 夜雨聆风
夜雨聆风梳理下大学里的几门数学课,目的是服务于管工学科里做数学模型的这条脉络。
大数据数学基础课 运筹优化建模课 运筹优化原理课 机器学习模型课
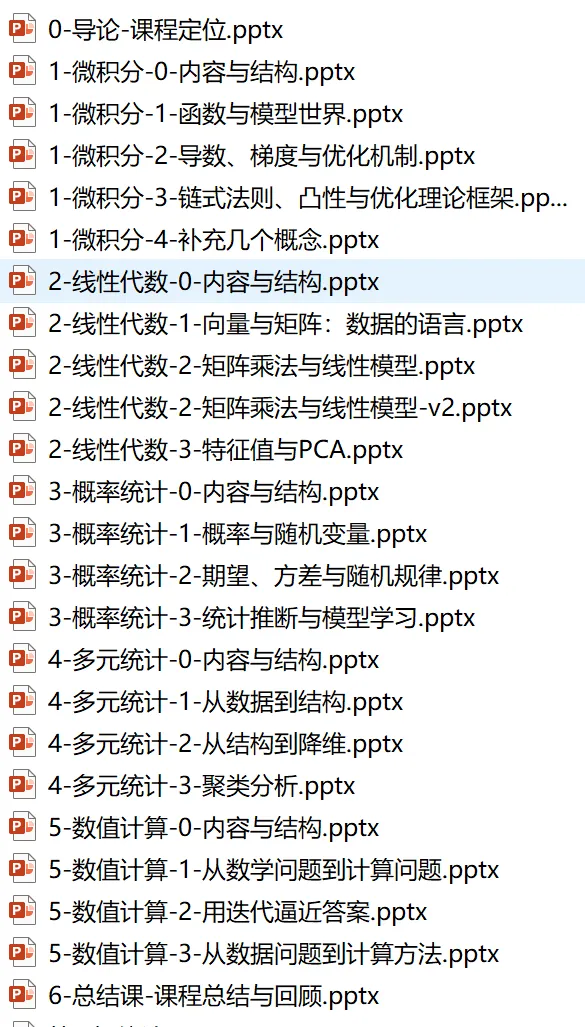
1. 大数据数学基础课
课程对象是非数学专业的本科生,其实给研究生上也可以。大体上是把大学期间上过的数学课串起来,服务于大数据分析。大部分学生学完数学课,考完试之后,就把数学都丢掉了,而且学的时候也大约是为了考试。上数学课为了考试是一码事,为了用是另外一码事。真正用的时候,有好多需要转变思维的地方。
一般非数学专业的本科生大体上只是上微积分、线性代数、概率统计,这三门数学课。多一点的也许还会上离散数学、多元统计、计算数学等。
这门课是串了微积分+线性代数+概率统计+多元统计+计算数学。服务于大数据分析,数学核心还是微积分、线性代数、概率统计
微积分告诉我们优化到底是怎么回事,其实就是函数求极值,极大或极小,最大或最小。 线性代数告诉我们数据结构到底是怎么回事,但凡提到结构两个字,其实就是在说几何。 概率统计告诉我们数据是怎么来的,以及不确定性到底是怎么回事。 多元统计,多元、多变量、高维、多维,其实都是一回事。前提得是的“多元”,数据结构变复杂了,才有分析结构的必要,不管是降维、回归、聚类、分类,都是在数据结构上做文章。 还有个计算数学,这个也是有必要的。按照公式来求解是一码事,计算机求解数学公式,或者是函数极值,或者是解方程,其实跟数学书上教的公式定理不是一回事。计算数学里最核心的观念就是迭代,先蒙一个解,然后按照某种规则调整这个解,得到新解,继续调整,继续迭代,直到满足某个停止标准。做算法设计是一定需要碰计算数学的。
离散数学其实是另外一码事,也跟大数据有关,但是其实不是服务于数据分析,是服务于数据存储,就是早些年的那些分布式存储、通信那些,Hadoop什么的。
2. 运筹优化建模课
首先第一点,数学建模比赛,这个数学模型其实是个更宽泛的概念,有各种各样的数学模型,运筹优化模型其实只能算是其中的比较小众的一个分支。而且对于解决一个问题,其实并不一定需要上数学模型的,也许可以完全直接上某个算法,或者某种规则就可以把事情搞定。解决一个问题,上数学模型的基本出发点是为了“全局最优解”,相比之下,用算法或者用规则来解决问题,大部分都是些局部最优。
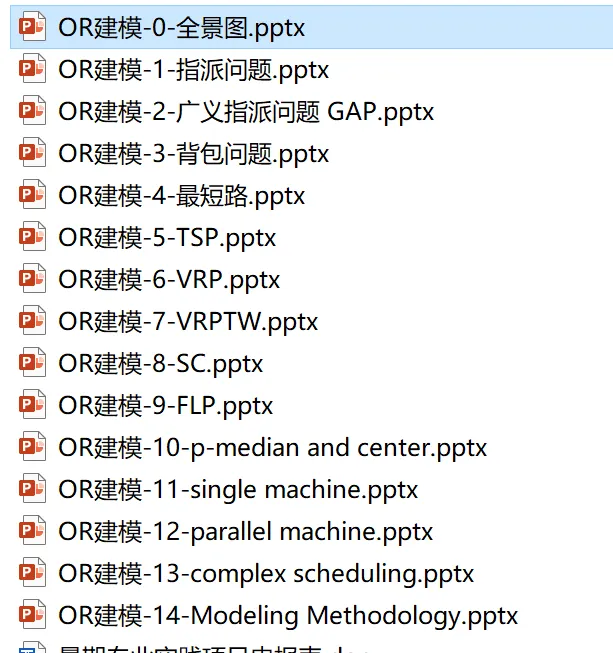
然后是运筹优化建模课,运筹优化这门学问本身的历史都不长,源自二战,到目前也就80年左右的历史。OR的模型类别也很窄,常见的就那么多。
指派问题,什么资源做什么事情 背包问题,在给定资源的前提下选择做哪些事情 路径问题,图论的分支,最短路,最大流,最小树 选址问题,网络设计问题,什么地方建仓库、消防站,医院等 调度问题,什么人什么时间做什么事情,这里的时间是关键
似乎也就这么几类。
运筹优化,“优化”的基本出发点就是让有限的资源发挥更好的效果。“先有再优”,类似先有可行解,再从中挑选最优解。
其实现在用AI做模型,只要我们能把一个问题描述清楚,AI都可以帮我们做一些很不错的模型。越复杂的问题,数学模型往往也越复杂。只是应该具有一种认知,复杂模型往往都是经典模型,+约束,+结构,+不确定性等一步步的复杂起来的,不是一下子就这么复杂的,理解这个慢慢生长的脉络很重要。
这门课就是讲这个模型慢慢变复杂的脉络。
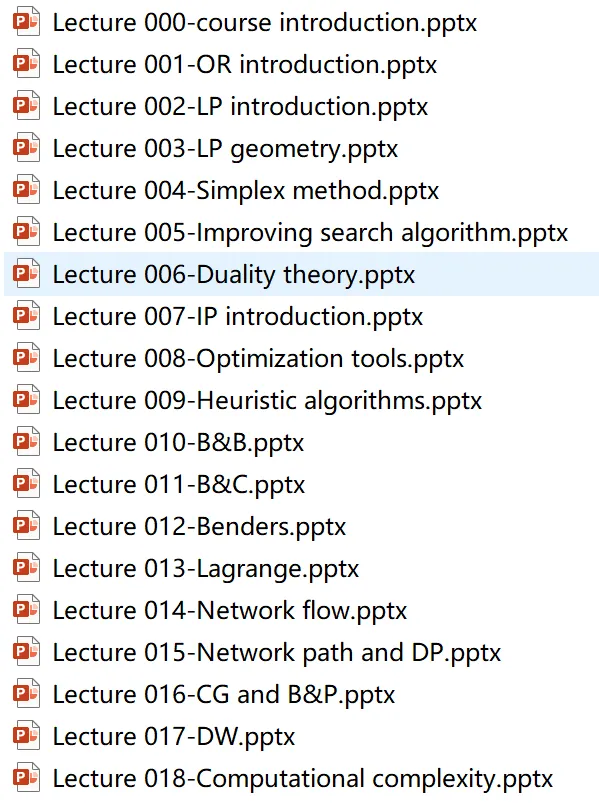
3. 运筹优化原理课
这个其实是两部分,模型性质分析,以及算法设计。
模型相关,首先第一个认知是,对于一个问题,一定是可以做不止一个数学模型的,有点模型表述的很清晰,有些模型虽然抽象但是符合某种特殊结构等。
模型分析大体上的事情
给定一个模型,这个模型好不好,复杂不复杂,能不能加强,能怎么加强。 一个模型不靠谱,怎么变?这个模型里包含一些很复杂的东西,怎么处理掉?或者是能否基于这个模型重新做个模型?那些对偶处理,变来变去的东西就属于这里。
至于算法设计
首先是那些智能算法,各种swarm intelligence,各种learning-based heuristics,各种meta-, hybrid-, hyper-等的算法,都是解决问题的算法,大体上都属于近似算法。
然后是那些精确算法,精确算法的设计放到复杂问题里,基本上就只剩下“分解”这一个途径了。起点还是问题很复杂,模型很复杂,但是我们仍然想用精确算法来搞定它。那没办法,要么做一个很厉害的模型,用上各种数据结构。要么就只能是把问题分解、模型分解了,一个复杂的问题分解成几块,再通过某些机制让这些模块在求解时能够相互传递一些信息,从而保证最终得到的解仍然是数学上的精确最优解。
目前为止,组合优化/整数规划/离散优化(这仨其实是一回事)里的精确算法
Benders那一套,主问题+子问题,两者之间信息传递来传递去的,其中最重要的是一个类似“泛化”的概念,大白话讲就是传递的信息要尽可能多的发挥作用。当然尽可能地传递准确严谨的信息也很重要。 列生成CG那一套,这个很厉害,核心在问题的理解与重构,一个复杂的问题,里面要包含某种特定的结构,sub-route, pattern, module什么的,然后走集合覆盖或者集合划分的路子。最核心的关键在于能够稳定快速地找到更好的pattern,这个很吃数据结构、图论那一套东西,一般需要比较好的编程基础,最好是计算机出身的… 拉格朗日那一套,这个的基本认识是往往都是用来处理一些非线性优化,大体上是上乘子,然后外部逼近等,这个碰的比较少,不敢乱说。
关于运筹优化,标注的OR,现在做研究的,感觉大部分都在做不确定性优化或者动态规划、强化学习那些。不确定性的确是现实问题里绕不过去的一个点。这一茬,目前个人理解里就是随机规划、鲁棒优化、以及预测优化。
目前最火的估计是鲁棒优化这个,从最开始的鲁棒优化,到分布式鲁棒,再到鲁棒满意度。感觉核心是在变模型,一遍遍地对偶,直到把模型变成一个可以直接求解的结构,好像是二阶锥什么的。这块一直没碰过,纯外行理解。 然后是随机规划,这个感觉上是个比较老套的内容,但是其实还挺有意思的,而且容易上手。走的是统计分析的路子,各种scenario,各种scene,各种sample什么的。大体上是SAA那些东西,还涉及到仿真验证什么的,感觉挺好玩的。 至于预测优化这个,其实前提很简单,要有数据,不管是统计学习,还是神经网络,没有数据,就压根碰不了数据驱动的东西。而且这个data不是parameter,像VRP的Solomon dataset,个人觉得不太算是数据…
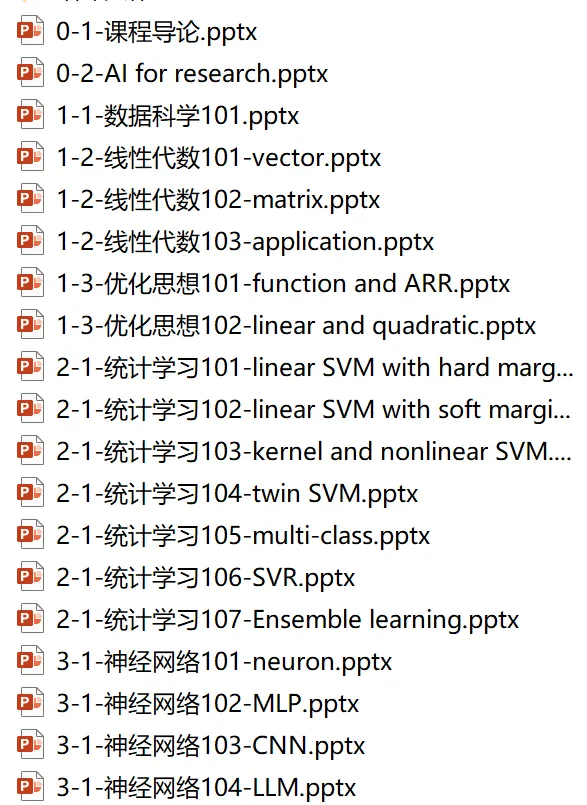
4.机器学习模型与优化
这个是在做数据科学,数据工程,数据分析了。
Again,没有数据的话不需要碰这个。
标标准准的数据分析流程,收集数据—清洗数据—特征工程—某个机器学习的模型或算法—结论—指标验证。大部分做这方面研究的学生其实是用的二手数据,基本上前面三个步骤就不需要碰了。
一般最简单的套路是给定标准数据,然后选择某个模型或算法,大部分都是python调用某个库,然后调参,然后结果分析。不管是统计学习的方法,还是神经网络的方法,绝大多数都已经被封装好了。
所以大部分学生走这条路线都是做多源数据融合,或者多种模型融合,或者是某个方法论里增加某个模块,尤其是attention的那个东西。(这个也是外行,大约理解不到位)
几个有意思的点:
模型vs算法:
统计学习的路子,从线性回归开始,逻辑回归,xx回归,分类,聚类。某些方法是属于“模型”的范畴,是可以写出来清晰的数学模型结构的,比如回归的这些,比如SVM。当然写出模型来不是重点,重点是这些模型背后都有成熟的算法来求解。某些方法是属于“算法”的范畴,比如决策树、随机森林。这个其实是规则式的处理方法,背后并没有数学模型。
相比之下,神经网络的路子,神经网络其实是属于模型,反向传播梯度下降这些属于算法。神经网络的模型早在上个世纪60年代就很成熟了,后来火起来是属于算法发展了,以及算力提升了。
而且现在的AI,大模型,transformer这些东西,是属于网络架构发生了变化,属于模型发生了变化,就是神经网络里的那些链接结构发生了变化,attention一些关键的东西就行,而非是全连接了。
现在vs未来:
机器学习这些,大致上属于engineering的范畴,目的是服务于未来,需要balance目前手头的信息,以及未来可能出现的情况,这也是训练的模型需要“泛化”的原因,这也注定了这一套东西其实不是基于当前信息进行精确求解。
相比之下,传统的运筹优化是基于给定的信息,在这些给定信息的前提下,来寻找最优解。完全不在意模型之外的东西,这也在一定程度上决定了运筹优化的东西其实跟大数据是不匹配的,信息太多了,模型根本跑不动。
调包vs数学原理
不懂背后的数学原理能做机器学习、数据分析吗?完全能,甚至在目前ai的加持下,不懂编程都可以做数据科学的东西。能掉包、能调参,能得到不错的结果,这已经很不错了。
至于学背后的数学原理是为了明白这些方法背后到底是怎么处理,怎么运算的。当一个模型对于一套数据集运行表现很好,换另外一套数据集表现不好时,也许模型需要改进,或者怎么修正,这时候就需要明白它背后到底是怎么回事。这里背后有个模型结构与数据结构匹配的事情。
以上是个人观点,仅供参考,肯定有一些表述不到位的地方。
I like math, hope it likes me back.
一审一校人员:王新颖
二审二校人员:张树柱
三审三校人员:张雷
