 夜雨聆风
夜雨聆风故事是这样的。
你写了个爬虫脚本,满怀期待地跑起来,结果还没爬几页,就被Cloudflare拦住了。「请验证您是人」。你换个IP,再试一次,还是被拦。你加了代理池,还是不行。你甚至花钱买了专业爬虫服务,结果人家也告诉你,「这个网站反爬太强,搞不了」。
这不是个例。Cloudflare、FingerprintJS、BrowserScan,这些检测工具像一堵墙,挡在你和数据之间。你明明只是想做个竞品监控、搞个数据分析,结果却被当成「机器人」对待。
README页的GIF,就是Cloudflare的Turnstile验证。看着很酷对吧?但对于爬虫开发者来说,这就是噩梦。
所以当我看到CloakBrowser这个项目时,当时就愣住了。
22k Stars,30/30测试全过。
这不是夸张,是实测数据。项目作者拿了30多个检测站点,一个个跑过去,结果全部通过。Cloudflare Turnstile、FingerprintJS、BrowserScan、reCAPTCHA,这些曾经拦住无数爬虫的工具,现在都认不出它。
怎么做到的?
不是简单的改个User-Agent、加个代理就能搞定的。CloakBrowser做的是源码级修改。
58个C++补丁。
这数字听着有点吓人,但确实是这么干的。作者直接修改了Chromium的源码,针对canvas指纹、WebGL渲染、音频指纹、字体检测、GPU信息、屏幕参数、WebRTC泄漏、网络时序等各个方面,一个个修复。每个补丁都是针对具体的检测点,从根本上抹掉「自动化痕迹」。
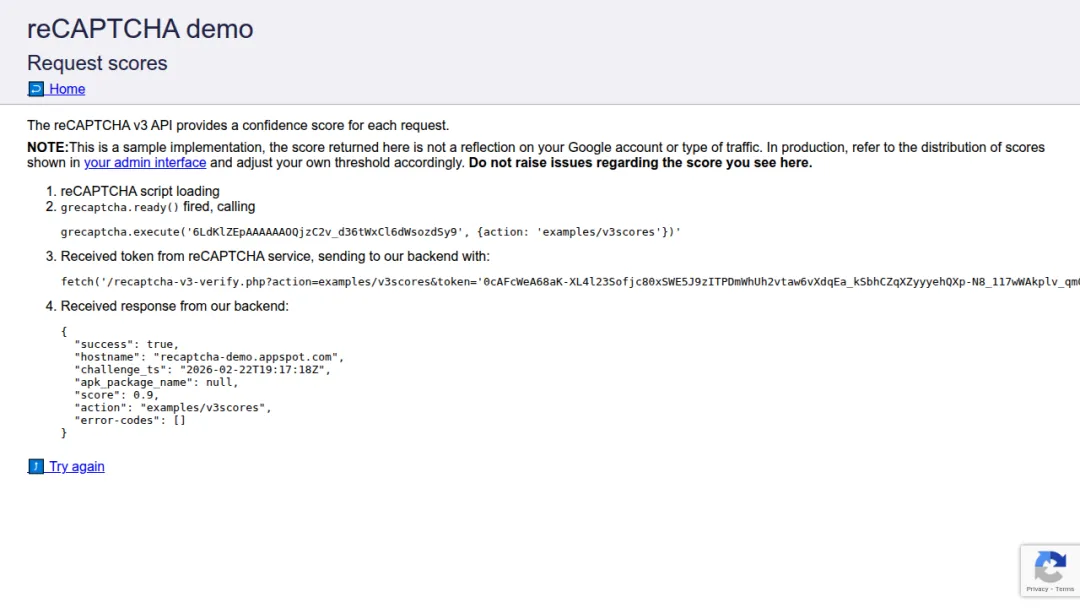
上面这张截图,是reCAPTCHA v3的检测结果。分数0.9。你可能不知道这分数代表什么,我解释一下。reCAPTCHA v3的评分范围是0到1,分数越高说明「越像真人」。一般人类用户的分数在0.7-0.9之间,低于0.5就会被判定为机器人。CloakBrowser拿到了0.9,这个分数甚至比很多真人用户还要高。
而且这个分数不是本地检测,是服务器端返回的。Google的验证服务器都认不出它是自动化浏览器。
还有个细节让我印象很深。
BrowserScan的检测结果,四个维度全过。WebRTC没有泄漏真实IP,Canvas指纹没有异常,AudioContext指纹正常,Font指纹也通过。四个检查项,全部显示NORMAL。。。
说到这,你可能有个疑问。这些检测工具,到底在检测什么?
我简单解释一下。
浏览器指纹。就像人的指纹一样,每个浏览器都有自己独特的「指纹」。Canvas指纹,通过Canvas API的渲染差异来识别。WebGL指纹,通过GPU型号和渲染能力来识别。Audio指纹,通过AudioContext的音频处理差异来识别。Font指纹,通过系统安装的字体列表来识别。
这些指纹组合起来,就形成了一个「浏览器ID」。即使你换了IP、清了Cookie,只要指纹不变,检测工具照样能认出你。
传统的反爬虫方案,大多是在应用层做伪装。改User-Agent、禁用WebDriver标记、模拟鼠标移动。但这些只是表面功夫,底层指纹还是暴露的。
CloakBrowser的思路完全不同。直接从源码层面抹掉指纹,让浏览器本身就没有「自动化痕迹」。这不是伪装,是真正的隐身。
还有个功能叫humanize。
这个功能让鼠标移动、键盘输入、滚动行为都更像真人。不是简单的随机延迟,而是模拟真实的人类操作模式。鼠标曲线有自然的弧度和停顿,键盘输入有节奏变化,滚动有惯性。
你可能会说,这些功能之前也有工具做过啊。但CloakBrowser的不同之处在于,它是Playwright的直接替代品。
三行代码就能用。
from cloakbrowser import launch
browser = launch(humanize=True)
page = browser.new_page()就这样。不需要复杂的配置,不需要额外的脚本。你原本用Playwright写的爬虫代码,几乎不用改,直接换成CloakBrowser就行。
而且它还支持Puppeteer API。如果你用的是JavaScript,也一样能用。
说到应用场景,其实很广。
数据采集。如果你需要从竞争对手网站抓价格、抓评论、抓商品信息,CloakBrowser能帮你绕过那些恼人的验证码。不是靠破解验证码,而是根本不触发验证码。
自动化测试。如果你在做前端自动化测试,很多网站会检测自动化浏览器,导致测试失败。CloakBrowser能让你的测试脚本像真人一样运行,不会被拦截。
竞品监控。如果你需要长期监控某个网站的变化,CloakBrowser的自动更新功能也能帮到你。它会在后台自动检查更新,保持最新的反检测能力。
当然,也有需要注意的地方。
CloakBrowser是MIT许可,完全开源免费。但使用它还是要遵守目标网站的服务条款。反检测技术只是工具,怎么用取决于使用者。如果用来做恶意爬取、数据窃取,那还是会涉及法律问题。
而且,反检测和检测本身就是一场持久战。检测工具也在不断升级,CloakBrowser也需要持续更新来应对新的检测手段。项目目前还在活跃开发中,已经有了自动更新机制,但长期效果还需要观察。
不过,从目前的数据来看,22k Stars、30/30测试全过、0.9的reCAPTCHA分数,这些硬指标确实让人印象深刻。
这项目的出现,某种程度上打破了反爬虫检测的「神话」。之前很多人觉得这些检测工具是无解的,只能花钱买服务或者手动采集。但CloakBrowser证明了,源码级的指纹修复是可行的。
而且它是开源的。任何人都可以查看代码、理解原理、甚至参与改进。这种透明度,比那些闭源的商业爬虫服务要靠谱得多。
如果你也在做数据采集、自动化测试,或者单纯对反检测技术感兴趣,可以看看这个项目。GitHub上已经有22k Stars,说明很多开发者都在关注。
开源的价值,不仅是免费,更是知识共享。CloakBrowser把反检测的技术细节公开出来,让更多人能理解、能学习、能改进。这才是技术社区最珍贵的东西。
