 夜雨聆风
夜雨聆风2026年5月,中国大模型周调用量首次突破7.94万亿Token,是美国的2.11倍。AI联盟这份公开报告比什么发布会PPT都实在——中国AI不是在画饼,是真在干活。
不过调用量多不代表能力强,外卖订单多不代表厨艺好。今天咱不吹不黑,拿真实数据和测评结果,把中美主流大模型拆开揉碎了比。所有数据都来自官方发布、第三方测评、各公司财报和公开报告,没一句瞎编。
📌 30秒看完全文
中国AI调用量是美国的2倍,但顶级能力还差15-20%。价格差35倍,国产性价比碾压。普通人免费组合豆包+DeepSeek+Kimi就能覆盖90%场景。
一、美国三巨头
🔵 OpenAI:GPT-5.5,流量之王
ChatGPT周活9亿,全球用户量最大。GPT-5.5在OSWorld测试里拿到75%,头一次超过人类基线——让模型操作电脑完成复杂任务。Agent能力确实突破了,能自己调用工具、执行多步骤任务。ARR年化收入大概250亿美元,商业上还是最成功的那一个。
但增速被Anthropic碾压。2025年OpenAI收入增长约50%,Anthropic却从10亿飙到440亿美元,10倍增速。OpenAI的问题不是产品不行,是越来越贵、越来越封闭。
💰 定价:标准版$2.5/$15,Pro版$5/$30,企业级方案月费动辄上万美元
🟢 Google:Gemini 3.1 Pro,科学推理最强
GPQA(研究生级别科学推理)94.3%,史上最高分。1M上下文,跟Google全家桶深度整合。3.5 Flash刚发布,速度极快,性价比在美系里算最好的。
Google的优势就是生态,Gmail、Docs、YouTube无缝嵌入。劣势也一样:离开Google生态体验打折扣,产品策略也挺乱。
💰 定价:Flash免费额度大,Pro版$1.25/$10
🟠 Anthropic:Claude Opus 4.7,编程之王
SWE-bench Verified 87%,全球编程第一。让模型修改真实GitHub仓库的代码,不是写玩具代码。Claude Code年化收入25亿美元,开发者自己掏钱买,说明真能干活。
ARR从10亿涨到440亿美元,估值9650亿超过OpenAI。最大优势是编程和企业信任。但也是最贵的:输入$5、输出$25每百万token,比DeepSeek V4 Flash贵35倍。
💰 定价:输入$5、输出$25,Pro $15/$75
二、中国主力军:6家各有绝活
🔥 字节豆包:Seed 2.0 Pro,国产第一
LMArena全球第9,国产第一。日活超1亿,中文对话体验国产里最自然。多模态很全:语音全双工、3D生成、4K60fps视频。免费版基本够用。
短板是深度任务——长文档、复杂编程不如Kimi和DeepSeek。字节AI策略变来变去,企业客户不敢深度绑定。
💰 定价:免费版够用,Pro版月费几十元
💚 腾讯混元:微信生态之王
周调用量2.68万亿Token全球第一。深度嵌入微信12亿月活,一句话生成小程序,AI Agent能调度整个微信生态。
💰 定价:微信内免费,API调用价格低
🟡 智谱GLM-5.1:纯国产芯片标杆
10万颗华为昇腾910B训练,纯国产芯片。企业级稳定可靠,8小时长程任务自治。MIT开源,推理速度400 tokens/s。政企客户必须用国产芯片的,GLM是首选。
💰 定价:开源免费,企业版按需定价
🟣 MiniMax M2.7:极低成本+自我进化
$0.3每百万输入token,比DeepSeek还便宜。有自我进化能力,多模态交互体验出色。问题是知名度低,企业客户少,B端能力弱。
💰 定价:$0.3/$0.8,国产最便宜之一
🔵 Kimi K2.6:上下文之王
200万+上下文全球第一,SWE-Bench Pro 58.6%登顶。300子Agent集群,13小时连续编码。分析500页合同、1000页论文,只有Kimi能完整读完。但90%的日常任务用不到200万上下文。
💰 定价:免费版200万上下文,Pro版月费待定
🔴 DeepSeek V4:性价比之王
1.6T/49B MoE,1M上下文,MIT开源。全面适配华为昇腾国产芯片。V4 Pro在5月23日75%永久降价:$0.435/$0.87。V4 Flash只要$0.14/$0.28。代码能力SWE-bench 80.6%,接近Claude的87%。企业月成本60元 vs GPT-5.5方案10200元。
💰 定价:V4 Flash $0.14/$0.28,V4 Pro $0.435/$0.87
三、中美差异:价格差35倍,能力差15-20%
价格:DeepSeek V4 Flash $0.14/M vs Claude Opus 4.7 $5/M,差35倍。企业用DeepSeek月成本60元,GPT-5.5方案10200元。

▲ 中美大模型价格对比(每百万Token成本)
能力:顶级场景美国仍领先,但差距从"代差"缩小到"版本差"。
| 维度 | 🇺🇸 最强 | 🇨🇳 最强 |
|---|---|---|
| 编程 | Claude 87% | DeepSeek 80.6% |
| 科学推理 | Gemini 94.3% | GLM-5.1 ~82% |
| 中文对话 | GPT-5.5 | 豆包 🏆 |
| 性价比 | Gemini Flash | DeepSeek V4 🏆 |
| 上下文 | Gemini 1M | Kimi 200万 🏆 |
调用量:中国7.94万亿/周 vs 美国3.76万亿/周,2.11倍。路线:美国规模优先,中国效率优先,各有道理。
四、差异背后的原因
🔧 算力:美国H100/H200集群规模远超,但昇腾910B正在追赶。DeepSeek V4证明国产芯片能训出顶级模型。
🌐 生态:美国开发者工具链成熟,中国企业应用落地更快(微信/钉钉/飞书内嵌AI)。
🛤️ 路线:美国大力出奇迹追AGI,中国MoE效率优先抢市场。
🧬 市场:美国企业付费意愿高(人力成本高),中国企业免费或低价是刚需。
五、普通人怎么选
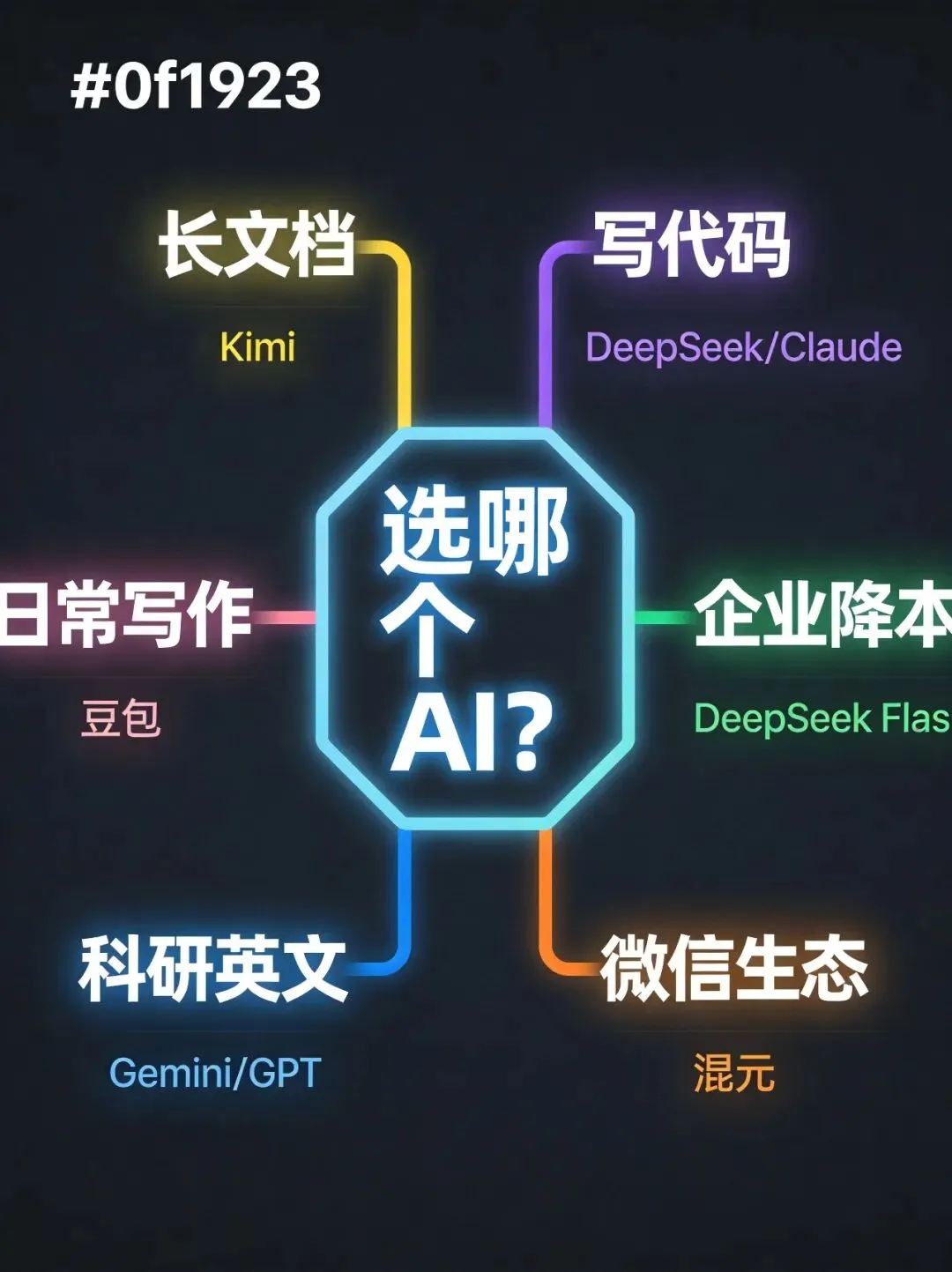
▲ 不同场景的AI模型选择推荐
💬 日常聊天写东西 → 豆包。中文最自然,免费版够用。
📄 长文档/合同/论文 → Kimi。200万上下文无可替代。
💻 写代码 → DeepSeek V4(免费)/ Claude(付费最强)。
🏢 企业降本 → DeepSeek V4 Flash。月成本60元 vs GPT-5.5方案10200元。
📱 微信生态 → 腾讯混元。公众号/小程序/企业微信深度集成。
🔬 科学研究/英文 → Gemini / GPT-5.5。别用国产做英文科研。
🏛️ 政企合规 → GLM-5.1 / 文心5.1。必须国产芯片的唯二选择。
💡 零成本起步方案
豆包+DeepSeek+Kimi三件套免费覆盖90%场景:豆包聊天、DeepSeek写代码、Kimi分析长文档。别只用一个,组合使用效果更好。
六、未来方向:分化而非追赶
🔧 国产芯片闭环加速:昇腾生态越来越成熟,2027年920发布后算力差距可能缩小到1-2年。
💸 价格战继续:DeepSeek已逼美国降价,中国模型价格还会降。
🤖 Agent从工具变员工:2027年可能出现月薪100元的AI员工。
🌍 中美从"追赶"变"分化":美国强在编程/科学推理/AGI,中国强在中文场景/性价比/生态集成。各自擅长领域不同。
📌 给普通人的信号
没有"最强模型",只有"最适合的模型"。豆包+DeepSeek+Kimi三件套免费覆盖90%场景,不够再加Claude或GPT-5.5。花几个月试错,找到最适合自己的组合,比看100篇测评实在。
---
这篇是全景概览,每个公司其实都有很多值得单独聊的——OpenAI怎么从非营利走到250亿美元?Anthropic凭啥一年涨10倍?DeepSeek到底怎么做到这么便宜的?豆包日活破亿背后踩了什么坑?
后面我会逐个拆解,一家公司一篇文章,把真实的商业逻辑、技术选择和行业八卦讲透。
👉 关注「汇观天下事」,中美AI系列持续更新中
你最想先看哪家公司的深度拆解?评论区告诉我,按热度排期。
