 夜雨聆风
夜雨聆风在前几篇文章里,我们已经把AI提数助手拆成了几个关键层次:
→ 交互入口层
→ 对话理解层
→ 业务语义层
→ 数据资产层
→ 查询生成层
→ 安全治理层
→ 查询执行层
→ 结果解释与反馈层
第四篇讲的是交互入口层,重点解决用户在哪里问、怎么问、结果怎么展示、如何追问和反馈。
这一篇进入第二层:对话理解层。
一、对话理解层是AI提数助手的“语义入口”
如果说交互入口层负责承接用户输入,那么对话理解层负责把用户输入真正变成系统能处理的任务。它要回答几个核心问题:
用户想做什么?
用户要查什么数据?
条件是否完整?
当前问题是否继承上一轮?
有没有歧义?
是否需要澄清?
下一步应该进入哪条链路?
这层做不好,后面所有模块都会被带偏。
指标匹配、表字段定位、SQL生成、结果解释,看起来是后续问题,实际很多错误都源于最前面的对话理解。
举个例子:
帮我看一下上个月华南运营区各门店支付GMV排名,顺便导出Excel
这句话不是一个简单的“查询”意图。系统至少要识别:
如果系统只输出:
{
"intent": "query"
}
这个结果没有实际价值。后续模块依然不知道查什么、按什么维度、怎么排序、是否需要导出。
更合理的输出应该是:
{
"primary_intent": "RANKING_QUERY",
"secondary_intents": ["REPORT_EXPORT"],
"metric": "支付GMV",
"time": {
"raw": "上个月",
"type": "relative_month"
},
"filters": [
{
"field_type": "region",
"operator": "=",
"value": "华南",
"raw": "华南运营区"
}
],
"dimensions": [
{
"name": "门店",
"role": "group_by"
}
],
"sorting_ranking": {
"type": "ranking",
"order_by": "支付GMV",
"direction": "DESC"
},
"post_actions": ["export_excel"]
}
企业级意图识别不是单一分类器,而应该是“多级路由 + 槽位抽取 + 置信度判断 + 兜底澄清”的体系;
对话理解层的核心,不是给用户问题贴一个意图标签,而是把自然语言问题转化为可执行、可校验、可追问、可路由的结构化查询任务。
二、对话理解层在整体架构中的位置
对话理解层处在交互入口层之后、业务语义层之前。
它接收的不是纯文本这么简单,而是一个带上下文的输入包。
1. 对话理解层的输入
一个成熟的对话理解层,输入至少包括:
+ 用户当前问题
+ 历史对话
+ 当前任务状态
+ 用户身份
+ 用户组织
+ 用户权限
+ 当前入口上下文
+ 当前报表/指标/业务对象上下文
+ 可用数据域
+ 可用工具链
+ 意图样例库
+ 多轮Case库
比如用户在BI报表页面问:
为什么下降?
如果只看当前句子,这句话无法理解。
但如果系统知道当前报表页面正在展示“华东区域域本月支付GMV趋势”,且当前图表中支付GMV环比下降,那么系统就可以判断:
用户意图:归因分析
指标:支付GMV
地区:华东区域
时间:本月
对比方式:环比
上下文来源:当前BI图表
这就是第四篇提到的“入口上下文”进入后端架构后的作用。
2. 对话理解层的输出
对话理解层的输出,不应该只是一个intent,而应该是一个标准化的语义任务对象。
例如:
{
"conversation": {
"intent": "NEW_QUERY",
"is_new_task": true,
"context_operation": "start"
},
"task": {
"query_type": "ranking_query",
"business_domain": "sales",
"primary_intent": "RANKING_QUERY",
"secondary_intents": ["REPORT_EXPORT"]
},
"subject": {
"type": "store",
"raw": "门店",
"normalized": null,
"confidence": 0.86
},
"time": {
"raw": "上个月",
"type": "relative_month",
"normalized": "2026-04",
"calendar_range": {
"start": "2026-04-01",
"end": "2026-04-30"
}
},
"metrics": [
{
"raw": "支付GMV",
"name": "支付GMV",
"role": "measure",
"aggregation": "SUM"
}
],
"dimensions": [
{
"raw": "门店",
"name": "门店",
"role": "group_by"
}
],
"filters": [
{
"raw": "华南运营区",
"field_type": "region",
"operator": "=",
"value": "华南"
}
],
"sorting_ranking": {
"type": "ranking",
"order_by": "支付GMV",
"direction": "DESC"
},
"post_actions": ["export_excel"],
"completeness": {
"is_complete": true,
"missing_slots": [],
"next_action": "semantic_mapping"
},
"confidence": {
"overall": 0.91,
"intent": 0.94,
"slots": 0.88
},
"rewrite_query": "查询上个月华南运营区各门店支付GMV排名,并导出Excel"
}
这个对象才是后续业务语义层、数据资产层和查询生成层真正能消费的内容。
对话理解层负责理解和结构化,不负责直接查数。
三、对话理解层到底要做哪些事情
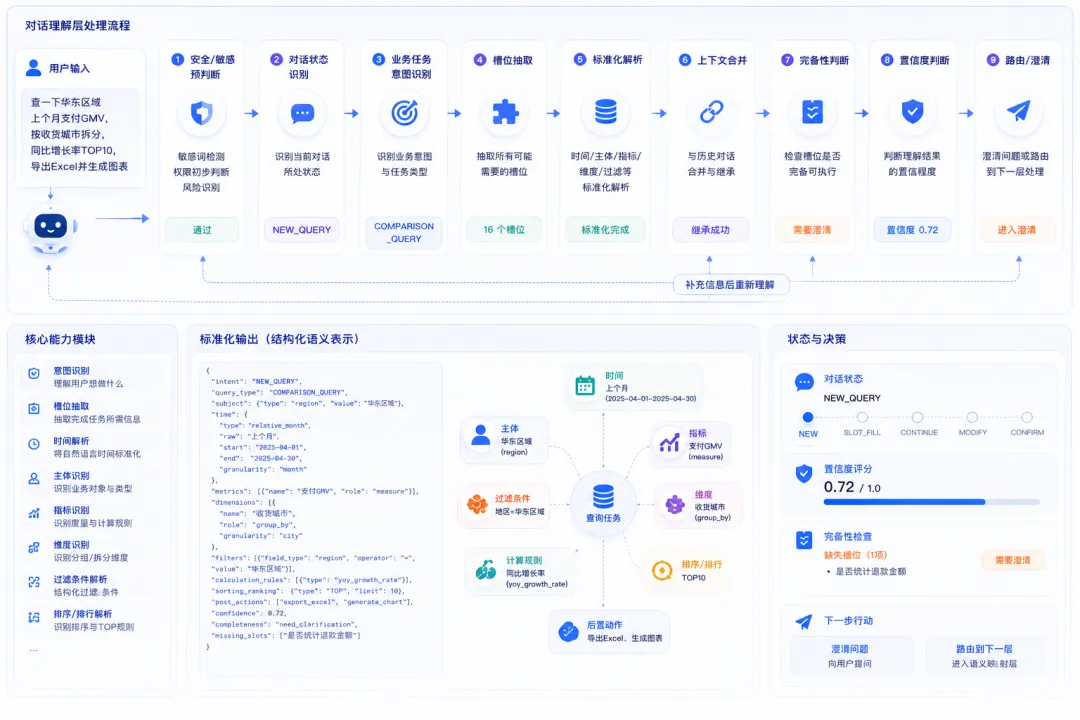
对话理解层可以拆成一组稳定的技术任务。
这不是“堆模块”。它们之间有明确的依赖关系。
一个合理链路应该是:
→ 安全/敏感预判断
→ 对话状态识别
→ 业务任务意图识别
→ 槽位抽取
→ 时间/主体/指标/维度标准化
→ 多轮上下文合并
→ 完备性判断
→ 置信度判断
→ 澄清或路由到下一层
对话理解层的目标可以概括为一句话:
把用户问题从“自然语言表达”整理成“可路由的任务、可校验的槽位、可继承的状态”。
四、意图体系设计:不是一个标签,而是任务路由
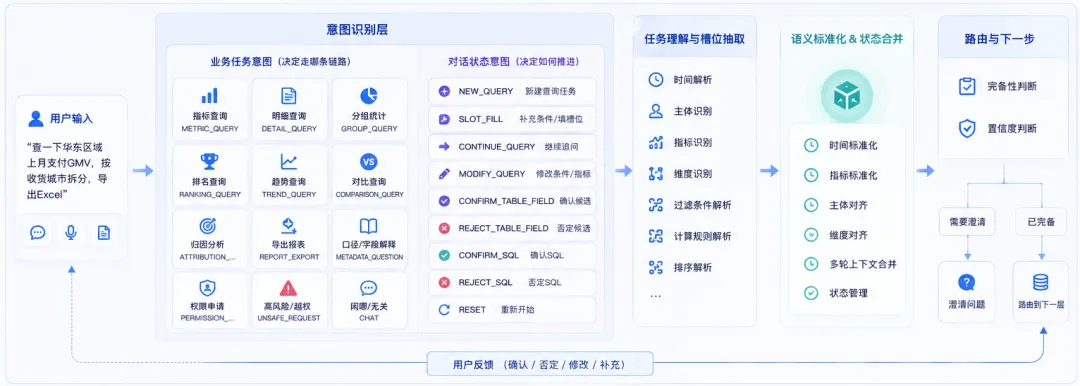
很多系统做意图识别时,会直接定义一批标签:
指标查询
明细查询
趋势分析
导出报表
闲聊
然后训练一个分类模型。这个方法能解决基础问题,但不够支撑企业级AI提数。原因有三个。
第一,用户问题经常不是单意图。
第二,意图不仅决定“是什么问题”,还决定“下一步走哪条链路”。
第三,对话过程中用户还会确认、否定、修改、补充,这些不是业务意图,而是对话状态意图。
所以AI提数的意图体系应该拆成两类:
+ 业务任务意图
+ 对话状态意图
1. 业务任务意图:决定调用哪条业务链路
这套体系不要追求一开始覆盖所有意图。早期可以从METRIC_QUERY、DETAIL_QUERY、GROUP_QUERY、RANKING_QUERY、TREND_QUERY、COMPARISON_QUERY这几类做起。
2. 对话状态意图:决定当前任务怎么推进
对话状态意图解决的是:
用户现在是在提出新问题?
还是在补充条件?
还是在修改上一轮?
还是在确认候选表字段?
还是在否定SQL?
推荐使用这套状态意图:CHAT、NEW_QUERY、SLOT_FILL、CONTINUE_QUERY、MODIFY_QUERY、CONFIRM_TABLE_FIELD、REJECT_TABLE_FIELD、CONFIRM_SQL、REJECT_SQL、RESET。文档中也给出了这些意图的系统动作,例如SLOT_FILL用于合并历史语义并重新检查槽位,REJECT_TABLE_FIELD用于带反馈重新选表字段,RESET用于清空当前任务上下文。
这两类意图要同时存在。
业务任务意图:决定查什么、分析什么、导出什么
对话状态意图:决定当前任务如何继续推进
这就是AI提数助手和普通FAQ机器人的差别。
五、槽位体系设计:从自然语言到结构化查询要素
意图识别回答“用户想做什么”。槽位抽取回答“完成这件事需要哪些信息”。
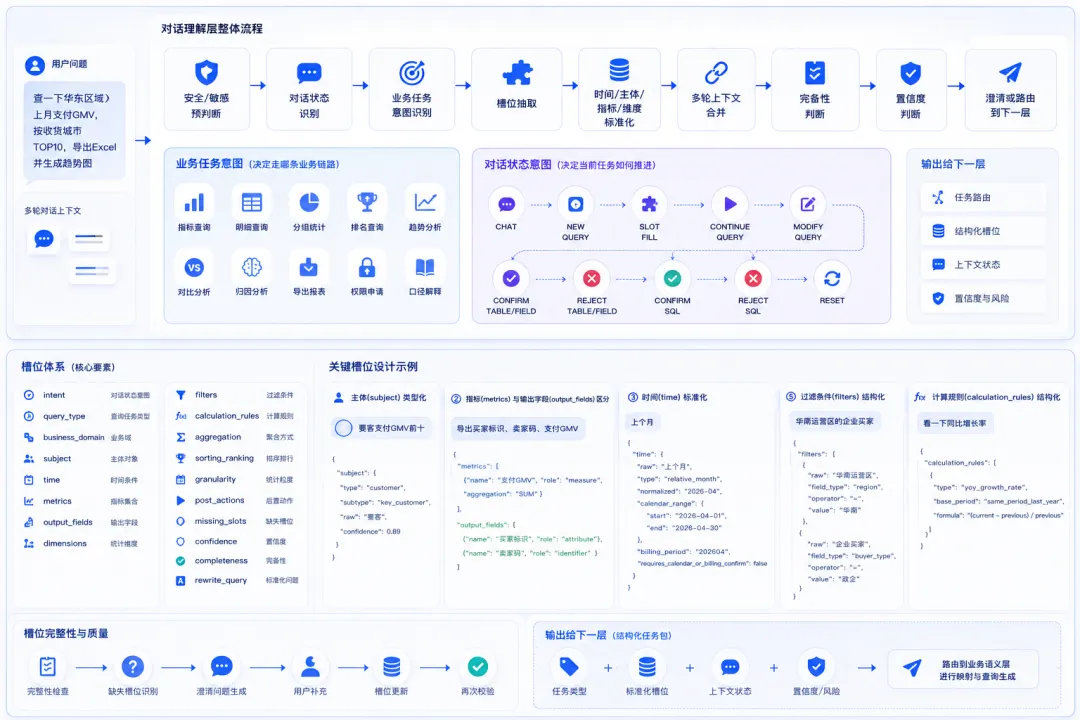
在标准NLU系统里,实体通常表示话语中用于完成或识别意图的重要信息;复杂实体还可以继续拆成子实体,例如地址可以拆为街道、城市、省州、邮编等。对AI提数来说,槽位就是把用户问题转成结构化查询任务的关键桥梁。
1. 推荐槽位体系
AI提数场景建议采用下面这套Schema。
2. 主体对象必须类型化
AI提数里,subject非常关键。
用户不是抽象地“查数据”,而是围绕某类主体查:
买家
商品
区域
类目
项目
组织
工单
订单
门店
渠道
例如:
查一下要客支付GMV前十
这里“要客”不能只做成普通过滤词,它隐含主体类型是“买家”。
推荐输出:
{
"subject": {
"type": "customer",
"subtype": "key_customer",
"raw": "要客",
"confidence": 0.89
}
}
如果没有主体类型,后续业务语义层很难判断要去买家维表、商品维表、区域维表还是组织维表做映射。
3. metrics和output_fields必须区分
这是AI提数里非常容易出错的地方。
用户说:
导出买家标识、卖家码、支付GMV
这里:
支付GMV = 指标
买家标识 / 卖家码 = 输出字段
如果全部放到metrics里,后续SQL生成可能把买家码、卖家码当作可聚合指标,生成非常离谱的SQL。
推荐结构:
{
"metrics": [
{
"name": "支付GMV",
"role": "measure",
"aggregation": "SUM"
}
],
"output_fields": [
{
"name": "买家标识",
"role": "attribute"
},
{
"name": "卖家码",
"role": "identifier"
}
]
}
这点在你上传的槽位设计中也被明确列为需要修正的问题:metrics需要区分“指标”和“输出字段”,否则卖家码、买家标识会被误当作可聚合指标。
4. time必须标准化
不能只输出:
{
"time": "上个月"
}
因为“上个月”对SQL生成没有直接价值。
推荐输出:
{
"time": {
"raw": "上个月",
"type": "relative_month",
"normalized": "2026-04",
"calendar_range": {
"start": "2026-04-01",
"end": "2026-04-30"
},
"billing_period": "202604",
"requires_calendar_or_billing_confirm": false
}
}
AI提数场景里的时间至少要支持:
- 自然日;
- 自然月;
- 统计月;
- 季度;
- 年;
- 最新一期;
- 近N天;
- 近N月;
- 同比基期;
- 环比基期;
- 多时间点对比。
如果时间不标准化,SQL生成就会反复出错。
5. filters必须结构化
不能输出:
{
"filters": ["华南", "企业买家"]
}
应该输出:
{
"filters": [
{
"raw": "华南运营区",
"field_type": "region",
"operator": "=",
"value": "华南"
},
{
"raw": "企业买家",
"field_type": "buyer_type",
"operator": "=",
"value": "政企"
}
]
}
结构化filter的价值是显性的。
它能让后续语义层知道“华南”要映射地域维度,“企业买家”要映射买家类型维度,而不是把它们都当成自由文本。
6. calculation_rules必须结构化
用户说:
看一下同比增长率
不能只记录:
{
"calculation_rules": ["同比增长率"]
}
应该表达为:
{
"calculation_rules": [
{
"type": "yoy_growth_rate",
"base_period": "same_period_last_year",
"formula": "(current - previous) / previous"
}
]
}
同样,环比、占比、贡献度、去重、平均值、累计值、留存率、转化率,都要尽可能结构化。否则后面查询生成层无法判断是一次查询、两次查询,还是需要派生计算。
六、四类核心解析:时间、主体、指标、维度
在AI提数对话理解层里,有四类解析最关键:时间、主体、指标、维度。

这四类一旦错,SQL大概率也会错。
1. 时间解析
时间解析要同时处理原始表达和标准表达。
常见类型包括:
这里要特别注意“自然月”和“统计月”的差异。
经营分析系统里,“上个月”不一定等同于“上一个自然月”,有些场景要按统计期、结算周期、数据快照周期来解释。
所以时间槽位要允许携带:
{
"calendar_range": {},
"billing_period": "",
"time_granularity": "",
"time_semantics": "calendar_or_billing"
}
2. 主体解析
主体解析要解决:
用户到底围绕哪个业务对象查?
例如:
查企业买家支付GMV
查会员套餐商品办理量
查华东区域投诉量
查美妆类目企业服务商品支付GMV
查项目回款情况
这里的主体分别可能是:
- 买家;
- 商品;
- 地域;
- 类目;
- 项目。
主体解析不能只靠词典。因为很多词会同时出现在多个业务体系里。
例如“政企”既可能是买家类型,也可能是组织条线;
“企业服务商品”既可能是商品,也可能是业务标签;
“华东区域”既可能是行政区域,也可能是组织归属。
所以主体槽位要尽量输出候选:
{
"subject": {
"raw": "政企",
"candidates": [
{
"type": "buyer_type",
"value": "企业买家",
"confidence": 0.83
},
{
"type": "business_line",
"value": "政企业务",
"confidence": 0.62
}
],
"selected": "buyer_type"
}
}
当候选置信度差距不大时,应进入澄清。
3. 指标解析
指标解析要解决:
用户想看的度量是什么?
指标可能是:
标准指标:支付GMV、买家数、投诉量; 别名指标:营收、出账、ARPU; 派生指标:同比增长率、环比增幅; 组合指标:支付GMV和买家数; 模糊指标:经营情况、发展情况、运营效果。
对于标准指标,可以先抽取词面,再交给业务语义层做指标匹配。
对于派生指标,要同时抽取指标和计算规则。
例如:
看一下华东区域支付GMV同比增长率
应拆成:
{
"metrics": [
{
"name": "支付GMV",
"role": "measure"
}
],
"calculation_rules": [
{
"type": "yoy_growth_rate"
}
]
}
不要把“支付GMV同比增长率”整体当成一个指标词,除非指标体系中确实存在该标准指标。
4. 维度解析
维度解析要解决:
按什么拆?
按什么分组?
按什么排名?
用户常见表达包括:
按收货城市拆
分商品看
各类目排名
每个月趋势
买家类型分布
维度解析要输出:
{
"dimensions": [
{
"raw": "收货城市",
"name": "收货城市",
"role": "group_by",
"granularity": "city"
}
]
}
这里还要判断维度是否适配当前指标。
不是所有指标都支持所有维度。比如某些指标只有省级汇总,没有收货城市级明细;某些指标只能按月统计,不能按天统计。这部分判断会在业务语义层和数据资产层进一步完成,但对话理解层需要先把维度意图抽清楚。
七、多意图识别:一个问题可能对应多个任务
AI提数场景中,一个用户问题经常包含多个动作。
例如:
查一下上个月华南各门店支付GMV排名,导出Excel,并生成一个柱状图
这句话包含:
主任务:支付GMV排名查询
后置动作1:导出Excel
后置动作2:生成柱状图
如果系统只识别成RANKING_QUERY,就会漏掉导出和图表生成。
如果只识别成REPORT_EXPORT,又会漏掉核心查询。
推荐输出:
{
"intents": [
{
"name": "RANKING_QUERY",
"role": "primary"
},
{
"name": "REPORT_EXPORT",
"role": "post_action"
},
{
"name": "CHART_GENERATION",
"role": "post_action"
}
]
}
多意图识别的关键不是把标签做多,而是要区分:
primary:决定主链路
secondary:影响任务补充
post_action:结果之后的动作
guardrail:安全/权限/敏感拦截
例如:
查一下所有买家买家手机号和交易明细,导出Excel
这里既有明细查询和导出,也有敏感字段风险。意图识别要输出高风险标记,后面才能进入权限和脱敏流程。
总之,多意图不能简单分类处理,需要支持主意图、次意图和后置动作等多个输出。
八、多轮上下文管理:继承、补充、修改、切断
对话理解层最难的部分之一,是多轮上下文。
真实用户不会每次都说完整问题。
用户:查一下华东区域新增买家
系统:返回结果
用户:按收货城市拆一下
用户:换成宽带
用户:只看TOP10
用户:和上个月比呢
用户:重新开始
这些短句单独看都不完整,但结合上下文就很清楚。
1. 上下文操作类型
2. 上下文对象建议
系统内部可以维护一个ConversationState:
{
"task_id": "task_001",
"status": "TASK_DONE",
"semantic_frame": {
"metric": "会员套餐新增买家数",
"time": "2026-04",
"region": "华东区域",
"dimensions": ["收货城市"],
"filters": []
},
"last_sql": "...",
"last_result_schema": ["city_name", "new_buyer_cnt"],
"active_contexts": [
{
"type": "metric_query_context",
"lifespan": 3
}
]
}
3. 新旧意图切断策略
上下文不能无限继承。
无限继承会造成任务污染。
例如:
用户:查一下华东区域支付GMV
用户:按收货城市拆
用户:附近有什么好吃的
第三句明显不是继续查支付GMV,而是新话题或无关问题。
建议切断规则:
多轮场景需要设计新旧意图切断策略,避免不同意图流程互相污染。
九、完备性判断:什么时候能继续往下走
不是所有用户问题都可以直接进入选表和SQL生成。
例如:
查一下支付GMV
这句话缺少很多信息:
时间?
地区?
GMV口径?
是否按组织权限默认?
是否需要分组?
输出表格还是图表?
如果直接查,风险很高。
1. 完备性判断维度
2. 完备性输出
{
"completeness": {
"is_complete": false,
"missing_slots": ["time", "metric_scope"],
"blocking_slots": ["metric_scope"],
"optional_slots": ["dimension"],
"next_action": "clarify"
}
}
注意这里要区分:
blocking_slots:不补不能执行
optional_slots:不补也能用默认值
例如:
指标不明确通常是blocking; 维度不明确可能是optional; 时间缺失在某些场景可默认最近一个月,但要提示; 明细导出涉及敏感字段时,权限审批是blocking。
3. 执行策略
可以设计三种执行策略:
完整且高置信:直接进入业务语义层
基本完整但有默认值:带提示执行
关键槽位缺失:澄清后再执行
完备性判断是“少犯错”的关键。
企业级AI提数不是追求每次都马上回答,而是该问清楚时必须问清楚。
十、低置信度判断与澄清机制
AI提数助手不能把所有不确定问题都硬查。可以采用置信度分层策略:高置信直接执行,中置信带确认执行,低置信反问澄清。 这个思路非常适合AI提数场景。
1. 推荐置信度策略
confidence >= 0.85:直接执行
0.60 <= confidence < 0.85:带确认执行
confidence < 0.60:反问澄清
这只是初始阈值,后续可以按场景调优。
2. 不同槽位可以有不同阈值
不要只看overall confidence。
不同槽位风险不同,阈值也应该不同。
3. 澄清问题要有候选项
不要问:
你想查什么?
这种问题太开放,用户负担大。
更好的方式:
“支付GMV”存在多个口径,请选择:
A. 支付GMV
B. 净支付金额
C. 财务确认支付GMV
D. 商品成交额
或者:
当前缺少时间范围,请选择:
A. 本月
B. 上月
C. 近30天
D. 自定义时间
澄清设计的原则是:
缺什么问什么
一次性补关键缺失项
优先给候选项
默认值必须透明
高风险口径必须确认
低风险条件可以默认
十一、状态机设计:把对话变成可控流程
大模型对话很容易变成自由聊天。 企业级AI提数必须把对话约束到可控流程中。这就需要状态机。
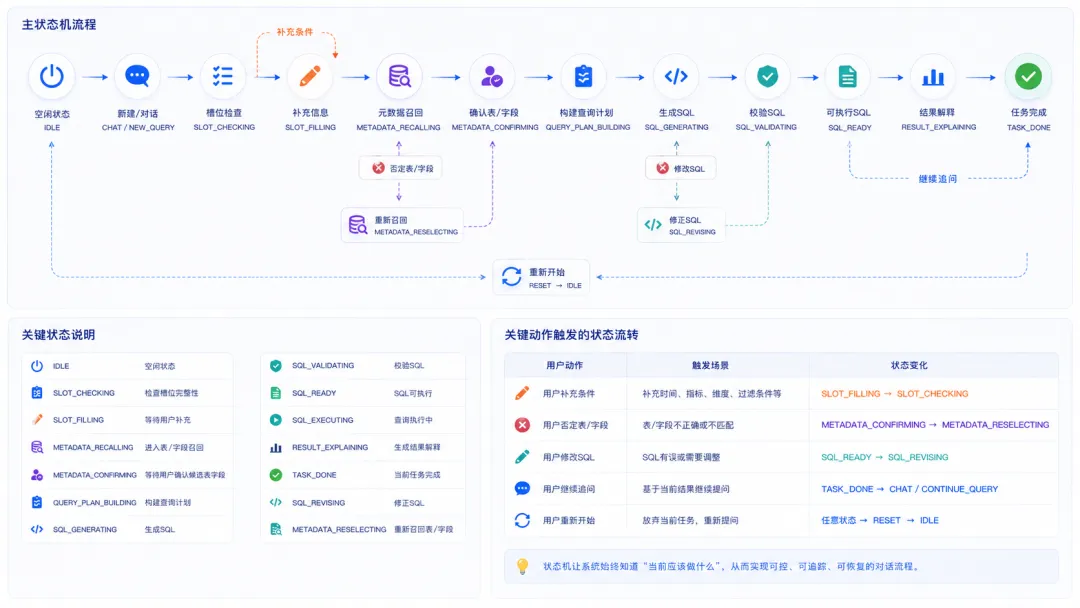
1. 推荐状态机
→ IDLE
→ CHAT / NEW_QUERY
→ SLOT_CHECKING
→ SLOT_FILLING
→ METADATA_RECALLING
→ METADATA_CONFIRMING
→ QUERY_PLAN_BUILDING
→ SQL_GENERATING
→ SQL_VALIDATING
→ SQL_READY
→ SQL_EXECUTING
→ RESULT_EXPLAINING
→ TASK_DONE
2. 关键状态说明
3. 特殊流转
状态机的价值是让系统知道“当前应该做什么”。
没有状态机,用户一句“这个不对”系统都不知道是表字段不对、SQL不对,还是结果解释不对。
Rasa的slot机制也体现了类似思想:NLU pipeline输出的intents和entities会和domain里定义的slot mappings匹配,满足映射后会设置slots,从而驱动后续对话行为。(rasa.com) 在AI提数里,我们也需要把抽取结果写入任务状态,再由状态机推动后续链路。
十二、技术路线:规则、模型、向量、LLM协同
对话理解层不适合押注单一技术路线。
只靠规则,泛化不够。
只靠BERT分类,复杂多意图和多轮上下文不够灵活。
只靠LLM,成本、延迟、稳定性和可控性都有问题。
为构建适合企业级生产的数据助手/智能客服/Agent平台,意图识别需要综合规则/关键词、传统机器学习、BERT微调、向量语义路由、LLM Prompt进行混合架构设计。
1. 推荐在线链路
→ 用户输入
→ 安全/敏感规则拦截
→ 高频规则识别
→ 向量语义路由
→ LLM复杂意图判断
→ 槽位抽取
→ Schema校验
→ 完备性判断
→ 澄清/执行
2. 各技术分工
3. 推荐生产形态
生产系统可以分为两路:
轻链路:规则/缓存/向量路由 → 快速返回
重链路:LLM + RAG + Schema校验 → 处理复杂问题
例如:
“按收货城市拆一下”这种短追问,可以走上下文规则; “导出昨天投诉明细”可以走规则 + 槽位模板; “为什么华东区域支付GMV下降”需要LLM做任务理解; “查一下上个月华南各门店支付GMV排名,顺便导出Excel”适合LLM结构化输出 + Schema校验; “所有买家买家手机号导出”必须先被安全规则拦截。
这样的混合路线,比单纯LLM更稳,也比纯规则更灵活。
十三、四种实现方案的演进路径
可以把对话理解层的实现路径分成四个阶段:Prompt驱动、节点拆分、意图RAG、多轮RAG增强。
1. 方案A:Prompt驱动
一个LLM节点同时完成意图识别 + 槽位抽取
适合MVP阶段。
优点是快,成本低,能迅速验证商品闭环。
缺点也明显:意图变多后Prompt膨胀,不同意图互相干扰,输出稳定性下降。
适合:
意图少
业务简单
内部试用
快速验证
不适合:
高并发
强安全
多轮复杂任务
长期生产系统
2. 方案B:意图识别与槽位抽取节点拆分
先识别意图
→ 按意图路由到对应抽槽节点
适合业务扩展期。
优点是职责清晰,每个抽槽节点只处理自己的槽位,维护性更好。
缺点是链路变长,延迟增加,而且多轮上下文容易在节点间丢失。
适合:
意图数量中等
各意图槽位差异大
对维护性要求高
3. 方案C:前置意图RAG召回
用户输入
→ 召回相似意图表达
→ LLM判断最终意图
适合用户表达复杂、Bad Case需要快速修复的阶段。
优势是把一部分实时泛化变成“离线样例库 + 在线召回”。
线上出现识别错误,可以补充样例和Case,而不是每次都改Prompt或重新训练模型。
缺点是更适合单轮,短句追问如果没有上下文,检索效果会不稳定。
4. 方案D:合并节点 + 多轮RAG增强
多轮上下文组装
→ 召回相似Case
→ LLM一次性输出意图 + 槽位
→ 状态机推进
适合核心业务链路。
它的关键不是“所有东西都塞给LLM”,而是:
先压缩有效上下文
再召回相似多轮Case
再让LLM一次性完成意图和槽位
最后用Schema、规则和状态机校验输出
对AI提数助手来说,建议路线是:
MVP:方案A
业务扩展:方案B + 部分规则
泛化优化:方案C
核心生产:方案D + 状态机 + 反馈闭环
十四、输出Schema设计:对话理解层的标准交付物
对话理解层最终要交付一个标准Schema。
这个Schema不是为了好看,而是为了让后续模块稳定消费。
1. 推荐Schema
{
"conversation": {
"intent": "NEW_QUERY",
"is_new_task": true,
"context_operation": "start"
},
"task": {
"query_type": "ranking_query",
"business_domain": "sales",
"primary_intent": "RANKING_QUERY",
"secondary_intents": ["REPORT_EXPORT"]
},
"subject": {
"type": "store",
"raw": "门店",
"normalized": null,
"confidence": 0.86
},
"time": {
"raw": "上个月",
"type": "relative_month",
"normalized": "2026-04",
"calendar_range": {
"start": "2026-04-01",
"end": "2026-04-30"
},
"billing_period": "202604"
},
"metrics": [
{
"raw": "支付GMV",
"name": "支付GMV",
"role": "measure",
"aggregation": "SUM",
"confidence": 0.93
}
],
"output_fields": [],
"dimensions": [
{
"raw": "门店",
"name": "门店",
"role": "group_by",
"confidence": 0.88
}
],
"filters": [
{
"raw": "华南运营区",
"field_type": "region",
"operator": "=",
"value": "华南",
"confidence": 0.91
}
],
"calculation_rules": [],
"sorting_ranking": {
"type": "ranking",
"order_by": "支付GMV",
"direction": "DESC",
"limit": null
},
"post_actions": ["export_excel"],
"completeness": {
"is_complete": true,
"missing_slots": [],
"blocking_slots": [],
"optional_slots": [],
"next_action": "semantic_mapping"
},
"confidence": {
"overall": 0.91,
"intent": 0.94,
"slots": 0.88
},
"rewrite_query": "查询上个月华南运营区各门店支付GMV排名,并导出Excel"
}
2. Schema设计原则
建议遵守这些原则:
字段固定
类型明确
保留raw和normalized
每个关键槽位带confidence
metrics和output_fields分开
time必须标准化
filters必须结构化
calculation_rules必须可执行化
completeness必须输出
next_action必须明确
大模型输出再自然,如果不能稳定解析,就不能进入生产链路。
所以对话理解层一定要有JSON Schema校验、字段枚举、类型校验、缺失字段补齐、非法值修复机制。
十五、对话理解层和后端架构的衔接
对话理解层不能孤立设计。它要为后面几层服务。
1. 和业务语义层衔接
对话理解层输出:
支付GMV
门店
华南
上个月
业务语义层负责:
支付GMV → 标准指标
门店 → 门店维度/组织维度
华南 → 地域维度编码
上个月 → 自然月/统计月
也就是说,对话理解层只做“自然语言结构化”,不直接做最终指标口径决策。下一篇“业务语义层”相关文章会重点讲:如何把这些结构化槽位映射成企业标准指标、维度、口径和编码。
2. 和数据资产层衔接
对话理解层输出:
metrics + dimensions + filters + time
数据资产层负责:
召回表
召回字段
判断Join关系
推荐数据源
过滤无权限资产
3. 和查询生成层衔接
对话理解层输出结构化任务:
query_type
metrics
dimensions
filters
time
calculation_rules
sorting_ranking
查询生成层负责:
QueryPlan → SQL
4. 和交互入口层衔接
对话理解层输出:
missing_slots
confidence
clarification_options
risk_flags
交互入口层负责展示:
槽位确认卡
澄清卡
风险提示
权限申请入口
5. 和反馈闭环衔接
用户反馈:
不是支付GMV,是主营支付GMV
系统应沉淀到:
指标别名
同义词库
Case库
评测集
Prompt样例
语义层规则
这就是前后端、模型层、数据层的闭环。
十六、评测体系:怎么判断对话理解层做得好不好
对话理解层必须可评测。
不能只看“感觉能不能答”。
微软CLU的评估流程会在测试集上预测意图和实体,再和标注结果对比,并返回Precision、Recall、F1等指标;其评估API也会返回意图和实体的precision、recall、F1以及混淆矩阵。(Microsoft Learn)
AI提数助手也应该建立类似评测体系。
1. 意图识别指标
2. 槽位抽取指标
3. 端到端业务指标
对话理解层的评测不能只做离线分类准确率。
真正要看的是它是否能推动后续查询任务稳定完成。
十七、运营闭环:对话理解层需要长期运营
对话理解层不是一次性开发完就结束。
业务会变,指标会变,用户表达会变,组织结构会变,商品名称会变。
因此它必须长期运营。
1. 需要运营的资产
意图体系
槽位体系
同义词库
时间规则
主体词库
指标别名
维度枚举
多轮Case库
Bad Case库
评测集
Prompt模板
JSON Schema
澄清模板
状态机规则
2. Bad Case处理流程
推荐流程:
→ 线上失败问题
→ 标注失败原因
→ 分类为意图错 / 槽位错 / 上下文错 / 语义映射错
→ 修复规则、样例、Prompt或Case
→ 加入评测集
→ 回归测试
→ 发布上线
3. Bad Case分类
4. 运营原则
高频Bad Case优先
高风险口径优先
核心指标优先
用户纠错必须沉淀
每次迭代必须回归评测
意图和槽位体系要版本化
这是对话理解层从“能跑”到“可运营”的关键。
十八、常见设计误区
1. 只做单标签intent分类
AI提数问题经常包含多意图、多动作。
单标签分类无法表达“查询 + 导出 + 图表 + 权限审批”。
2. 槽位只抽原文,不做标准化
抽出“上个月”没有意义,必须转换成自然月、统计期或日期范围。
3. 不区分指标和输出字段
把买家标识、卖家码当成指标,会直接影响SQL生成。
4. 没有完备性判断
槽位缺失时直接生成SQL,容易查错。
5. 没有低置信度澄清
不确定时强行执行,比查不到更危险。
6. 多轮上下文无限继承
上下文不切断,会造成任务污染。
7. 完全依赖LLM
LLM输出灵活,但生产系统需要规则、Schema、状态机和评测体系约束。你上传的设计文档也指出,LLM Prompt分类虽然语义理解强、适合复杂查询和多轮判断,但存在成本延迟高、输出不稳定、需要JSON Schema和校验器、高风险场景不能完全依赖LLM单点判断等问题。
十九、总结:对话理解层决定AI提数助手能不能真正听懂用户
AI提数助手的对话理解层,不是一个简单的NLU分类模块,也不是一个Prompt节点。
它是自然语言到结构化查询任务之间的关键转换层。
它要同时解决:
用户想做什么
查什么主体
看什么指标
按什么维度
限定什么时间
过滤哪些条件
是否要排序/对比/归因
是否要导出/生成图表/生成报告
是否继承上一轮
是否需要澄清
下一步进入哪条链路
最终输出不应该是:
{
"intent": "query"
}
而应该是一个完整的语义任务对象:
+ conversation intent
+ task intent
+ subject
+ time
+ metrics
+ output fields
+ dimensions
+ filters
+ calculation rules
+ post actions
+ completeness
+ confidence
+ next action
从技术实现上,企业级AI提数助手的对话理解层应该采用混合架构:
+ 规则
+ 分类模型
+ 槽位抽取模型
+ 向量检索
+ LLM
+ RAG
+ JSON Schema
+ 状态机
+ 反馈闭环
大模型负责理解复杂表达,规则和状态机负责确定性控制,语义样例库和Case库负责持续优化,Schema负责工程稳定性,评测体系负责质量度量。
这层做扎实,后面的业务语义层、数据资产层、查询生成层才有稳定输入。
这层做不扎实,后面再强的Text-to-SQL也只能在错误语义上生成SQL。
下一篇顺着这个结构继续往下走,进入业务语义层设计:当对话理解层已经抽出了“支付GMV、华南、门店、上个月”之后,系统如何进一步把这些自然语言槽位映射成企业标准指标、维度编码、业务口径和推荐数据源。那一层,才是真正把“听懂用户”推进到“对齐企业数据标准”的关键。
