 夜雨聆风
夜雨聆风
华为韬定律?这不就是综合软件干的事吗——从 KTM5900 看芯片里的“时间战争”
这几天华为“韬定律”刷屏。
我看完第一反应,其实有点不屑。
什么“时间缩微”,什么“压缩信号传播时延”,什么“逻辑折叠”,什么“减少关键路径”——这些词换成数字芯片工程师熟悉的语言,不就是综合、布局布线、STA、timing closure 那一套吗?
信号太慢,就优化逻辑级数; 路径太长,就改 floorplan; fanout 太大,就插 buffer; slack 不够,就重综合、重约束、重布局; 实在不行,就拆 pipeline、做 retiming。
后端工程师天天被这些东西折磨,半夜看 timing report 看到怀疑人生。现在突然包装成一个“定律”,说实话,第一眼确实有点像把工程苦活重新起了个豪华名字。
但如果话只说到这里,又太浅。
因为华为这次真正值得讨论的地方,不是它发现了一个没人知道的新物理规律,而是它试图把过去主要发生在芯片内部的“时间优化”,往外推到器件、电路、芯片、封装、软件,甚至整个电子系统。
换句话说,过去综合软件主要解决的是:
寄存器到寄存器之间,信号能不能按时到。
但如果把这个问题放大到一颗编码器芯片,甚至放大到一套伺服系统里,它就变成了:
传感器看到的位置,能不能以最短、最稳定、最可信的时间,到达控制器,再变成电机的动作。
这个时候,事情就有意思了。
华为官方对韬(τ)定律的表述,是把“时间缩微”作为半导体和电子系统演进的新原则,具体分成器件、电路、芯片、系统四层:器件层优化晶体管和互连的电阻、电容,电路层通过逻辑折叠缩短关键路径,芯片层做软件、架构、芯片协同,系统层通过互联协议降低通信时延。这个说法本身很宏大,但拆到底就是一句工程话:当几何尺寸越来越难缩,系统就要想办法让信号少绕路、少等待、少排队。
所以我不想把韬定律神化。
它不是“华为重新发明了半导体物理”。
但我也不想一句“这不就是综合软件吗”就把它打发掉。
因为当“综合”的对象不再是一段 RTL,而是一颗芯片、一个传感模组、一套伺服驱动系统时,问题的难度就完全变了。
局部优化叫技巧。
系统级优化,才叫工程能力。
一颗编码器芯片,本质上就是一条时间链路
拿昆泰芯 KTM5900 来说。
公开资料显示,KTM5900 是一颗 24bit 绝对角度 TMR 磁性编码器芯片,内部集成双 16bit 2M SAR ADC,用来读取差分模拟正弦/余弦信号,并通过高速数字电路完成角度计算和位置输出;官方产品页还提到它具备 80M 内部主频、最大 36M SPI 角度输出及寄存器读写、独立 PWM 绝对角度输出,规格表中列出 180,000 rpm 转速、QFN32 封装、-40℃ 到 +125℃ 工作温度等信息。
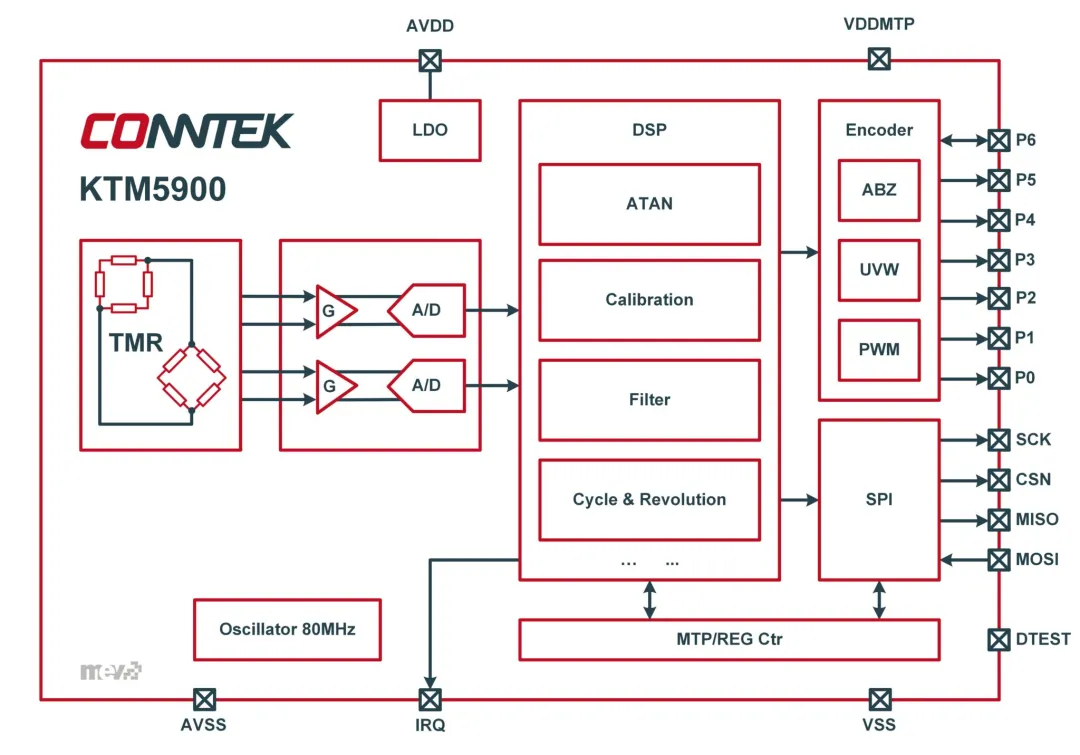
这些参数单独看都很漂亮。
24bit。 TMR。 双 16bit 2M SAR ADC。 36M SPI。 180,000 rpm。 低延时。 自校准。 非线性补偿。
但真正做编码器芯片的人,不能只看这些孤立参数。
因为编码器芯片输出的不是一个简单数字。
它输出的是伺服系统对现实世界的“时间感”。
磁铁在转,TMR 桥感知到磁场方向,模拟前端把微弱信号放大、滤波,ADC 把正弦/余弦信号采出来,数字电路做 arctan 或 CORDIC 角度解算,再经过幅值不匹配补偿、相位误差补偿、非线性校准、数字滤波,最后通过 SPI、ABZ、UVW 或 PWM 把位置交给控制器。
这条链路上每一步都在花时间。
传感器有响应时间。 模拟前端有带宽和群延迟。 ADC 有采样周期和转换延迟。 数字解算有 pipeline latency。 查表补偿有访问延迟。 数字滤波有相位滞后。 接口传输有帧时间。 控制器读取还有同步误差。
所以,编码器芯片真正难的,不是把某个参数写到 datasheet 上,而是把这些东西放进同一张时间预算表里。
这就很像我理解的“系统级韬定律”。
不是问某一段逻辑能不能过 timing。
而是问:
从物理角度变化,到控制器拿到可信位置,中间到底丢了多少时间。
24bit 分辨率,不等于伺服系统时时刻刻拿到 24bit 有效位置
KTM5900 这类产品最容易被外行误读的一个参数,就是 24bit。
很多人看到 24bit,会直觉认为:这颗芯片每一瞬间都能给控制器一个 24bit 真实有效角度。
工程上没这么简单。
公开资料里,KTM5900 的定位是 24bit 绝对角度 TMR 磁编码器,但它内部读取正弦/余弦信号的是双 16bit 2M SAR ADC;官方规格表也写到“有效位 16Bit”,同时给出 24bit 角度分辨率。
这说明什么?
说明 24bit 更像是角度细分能力和输出格式能力,而不是说在所有温度、所有磁场、所有转速、所有安装误差、所有噪声环境下,都天然拥有 24bit 的真实动态有效精度。
编码器芯片里的“分辨率”和“精度”本来就不是一回事。
分辨率是你能把一圈切成多少份。
精度是你切完以后,那个位置到底准不准。
动态有效精度还要再加一层:你这个准的位置,是不是来得足够快,抖动是不是足够小。
如果一个角度值靠很重的平均、很长的滤波、很慢的补偿换来,那它静态看起来很漂亮,动态用起来可能就会拖后腿。
伺服系统不喜欢迟到的高精度。
它宁可要一个及时、稳定、误差可建模的位置,也不喜欢一个晚了几微秒、延迟还不稳定的“漂亮数字”。
2M SAR ADC 背后,真正要算的是时间账
KTM5900 的双 16bit 2M SAR ADC 是一个很关键的参数。
2MHz 采样率意味着单次采样周期大约是 0.5 微秒。公开报道还提到,KTM5900 系统延时低至 0.5 微秒,支持最高 180,000 rpm,并通过 256 点误差查找表与非线性补偿来处理磁铁安装偏差、温度变化等问题。
这里就可以做一个很具体的工程计算。
180,000 rpm 是什么概念?
180,000 rpm = 3000 转/秒。
也就是说,一圈只有 333 微秒左右。
如果系统延迟是 0.5 微秒,那么在最高转速下,机械角度已经转过:
360° × 0.5μs / 333μs ≈ 0.54°
0.54° 机械角看起来不算离谱,但如果这是一个多极对电机,电角度误差还要乘以极对数。
比如 7 对极电机,0.54° 机械角对应大约 3.8° 电角度。
如果延迟不是 0.5 微秒,而是 5 微秒呢?
机械角滞后就变成 5.4°。
7 对极下,电角度滞后就是 37.8°。
这已经不是“小数点后面的误差”了。
这会直接影响 FOC 里的 Park 变换角度,影响 q 轴/d 轴解耦,影响转矩输出,影响高速稳定性。
所以,编码器芯片里的延迟不是背景参数。
延迟就是性能本身。
而且,比固定延迟更可怕的是延迟抖动。
固定延迟还可以建模、补偿、外推。
今天 0.5 微秒,明天 2 微秒,低速一个样,高速一个样,SPI 读数又因为控制器调度再飘一点,那伺服控制器就很难受。
它以为自己拿到的是“当前位置”。
实际上拿到的是一个时间不确定的过去位置。
最大参数不能同时拉满,这才是 datasheet 背后的现实
再看 KTM5900 的输出接口。
公开资料提到它支持最高 36Mbps SPI 绝对角度输出,也支持可编程最大 65536 线 ABZ 正交脉冲增量输出、UVW 和 PWM 等输出模式。([sensorexpert.com.cn][4])
这时候就不能只看“最大值”。
因为最大值之间经常不能同时成立。
假设 ABZ 真的配置到 65536 线/圈。
如果按四倍频边沿计数,一圈就是:
65536 × 4 = 262144 个计数边沿
如果转速来到 180,000 rpm,也就是 3000 转/秒,那么边沿频率就是:
262144 × 3000 ≈ 786 MHz
这个频率对普通 ABZ 接收链路来说基本不现实。
即便只看 A/B 的线频,65536 线 × 3000 转/秒,也接近 197 MHz。
所以,65536 线和 180,000 rpm 这两个最大参数,不能简单理解成“同时满配工作”。
这不是 KTM5900 的问题。
这是所有高速高分辨率编码器都会遇到的问题。
分辨率、转速、接口带宽、边沿完整性、控制器捕获能力,本来就是一个系统联立方程。
SPI 也是一样。
36Mbps 听起来很高,但如果你要读 24bit 角度,再加命令位、地址位、状态位、CRC、片选间隔、控制器调度延迟,一次完整事务可能就不是 24/36M 这么简单。
24bit 裸数据传输时间约 0.67 微秒。
但真实 SPI 帧通常不会只有 24bit。再加上控制器发起读数的时刻不一定刚好对齐芯片内部角度更新点,系统端到端延迟就又多了一层不确定性。
PWM 输出更典型。
PWM 很方便,接线简单,抗某些系统复杂度的能力强,但它天然有周期和占空比分辨率之间的矛盾。你想要更高分辨率,就需要更长周期或者更高计数时钟;你想要更低延迟,就不能让周期太长。
这就是编码器芯片里的时间战争。
不是一个参数赢了就赢了。
是每条路径都要算账。
KTM5900 真正值得看的,不是 24bit,而是它怎么把“传感—采样—解算—输出”压到一个系统里
所以我看 KTM5900,不会只看 24bit。
我更关心它的架构取舍。
TMR 传感器的好处是灵敏度高,适合做磁编码器的高精度角度检测。但高灵敏度也意味着你要认真处理磁场幅值、安装偏心、正弦/余弦幅度不匹配、相位非正交、谐波、温漂、外部电磁噪声这些问题。
双通道 16bit 2M SAR ADC 解决的是“快速把模拟正弦/余弦采进来”。
80M 内部主频解决的是“数字链路有足够节拍做解算和补偿”。
256 点误差查找表和非线性补偿解决的是“安装和磁场不完美时,角度不能跟着歪”。
36M SPI、ABZ、UVW、PWM 解决的是“不同控制系统怎么拿到这个角度”。
这些东西放在一起看,才是产品。
如果从“综合”的角度看,KTM5900 不是单纯把 RTL 综合成门级网表,而是在做一件更完整的事情:
把磁场、模拟、ADC、数字算法、存储器、输出接口、控制器采样方式,尽可能压成一条短而稳定的时间路径。
这就是我前面说的:
数字综合优化的是寄存器到寄存器的时间;编码器芯片优化的是磁铁到控制器的时间。
如果把韬定律翻译成伺服语言,它就不是玄学
所以,如果把华为韬定律翻译成伺服系统语言,我觉得它不是一句“我们有新摩尔定律了”。
它更像是在问:
位置反馈能不能少等一次滤波?
角度解算能不能少走一段 pipeline?
补偿查表能不能和 CORDIC 并行?
SPI 读数能不能对齐内部采样时刻?
控制器能不能知道这个角度值对应的真实采样时间?
PWM 更新能不能和位置采样建立确定关系?
编码器、驱动器、电机和负载之间,能不能作为一个整体重新分配延迟预算?
这些问题听起来没有“1.4 纳米”“弯道超车”那么刺激。
但工程上真正让系统变稳的,往往就是这些不起眼的问题。
一个伺服系统里面,也有 critical path。
只不过它不叫 RTL critical path。
它可能叫:
采样延迟。 角度刷新周期。 SPI 事务时间。 控制 ISR 抖动。 PWM 更新延迟。 电流环相位滞后。 速度估算滤波延迟。 机械共振响应时间。
芯片里的时序收敛,是让信号在一个 clock cycle 里准时到。
伺服系统里的时序收敛,是让现实世界的位置变化,在控制环能承受的时间内被感知、计算、执行。
真正高级的优化,是把整套系统当成一颗“大芯片”重新布局
我觉得韬定律最值得借鉴的地方,也正在这里。
如果它只是说“缩短关键路径”,那确实没什么新鲜。
但如果它背后的思想是:
把整个电子系统当成一颗大芯片重新综合、重新布局、重新分配时间预算。
那就很有价值。
在伺服系统里,这种思想可以落到很具体的设计动作上。
比如编码器芯片内部要尽量减少不必要的串行等待,ADC 采样、角度解算、误差补偿、接口输出能 pipeline 的地方就 pipeline。
比如角度输出不要只给一个位置值,最好让控制器知道它对应哪个采样时刻,否则控制器拿到的是“没有时间戳的位置”。
比如 SPI 读数最好和控制周期同步,避免控制器在角度更新前后随机读到不同相位的数据。
比如高速模式下,滤波策略不能只盯着静态噪声,要看它给电流环和速度环带来的相位损失。
比如 ABZ 高线数输出不能只宣传最大线数,还要看最高转速下的边沿频率、驱动能力、线缆完整性、控制器捕获上限。
比如在机器人关节里,编码器芯片、驱动芯片、GaN 功率级、电流采样、控制 MCU 或 DSP,不能各自只优化自己的指标,而要共同回答一个问题:
从关节真实偏了一点,到系统把它拉回来,中间到底过了多久。
这就是系统级时间优化。
它和数字综合很像,但难度更大。
因为数字综合里的单元库、约束、corner、时钟关系相对清楚。
伺服系统里有磁铁安装误差、PCB 寄生、线缆噪声、逆变器开关干扰、机械负载变化、温度漂移、控制器调度、客户现场接线方式。
这些东西不会老老实实待在 EDA 工具里。
它们会在客户现场凌晨两点给你打电话。
所以,我对韬定律的态度是:不神化,但也别低估
我不喜欢把韬定律吹成“华为一夜之间绕开先进制程”。
从工程角度看,它里面很多内容确实是数字综合、物理设计、架构优化、系统协同早就在做的事。
但我也不认同一句“这不就是综合软件吗”就把它打发掉。
因为老问题做到系统级,就会变成新战场。
在先进制程受限时,芯片当然还要继续追工艺。
但不能只等工艺。
你还要在器件寄生、互连长度、存储访问、数据搬运、接口协议、软件栈、系统拓扑里继续抠时间。
同样,做编码器芯片也不能只宣传 24bit、多少 rpm、多少 Mbps。
最后客户真正关心的是:
电机高速转起来稳不稳? 机械臂突然受扰能不能快速反应? 位置反馈有没有慢半拍? 接口读数有没有抖动? 高温、干扰、安装偏心以后,控制环还剩多少余量?
客户不会问你用了什么定律。
客户只会问:
为什么我的电机一加速就抖?为什么位置反馈慢半拍?为什么 datasheet 上写得很好,到了现场就不稳?
这时候,所有宏大的技术叙事,最后都会回到一张最朴素的时间预算表上。
所以,华为韬定律最有价值的地方,可能不是它提出了一个多么神秘的新概念。
而是它把一个芯片工程师天天面对、却很少被大众理解的问题推到了台前:
当尺寸越来越难缩,时间就会成为新的战场。
AI 芯片是这样。
KTM5900 这类编码器芯片也是这样。
伺服系统更是这样。
芯片战争从来不只是把晶体管做小。
很多时候,它是在问:
信号能不能少走一点弯路,数据能不能少排一次队,系统能不能少等那几个微秒。
