 夜雨聆风
夜雨聆风题目: DataMaster: Data-Centric Autonomous AI Research
论文地址:https://arxiv.org/abs/2605.10906
代码地址:https://github.com/sjtu-sai-agents/DataMaster

创新点:
• 提出了一种全新的研究范式:在固定学习算法的前提下,仅通过优化数据端来提升下游模型性能。涵盖的数据工程环节包括:外部数据发现、数据选择与组合、数据清洗与转换。
•将数据工程从"手动、临时性"的工作转变为系统化、可累积、可复用的自主智能体流程,在不动模型算法的前提下,通过数据侧的优化实现显著性能提升。
方法:
本文是一篇关于数据中心化自主 AI 研究的论文,其核心思想是在模型架构、训练方法和计算预算日益标准化的背景下,机器学习系统的进一步性能提升越来越依赖于数据质量的优化。然而当前的数据工程仍然大量依赖人工操作且缺乏系统性,研究人员需要反复搜索外部数据集、将其适配到现有流程中、通过下游训练验证数据效果,并从过往尝试中总结经验。针对这一现状,论文提出了任务条件化的自主数据工程范式,即让一个自主智能体在保持学习算法不变的前提下,仅通过优化数据端来获得更强的下游解决方案。为了应对自主数据工程中存在的开放式搜索空间、分支依赖精细化以及延迟验证等固有挑战,论文设计了 DataMaster 框架,该框架整合了树状搜索结构、共享候选数据池和累积记忆机制三个关键组件。
DataMaster 框架概览
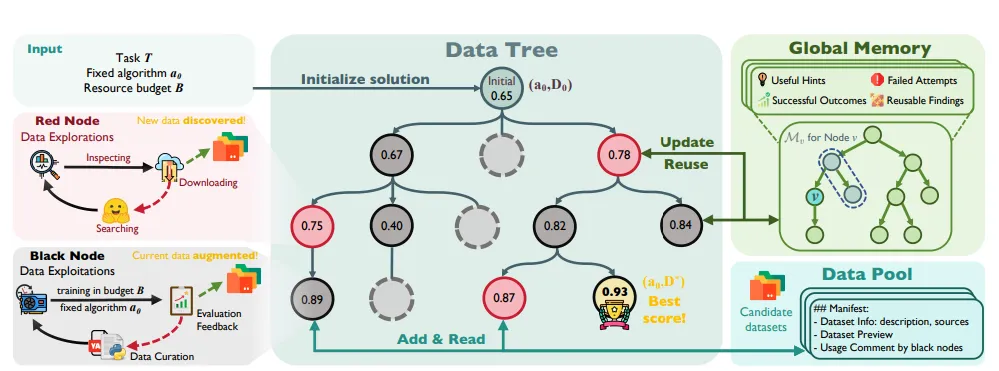
本图系统性地展示了 DataMaster 这一自主数据工程智能体框架的整体架构与工作流程。输入端接收任务描述 T、固定学习算法 a₀ 以及资源预算 B,随后初始化一个根节点,其初始性能得分为 0.65。框架的核心是 DataTree,该树状结构通过两种类型的节点实现数据工程的迭代优化:红色节点代表数据探索阶段,智能体在此阶段执行搜索、检查与下载操作以发现新的外部数据源,并在发现新数据时触发数据池的更新与复用机制;黑色节点代表数据利用阶段,智能体在此阶段对当前数据进行数据策展,并在预算约束下评估反馈,同时将数据集描述、来源信息及使用注释等元数据写入 Data Pool。Global Memory 作为累积记忆模块,以树状结构记录各节点的有用提示、失败尝试、成功结果及可复用发现,支持跨分支的知识传承与经验复用。整个流程通过树状搜索不断扩展与深化,最终收敛至最优节点,其性能得分达到 0.93,标志着在固定算法条件下通过数据端优化实现了下游任务性能的最大化提升。
DataMaster 在 PostTrainBench 基准测试上的性能对比
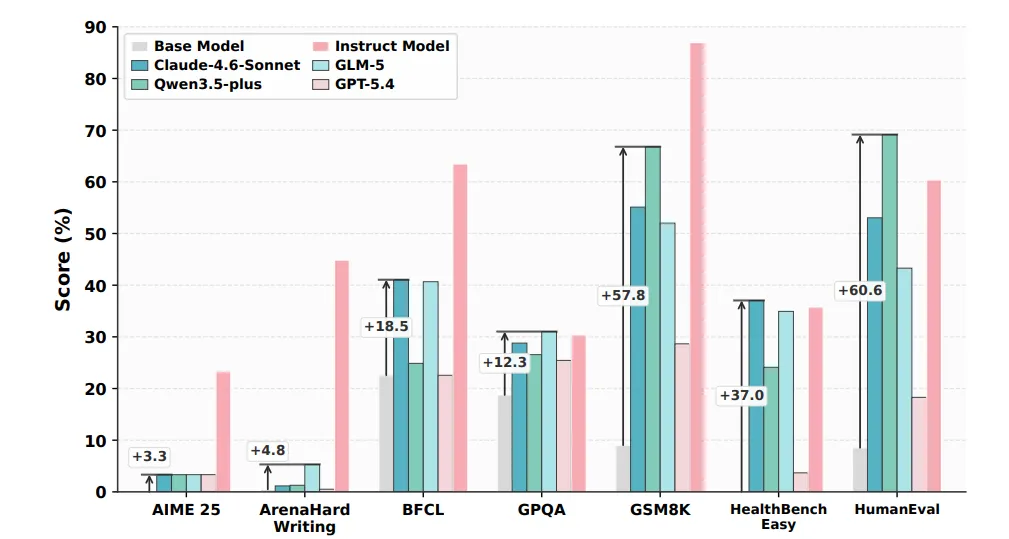
本图展示了 DataMaster 框架在七个下游任务基准上相对于基线模型及多个强基座模型的性能表现。图中灰色柱体代表 Base Model(基础模型),粉色柱体代表 Instruct Model(指令微调模型),其余四种不同色调的柱体分别对应 Claude-4.6-Sonnet、GLM-5、Qwen3.5-plus 和 GPT-5.4 等主流大语言模型。从实验结果可以看出,DataMaster 在多个任务上均实现了显著的性能跃升:在 AIME 25 上提升 3.3 个百分点,在 ArenaHard Writing 上提升 4.8 个百分点,在 BFCL 上提升 18.5 个百分点。尤为值得注意的是,在 GPQA 任务上 DataMaster 以 31.02% 的得分超越了 Instruct Model 的 30.35%,在 GSM8K 和 HumanEval 等推理与代码生成任务上更是实现了跨越式提升,充分验证了在固定学习算法的前提下,通过系统化的自主数据工程优化数据端而非模型端,能够带来 substantial 且 consistent 的下游性能增益,且该增益在数学推理、代码生成等复杂认知任务上表现得尤为突出。
DataMaster 在 GPQA 任务上的渐进式数据工程优化轨迹
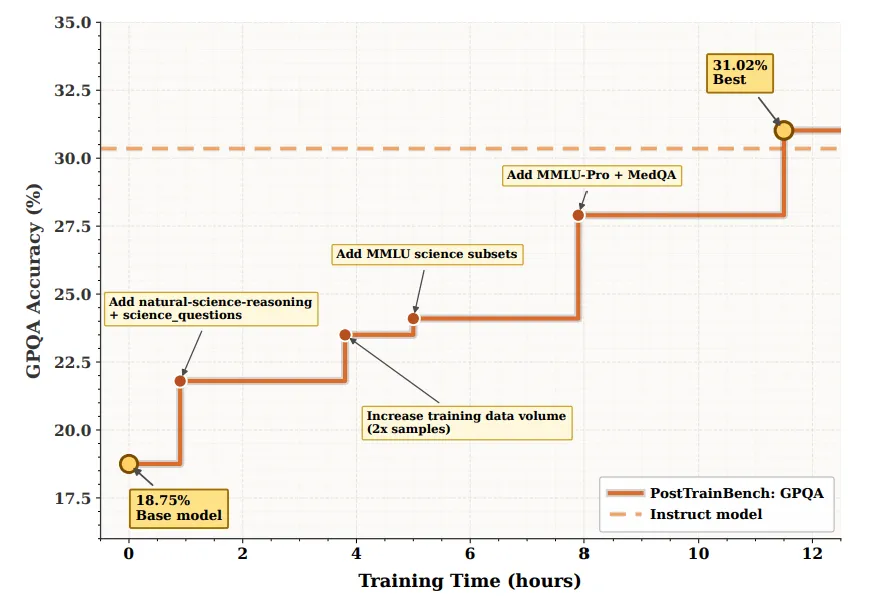
本图呈现了 DataMaster 框架在 PostTrainBench 的 GPQA 基准上,通过自主数据工程策略逐步提升模型性能的完整演化过程,横轴为训练时间(小时),纵轴为 GPQA 准确率。图中橙色实线代表 DataMaster 的性能轨迹,橙色虚线代表 Instruct Model 的基线水平。初始状态下,Base Model 的 GPQA 准确率仅为 18.75%。DataMaster 在约 1 小时训练时间时执行第一次数据探索操作,引入 natural-science-reasoning 与 science_questions 数据集,性能跃升至约 22%;最终在约 11.5 小时处达到最优性能 31.02%,成功超越 Instruct Model 基线。该图清晰地揭示了 DataMaster 的数据工程策略具有显著的累积效应与阶段跃迁特征,每一次性能提升均对应于特定的数据操作,且后期引入的专业化数据集带来了最为显著的性能增益,表明自主智能体能够通过系统化的数据探索与复用机制,在固定算法条件下实现超越传统指令微调模型的下游任务表现,同时也印证了数据质量与多样性对于复杂科学问答任务的关键作用。
实验
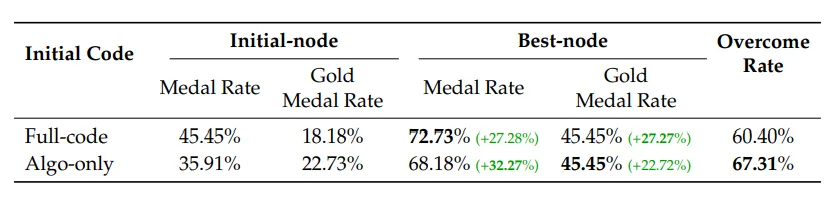
该表格展示了 DataMaster 在 MLE-Bench Lite 基准测试上的性能表现,对比了两种初始代码条件下初始节点与最优节点的奖牌率及金牌率差异。在 Full-code 条件下,初始节点的奖牌率为 45.45%,金牌率为 18.18%;经过 DataMaster 的自主数据工程优化后,最优节点的奖牌率提升至 72.73%,金牌率提升至 45.45%克服率达到 60.40%。在 Algo-only 条件下,初始节点的奖牌率为 35.91%,金牌率为 22.73%;优化后最优节点的奖牌率提升至 68.18%,金牌率提升至 45.45%,克服率达到 67.31%。这一结果充分验证了 DataMaster 在数据受限场景(Algo-only)下具有更强的相对增益潜力,同时也表明初始代码质量对于最终绝对性能上限具有显著影响,而克服率指标则揭示了 DataMaster 在超过半数测试用例中成功超越了初始基线水平,体现了其自主数据工程策略的有效性与泛化能力。
