 夜雨聆风
夜雨聆风最近蓝翼在研究 MiMo 模型的套餐定价——旧套餐一个月 328 元买 7 亿 Credit,新套餐一个月 328 元买 380 亿 Credit。乍看新套餐「碾压」,但计费方式完全不同:旧套餐统一单价,新套餐按 Input Hit / Input Miss / Output 三类分别计价,其中未命中的单价高达 300 credit/token、输出更是达到了 600 credit/token。到底哪个划算?
蓝翼心想,这笔账不算复杂,但数字不少;于是蓝翼干了一个让所有 LLM 都恶心的活儿:让它们做算术题。蓝翼找了当下主流的 14 个 AI 模型,把同一套账丢给它们算。结果,还真有些出乎意料。
蓝翼用 MiMo 的真实账单数据设计了一套试卷,6 道大题、满分 100 分:
第一题(10 分):数据校验——验证三行 totalToken 是否等于 Input Hit + Input Miss + Output,相当于「加法验算」
第二题(15 分):汇总统计——把 MiMo-V2.5-Pro 模型 13 天的使用数据逐行求和,算出总 Input Hit、总 Input Miss、总 Output、总 Token、总请求次数
第三题(15 分):旧套餐费用计算——统一单价,总 Token × 单价,判断 7 亿额度够不够用
第四题(25 分):新套餐费用计算——分类计费,Hit × 2.5 + Miss × 300 + Output × 600,再汇总一下,判断 380 亿额度够不够用
第五题(15 分):混合成本分析——两个套餐各自的「每 Token 成本」,以及 328 元能买多少 Token
第六题(20 分):综合对比——做个新旧套餐对比表,分析成本效益和风险,给出推荐
考题附了完整的参考答案,一到五题全都是客观题,第六题则是主观题。蓝翼把这同一份试卷分别投给了 14 个 AI 模型,AI 们大显神通,有的干脆开启了代码模式,让人叹为观止。然后蓝翼逐题对照参考答案打分。
十四个 AI 可以说是囊括了国内外人工智能的当家花旦:Anthropic 的 Claude 家族 Opus 4.8、Opus 4.7、Opus 4.6、Sonnet 4.6,OpenAI 的 GPT-5.5,Google 的 Gemini 3.5 Flash、Gemini 3.1 Pro,国产的 GLM-5.1、Qwen 3.7 Max、Qwen 3.6 Plus、DeepSeek Pro、DeepSeek Flash、MiniMax 2.7,以及小米自己家的 MiMo 2.5 Pro。
讲真,蓝翼本以为这考试对 AI 来说应该是轻松满分。毕竟是加减乘除,没有微积分,连方程都不用解。
结果呢?14 个模型里,只有 7 个拿到了满分 100 分。
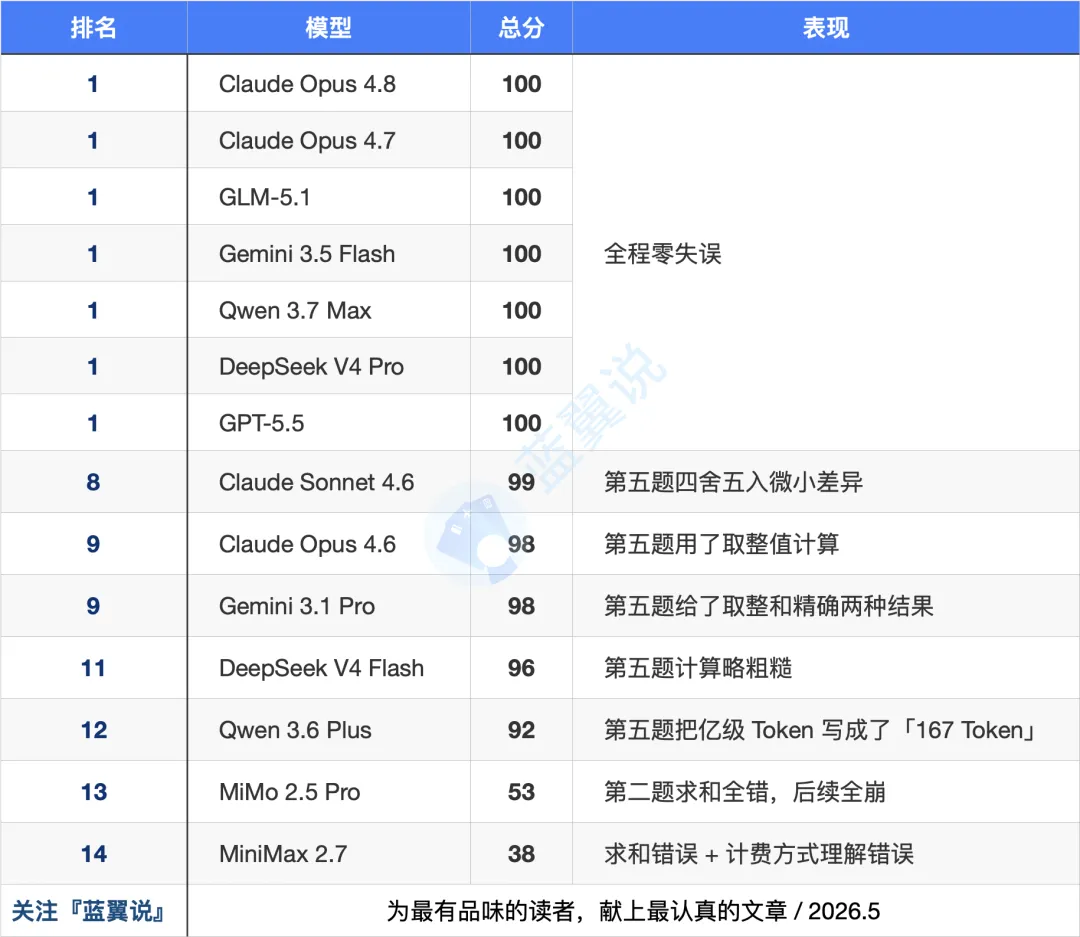
决定成败的不是什么高深的推理能力,而是第二题那个最朴素的操作:把 13 行八位数的数字逐行加起来。能过这一关的模型,后面四道题基本一路畅通;过不了的,从第二题开始就带着错误数据一路往下算,第三、四、五题全部偏离参考答案。而且没有一家在后续题目中自我修正。换句话说,AI 会认真执行每一步计算,但不会回头问一句:「等等,这个数字对吗?」
先说最讽刺的:MiMo 算不好自己的账。
MiMo 2.5 Pro 是被测模型之一,但它连自家 billing 数据的 13 行求和都没算对。Input Hit 参考答案是 255,099,264,它算出了 255,119,064;连请求次数都数错了(3,534 vs 正确的 3,334)。更要命的是,这个错误一路传导到第三、四、五题,最终 53 分,不及格。
MiniMax 2.7 的问题更严重。不止求和出错,它还把旧套餐的计费规则理解错了。旧套餐是「统一单价」(pro 按 2、v2.5 按 1),它算成了各类都乘以 2。结果得出了「7 亿额度不够用」的结论,和参考答案完全相反。到了第五题,新套餐 328 元只能买 2.12 亿 Token,比旧套餐的 3.55 亿还少。这么荒谬的数字,它竟然没察觉到矛盾。
Qwen 3.6 Plus 前四题全对,眼看就要满分。结果第五题把「约 3.55 亿 Token」写成了「167 Token」——明显是算出了 328 ÷ 1.97 ≈ 166.5,然后直接当结果写了,丢了亿级单位。从 100 分掉到 92 分,只能说可惜。
还有一个观察值得说一下:第六题是唯一的主观分析题,即使前面数据全错的模型,分析框架和推荐逻辑也基本合理。MiMo 2.5 Pro 给出了「新套餐更划算」的正确推荐,MiniMax 2.7 的风险分析框架也没毛病。推理能力和计算能力大概是两个独立维度,算不对数不影响想明白道理。
如果把这次测试比作选信用卡:满分的 7 个模型就像那些「无脑推荐」的好卡,权益扎实、年费合理,闭眼选就行。96-99 分的 4 个模型是「基本够用但有微小瑕疵」,不影响核心判断,细节控可能会在意。
Qwen 3.6 Plus 像一张「活动很好但偶尔翻车」的卡,大部分时候靠谱,但偶尔来个「167 Token」式的操作让人哭笑不得。MiMo 2.5 Pro 和 MiniMax 2.7 就像权益严重缩水的卡,连基本功都不过关,用起来还得自己再验算一遍,反而更费时间。
这次测试让蓝翼感触最深的是:AI 推理是一把好手,基本功却频频翻车。
13 行数字的加法,人类用 Excel 五秒钟就能验证。但当 AI 在这个环节翻车时,后续所有的分析、建议、推荐都变成了空中楼阁,而且它自己完全不知道。
类似的还有数据搜集。如果你没有喂给它靠谱的来源,AI 有时候会编造一个看上去很真的源头,这也是现阶段 AI 最主要的幻觉。
所以蓝翼建议:用 AI 算账没问题,但关键数据一定要自己验一遍。 尤其是汇总、求和这类看似简单的操作,恰恰是 AI 最容易出错的地方。至于那 7 个满分选手嘛,至少在算账这件事上,它们是靠谱的。
大家平时用 AI 做计算多吗?有没有翻车的经历?留言里聊聊吧。
本文测试基于蓝翼自己的使用场景和数据,仅代表个人观点,不代表对任何模型的全面评价。
分享、点赞、在看三连起来!
