以应对传统存储需求
美光UBS大幅上调目标价,带动Micron Technology市值首次突破1万亿美元
3.AI数据平台
LlamaIndex分析非结构化数据提取工作流,并强调LlamaParse智能体编排与多模态处理能力
LlamaIndex提出利用LlamaParse与语义搜索混合架构,解决智能体检索扩展与非结构化数据解析难题
Qumulo联合Cisco正式发布Cloud AI Accelerator,以解决数据引力瓶颈并提升GPU流动性
AI时代DBA角色向数据流水线监督转移,Everpure平台致力于消除基础设施碎片化
4.AI数据中心
施耐德电气预测AI数据中心向800伏电源架构与液冷技术的演进路径及影响
AI云初创公司Modal Labs完成3.55亿美元C轮融资,估值达46.5亿美元
5.AI模型与应用
OpenRouter完成1.13亿美元B轮融资,估值提升至约13亿美元
美光与阿贡国家实验室联合发布关于以推理为中心的LLM在GPU集群上的推理扩展与性能表征研究
研究人员提出MUSE-Autoskill框架,通过全生命周期管理使能LLM智能体的自我进化
6.具身智能
宇树科技第一季度利润同比下降52%,拟在IPO审核前筹集42亿元人民币
多所高校联合发布具身智能领域首个机器人记忆系统性评测基准RoboMemArena
[正文内容]

1.AI芯片
NVIDIA
2026-05-27:NVIDIA Vera CPU首批基准测试性能表现优异,超越同类竞品
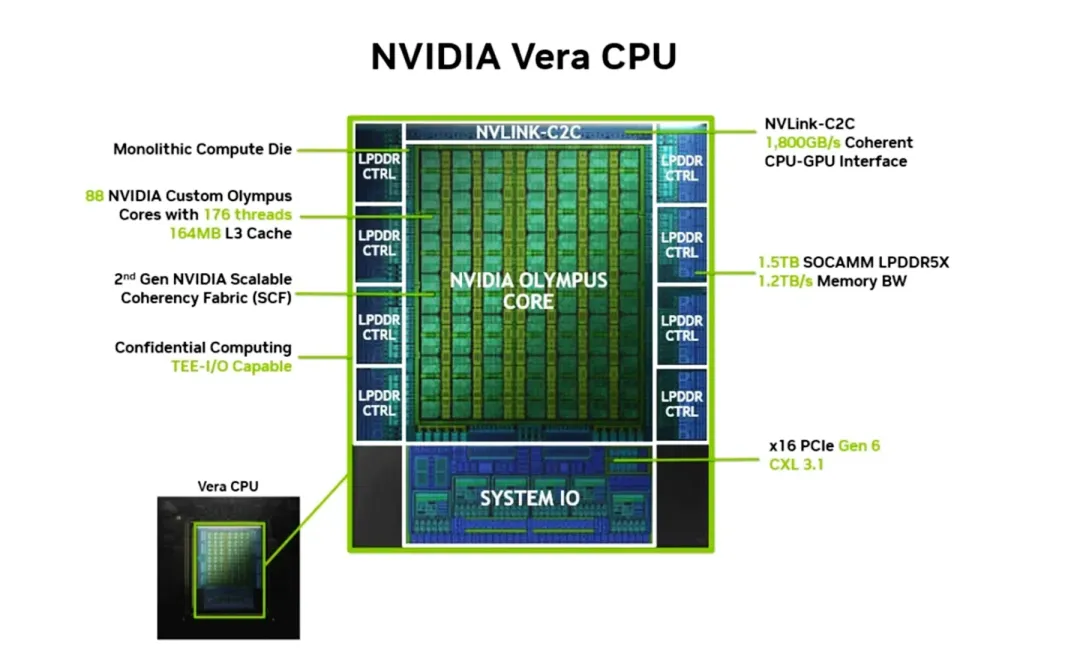
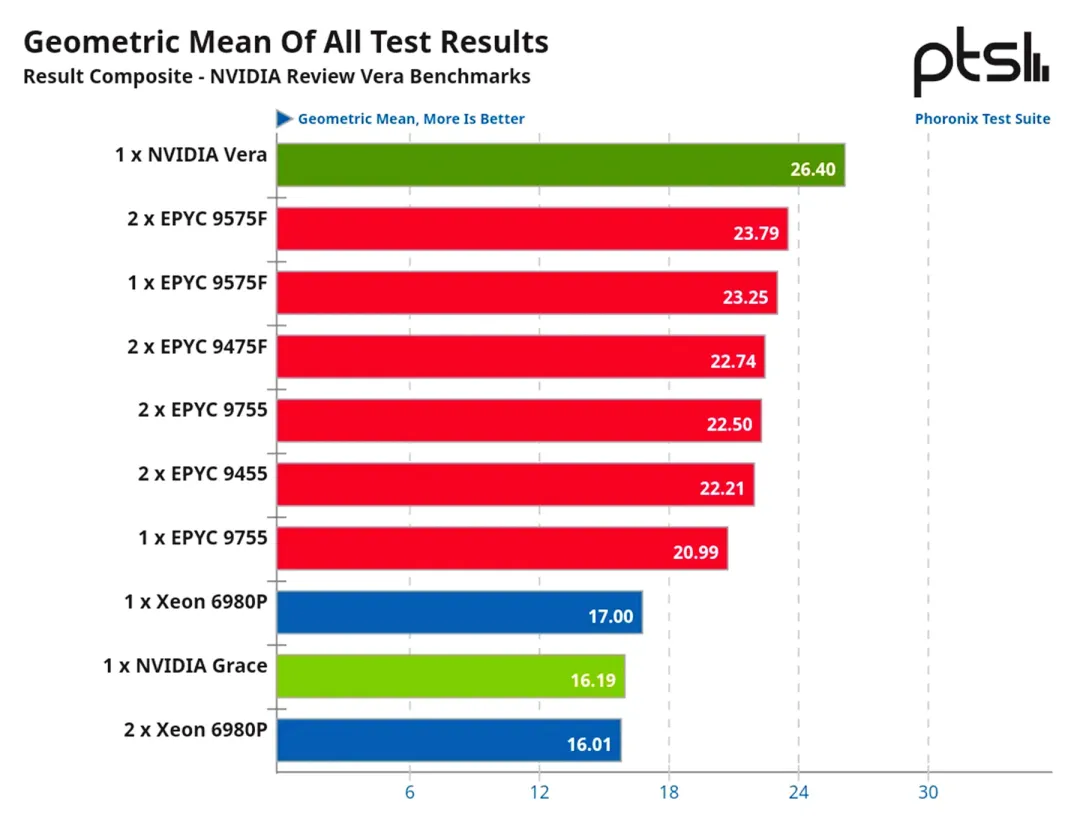
评测机构Phoronix公布了NVIDIA首批Vera CPU的基准测试结果。Vera CPU专为支持智能体的串行工作负载、分支密集型运行环境和数据处理设计。在整体测试几何平均中,Vera性能比前代72核Grace CPU提升约63%,比搭载Zen 5架构的AMD EPYC 9575F高约10%,领先Intel Granite Rapids Xeon 6980P约55%。Vera配备88个兼容Armv9.2指令集的定制Olympus核心,采用第二代NVIDIA可扩展一致性Fabric。其集成第二代LPDDR5X内存子系统,在内存功耗低于30W时可提供1.2TB/s带宽。在STREAM Triad测试中,Vera维持了90%的峰值内存带宽。在代码编译等实际工作负载中,单路Vera仅需20秒即可完成默认Linux内核编译,速度达128核竞品的2倍。目前Vera正处于客户测试阶段,提供风冷和液冷方案以支持AI工厂部署。
2026-05-27:NVIDIA Rubin CPX推理GPU发布计划存在不确定性,内存与基板订单尚未落实

行业消息指出,NVIDIA原计划于2026年下半年推出的推理专用GPU Rubin CPX发布前景存在不确定性。目前NVIDIA尚未下达相关的GDDR7或封装基板订单,也未提出相关开发需求。Rubin CPX原设计配备128GB GDDR7,在封装基板周围配置8个16GB芯片,用于应对智能体普及带来的推理计算需求。然而该产品已在2026年3月的GTC 2026路线图中被移除。市场分析指出,NVIDIA已将重心转向2025年底签署的价值200亿美元合同并实质性整合的Groq LPU技术,Groq 3 LPX已成为Vera Rubin平台的核心推理产品。基于整合的核心推理技术与工程师,NVIDIA未来可能会重新设计Rubin CPX。
Intel
2026-05-26:Intel计划在新墨西哥州Rio Rancho工厂生产首个玻璃基板并提供硅光子制造服务



报道指出,Intel正加速玻璃基板商业化,其新墨西哥州Rio Rancho工厂有望成为全球首个批量玻璃基板制造基地。Intel首款采用共封装光学(CPO)器件的玻璃基板原型预计于2030年实现商用。同时该工厂已开始向外部代工客户提供硅光子制造服务。在先进封装生态方面,Intel的EMIB技术已吸引AWS、Cisco等客户,并与Apple、Google、Microsoft、NVIDIA等探讨潜在合作。Rio Rancho与马来西亚槟城工厂主要负责EMIB生产和Foveros 3D芯片堆叠。受AI超大周期影响,有机基板面临短缺与技术瓶颈,玻璃基板因表面平坦且热膨胀系数接近硅,正成为中介层或基板的替代方案。
Marvell
2026-05-27:Marvell联合立讯技术展示用于Scale-Up与内部Scale-Out的224G长距离SerDes技术
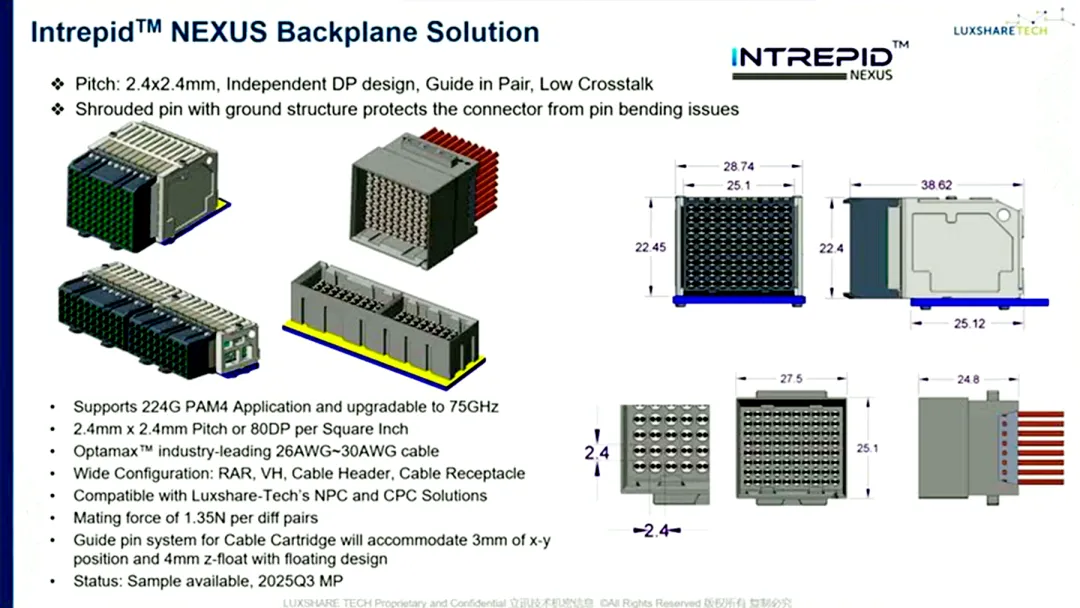

在OFC 2026上,Marvell与立讯技术展示了其3nm 224G长距离SerDes技术与共封装铜缆等连接方案的集成。该技术用于为服务器或交换机托盘内的芯片,以及机架内Scale-Up或Scale-Out网络构建高性能内部架构。该演示系统包含立讯技术的0.75米薄规格共封装铜缆、1米APEX高速背板及另一段0.75米共封装铜缆,累计传输距离2.5米。通过8个SerDes通道传输,端到端损耗为48dB,信道误码率达1e-11,性能表现优异。该技术可将最多512个通道集成到102.4T交换机中,每比特功耗仅4皮焦(pJ)。通过将200G/通道设备的每比特功耗降低1皮焦(pJ),系统功耗可降低100W,降低超大规模企业的OpEx或将电力转移至推理服务。
世芯-KY
2026-05-26:世芯-KY董事长表示ASIC市场动能超越GPU,3nm设计需求旺盛
在世芯-KY股东大会上,董事长沈翔霖指出,随着AI与HPC需求持续增长,定制ASIC增速将超越GPU。虽然GPU目前仍主导AI训练与推理市场并保持高速增长,但ASIC具备差异化与定制优势,市场动能更强。在CPU与GPU对比中,沈翔霖认为CPU目前多处于二维(2D)同构设计,准入门槛较低;而GPU已全面向2.5D和3D方向发展,技术复杂度高。世芯-KY将布局超大规模云服务商、定制系统与初创企业市场,并重点拓展北美布局以提升本地化服务。公司指出目前3nm需求旺盛,且重要客户在尝试其他供应商后已重新回流,客户黏性提升,预期2026年恢复营收与净利润增长。
弘塑 Grand Process Technology
2026-05-27:弘塑预期2026年起3D封装需求浮现,扩充产能应对订单
中国台湾半导体设备厂弘塑在业绩发表会上表示,受客户持续扩产驱动,至2027与2028年的订单需求强劲。预计2026年起3D封装需求开始浮现,且在2027至2028年的营收比重中显著提升。同时PLP市场空间扩大,相关出货将在2026年贡献少部分营收,2027年大规模确认营收。HBM应用快速增加,2026年相关出货量预计增长超100%。为满足产能需求,弘塑计划每年增加50%产能,目前通过二期新厂、并购、租赁厂房及外包等方式扩产。公司计划在东南亚、中国大陆及美国建立服务基地,满足客户本地化供应及售后服务需求。虽然第一季度受股权处置等因素影响毛利率,但预计未来高毛利的3D封装设备出货增加将对整体利润率形成支撑。
HNS Hi-Tech
2026-05-27:HNS Hi-Tech进军半导体封装薄膜市场,推出多款先进封装材料
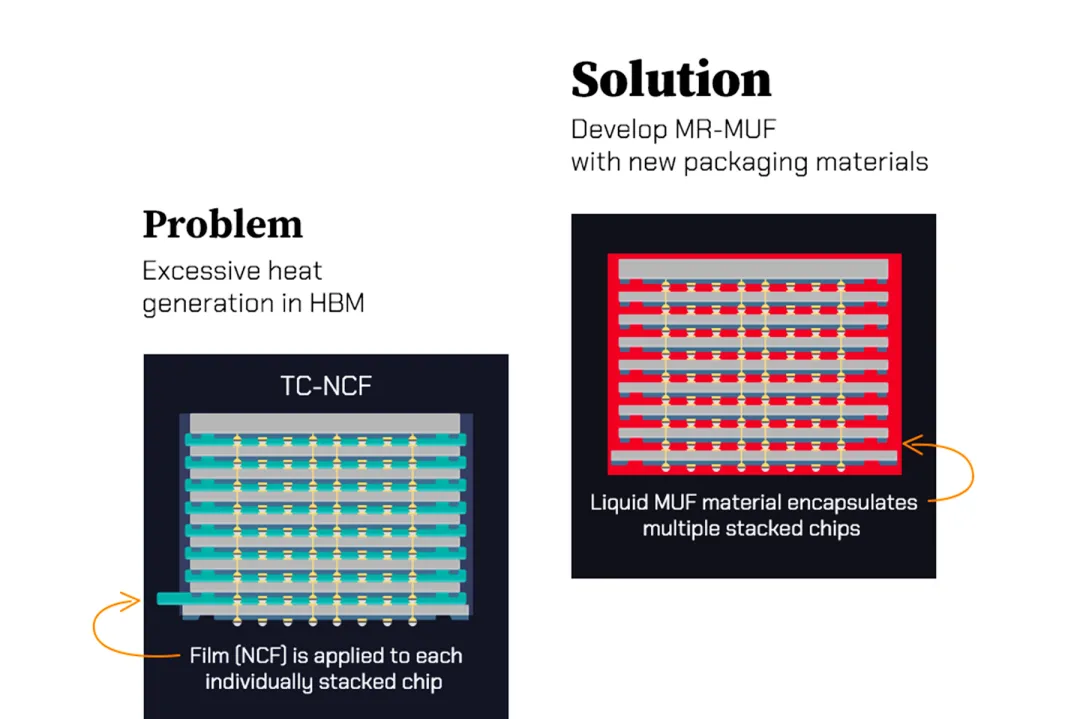
韩国企业HNS Hi-Tech宣布将产品组合从移动摄像头模组和显示器领域扩展至半导体封装材料市场,于SID 2026上展示了图案匹配薄膜、NCF及积层薄膜等关键产品。图案匹配薄膜基于高度均匀导电膜技术开发,属于ACF的高性能版本,可在超精细电路中实现稳定电连接,部分替代传统封装中的金属凸块用于芯片间及基板间连接。NCF是一种用于半导体堆叠热压键合工艺的绝缘材料,支持在凸块间距缩小的先进封装环境中保持粘合稳定性。积层薄膜用于高性能封装基板的绝缘层,对于减少高集成度基板信号损失 and 翘曲至关重要。目前该市场主要由日本味之素主导,HNS Hi-Tech正通过与全球显示和半导体制造商联合测试建立量产体系。
SEMI
2026-05-27:SEMI发布玻璃芯基板市场报告,预计2028年启动初期生产
SEMI与Global Netcorp联合发布《玻璃芯基板市场及发展趋势》报告。报告指出,受AI加速器和HPC等先进封装需求驱动,玻璃芯基板初期生产预计于2028年左右开始。初期将重点应用于部分高性能领域,随后扩展至更大、更复杂的半导体封装结构。玻璃芯基板通过用玻璃替代传统有机材料芯,具备耐热且几乎无翘曲的特性,支持实现更大封装面积和更精细的互连。报告预计,2028年至2040年间,全球玻璃芯基板市场CAGR将达67.2%。目前亚洲、北美和欧洲的企业及研究机构正扩大研发投入与CapEx,以支持更大封装尺寸、更精细互连及更高可靠性。
2.存储半导体
三星电子
2026-05-27:斥资15亿美元在越南建设半导体测试工厂以应对传统存储需求
Samsung Electronics目前正在越南北部太原省筹建一座价值约2.2万亿韩元(约合15亿美元)的半导体后端工艺测试工厂。该新工厂紧邻其生产智能手机和平板电脑的大型制造基地,是Samsung Electronics在越南设立的首家半导体测试工厂。根据向越南政府提交的投资申请,该工厂规划的DRAM最大年产能为1533亿Gb(约合191亿GB),NAND闪存年产能为2556亿Gb(约合318亿GB)。预计DRAM芯片的出货量占比将更高,且生产重心将主要聚焦于前代传统产品。该工厂计划于明年11月投产,目前项目已动工,自去年4月起已有200余名工程师驻场工作。越南政府已于今年3月批准该项投资。若新项目未来实现盈利,Samsung Electronics还计划追加25亿美元用于再投资,以建设第二座工厂。
Samsung Electronics筹建该测试工厂旨在缓解传统存储芯片的供应缺口。近期,为响应AI基础设施建设需求,Samsung Electronics和SK Hynix等存储芯片厂商将晶圆产能集中于HBM and 最新的DDR5等高附加值产品,导致DDR4和LPDDR4等前代传统产品产量快速下降。今年4月,Samsung Electronics已停止接受LPDDR4与LPDDR4X产品的客户订单,但市场对前代传统存储芯片的需求依然维持高位。数十年来,Samsung Electronics在越南的累计投资已超230亿美元,推动越南成为半导体后端工艺的重要基地,目前Intel、Amkor Technology和Hana Micron等多家厂商也在当地运营封装测试(封测)工厂。
美光
2026-05-27:UBS大幅上调目标价,带动Micron Technology市值首次突破1万亿美元
在AI基础设施部署加速、存储芯片需求强劲的背景下,美国最大存储芯片厂商Micron Technology股价盘中大涨18%,市值首次突破1万亿美元(约合新台币31.44万亿元)。此次股价上涨主要由于UBS将美光目标价由535美元大幅上调至1625美元。该目标价为追踪美光的46家券商中的最高预测值,达到了5月22日收盘价的两倍以上。这一里程碑不仅表明存储芯片在AI基础设施中的关键作用,也反映出AI投资逻辑的转变,即资金正从GPU制造侧向外扩散,流入有望受益于大型科技公司CapEx计划的其他板块。行业分析指出,纯存储芯片需求短期内快速上升,处于行业核心地位的Micron Technology市值突破1万亿美元,印证了数据中心需求的强劲增长。
3.AI数据平台
LlamaIndex
2026-05-26:LlamaIndex分析非结构化数据提取工作流,并强调LlamaParse智能体编排与多模态处理能力
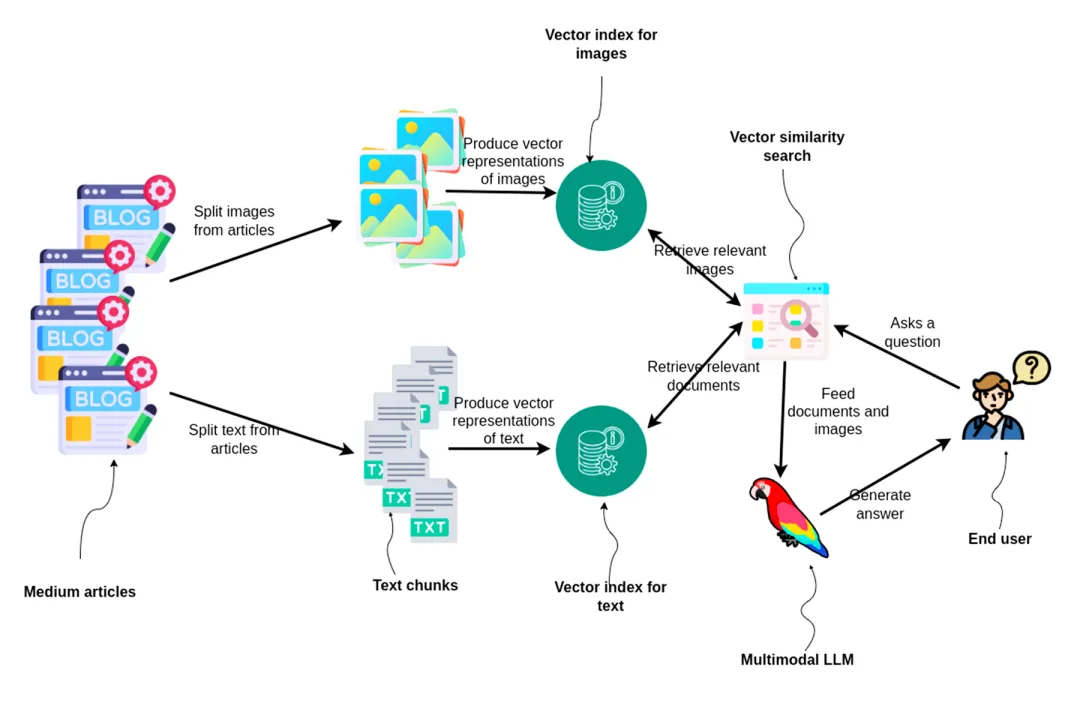
企业数据中约有90%为非结构化数据,传统的基于规则的解析器在文档格式变化时极易失效。现代提取方法主要基于NLP、NER以及LLM,以支持零样本或少样本提取。数据提取流水线通常涵盖数据摄取、预处理、提示词设计与提取、校验以及数据输出与系统集成。在生产环境中,高级提取技术需要通过Pydantic模型或JSON Schema进行架构约束与强校验,并采用合理的切片分块策略进行上下文窗口管理。LlamaParse引入了智能体编排机制,可将文本块、表格和图形等不同版面元素智能路由至最契合的模型处理路径。这实现了高效的多模态理解与多重校验闭环,无需针对每种新文档格式进行定制化微调,即可输出高可靠性的结构化数据。
2026-05-26:LlamaIndex提出利用LlamaParse与语义搜索混合架构,解决智能体检索扩展与非结构化数据解析难题
企业中大部分知识都沉淀在非结构化文档中。在小规模纯文本语料库场景下,传统的词汇搜索能够为智能体提供快速、精确的词项匹配。然而,当语料库规模扩展至数百万级文档时,词汇搜索就会遭遇响应延迟、因词汇表达差异导致的召回率低下,以及信噪比失衡等瓶颈。语义搜索及基于此构建的RAG模式,通过建立近似最近邻索引来支持子线性时间检索,从而在语料库规模增长时依然能保持大致恒定的查询时间。LlamaIndex推出了LlamaParse MCP服务器以及完全本地化的LiteParse工具,旨在将非结构化文档精准解析并无缝开放给下游工具链。行业内务实的解决方案通常采用分层设计:首先使用版面感知解析工具将非结构化文档解析为高保真文本,随后进行索引构建以支持高效率的语义搜索,同时将精确匹配搜索作为备选方案保留在工具箱中,供智能体自主调用与决策。
Qumulo
2026-05-26:Qumulo联合Cisco正式发布Cloud AI Accelerator,以解决数据引力瓶颈并提升GPU流动性
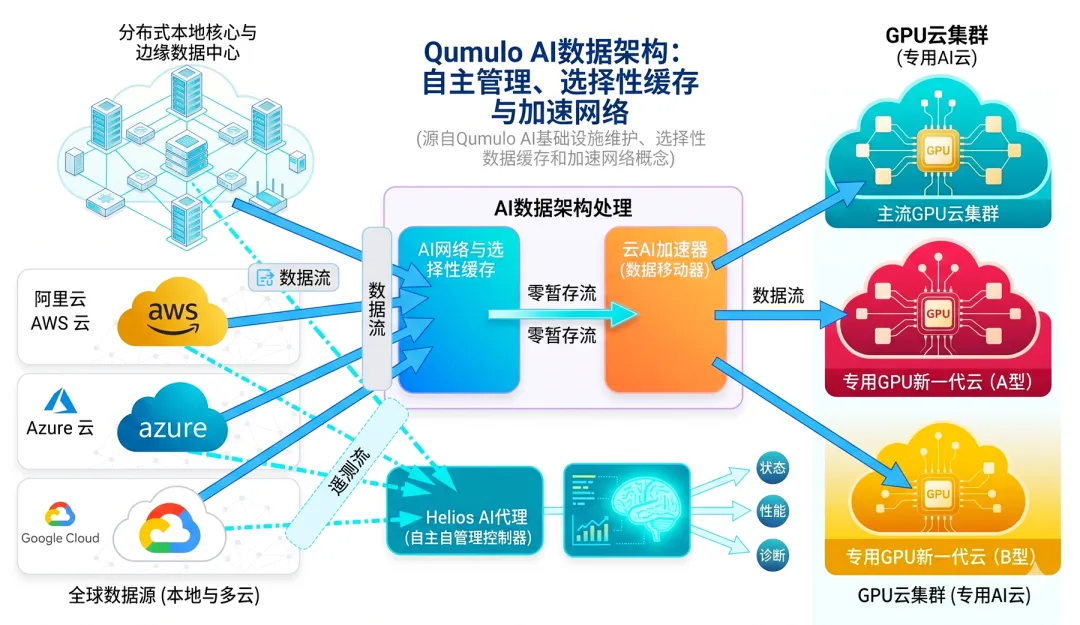
当前企业GPU的平均利用率仅为5%左右,这意味着价值数千亿美元的算力基础设施有将近95%的时间处于闲置状态。造成这一局面的主要原因在于,在AI工作负载正式启动前,必须花费数周时间进行繁重的数据暂存与迁移。Qumulo联合Cisco正式推出Cloud AI Accelerator产品。该产品旨在消除将数据复制并暂存到紧耦合全闪存存储的繁重阶段,从而降低因数据等待导致的GPU闲置成本。该产品基于其Cloud Data Fabric核心存储库与NeuralCache预测性缓存技术,能够将数据以块级数据流的形式,直接从本地部署(On-Prem)、边缘节点或云原生系统传输至加速器的缓存空间,随后直接送达GPU。这助力企业构建起与各主流云服务商AI平台的安全连接。此外,该产品目前尚未直接支持NVIDIA的STX参考架构及其KV Cache方案。
Everpure
2026-05-27:AI时代DBA角色向数据流水线监督转移,Everpure平台致力于消除基础设施碎片化
随着AI原生数据库逐步将自动调优和机器学习辅助优化等功能融入数据库内核,DBA的角色定位正在发生根本性转变,即从过去的持续手动干预,过渡到对自动化系统的顶层监督与合规验证。行业研究表明,混合云环境与基础设施的碎片化带来了高昂的运维开销。高达80%的受访者指出,DBA不得不将大部分精力耗费在环境的重复验证上,阻碍了业务创新。在此背景下,DBA的职责重心正加速向数据流转转移,重点聚焦于多系统间数据流水线的平稳运行,以及结构化与非结构化数据的共存。Everpure平台的设计初衷,正是通过消除底层异构平台的可变性,确保系统性能和运维工作流在不同环境下的行为表现高度一致,从而避免在工作负载迁移时丧失AI自动化带来的效率提升。
4.AI数据中心
Schneider Electric
2026-05-27:施耐德电气预测AI数据中心向800伏电源架构与液冷技术的演进路径及影响
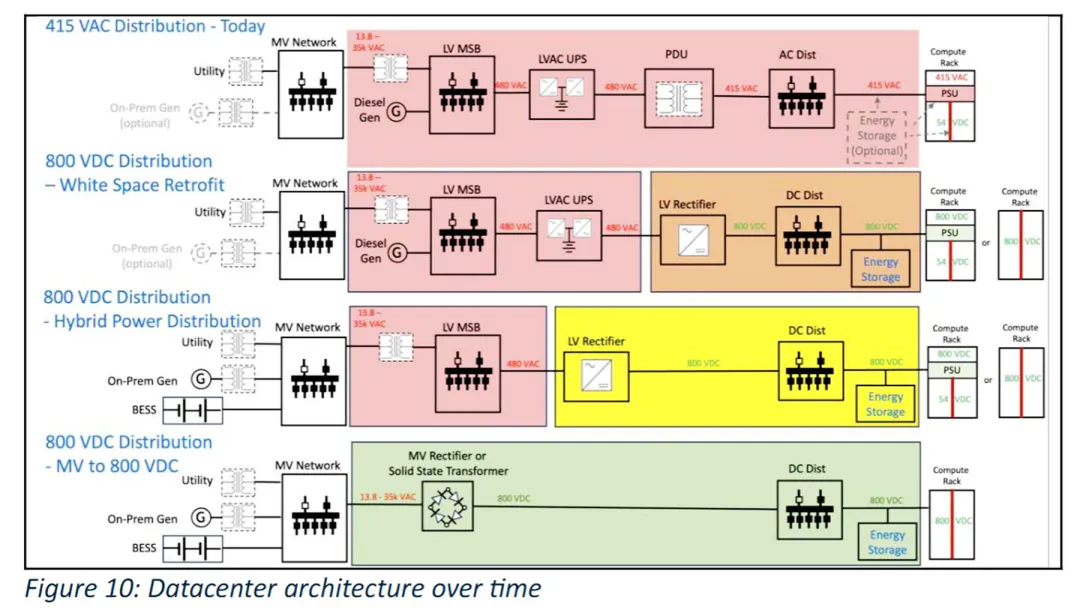
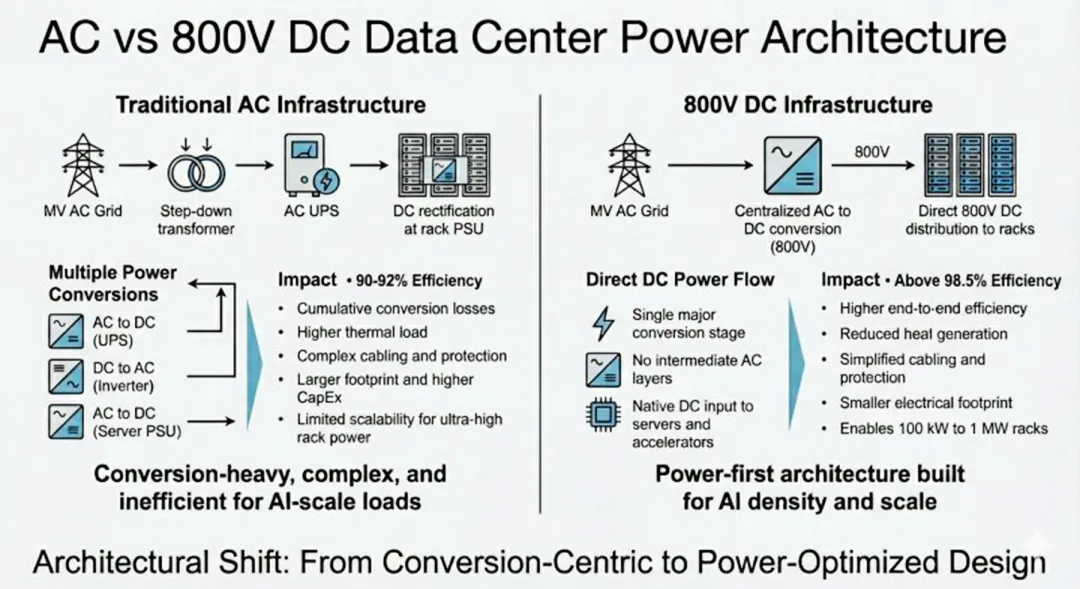
NVIDIA可能正在推动数据中心客户采用800伏电源,其Kyber机架架构设想了单机架功耗高达1兆瓦(MW)的极高能耗场景。然而,Schneider Electric云服务和云服务商技术解决方案总监Rob Bunger预计,到2030年,全球仅有约10%的新建AI节点会采用800伏直流电。随着单机架功率从140千瓦(kW)增长至400千瓦(kW),传统的48伏机架内配电架构将面临来自物理馈电与功率转换器的严重拥堵挑战。例如,运行72个GPU的150千瓦(kW)机架需要8根线缆,而运行144个GPU的1兆瓦(MW)机架则需要多达32根线缆,这使得原有的物理设计在实际部署中变得不再可行。通过将转换器移出机架并提升配电电压,可以实现单根线缆传输更大电力。Schneider Electric预计将于2029年推出基于2至5兆瓦(MW)模块的集中式直流配电解决方案,以替代占用机架空间的Sidecar(侧车)方案。此外,AI训练工作负载具有显著的脉冲特性,这不仅要求数据中心基础设施保障IT负载的高可用性,还必须同时具备保护电网的能力。

在制冷技术方面,Schneider Electric首席营销官Kevin Brown和制冷业务负责人Duan Huang指出,随着高功耗机架的激增,向液冷技术的转型将支持AI数据中心生成更多Token。一项对比得克萨斯州与巴黎两地100兆瓦(MW)数据中心的研究表明:在得克萨斯州,结合液冷技术与NVIDIA Vera-Rubin系统,数据中心可实现1.04的PUE,消耗相当于79个奥林匹克标准游泳池的水量,并生成2.52×10^11个Token;而在气候更为温和的巴黎,同等规模 of 设施在维持1.04的PUE之余,仅需消耗20个游泳池的水量,即可生成2.91×10^11个Token。上述高管强调,采用液冷技术并不必然意味着高用水量,实际耗水量主要取决于蒸发冷却的应用程度以及数据中心地理位置的选择。通过合理的建筑与制冷系统设计,能够大幅提升数据中心的能源利用与算力产出效率。
Modal Labs
2026-05-26:AI云初创公司Modal Labs完成3.55亿美元C轮融资,估值达46.5亿美元
总部位于纽约市的AI云初创公司Modal Labs在C轮融资中筹集了3.55亿美元,使其公司估值达到46.5亿美元。这一估值水平是其2025年9月完成的8000万美元B轮融资(当时估值为11亿美元)的4倍以上。本轮融资由General Catalyst和Redpoint领投,Menlo、Bain Capital Ventures以及Accel等新老投资者共同参与。由于投资机构认购意向强烈,该轮融资分两批进行,首批以25亿美元的估值入场,第二批则以更高的估值完成投资。
Modal Labs由首席执行官Erik Bernhardsson和首席技术官Akshat Bubna共同创立。公司从零开始构建了自主可控的Runtime、调度器、文件系统和编排层,专为AI等计算密集型应用提供快速迭代与弹性计算能力。借助该Serverless基础设施平台,用户无需预先储备资源,即可在数分钟内将GPU数量从0弹性扩展到1000个。Modal Labs自身不拥有或运营物理数据中心,而是与包括比特币挖矿公司Bit Digital在内的13家云服务商展开合作。目前,该公司的计算服务平台已被广泛应用于构建AI编码工具、生物技术平台、大规模推理系统以及支撑复杂的研究工作负载。
5.AI模型与应用
OpenRouter
2026-05-26:OpenRouter完成1.13亿美元B轮融资,估值提升至约13亿美元
OpenRouter宣布完成1.13亿美元B轮融资,由Alphabet旗下成长风险基金CapitalG领投。完成本轮融资后,OpenRouter估值约13亿美元,相比一年前A轮融资时约5.47亿美元的估值(当时筹集4000万美元)实现大幅增长。作为AI网关厂商,OpenRouter支持企业及其他人工智能用户为不同任务选择合适的AI模型,以控制成本并提升推理准确性。目前该平台提供对400多个模型的访问,包括Anthropic、Google、OpenAI、xAI和DeepSeek等。其全球用户数已达800万,每月处理100万亿个Token(每周约25万亿个Token),处理量较六个月前增长5倍。这一增长反映出人工智能工作负载正从训练向推理及智能体方向转变,并印证了企业避免受单一模型供应商锁定的多模型趋势。
美光科技 / 美国阿贡国家实验室
2026-05-26:美光与阿贡国家实验室联合发布关于以推理为中心的LLM在GPU集群上的推理扩展与性能表征研究
美光科技与阿贡国家实验室研究人员联合发布题为《理解LLM的推理扩展:瓶颈、权衡和性能原则》的技术论文。研究指出,系统需求正经历从标准生成式AI向以推理为中心架构(如广泛的思维链(CoT)处理)的根本性范式转变。与传统以计算受限的Prefill(预填充)阶段为主的工作负载不同,以推理为中心的工作负载会生成长Token链,将推理过程转变为容量受限瓶颈。研究团队在GPU集群上对8B至671B参数的模型进行了全面系统表征。分析表明,数据并行对小型模型具备高吞吐效率,但由于KV Cache碎片化强制施加早期限制,导致计算资源利用率偏低,在推理工作负载中易陷入容量陷阱。张量并行可释放闲置内存,并在模型规模接近32B时提供次线性增益。在前沿规模下,密集模型(如Llama-405B)受限于Fabric与内存带宽,更适合采用高维度张量并行;而稀疏的混合专家(MoE)模型(如DeepSeek-R1)主要受限于路由与同步延迟,采用混合策略可获得更大收益。该研究通过系统性探索数据并行、张量并行和流水线并行之间的相互作用,为构建下一代推理基础设施的架构设计提供了严谨的决策框架。
行业动态
2026-05-26:研究人员提出MUSE-Autoskill框架,通过全生命周期管理使能LLM智能体的自我进化
针对现有LLM智能体在技能构建上存在的碎片化与静态化缺陷,从而限制其可重重用性与长期优化能力的问题,研究人员提出MUSE-Autoskill智能体框架。该框架以技能为中心,支持智能体在统一的全生命周期(创建、记忆、管理、评估与完善)下,按需创建并在跨任务中存储和重用技能,持续提升任务解决能力。智能体可通过单元测试和运行时反馈对技能进行评估并持续完善。此外,框架引入技能级记忆,可跨任务为各项技能积累经验。基于SkillsBench的实验初步证明,这种全生命周期管理的技能机制能提升任务成功率、运行效率、技能重用率及跨智能体迁移能力,凸显了将技能作为长期存在、具备经验感知且可测试资产的重要性。
6.具身智能
宇树科技 Unitree Robotics
2026-05-26:第一季度利润同比下降52%,拟在IPO审核前筹集42亿元人民币
宇树科技(Unitree Robotics)正推进IPO进程,上海证券交易所上市委员会定于6月1日审核其首发申请。公司计划通过本次发行募集42亿元人民币资金。财务数据显示,尽管宇树科技第一季度营收同比增长超68%,达到4.228亿元人民币,但扣非净利润同比下降逾52%至4030万元人民币,低于去年同期的8480万元人民币。
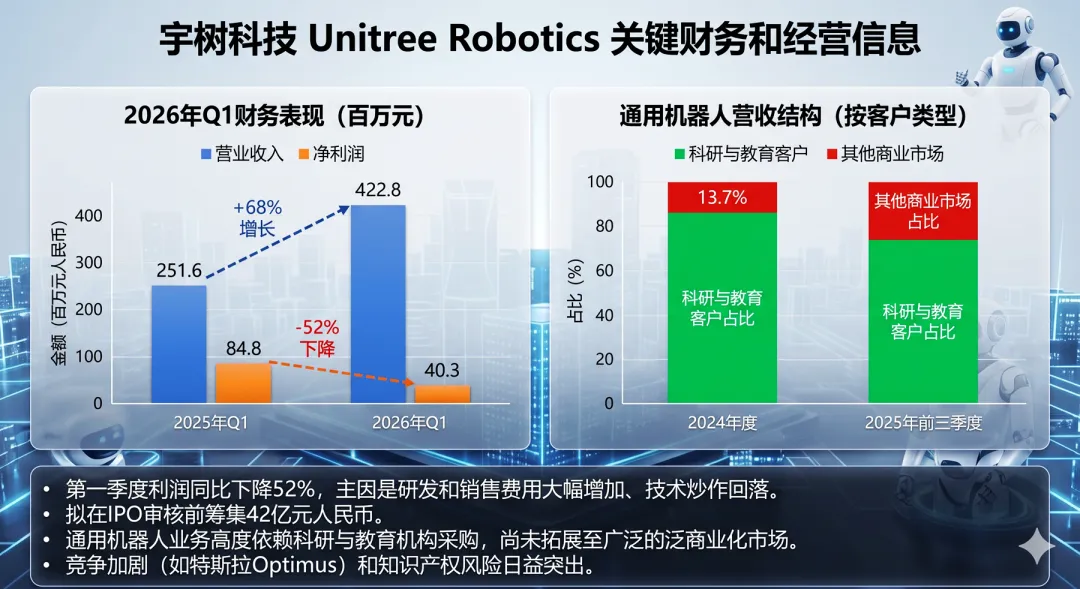
研发与销售费用大幅增加、人形机器人技术炒作周期热度回落,以及2025年高增长带来的高基数效应,是导致第一季度利润承压的主因。尽管面临短期压力,公司对后续增长仍持乐观态度,预计上半年营收将同比增长35.6%至45.4%,达到10.5亿元至11.3亿元人民币,净利润降幅预计收窄至6.4%至22%。
宇树科技仍是业内少数实现大规模盈利的人形机器人企业之一。作为对比,优必选在2025年实现营收20.01亿元人民币,但归母净亏损达7.03亿元人民币。在营收结构上,宇树科技的通用机器人业务高度依赖科研与教育客户,该领域在2024年和2025年前三季度分别贡献了86.3%和73.6%的营收,表明其商业化变现仍主要依赖机构采购,尚未拓展至广泛的商业市场需求。
此外,公司正面临日益激烈的竞争与知识产权风险。特斯拉(Tesla)的Optimus项目以及中国车企、消费电子巨头的竞相入局,可能会对公司的定价能力、市场份额和盈利空间造成压力。同时,由于公司在历史上主要通过商业秘密来保护技术,并未优先采用专利手段,截至1月31日,公司仅拥有262项海内外注册专利(含20项国内发明专利),这可能会限制其通过知识产权保护来维护核心技术的能力。
行业动态
2026-05-27:多所高校联合发布具身智能领域首个机器人记忆系统性评测基准RoboMemArena
香港科技大学(广州)联合清华大学、浙江大学、西湖大学、上海交通大学等多所顶尖高校与科研机构,共同发布了具身智能领域首个聚焦机器人记忆能力的系统性评测基准RoboMemArena。当前,具身基础模型(如VLA、世界模型)在处理长时程与复杂任务时,常面临记忆能力不足的瓶颈,而现有的基准测试对依赖记忆的长时程操作刻画明显不足。
RoboMemArena突破了传统基准仅关注短期感知与即时控制的局限,构建了涵盖物体转移、目标遮挡、动作计数与顺序执行四大核心记忆场景的综合评测体系。该基准共包含26项长时程任务、151个细粒度子任务(其中68.9%依赖历史记忆)以及2600条专家长程视觉轨迹。平均每个任务包含超过1000个执行步骤,并切分为15100个对齐关键帧的视频片段。该基准提供了构建机器人记忆所需的完备多模态标注,包括子任务级标注和显式标记物理状态转折的关键帧标注。
该基准除仿真环境外,还配套设计了5个复杂的真实机器人记忆任务,最长真实任务的时长超过3分钟,支持外部单位手动上传模型进行真机评测。配合该基准,研究团队还提供了一个双系统VLA基线模型PrediMem。该模型的高层VLM负责规划与记忆管理(显式维护最近帧缓冲区与关键帧缓冲区),并通过预测编码头对物理状态的转折保持敏感;低层VLA则负责执行具体动作块。
实验结果表明,PrediMem在仿真实验中以38.5%的整体任务成功率优于其他基线模型(如MemER、π0.5),并在真实机器人任务中取得了52%的平均成功率。在最长、最复杂且最依赖历史信息的真实任务(模拟人类做早餐)中,仅有PrediMem成功完成。这表明在长时程机器人任务执行中,记忆机制并非可选项,而是决定任务能否完整执行的核心底层能力。
更多交流,可加本人微信
(请附中文姓名/公司/关注领域)

