 夜雨聆风
夜雨聆风过去几天 AI 圈值得知道的 7 件事。
01|Anthropic 完成 650 亿美元融资,估值 9650 亿美元首超 OpenAI,Claude Opus 4.8 同日上线

两件事同一天落地:Anthropic 完成新一轮 650 亿美元融资,投后估值达 9650 亿美元,首次超过 OpenAI(3 月估值 8520 亿美元)。领投方包括 Altimeter Capital、Dragoneer、Greenoaks、红杉,三星、SK 海力士、美光也作为战略方参与。
同日,Anthropic 上线 Claude Opus 4.8。距上一版 Opus 4.7 发布仅 41 天。代理编程得分从 64.3% 升到 69.2%,fast mode 速度提升 2.5 倍、成本降到三分之一。新功能 Dynamic Workflows 允许 Claude 在单次会话内启动数百个并行子 Agent、自动规划拆解再汇总。
营收数字也同步更新:Anthropic 自报年化营收(run-rate)已达 470 亿美元。今年初还是 300 亿,去年全年实际收入是 100 亿。美国媒体 Axios 写道:找遍任何行业任何时代,找不到一家公司能在这个规模上把自然增长做得这么快。
这轮融资可能是 Anthropic 上市前最后一次大规模私募,接下来走向公开市场的可能性越来越高。
02|Cursor 开发者报告:AI 编码正在产生马太效应

Cursor 近期发布了一份开发者使用数据报告。最核心的结论:头部用户的 AI 代码产出量、token 消耗、PR 合并率,都远高于中位数,而且差距还在拉大。
报告里有一个数字值得单独看:AI 写代码时"读入"越来越多,input/output token 比例大幅上升。Cursor 给出的解释很直白——「真正贵的不是让 AI 写代码,而是让 AI 理解一个代码库和任务。」缓存因此变得非常重要,每次 Agent 从零读上下文的话成本会爆炸。
工作流层面也在变:开发者越来越少手动审查每一行 diff,更多 AI 改动直接进入 commit;单个 PR 体量在变大,1000 行以上的大 PR 占比上升。副作用是:架构边界的设计、review 的质量、自动化测试的覆盖率,这些事情会比以前更重要。
03|Uber AI 预算超支故事被翻案:超支恰恰是 PMF 的证据

5 月 26 日,美国媒体 Fortune 发文:Uber 把 2026 年全年 AI 预算在四个月内烧光了,COO 开始质疑值不值。这个故事被广泛转发,成为「AI ROI 存疑」的标志性案例。
业内 LLM 研究者 Simon Willison 随后深挖原始资料,去找了 Uber COO Andrew Macdonald 的播客原话,发现「实际上没什么实质内容」——媒体的标题比 COO 原话激烈得多。
他的翻案逻辑是:Uber 2025 年制定预算时,Claude Code 还没成熟(要到 11 月才真正好用)。2026 年开发者大量涌入,消耗量远超预算——这是开发者觉得好用才疯狂使用,不是烧钱没收获。预算超支本身,恰恰是产品找到市场的证据,不是 AI 失败的证据。
04|Perplexity Computer 进入 MS Office:Excel、Word、PPT、Outlook 均已集成
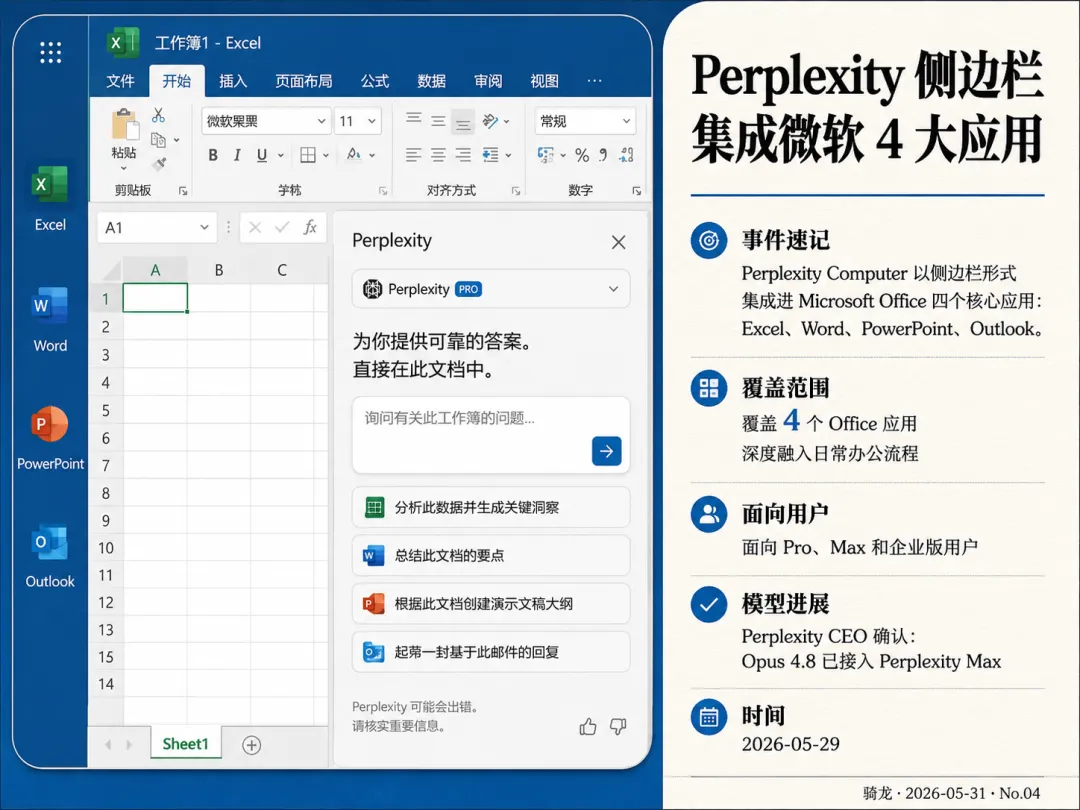
Perplexity Computer 现在能在 Microsoft Office 四个核心应用里直接用了:Excel、Word、PowerPoint、Outlook。形式是侧边栏插件,通过微软应用商店安装,面向 Pro、Max 和企业版用户开放。
各应用里的能力有所差异。Word 里可以起草、改写、总结,也能用 Deep Research 从网页和文档里找资料补进来。Excel 里可以直接读写表格、从网络或数据仓库拉数据。PowerPoint 里可以基于文档或表格生成幻灯片。Outlook 里可以起草改写邮件,从邮件线程和附件里提炼会议简报。
Perplexity CEO 在发布时补充:Opus 4.8 已接入 Perplexity Max,推荐在 Perplexity Computer 里作编排器使用。这相当于把 Anthropic 最新旗舰模型打包进了 Office 生产力场景。
05|归藏社交媒体卡片 Skill 登顶 GitHub 本周 Star 榜,靠 Agent 互相推荐传开
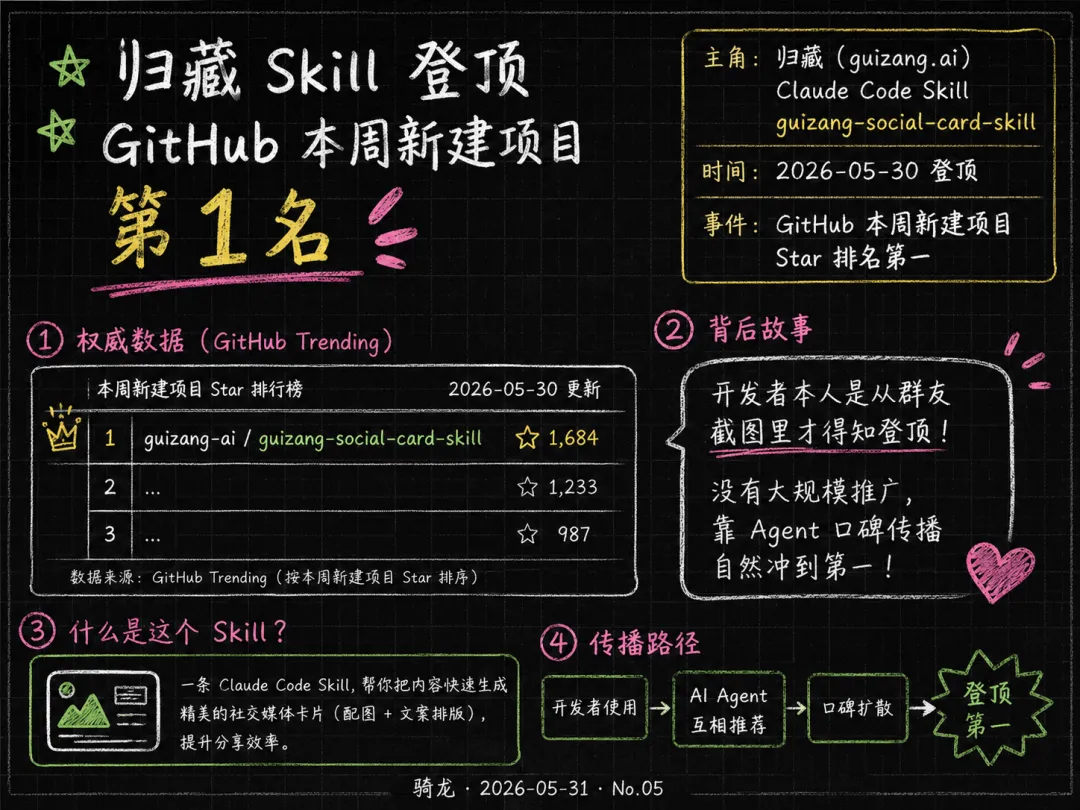
归藏(guizang.ai)开发的社交媒体卡片 Skill,5 月 30 日冲到 GitHub 本周新建项目 Star 排名第一。这个 Skill 能让 AI Agent 自动生成适配各平台的社交媒体卡片图,架构是标准 Claude Code Skill 格式。
有意思的是,归藏本人是从一个群友分享「让 Agent 找项目」的截图里才知道自己登顶的。这个 Skill 没有大规模推广,靠开发者社区的口碑在 Agent 之间流传——一个 Agent 向另一个 Agent 推荐,成了这次意外登顶的主要路径。
一个工具能进入「AI 自己会推荐给 AI 用」的阶段,说明它的接口设计足够标准、足够通用。对 Skill 生态来说,这可能是比 Star 数量更有价值的信号。
06|MIT 和哈佛团队做了个 AI 家教 Koji:你问答案,它只逼你自己想
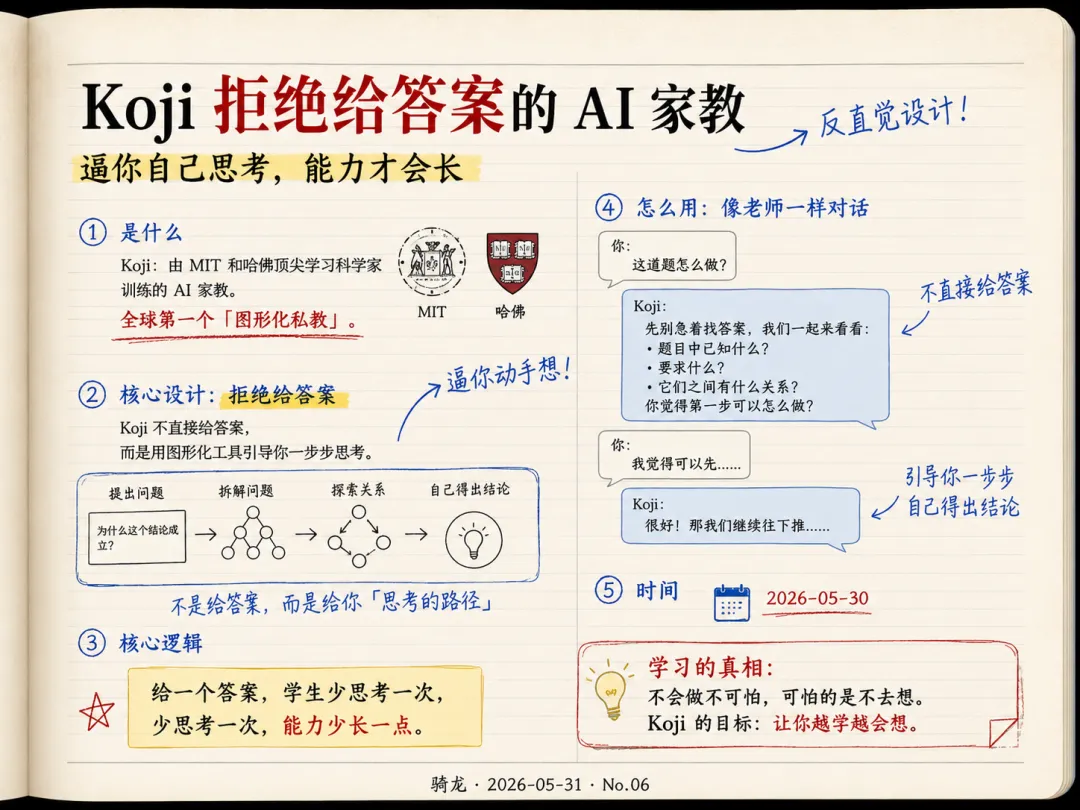
Koji 是一个拒绝给答案的 AI 家教,由麻省理工学院和哈佛大学的学习专家训练,号称全球第一个「图形化私教」。
它的核心设计是:学生问问题,Koji 不直接给答案,而是通过图形化工具引导学生一步步想出来。背后的逻辑是:给一个答案,学生少思考一次;少思考一次,这个能力就少长一点。
AI 教育工具大多在比谁能更快、更全地给出正确答案,Koji 反着走。这个方向能不能成,取决于家长和学生愿不愿意接受一个「故意不帮你」的 AI。
07|Opus 4.8 上线当天,社区测出写作能力不如 4.6
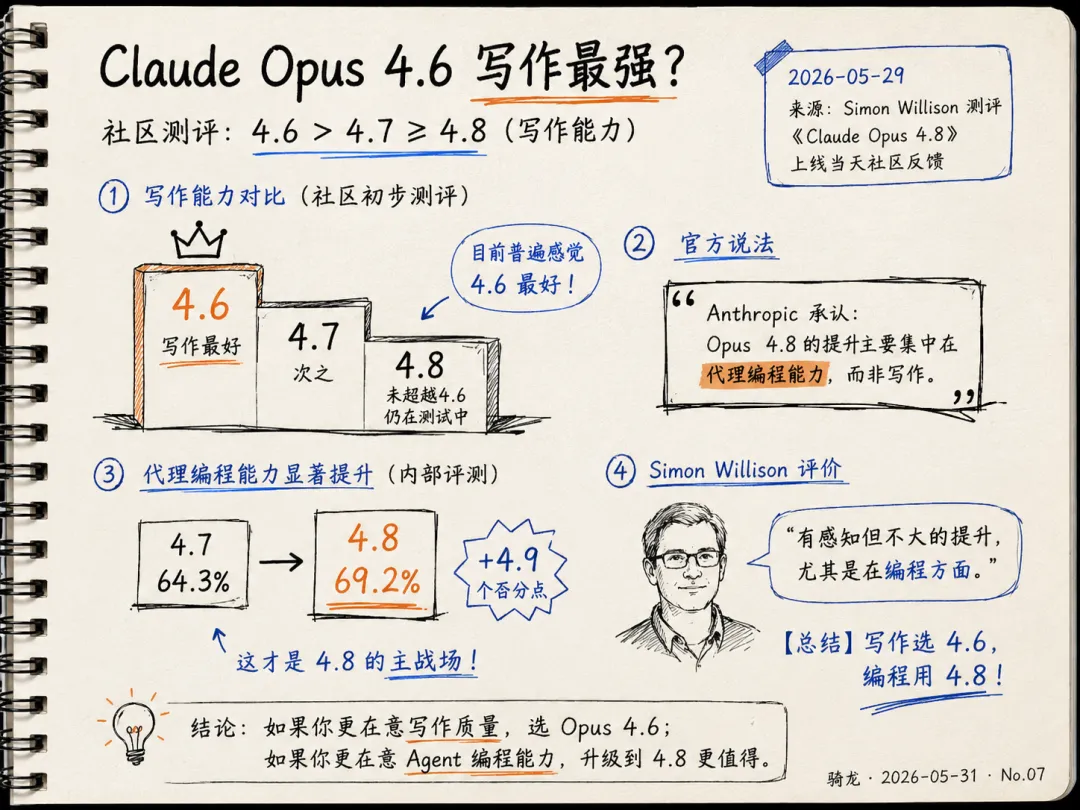
Claude Opus 4.8 刚上线,社区马上开始横评。业内开发者的测试结论:写作能力 Opus 4.6 肯定强于 4.7,4.8 是否能超过 4.6 还在测试中,目前感觉仍是 4.6 最好。
这个结论和 Simon Willison 的评测方向一致——他把 Opus 4.8 评为「有感知但不大的提升」,增益主要集中在代理编程和任务自动化,不是写作。
Anthropic 每次发新模型,提升最明显的往往是代码和推理这条线,写作不是主战场。Opus 4.8 的设计目标是更可靠的 Agent,不是更好的文案工具。如果你主要用 Claude 写东西,4.6 依然是选项。
骑龙 · 2026-05-31
