 夜雨聆风
夜雨聆风
谱学作为物质结构鉴定、表征、测量、预测的"基本工具",在新材料发现、药物筛选及生命科学研究中发挥着不可替代的作用。近年来,人工智能大模型为谱学数据的智能化分析开辟了新路径,然而该领域研究长期面临四大核心瓶颈:高质量实验数据稀缺且类别失衡、计算光谱与真实实验环境存在显著域间鸿沟、不同光谱模态(如IR、NMR、MS)难以统一对齐,以及缺乏标准化基准导致模型评估碎片化等问题,严重制约了谱学智能从"单点突破"迈向"系统创新"。
针对上述瓶颈,上海人工智能实验室携手中国科学技术大学等机构推出谱学智能研究平台SpectrumWorld。该平台致力于打通“数据生成→模型评测→能力迭代”的全链路,提供可复现、可对齐的AI基础设施,全面赋能谱学智能迈向系统创新。
研究人员通过SpectrumWorld对23个大模型开展评测,结果显示:当前模型普遍在信号层基础感知能力已趋成熟(任务平均准确率达66.96%),但在生成层任务准确率骤降至10.07%,逆向推理与分子生成仍是主要短板。这一"能力断层"揭示:大模型已具备"看懂光谱"的潜力,但要达到"用光谱推理化学"仍需深度融合领域知识与科学推理机制。
值得关注的是,书生科学大模型(Intern-S1)综合准确率达65.37%,逼近闭源模型Gemini-2.5-pro(67.81%),并在分子结构解析(90.00%)、光谱-分子逆向推理(40.00%)等高难任务上表现领先,为光谱智能从"模式识别"迈向"科学推理"提供了关键基准与优化方向。
SpectrumWorld已通过GitHub、Hugging Face等在线开源平台面向全球研究者开放,支持多模型统一接入、可复现评测与持续扩展,推动光谱智能从"单点刷分"走向"系统迭代"。该工作已被KDD 2026接收,论文第一作者为上海人工智能实验室实习生杨卓与谢嘉庆。
核心代码:
https://github.com/InternScience/SpectrumLab
项目主页:
https://spectrumworld.github.io/(含论文、数据、使用平台等)
谱学智能评测为何需要『统一基座』?
化学家读谱并不是简单“看图”,而是遵循一条逐步递进的认知链条:先看清谱图信号,再识别峰型与化学模式,进一步推断分子结构,最后才能进行逆向解析或分子设计。但当 GPT、Gemini、Qwen-VL 等多模态大模型进入光谱场景时,领域仍面临四类结构性瓶颈:
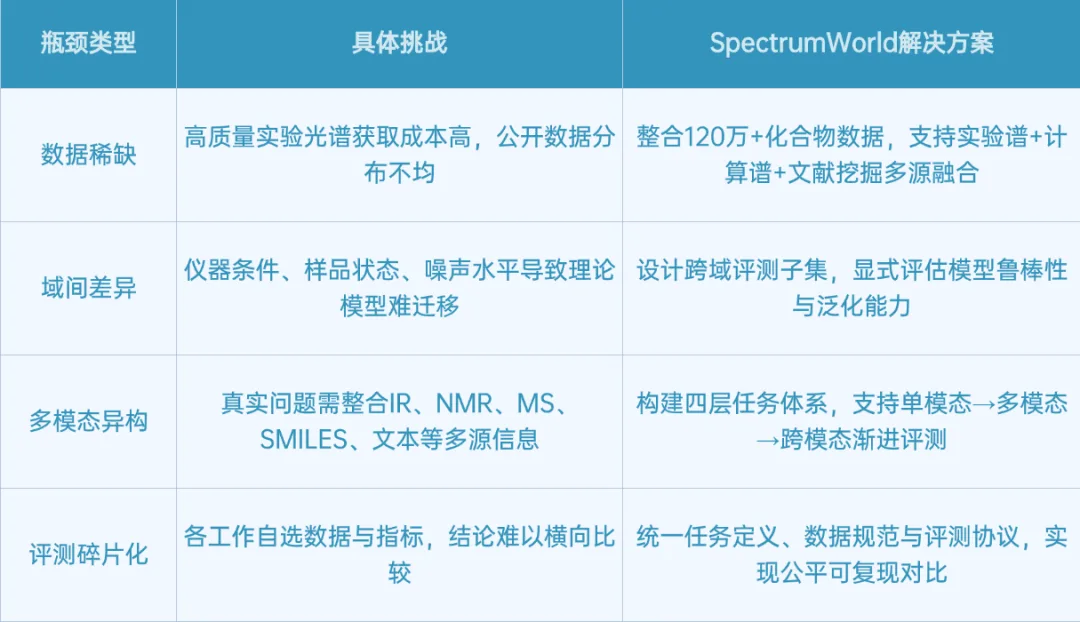
SpectrumWorld 的目标不是提出一个新的单点模型,也不只是构建一个新的排行榜,而是回答一个更基础的问题:光谱领域的 AI 应当如何被系统地训练、评测、比较和迭代?
创新架构:三大模块闭环,构建可扩展评测生态
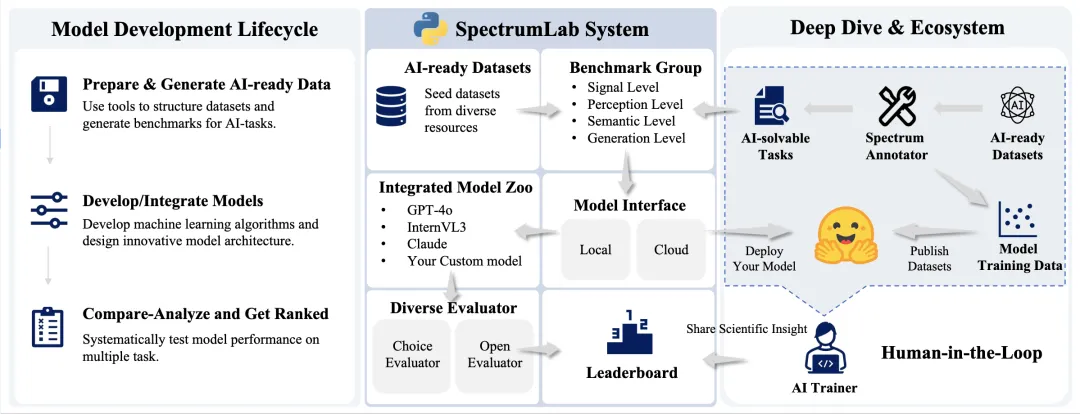
SpectrumWorld由三大核心模块构成:
SpectrumLab,模块化Python平台,集成数据处理、模型接入与评估工具链,显著降低光谱AI研发门槛;
SpectrumAnnotator,基于多模态大语言模型的自动标注引擎,通过"零样本推理+专家闭环校验"高效生成高质量基准数据;
SpectrumVQA,覆盖14项任务、10+光谱类型、120万+化合物的多层基准套件,可首次系统量化23个前沿大模型在光谱理解与生成任务中的能力图谱。
SpectrumVQA:模拟化学家读谱过程的四层任务体系
SpectrumVQA 模拟化学家读谱的认知流程,将 14 个子任务组织为四个层级,考察模型的多维能力:
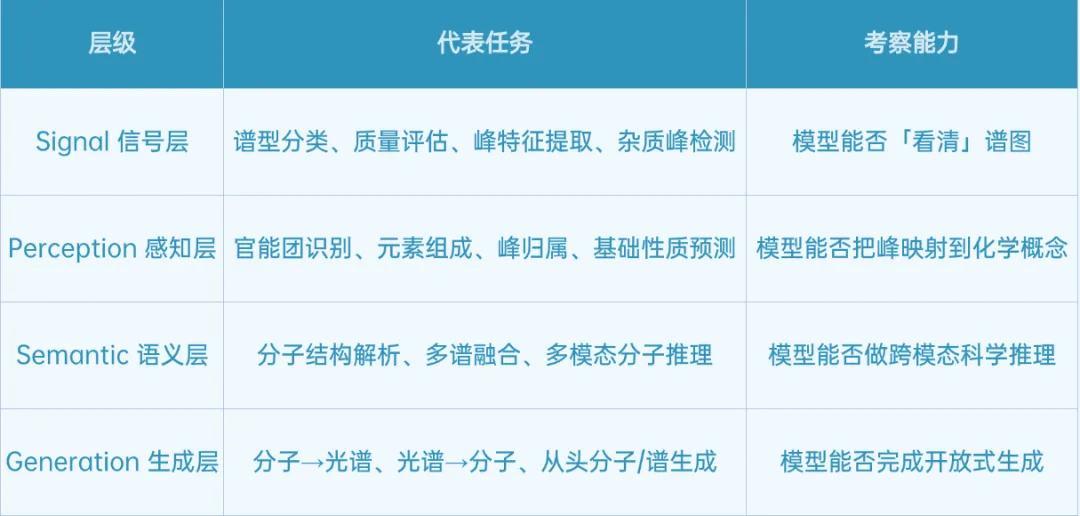
当前 SpectrumVQA 共包含 572 道评测题,覆盖 IR、NMR、MS、Raman 等 10+ 类光谱类型,相关数据来自 120 万+ 化学物质数据的整合与处理。
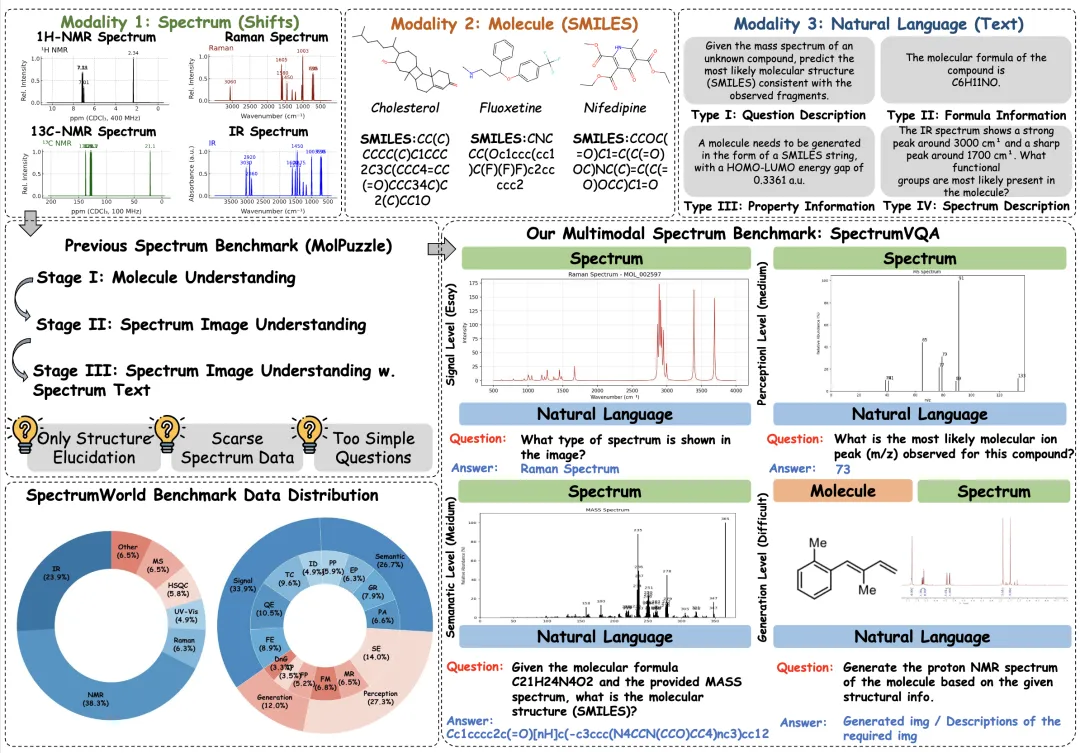
SpectrumAnnotator:让评测基准可持续生长
高质量评测数据的难点不只是“攒数据”,更在于如何构造科学合理、可自动验证、可持续扩展的问题与答案。为此,SpectrumAnnotator 将合作实验室实验谱、公开数据库和期刊补充材料等多源数据纳入统一流程,并通过模板生成、自动质检和专家复核形成闭环。其核心流程包括:
种子数据整理 → 合作实验室实验谱(约 23.9 万个分子数据点,覆盖 8 类光谱)+ SDBS、QM9S、NovoBench 等公开库(100 万+ 化合物)+ 期刊补充材料挖掘
任务模板生成 → YAML 配置驱动,结合分子元数据自动生成选择题
自动解析与质检 → SpectrumVerifier 过滤格式错误、图文不一致样本
专家复核 → 复杂样本人工把关,形成闭环
因此,SpectrumVQA 不是一次性的静态数据集,而是一个可以随着新数据、新光谱类型和新任务持续扩展的评测生成框架。
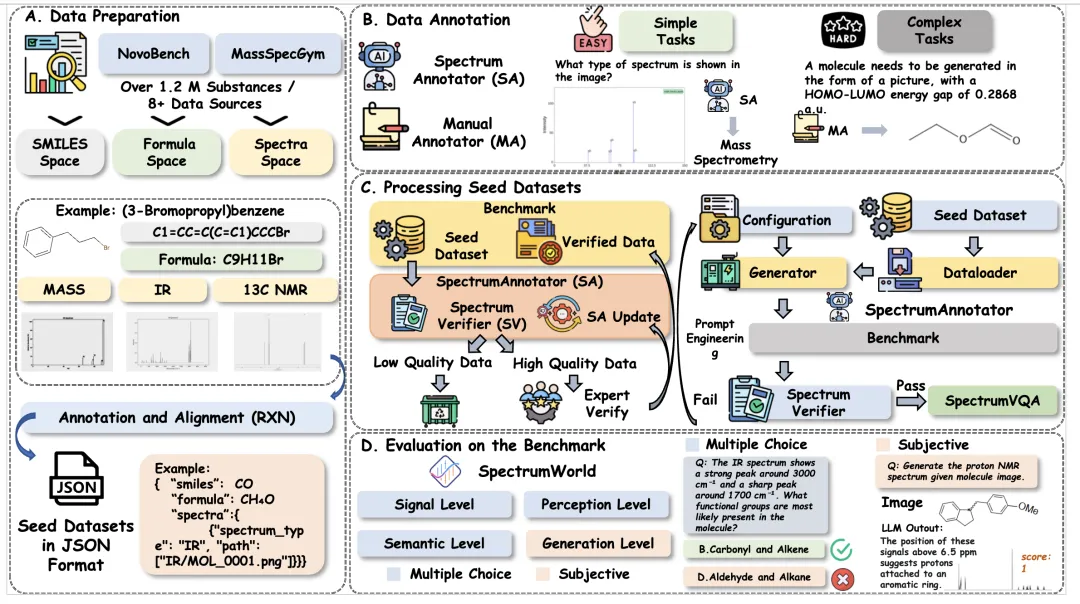
SpectrumLab:一次性评测到持续迭代的工具链
SpectrumLab 提供评测数据管理、多模型统一接入、选择题/开放式评测器、CLI 评测与公开排行榜。研究者可快速加载指定层级/子任务,在统一协议下接入自有模型或 API 服务,实现可复现对比。
大模型评测:会看谱,推理仍是短板
基于 SpectrumWorld,研究团队对 23 个主流开源与闭源多模态大模型进行了系统评测,覆盖 GPT-4o、Claude、Gemini、Qwen-VL、InternVL、GLM、Doubao 等代表性模型。评测结果显示,当前模型在基础识别任务上已有一定能力,但在复杂结构推理和生成类任务上仍存在明显差距。
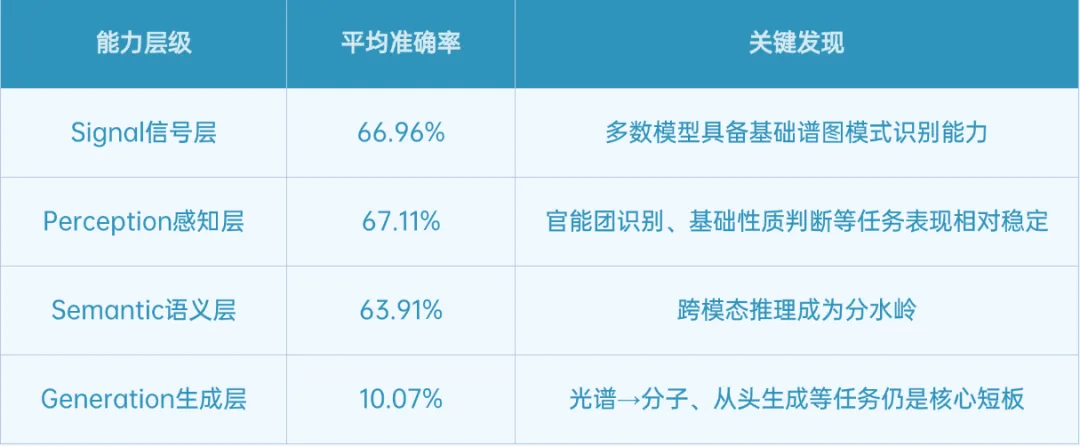
这说明当前模型已经能够识别不少谱图模式,但距离真正完成“峰位—官能团—分子式—结构”的多步科学推理仍有距离。
从整体榜单看,闭源模型仍保持领先,但开源模型已经明显逼近。Gemini-2.5-pro 以 67.81% 的综合准确率位列第一,InternVL3.5-241B 达到 65.50%,与闭源最优模型差距约 2.31 个百分点。与此同时,具备显式推理过程的模型在高阶任务上普遍表现更好,表明多步推理能力可能是光谱科学任务中的关键变量。
书生 Intern-S1:在光谱科学任务上展现科学推理优势
SpectrumWorld 的价值不仅在于给出总分排名,更在于揭示模型在不同认知层级上的能力差异。以 Intern-S1 为例,其 thinking 模式在结构解析、逆向推理和性质/结构预测相关任务上表现突出,显示出面向科学场景强化推理能力的重要性。
综合性能稳居第一梯队
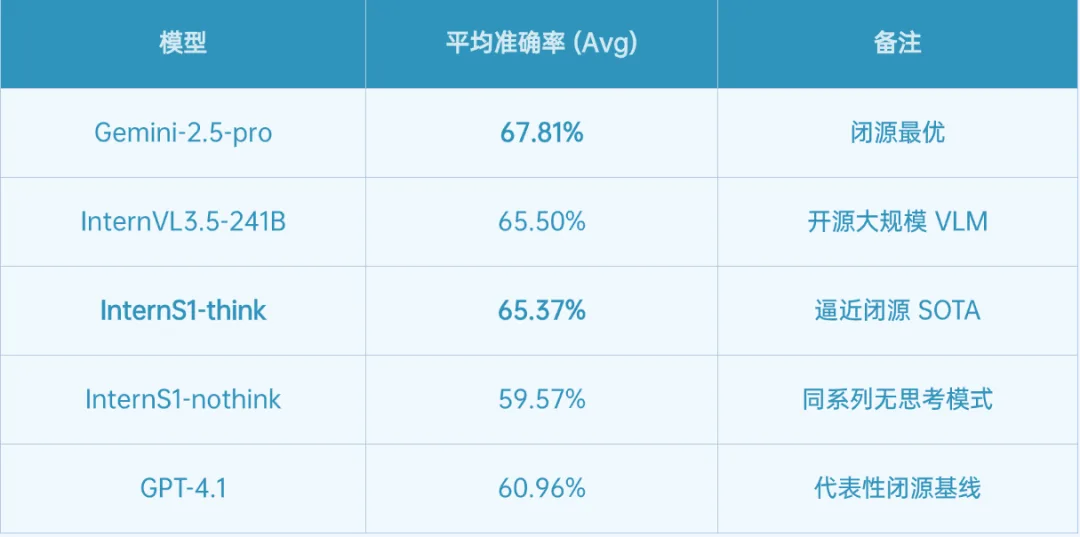
InternS1-think 以 65.37% 的综合准确率位列参评模型前三,与最优闭源模型 Gemini-2.5-pro 的差距仅约2.44 个百分点。开启思考模式后,相较 InternS1-nothink(59.57%)提升约 5.8 个百分点,说明多步推理对光谱这类「证据链很长」的科学任务至关重要。
高难度任务上的突出表现
在化学家最关心的结构解析与逆向推理上,Intern-S1 优势更为明显:
- 分子结构解析(SE):InternS1-think 达 90.00%,为参评模型中的顶尖水平之一;
- 逆向问题(IP,光谱→分子):InternS1-think 40.00%,大幅领先多数模型(大量模型在该项接近 0%);
- 从头生成(DnG):InternS1-think 15.79%,在 Generation 层整体平均仅 6.41% 的背景下仍表现突出。
误差分析:性质预测任务族表现领先
误差分析进一步显示,Intern-S1 在性质/结构预测相关任务上的错误率较低。在性质预测任务中,Intern-S1 的错误率为 10.5%,低于 InternVL-3.5 的 13.2%。这表明它在“从谱图证据推断分子性质或结构”这一环节上具有更稳定的跨模态映射能力。
> 解读:光谱 AI 的瓶颈不仅是「图像识别」,更是峰位—官能团—分子式—结构之间的多步符号整合。Intern-S1 的 thinking 模式使其在结构解析、逆向推理等需要多步证据整合的科学任务上体现出优势。
推理能力:Generation 层的「分水岭」
除 Intern-S1 外,实验还显示:显式增强推理的模型,在生成类任务上优势显著。 类似地,Doubao-1.5-Vision-Pro-Thinking 在 Forward Problems 上达到66.67%,也说明 reasoning 能力是生成类光谱任务的关键变量。
Intern-S1 在科学推理任务中的突出表现印证了:为光谱场景注入深度推理能力,是突破当前瓶颈、提升模型科学可靠性的关键路径。SpectrumWorld 的核心使命,正是将这些隐性的能力差异“显性化”、标准化,并精准转化为下一代模型迭代的导航图。
谱学作为物质结构鉴定、表征、测量、预测的"基本工具",在新材料发现、药物筛选及生命科学研究中发挥着不可替代的作用。近年来,人工智能大模型为谱学数据的智能化分析开辟了新路径,然而该领域研究长期面临四大核心瓶颈:高质量实验数据稀缺且类别失衡、计算光谱与真实实验环境存在显著域间鸿沟、不同光谱模态(如IR、NMR、MS)难以统一对齐,以及缺乏标准化基准导致模型评估碎片化等问题,严重制约了谱学智能从"单点突破"迈向"系统创新"。
针对上述瓶颈,上海人工智能实验室携手中国科学技术大学等机构推出谱学智能研究平台SpectrumWorld。该平台致力于打通“数据生成→模型评测→能力迭代”的全链路,提供可复现、可对齐的AI基础设施,全面赋能谱学智能迈向系统创新。
研究人员通过SpectrumWorld对23个大模型开展评测,结果显示:当前模型普遍在信号层基础感知能力已趋成熟(任务平均准确率达66.96%),但在生成层任务准确率骤降至10.07%,逆向推理与分子生成仍是主要短板。这一"能力断层"揭示:大模型已具备"看懂光谱"的潜力,但要达到"用光谱推理化学"仍需深度融合领域知识与科学推理机制。
值得关注的是,书生科学大模型(Intern-S1)综合准确率达65.37%,逼近闭源模型Gemini-2.5-pro(67.81%),并在分子结构解析(90.00%)、光谱-分子逆向推理(40.00%)等高难任务上表现领先,为光谱智能从"模式识别"迈向"科学推理"提供了关键基准与优化方向。
SpectrumWorld已通过GitHub、Hugging Face等在线开源平台面向全球研究者开放,支持多模型统一接入、可复现评测与持续扩展,推动光谱智能从"单点刷分"走向"系统迭代"。该工作已被KDD 2026接收,论文第一作者为上海人工智能实验室实习生杨卓与谢嘉庆。
核心代码:
https://github.com/InternScience/SpectrumLab
项目主页:
https://spectrumworld.github.io/(含论文、数据、使用平台等)
谱学智能评测为何需要『统一基座』?
化学家读谱并不是简单“看图”,而是遵循一条逐步递进的认知链条:先看清谱图信号,再识别峰型与化学模式,进一步推断分子结构,最后才能进行逆向解析或分子设计。但当 GPT、Gemini、Qwen-VL 等多模态大模型进入光谱场景时,领域仍面临四类结构性瓶颈:
SpectrumWorld 的目标不是提出一个新的单点模型,也不只是构建一个新的排行榜,而是回答一个更基础的问题:光谱领域的 AI 应当如何被系统地训练、评测、比较和迭代?
创新架构:三大模块闭环,构建可扩展评测生态
SpectrumWorld由三大核心模块构成:
SpectrumLab,模块化Python平台,集成数据处理、模型接入与评估工具链,显著降低光谱AI研发门槛;
SpectrumAnnotator,基于多模态大语言模型的自动标注引擎,通过"零样本推理+专家闭环校验"高效生成高质量基准数据;
SpectrumVQA,覆盖14项任务、10+光谱类型、120万+化合物的多层基准套件,可首次系统量化23个前沿大模型在光谱理解与生成任务中的能力图谱。
SpectrumVQA:模拟化学家读谱过程的四层任务体系
SpectrumVQA 模拟化学家读谱的认知流程,将 14 个子任务组织为四个层级,考察模型的多维能力:
当前 SpectrumVQA 共包含 572 道评测题,覆盖 IR、NMR、MS、Raman 等 10+ 类光谱类型,相关数据来自 120 万+ 化学物质数据的整合与处理。
SpectrumAnnotator:让评测基准可持续生长
高质量评测数据的难点不只是“攒数据”,更在于如何构造科学合理、可自动验证、可持续扩展的问题与答案。为此,SpectrumAnnotator 将合作实验室实验谱、公开数据库和期刊补充材料等多源数据纳入统一流程,并通过模板生成、自动质检和专家复核形成闭环。其核心流程包括:
种子数据整理 → 合作实验室实验谱(约 23.9 万个分子数据点,覆盖 8 类光谱)+ SDBS、QM9S、NovoBench 等公开库(100 万+ 化合物)+ 期刊补充材料挖掘
任务模板生成 → YAML 配置驱动,结合分子元数据自动生成选择题
自动解析与质检 → SpectrumVerifier 过滤格式错误、图文不一致样本
专家复核 → 复杂样本人工把关,形成闭环
因此,SpectrumVQA 不是一次性的静态数据集,而是一个可以随着新数据、新光谱类型和新任务持续扩展的评测生成框架。
SpectrumLab:一次性评测到持续迭代的工具链
SpectrumLab 提供评测数据管理、多模型统一接入、选择题/开放式评测器、CLI 评测与公开排行榜。研究者可快速加载指定层级/子任务,在统一协议下接入自有模型或 API 服务,实现可复现对比。
大模型评测:会看谱,推理仍是短板
基于 SpectrumWorld,研究团队对 23 个主流开源与闭源多模态大模型进行了系统评测,覆盖 GPT-4o、Claude、Gemini、Qwen-VL、InternVL、GLM、Doubao 等代表性模型。评测结果显示,当前模型在基础识别任务上已有一定能力,但在复杂结构推理和生成类任务上仍存在明显差距。
这说明当前模型已经能够识别不少谱图模式,但距离真正完成“峰位—官能团—分子式—结构”的多步科学推理仍有距离。
从整体榜单看,闭源模型仍保持领先,但开源模型已经明显逼近。Gemini-2.5-pro 以 67.81% 的综合准确率位列第一,InternVL3.5-241B 达到 65.50%,与闭源最优模型差距约 2.31 个百分点。与此同时,具备显式推理过程的模型在高阶任务上普遍表现更好,表明多步推理能力可能是光谱科学任务中的关键变量。
书生 Intern-S1:在光谱科学任务上展现科学推理优势
SpectrumWorld 的价值不仅在于给出总分排名,更在于揭示模型在不同认知层级上的能力差异。以 Intern-S1 为例,其 thinking 模式在结构解析、逆向推理和性质/结构预测相关任务上表现突出,显示出面向科学场景强化推理能力的重要性。
综合性能稳居第一梯队
InternS1-think 以 65.37% 的综合准确率位列参评模型前三,与最优闭源模型 Gemini-2.5-pro 的差距仅约2.44 个百分点。开启思考模式后,相较 InternS1-nothink(59.57%)提升约 5.8 个百分点,说明多步推理对光谱这类「证据链很长」的科学任务至关重要。
高难度任务上的突出表现
在化学家最关心的结构解析与逆向推理上,Intern-S1 优势更为明显:
- 分子结构解析(SE):InternS1-think 达 90.00%,为参评模型中的顶尖水平之一;
- 逆向问题(IP,光谱→分子):InternS1-think 40.00%,大幅领先多数模型(大量模型在该项接近 0%);
- 从头生成(DnG):InternS1-think 15.79%,在 Generation 层整体平均仅 6.41% 的背景下仍表现突出。
误差分析:性质预测任务族表现领先
误差分析进一步显示,Intern-S1 在性质/结构预测相关任务上的错误率较低。在性质预测任务中,Intern-S1 的错误率为 10.5%,低于 InternVL-3.5 的 13.2%。这表明它在“从谱图证据推断分子性质或结构”这一环节上具有更稳定的跨模态映射能力。
> 解读:光谱 AI 的瓶颈不仅是「图像识别」,更是峰位—官能团—分子式—结构之间的多步符号整合。Intern-S1 的 thinking 模式使其在结构解析、逆向推理等需要多步证据整合的科学任务上体现出优势。
推理能力:Generation 层的「分水岭」
除 Intern-S1 外,实验还显示:显式增强推理的模型,在生成类任务上优势显著。 类似地,Doubao-1.5-Vision-Pro-Thinking 在 Forward Problems 上达到66.67%,也说明 reasoning 能力是生成类光谱任务的关键变量。
Intern-S1 在科学推理任务中的突出表现印证了:为光谱场景注入深度推理能力,是突破当前瓶颈、提升模型科学可靠性的关键路径。SpectrumWorld 的核心使命,正是将这些隐性的能力差异“显性化”、标准化,并精准转化为下一代模型迭代的导航图。
