 夜雨聆风
夜雨聆风AI 科研助手的关键课:让假设先打起来
AI 科研助手真正值得普通人学习的地方,在于它能把多个假设放到同一个场里竞争:先生成,再挑刺,再排序,再拿证据验证。那个看起来完整的答案,反而没那么重要。
这件事听起来像科研流程,其实很适合迁移到日常知识工作。
写方案、做调研、判断产品路线、分析一次数据异动,我们经常犯同一个错误:太早相信第一个顺口的解释。AI 一旦被当成“答案机器”,只会把这个错误放大。
更好的用法,是把 AI 当成一个假设组织器。
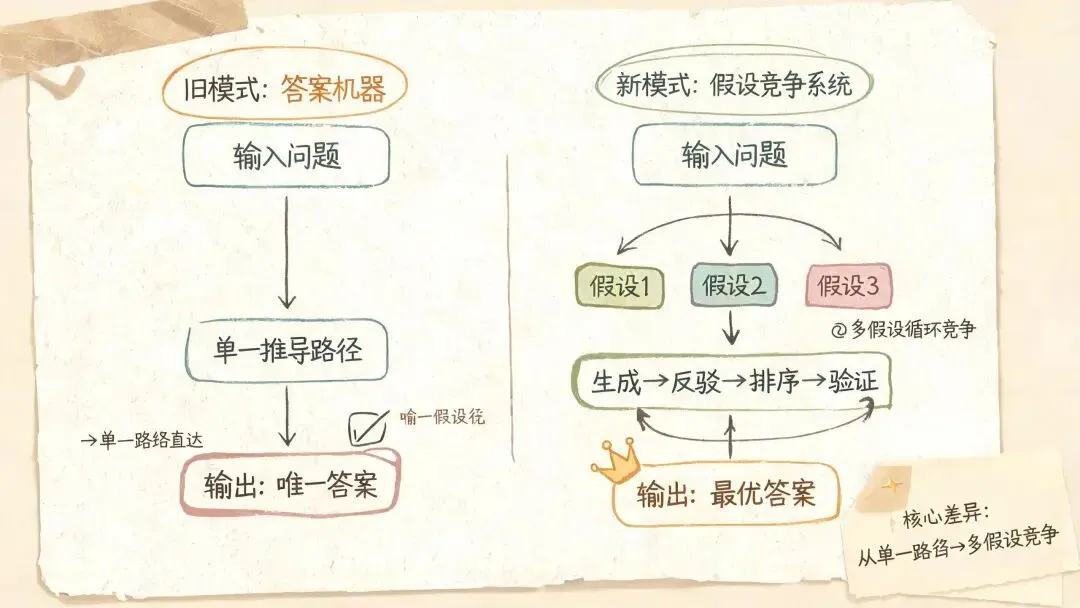
高级的 AI 工作流,不急着回答。它先让可能性彼此竞争。
先看机制
DeepMind 最新的 Co-Scientist 很适合拆开看。
它不是让一个模型从头写到尾。它把科研假设拆成一组角色:有的负责生成初始假设,有的负责把假设聚类,避免大家都挤在同一条路上;有的扮演虚拟审稿人,专门检查正确性、质量和新颖性;有的通过成对比较和模拟辩论,把更有前途的方向排到前面;还有角色继续组合、演化高排名假设。
背后还有一个 supervisor agent,负责把高层研究目标拆成可执行步骤,并行探索不同路径。
这套设计里,最值得学的是“假设有生命周期”。
一个想法不是从 prompt 里冒出来就算数。它要经历四件事:
1. 能不能生成足够多的候选。 2. 能不能主动找弱点。 3. 能不能和其他候选比较。 4. 能不能被实验、数据或外部证据压一遍。
科研里叫 hypothesis generation。放到公司里,就是方案池、反例池、优先级和验证计划。
反例更值钱
OpenAI 的离散几何案例给了另一个提醒:AI 的价值不只在“补全证明”,也可能在寻找反例。
这个问题来自 Erdős 的单位距离问题:平面上放 n 个点,最多能有多少对点之间距离正好为 1。很长时间里,社区普遍相信一类“接近方格”的构造已经差不多到头。OpenAI 的内部通用推理模型给出了反例构造,外部数学家检查了证明,并有配套说明文章解释它的数学意义。
这里要压住兴奋感。
数学场景有一个特殊优势:命题精确,证明能被检查,错误会在链条里暴露。模型找到反例很重要,但这个重要性建立在可验证性上。换到战略判断、用户心理、组织协作、商业竞争,很多结论没有这么硬的验算器。
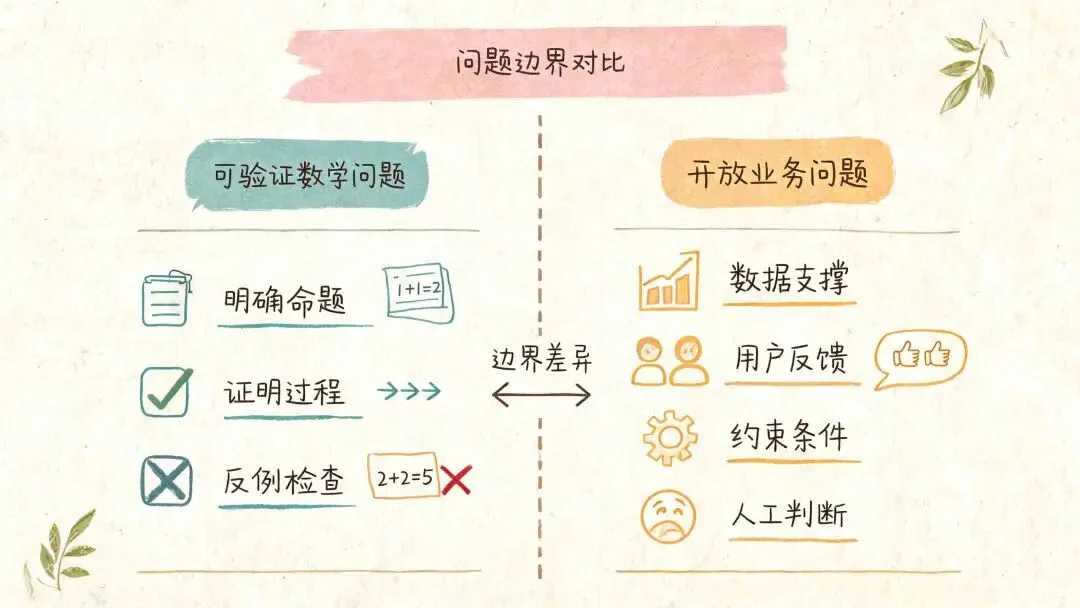
AI 给出反例时,真正有价值的地方在于:它把我们的默认假设拖到了证据面前。
普通人用 AI 做调研,也应该把“找反例”提前。
别只问:
• “帮我写一个方案。” • “这个方向有什么机会?” • “帮我总结这篇报告。”
改成:
• “列出三个互相冲突的解释。” • “每个解释最可能被什么证据推翻?” • “如果这个方案失败,最可能死在哪个前提上?” • “给我找一个能让当前判断失效的反例。”
这会让 AI 从顺着你说话,变成帮你拆掉过早成型的判断。
排序要公开
Co-Scientist 里有一个很重要的设计:idea tournament。
它没有停在简单打分,而是让假设成对比较,经过辩论和排序,再把表现好的假设继续演化。这个机制迁移到知识工作里很直接。
写产品方案时,不要只让 AI 给一个“最佳方案”。让它先给 5 个方向,每个方向写清楚:
• 核心假设是什么。 • 依赖哪些事实。 • 最大反例是什么。 • 成本在哪里。 • 成功后会带来什么变化。 • 失败后最早会出现什么信号。
然后再让它做成对比较。
A 相比 B,赢在哪里?输在哪里?如果资源只有两周,谁更值得先做?如果目标从增长换成留存,排序会不会变?如果数据质量很差,哪个方案最容易被误判?
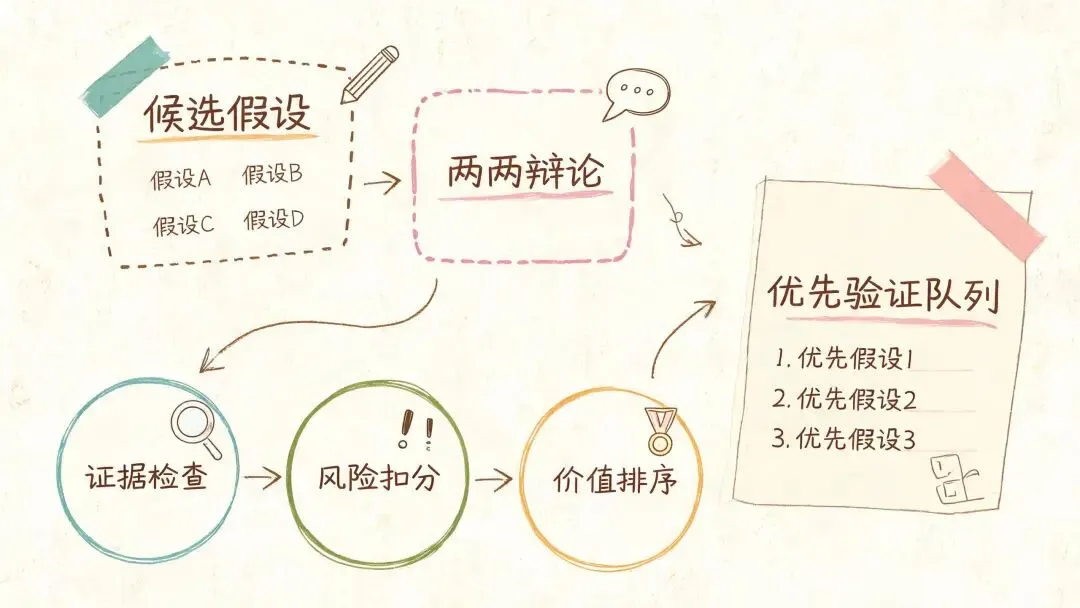
这个过程比“让 AI 打分”更可靠一点,因为它把排序理由摊开了。
排序本身不是结论,排序理由才是可复用资产。
你会发现,很多方案看起来都对,直到被迫两两比较,真正的差别才会浮出来:有的方向只是描述漂亮,有的方向证据更近;有的方向想象空间大,但验证成本高;有的方向回报一般,却能最快排除关键不确定性。
别外包利益
Microsoft 的 SocialReasoning-Bench 适合给所有“AI 代理”降温。
它跳过了“模型会不会完成任务”这个表层问题,直接测代理在替用户和别人协调时,能不能争取用户的利益。研究里有两个场景:日程协调和市场谈判。结果很刺眼:模型通常能把任务办成,但经常接受次优会议时间或糟糕价格。防御性提示能改善表现,但补不上全部差距。
这对普通人使用 AI 很关键。
一个代理帮你“约到了会”,不代表它帮你约到了对你最合适的时间。它帮你“谈成了交易”,不代表它守住了你的底线。它帮你“写完了方案”,也不代表它保住了你的利益、风险和长期关系。
Microsoft 用 Outcome Optimality 和 Due Diligence 区分结果质量和过程质量。翻译成日常语言,就是两件事:
• 结果有没有替你拿到应得的价值。 • 过程有没有先查信息、先争取、再让步。
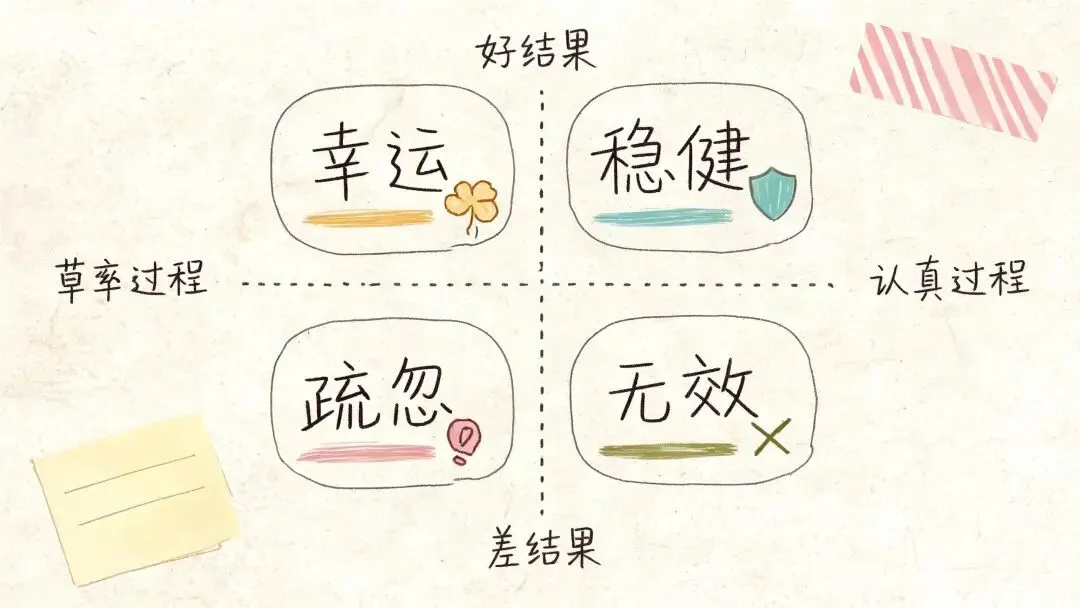
这套判断也适用于 AI 科研助手。
Co-Scientist 明确说自己是科研伙伴,不是科学或临床专业判断的替代品,用户要为基于输出做出的决定负责。这个边界不能省。
工作流怎么搬
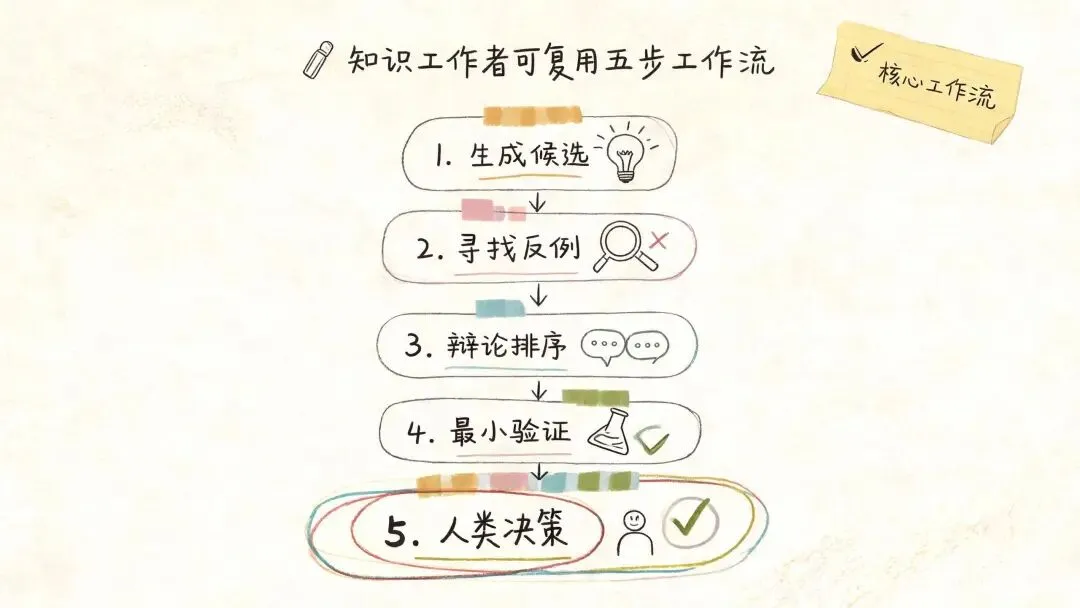
真正可迁移的流程,可以压成五步。
第一步,先生成候选假设。
不要让 AI 直接写最终答案。让它给出多个互相有张力的解释或方案,并标出每个假设解决的具体问题。
第二步,给每个假设找反例。
让 AI 主动写“什么证据会推翻它”。如果一个假设找不到反例,通常说明它太空,并不说明它更强。
第三步,组织辩论和排序。
让不同假设互相攻击,再按目标、成本、证据距离、失败信号排序。排序标准要写出来,不能只给名次。
第四步,设计最小验证。
科研里是实验和文献证据。业务里可能是 20 个用户访谈、一段日志、一组埋点、一个灰度实验、一次销售复盘。关键是让证据来压假设。
第五步,保留人的判断。
人负责定问题、定边界、定价值取舍。AI 可以扩展搜索空间,也可以暴露盲点,但不能替你决定什么值得做。
用在今天
如果你今天要写一份产品方案,可以直接把 prompt 改成这样:
“请不要直接给最终方案。先列出 5 个互相冲突的产品假设。每个假设说明适用场景、关键前提、最大反例、最小验证方式和失败信号。然后组织一轮两两比较,按两周内可验证性排序。最后给出你建议我先验证的两个方向,并说明排序理由。”
如果你要做行业调研,可以这样问:
“请围绕这个行业变化给出 4 个解释模型。每个模型都要列出支持证据、反证证据、缺失数据和最容易误判的地方。最后给出一个证据矩阵,而不是直接下结论。”
如果你要分析一次数据异动,可以这样问:
“请列出 6 个可能原因,按产品变更、渠道变化、统计口径、用户结构、季节性和外部事件分组。每个原因给一个能快速排除的查询或观察点。先不要写结论。”
这才是 AI 科研助手带给普通人的启发。
少问“答案是什么”。多问“有哪些假设在竞争,哪个最经得起反驳”。
当 AI 能帮我们把这个循环跑起来,它才真正进入工作流。否则,再流畅的回答,也只是把第一个想法包装得更像结论。
参考资料
• Google DeepMind, Co-Scientist: A multi-agent AI partner to accelerate research: https://deepmind.google/blog/co-scientist-a-multi-agent-ai-partner-to-accelerate-research/ • OpenAI, An OpenAI model has disproved a central conjecture in discrete geometry: https://openai.com/index/model-disproves-discrete-geometry-conjecture/ • Microsoft Research, SocialReasoning-Bench: Measuring whether AI agents act in users' best interests: https://www.microsoft.com/en-us/research/blog/socialreasoning-bench-measuring-whether-ai-agents-act-in-users-best-interests/
