 夜雨聆风
夜雨聆风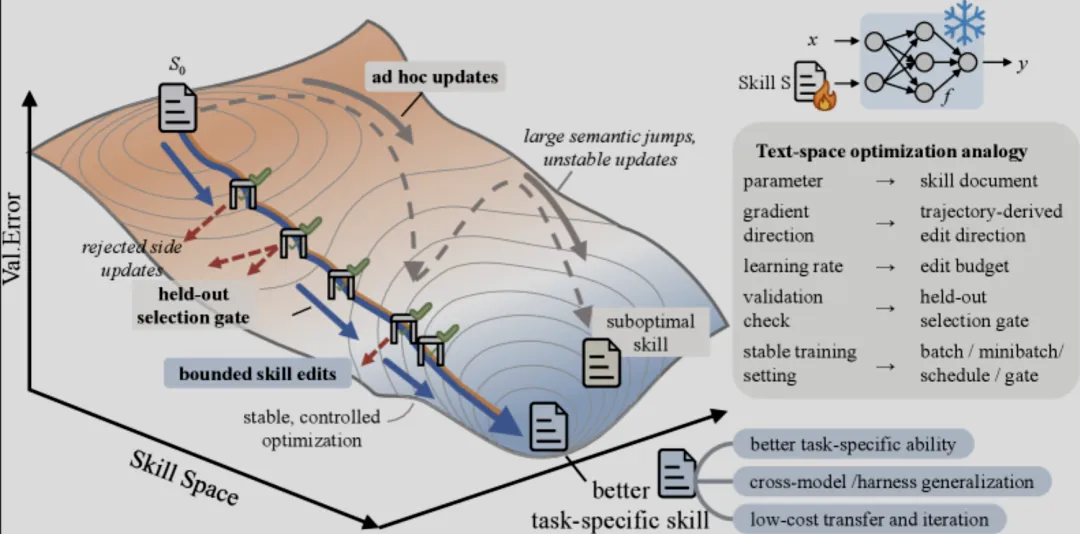
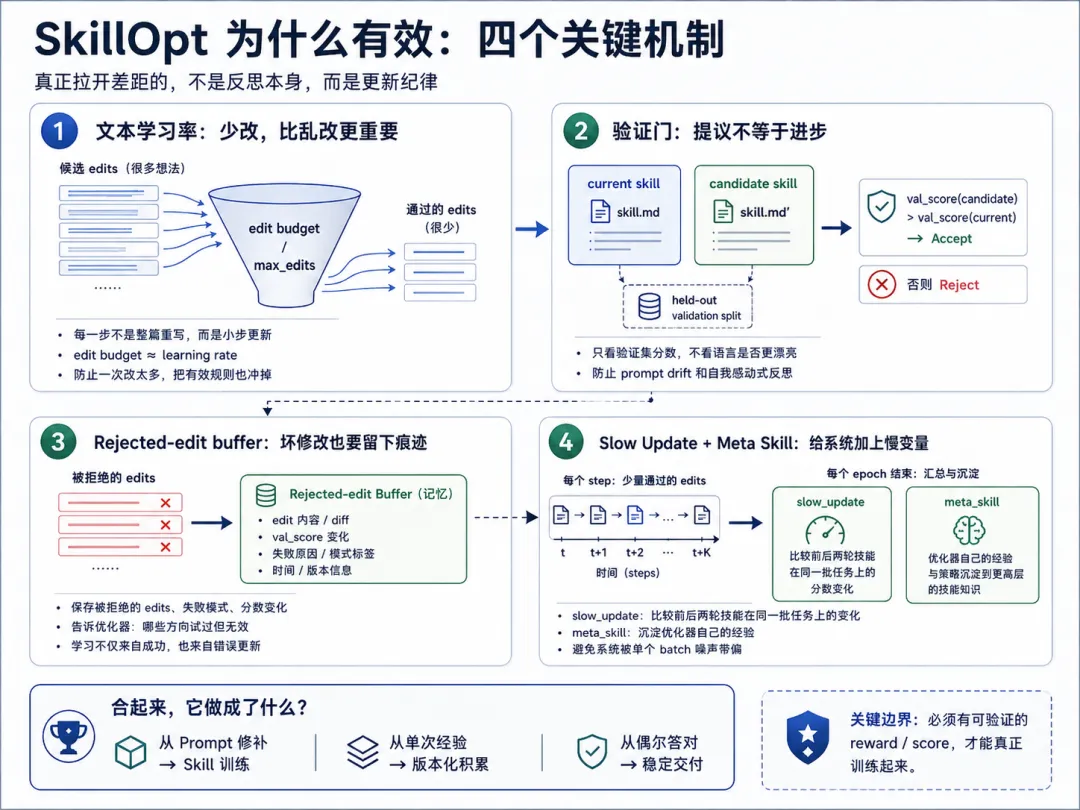
过去一年,Agent 工程最常见的优化方式,仍然是改 Prompt。模型答错了,补一条规则;工具调用乱了,加一段约束;输出格式不稳定,再塞几个示例。短期看,这些修补当然有效,但几轮之后,系统提示词往往会变成一份没人敢动的“祖传配置文件”:规则越来越长,边界越来越模糊,旧约束和新约束互相打架,换个模型或者换个执行环境,原来的经验又可能失效。
这不是 Prompt 工程师不努力,而是这套方法天然缺少训练纪律。传统 Prompt 修补很难回答几个基本问题:一次该改多少?修改依据来自单个失败样本,还是来自一批轨迹的共性?改完以后有没有独立验证?验证失败的修改是否会被记录,避免下次换个说法再犯?如果这些问题没有系统答案,所谓“反思”很容易变成自我安慰。
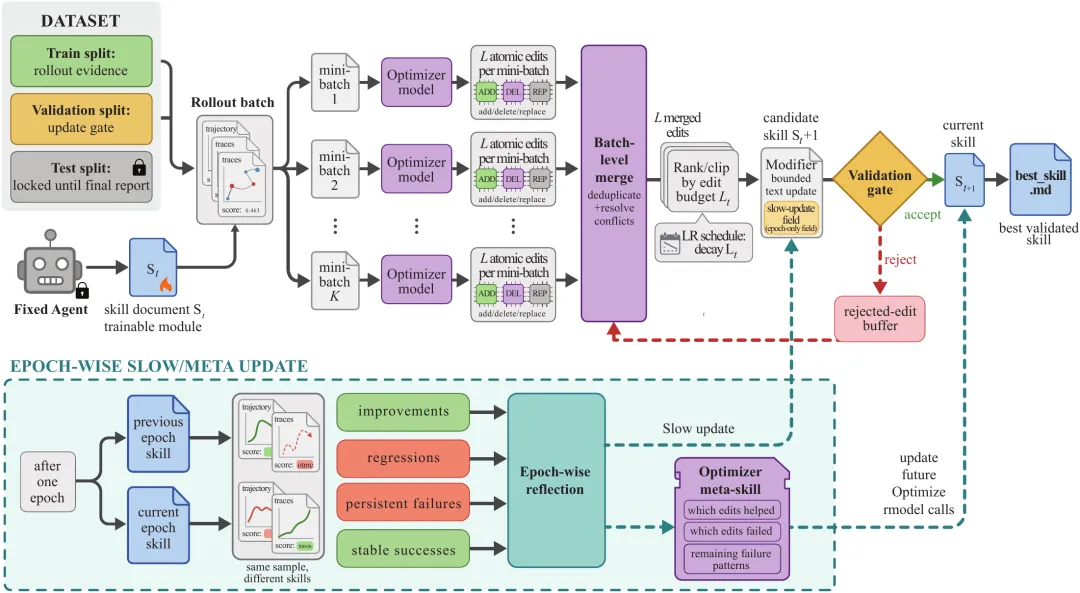
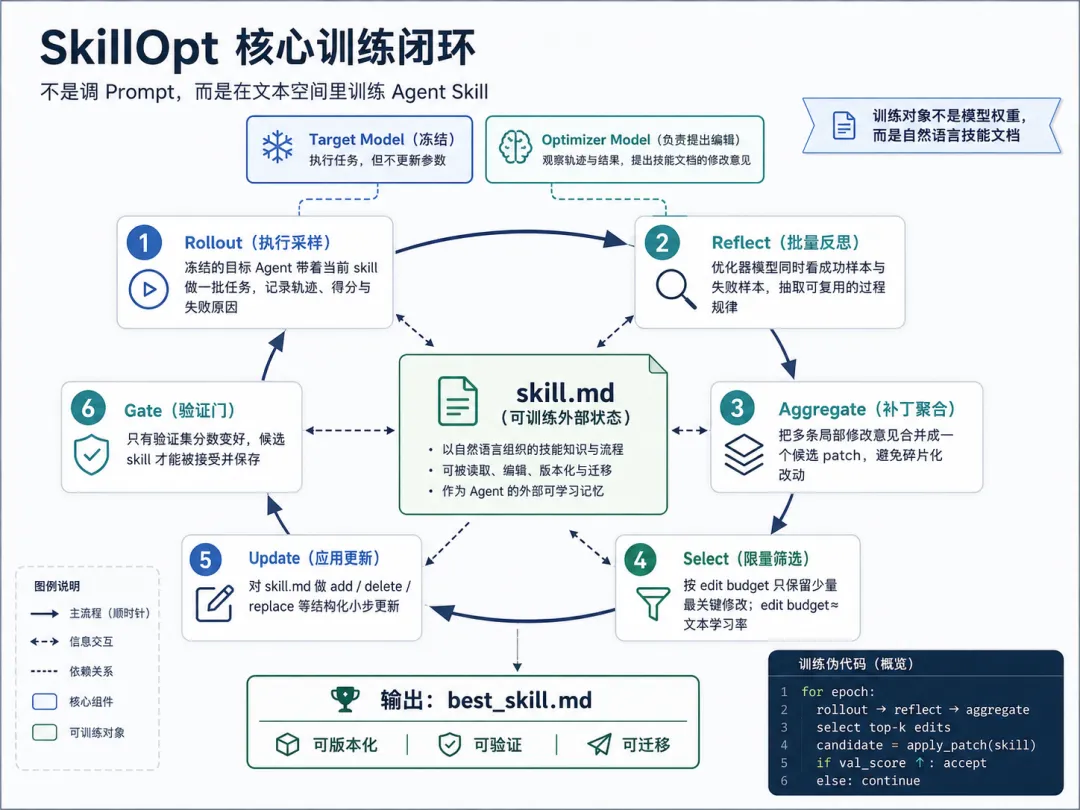
微软 SkillOpt 的价值正在这里。它不是又一个自动改 Prompt 的小工具,而是把一份自然语言写成的 skill.md 当成可训练状态,放进一个类似神经网络训练的闭环里:Agent 先带着当前 Skill 执行一批任务,系统记录轨迹和分数;优化器模型根据成功与失败样本提出结构化 edits;这些 edits 经过合并、排序、限量筛选,再应用到 Skill 文档上;最后只有在验证集上真正提升的 candidate skill,才会被接受。
换句话说,SkillOpt 训练的不是模型权重,而是 Agent 的外部工作方法。
一、SkillOpt 的核心判断:训练程序,而不是训练权重
SkillOpt 最重要的一句话,不是“自动优化 Skill”,而是“Train the procedure, not the weights”。在它的设定里,目标模型冻结,执行 harness 固定,工具环境固定,真正被更新的是一份紧凑的自然语言 Skill 文档。
普通 Prompt 优化通常是:
失败案例 → 总结原因 → 重写 Prompt → 再试一次SkillOpt 的路径更接近训练系统:
skill.md→ rollout 执行采样→ reflect 批量反思→ aggregate 聚合补丁→ select 限量筛选→ update 应用修改→ gate 验证接受→ best_skill.md这两条路径看起来相似,实则完全不同。前者把“改完”当成结果,后者把“验证集提升”当成结果;前者依赖经验判断,后者用 held-out selection split 做裁判;前者容易让 Prompt 变长、变乱、变脆,后者用 edit budget、patch 操作和 gate 机制限制更新幅度。
这就是 SkillOpt 的第一性原理:Agent 不应该只会反思,而应该让反思进入一个可恢复、可版本化、可验证的训练过程。
README 里的输出目录已经暴露了它的本质:
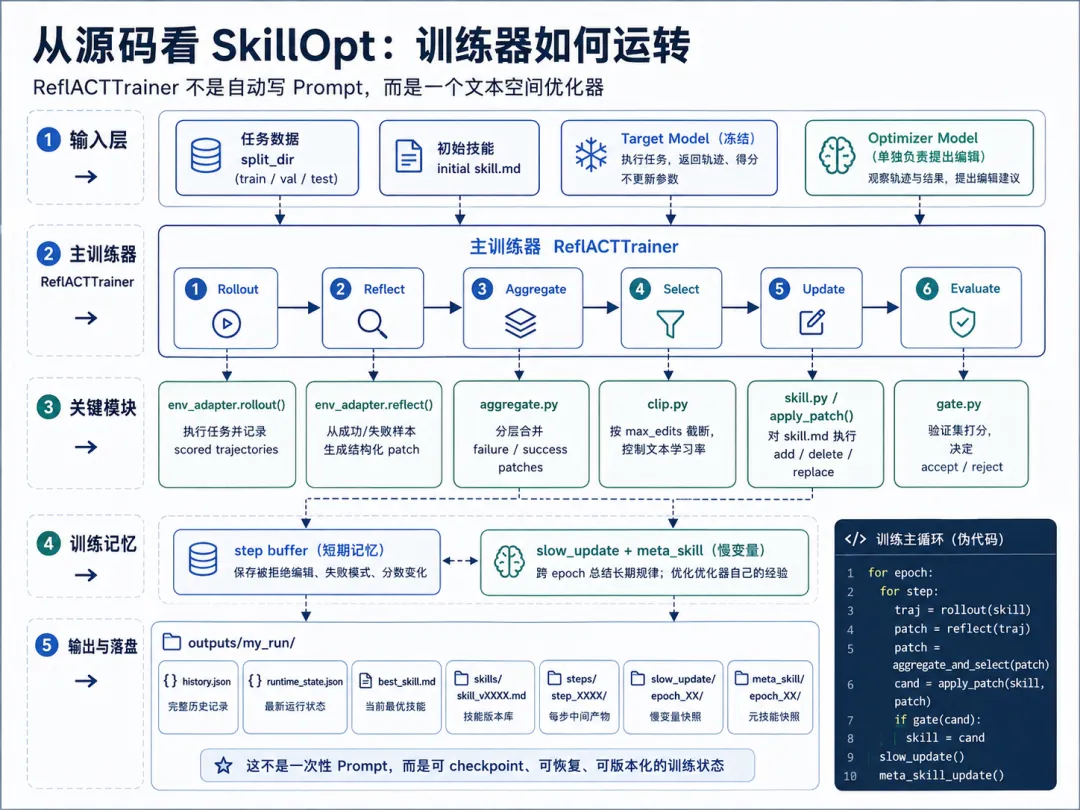
outputs/<run_name>/├── config.json├── history.json├── runtime_state.json├── best_skill.md├── skills/skill_vXXXX.md├── steps/step_XXXX/├── slow_update/epoch_XX/└── meta_skill/epoch_XX/这不是一个 Prompt 工具的输出结构,而是训练系统的输出结构。runtime_state.json 说明训练可以恢复,history.json 说明每一步可追踪,skills/skill_vXXXX.md 说明 Skill 是版本化状态,steps/step_XXXX/ 保留中间产物,slow_update/ 和 meta_skill/ 则说明它不只做单步修补,还有 epoch 级别的长期记忆。
二、从源码看:ReflACTTrainer 如何把反思变成训练
SkillOpt 的主控逻辑集中在 skillopt/engine/trainer.py。如果只看模块导入,整个框架的骨架已经很清楚:
from skillopt.evaluation.gate import evaluate_gate, select_gate_scorefrom skillopt.gradient.aggregate import merge_patchesfrom skillopt.optimizer.meta_skill import run_meta_skillfrom skillopt.optimizer.clip import rank_and_selectfrom skillopt.optimizer.lr_autonomous import decide_autonomous_learning_ratefrom skillopt.optimizer.skill import apply_patch_with_reportfrom skillopt.optimizer.slow_update import build_comparison_pairs, run_slow_update这些函数名背后是一条完整训练链路。merge_patches 负责把多条局部反思合并成候选 patch,rank_and_select 按 edit budget 做截断,apply_patch_with_report 把 patch 应用到 skill.md,evaluate_gate 决定接受还是拒绝,run_slow_update 做跨 epoch 的长期总结,run_meta_skill 则进一步沉淀优化器自身的经验。
env_adapter.rollout() | |||
env_adapter.reflect() | |||
aggregate.py / merge_patches | |||
clip.py / rank_and_select | max_edits 截断候选修改 | ||
skill.py / apply_patch_with_report | skill.md 执行 add/delete/replace | ||
gate.py / evaluate_gate | |||
slow_update.py | |||
meta_skill.py |
把主循环抽象出来,核心逻辑大致如下:
skill = load_initial_skill()best_skill = skillcurrent_score = eval_on_validation(skill)for epoch in range(num_epochs): for step in range(steps_per_epoch): trajectories = rollout(target_agent, skill, train_batch) raw_patches = reflect( optimizer_model, trajectories, current_skill=skill, rejected_history=step_buffer, meta_skill=meta_skill, ) merged_patch = merge_patches(skill, raw_patches) selected_patch = rank_and_select( skill, merged_patch, max_edits=edit_budget, ) candidate_skill = apply_patch_with_report( skill, selected_patch, ) candidate_score = eval_on_validation(candidate_skill) if candidate_score > current_score: skill = candidate_skill current_score = candidate_score best_skill = maybe_update_best(skill) else: step_buffer.append(rejected_patch) skill = run_slow_update(...) meta_skill = run_meta_skill(...)这段伪代码的重点,不是 LLM 能不能提出反思,而是每个反思都必须经过一连串工程约束。SkillOpt 不允许优化器模型随意重写全文,也不允许看起来合理的建议直接进入系统;它把反思变成候选补丁,把补丁变成 candidate skill,再让验证集决定 candidate skill 能不能进入下一轮。
很多 self-reflection Agent 的问题就在这里。它们不缺“反思”,甚至反思很多,但反思之后往往默认生效。结果是 Prompt 越改越长,规则越来越互相冲突,系统逐渐发生 prompt drift。SkillOpt 真正解决的不是“让模型更会总结错误”,而是“让错误总结只能在验证通过后变成系统状态”。
三、Rollout 与 Reflect:语言空间里的 forward / backward
SkillOpt 的第一步是 rollout。它不是简单让 Agent 做题,而是让冻结的目标 Agent 带着当前 Skill 去执行一批任务,并把可训练证据记录下来:任务 ID、任务类型、执行轨迹、工具调用、预测结果、参考答案、hard score、soft score、失败原因。对训练系统来说,这些 scored trajectories 才是后续反思的原料。
如果用神经网络类比,rollout 相当于 forward pass。神经网络 forward 得到 loss,SkillOpt rollout 得到带分数和失败模式的轨迹。区别在于,SkillOpt 没有数值梯度,所以它需要让 optimizer model 把轨迹转成语言空间里的修改方向。
这就是 reflect。优化器模型不是只看一个失败样本,而是同时看成功样本和失败样本,从一批轨迹里抽取可复用的过程规律。例如在表格任务里,失败可能不是模型不会算,而是操作过程不稳定:没有先检查 workbook 结构,没有确认目标 sheet 和 cell,写入后没有重新打开验证,或者把公式误覆盖成静态值。这样的失败如果只总结成“以后更仔细”,没有任何训练价值;SkillOpt 要的是能落到 skill.md 上的结构化 edit。
一个候选 edit 可能长这样:
{ "op": "append", "content": "Before modifying a spreadsheet, inspect workbook structure, target sheet names, and required output cells.", "support_count": 6, "source_type": "failure"}也可能是替换某条旧规则:
{ "op": "replace", "target": "Write the answer directly.", "content": "Verify the intermediate result with the relevant tool before writing the final answer.", "support_count": 4, "source_type": "failure"}这就是 SkillOpt 的“文本梯度”。神经网络更新的是权重矩阵,SkillOpt 更新的是自然语言规则;神经网络靠 learning rate 控制步长,SkillOpt 靠 edit budget 控制每一步最多改多少;神经网络有验证集防止过拟合,SkillOpt 也用验证门决定 candidate skill 是否能留下。
四、真正难的不是反思,而是控制更新
从 reflect 到 update,中间最容易被忽略的是三件事:合并、限量、应用。它们看起来像工程细节,其实决定了 SkillOpt 是否会退化成普通 Prompt 重写。
首先是 aggregate.py。Reflect 会产生很多 patch,如果直接全部写进 Skill,文档很快会膨胀。SkillOpt 采用分层合并:先把 patch 按 batch 分组,同层并行 merge,再逐层向上合并,直到得到一个全局候选 patch。更重要的是,failure patches 和 success patches 会分开处理。失败样本告诉系统哪些地方经常错,成功样本则提醒系统哪些已有行为不能被破坏。只看失败,Skill 会过度保守;只看成功,又无法修复系统性错误。SkillOpt 的选择是 failure-first,但不丢 success,这非常符合稳定性优化的工程直觉。
然后是 clip.py 里的 rank_and_select。它的作用可以概括成一句话:少改,比乱改更重要。优化器模型会对候选 edits 排序,系统只保留 top-L,其中 max_edits 就是文本空间里的 learning rate。学习率太小,系统学得慢;学习率太大,一步跨太远,容易把原来有效的规则也冲掉。传统 Prompt 修补经常在这里失控:一次失败之后大段重写,短期看解决了当前问题,长期看却破坏了已有能力。SkillOpt 用 edit budget 把更新限制在小步范围内。
最后是 apply_patch_with_report。它支持的基本操作并不复杂:append、insert_after、replace、delete。关键在于这些操作是结构化的、可审计的、可回放的,而不是让 LLM 自由重写整篇文档。replace 和 delete 找不到 target 会跳过,insert_after 找不到 target 可以 fallback 成 append,slow update 区域则是 protected region,不能被普通 step-level edit 随意覆盖。
max_edits | ||
这几步合起来,解决的是同一个问题:LLM 的反思能力很强,但更新能力必须被约束。没有约束,反思会变成漂移;有约束,反思才可能变成训练。
五、Gate、Rejected Buffer、Slow Update:SkillOpt 拉开差距的地方
如果只能记住 SkillOpt 的一个机制,应该记住 validation gate。它的逻辑很朴素:candidate skill 在 held-out selection split 上的分数,如果超过 current skill,就接受;如果超过历史最好,就成为新的 best skill;否则拒绝。
def evaluate_gate(candidate_score, current_score, best_score): if candidate_score > current_score: if candidate_score > best_score: return "accept_new_best" return "accept" return "reject"这一步把“自我反思”变成了 propose-and-test。LLM 可以提出建议,但不能自证正确;语言更漂亮不算进步,解释更合理也不算进步,只有验证集分数提升才算进步。很多 Agent 框架把反思本身当成能力,SkillOpt 则更冷酷:反思只是候选,验证才是裁判。
更进一步,被拒绝的 edits 不会直接丢掉,而是进入 rejected-edit buffer。这里保存的不只是 edit 内容,还包括验证集分数变化、失败原因、失败模式和版本信息。它的作用很像负反馈记忆:告诉优化器哪些方向看似合理,但试过以后会让验证集掉分。一个成熟组织不仅要沉淀 best practice,也要沉淀 bad practice;否则同一种坏方案会换个名字反复出现。SkillOpt 在训练系统里做了同样的事。
Slow Update 则解决另一个问题:单步更新容易被 batch 噪声带偏。它在 epoch 结束时比较上一轮 Skill 和当前 Skill 在同一批样本上的表现,把变化分成四类:wrong → right 是 improved,right → wrong 是 regressed,wrong → wrong 是 persistent fail,right → right 是 stable success。这样一来,系统看到的不只是“这一步有没有变好”,还包括“一个 epoch 之后哪些能力真的改善、哪些能力退化、哪些错误一直没解决”。
Meta Skill 是更隐蔽的一层。Slow Update 更新的是目标 Agent 的 Skill,Meta Skill 更新的是优化器自己的经验。也就是说,SkillOpt 不只训练 Agent 的工作方法,还在训练“如何训练工作方法”:哪些类型的 edits 更容易通过 gate,哪些修改方向容易造成退化,什么时候应该补规则,什么时候应该删掉冲突规则。这一层不会进入最终部署的 best_skill.md,但会影响训练期间 optimizer model 如何提出下一轮修改。
六、结果表真正说明了什么?
SkillOpt 项目页给出的主结果很直接:在 6 个 benchmark、7 个 target models、Codex 与 Claude Code 等执行 harness 组合中,SkillOpt 在 52/52 个评测组合里达到最佳或并列最佳。更重要的是,它不是只在某个强模型上有效,而是在 GPT 与 Qwen、小模型与强模型、direct chat 与代码执行 harness 中都有提升。
这张表最值得看的不是“平均提升多少”,而是提升集中出现在程序性任务上:SpreadsheetBench、OfficeQA、LiveMath、ALFWorld 都是需要执行过程的任务。它们不是单纯问答,而是涉及文件、工具、验证、步骤、环境状态。SkillOpt 在这些地方提升更明显,说明它学到的不是“更会说”,而是“更会做”。
消融实验也能解释为什么它有效。
这张表很关键。去掉 learning rate,分数会掉;去掉 rejected buffer,分数会掉;去掉 meta skill + slow update,SpreadsheetBench 从 77.5 掉到 55.0。也就是说,SkillOpt 的提升不是因为“多反思几次”这么简单,而是来自一整套训练控制:有足够 evidence,有受限更新,有失败记忆,有长期慢变量,有验证门。
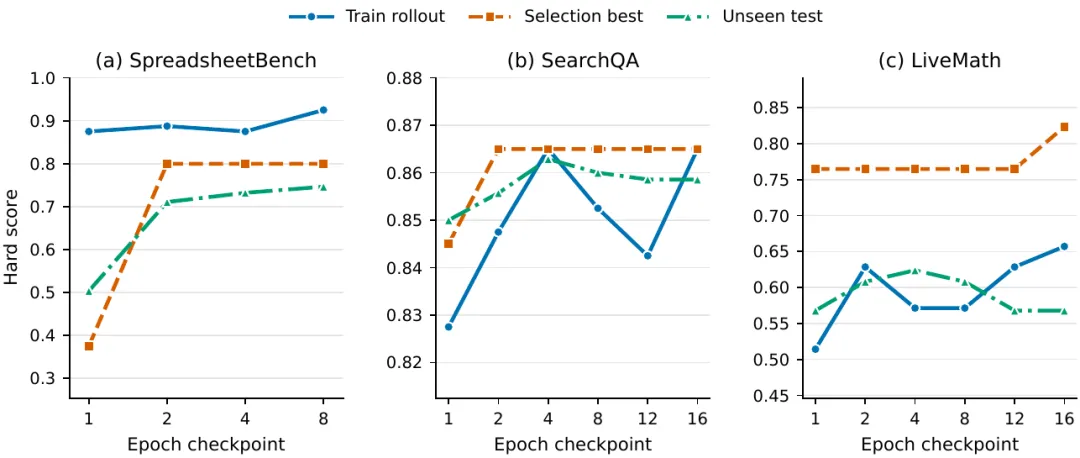
官方趋势图也说明了这一点。选择集上的 best checkpoint 和 unseen test 表现基本同向,说明 gate 不是简单过拟合验证集,而是在选出更可能泛化的 Skill。
七、为什么 SkillOpt 能迁移?
如果 SkillOpt 只是把 benchmark 题目背下来,它换模型、换 harness、换相近任务就应该失效。但项目页和论文都展示了跨模型、跨 harness、跨 benchmark 的迁移结果。原因并不神秘:SkillOpt 学到的不是答案,而是过程。
best_skill.md,不需要 optimizer memory |
以表格任务为例,一个优化后的 Skill 可能不会记住某道题的具体答案,但会学到一套稳定的操作程序:先检查 workbook 结构,确认目标 sheet 和 cell,用工具读取真实内容,不凭记忆猜文件状态,写入后重新打开验证,最终输出前核对结果。这样的内容不是题库记忆,而是工作规程,因此可以迁移到另一个模型,甚至另一个执行环境。
这也是 SkillOpt 部署形态很轻的原因。训练阶段需要 rollout、reflect、merge、gate、slow update;部署阶段只需要把 best_skill.md 交给目标 Agent。优化器模型、训练日志、rejected buffer 都不需要跟着上线。训练过程可以重,执行过程必须轻,这非常符合企业 Agent 的落地规律。
八、边界也很清楚:没有可验证 reward,就没有真正训练
SkillOpt 不适合被神化。它最适合的任务有一个共同特征:可验证。代码测试是否通过,表格是否修改正确,问答答案是否命中,数学结果是否正确,文档抽取是否匹配,环境任务是否完成。这些任务都有相对明确的 score 或 reward,Gate 才能发挥作用。
如果任务高度开放,例如战略判断、创意写作、组织管理建议,验证信号就会变弱。没有可靠验证集,SkillOpt 很容易退化成“看起来很聪明的自我修辞”。所以它真正适合先落地的,不是所有 Agent,而是高频、重复、可评分、可复盘的工作流。
这类任务有稳定分布,有失败样本,有验证标准,也有持续优化价值。Agent 的训练,应该从这里开始。
结语:SkillOpt 最值得关注的地方
SkillOpt 最值得关注的地方,不是它把某个 benchmark 刷高了多少分,而是它把 Agent skill 从“提示词资产”推进到了“可训练软件资产”。
以前我们说 AI Agent 工程化,主要讲 harness:文件、工具、权限、sandbox、测试、工作流。SkillOpt 补上了另一块:Agent 的做事方法本身,也要有训练循环。
它不是 fine-tuning 的替代品,也不是 harness 的替代品。它更像第三层:
模型权重:提供通用智能harness:提供可执行环境skill:提供领域做事方法过去大家疯狂卷第一层,最近开始卷第二层。SkillOpt 提醒我们,第三层可能才是企业最容易沉淀壁垒的地方。模型会换,harness 会更新,但你在真实业务里踩过的坑、总结过的规则、验证过的流程,会变成别人拿不到的 procedural memory。
这也是我对 SkillOpt 的最终判断:它不是 prompt 优化器,而是一台 skill 训练机。
如果你做 Agent,还在把失败案例扔进聊天记录里,那就太浪费了。把失败轨迹留住,把高频错误聚类,把候选规则写成 patch,用 held-out 任务拦一下。能过门的,才配进入 skill。
这可能比再换一个更贵的模型,更接近 Agent 真正可用的答案。
子非AI,焉知AI之乐
如果你正在做 Agent 项目,别急着写第 101 条 prompt。先挑 20 个真实失败案例,做一个小 selection set,然后问自己一句:
这次失败,是模型不够聪明,还是你的 Agent 根本没有被训练过“该怎么做事”?
