 夜雨聆风
夜雨聆风
大多数人对PX4的理解停留在wiki层面——知道有哪些模块,知道EKF2负责估计,知道uORB是消息总线。但wiki告诉你的是"有什么",不是"为什么这样"。
我改了两年PX4的代码,从EKF2边界到uORB性能,从时间同步到高频Buffer。每次改一个模块,都要先搞清楚数据从哪来、到哪去。改多了,整条链路就在脑子里串起来了。
这篇文章做一件事:从IMU采到一个原始数据开始,跟踪它穿越PX4的12个模块,最终变成电机PWM输出的完整路径。读懂这条线,PX4的架构就不再是模块列表,而是一套有设计逻辑的系统。
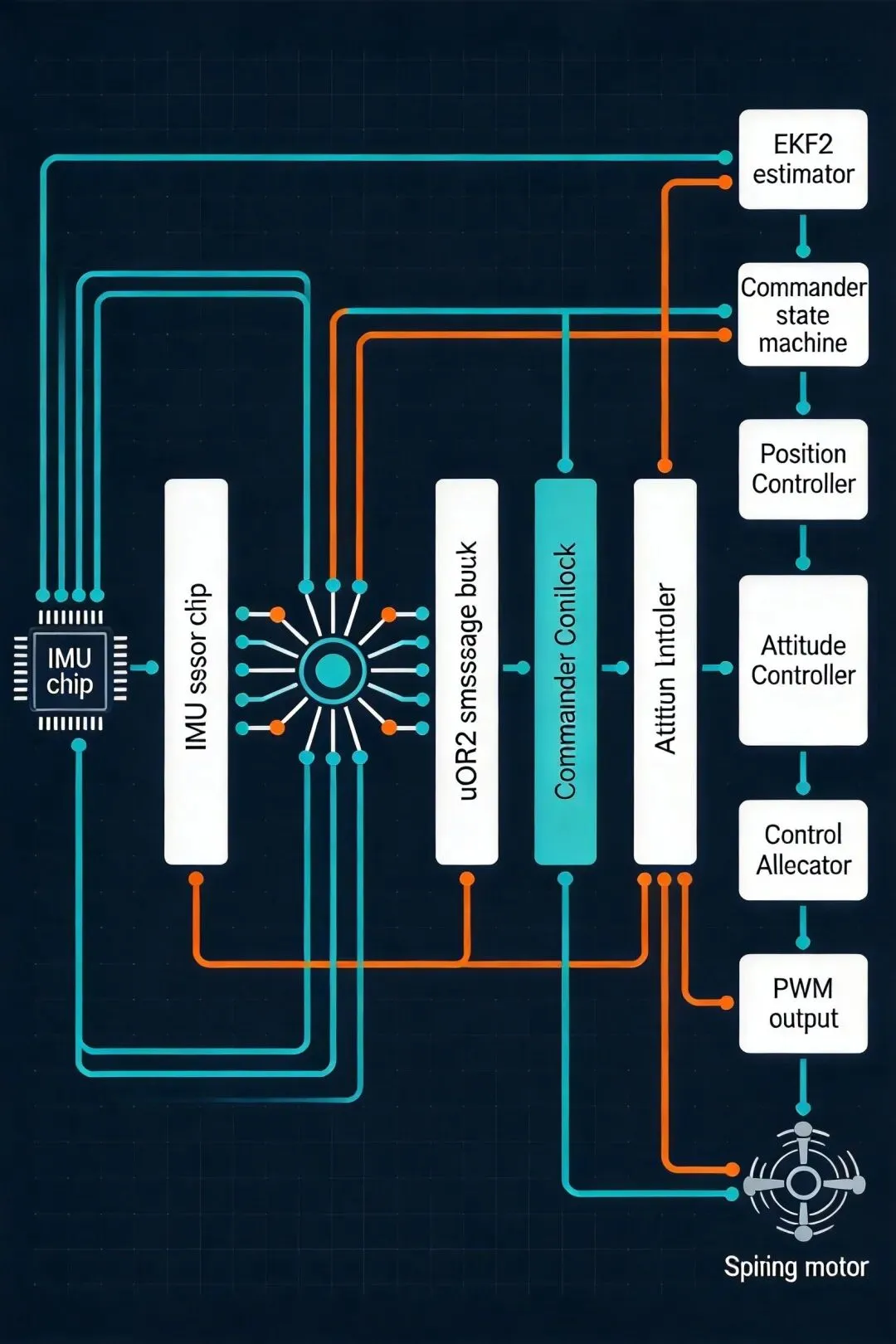
一切从一次中断开始
PX4的代码入口不是main(),是一次硬件中断。
以BMI088 IMU为例,陀螺仪数据就绪后触发SPI中断,驱动里的回调被唤醒:
// src/drivers/imu/bosch/bmi088/BMI088_gyro.cpp
voidBMI088_gyro::Run()
{
// 从SPI读取原始数据
bmi088_gyro_data_t gyro_data;
_gyro.read(&gyro_data);
// 填充uORB消息
sensor_gyro_s gyro_report{};
gyro_report.timestamp = hrt_absolute_time();
gyro_report.x = gyro_data.x * _gyro_scale;
gyro_report.y = gyro_data.y * _gyro_scale;
gyro_report.z = gyro_data.z * _gyro_scale;
// 发布到uORB
_gyro_pub.publish(gyro_report);
}
注意那个hrt_absolute_time()——这是PX4的高精度时间戳,微秒级,来源是STM32的定时器。所有模块的时间基准都靠它,这也是我之前写时间同步方案的起点:一旦多个传感器的时间戳不对齐,后面所有估计都白费。
驱动跑在work_queue上。work_queue不是RTOS的线程,是PX4自己实现的一套协作调度器——每个驱动注册一个回调函数和执行周期,调度器按优先级轮转调用。好处是省内存(不用给每个驱动分配独立栈),代价是回调里不能阻塞。
这个设计决定了PX4驱动的写法:读取→填充→发布,一气呵成,中间不能等。
uORB:40万行代码的血管系统
PX4有200多个uORB主题(topic)。每个主题就是一个结构体类型,发布者往里写,订阅者从中读,发布者和订阅者互相不知道对方存在。
核心API只有四个:
orb_advertise(ORB_ID(sensor_gyro), &gyro_report); // 我要发布这个主题
orb_subscribe(ORB_ID(sensor_gyro)); // 我要订阅这个主题
orb_publish(ORB_ID(sensor_gyro), handle, &gyro_report); // 发布一条数据
orb_copy(ORB_ID(sensor_gyro), handle, &gyro_report); // 读取最新数据
看起来简单,但uORB解决了一个飞控系统的核心矛盾:模块间必须通信,但模块不能互相依赖。
为什么?因为飞控的模块组合是动态的——同一段代码跑在多旋翼上要配mc_pos_control,跑在固定翼上要配fw_pos_control,跑在VTOL上两种都要。如果模块之间直接调用函数,改一个模块就要改所有调用方。uORB把"谁需要这个数据"这个问题推迟到运行时,编译时只依赖一个头文件。
ORB_ID是个宏技巧:
#define ORB_ID(name) &orb_metadata_##name
编译器会为每个主题生成一个元数据结构体,包含主题名、数据大小、优先级等信息。这意味着主题注册是编译期确定的,运行时零开销。加一个新主题只需要在.msg文件里定义结构体,构建系统自动生成对应的C/C++头文件和ORB_ID。
我之前做uORB减负优化时发现一个细节:每次orb_copy都会memcpy整个结构体。当订阅者多、结构体大时,这个开销不可忽略。这就是为什么sensor_combined_s里塞了太多字段后性能会退化——不是计算慢,是搬运慢。
EKF2:第一个消费者
IMU数据发布到uORB后,第一个重要消费者是EKF2。
// src/modules/ekf2/EKF2.cpp
voidEKF2::Run()
{
// 订阅所有需要的传感器
sensor_combined_s sensor;
orb_copy(ORB_ID(sensor_combined), _sensor_sub, &sensor);
// 运行EKF预测+更新
_ekf.update(sensor.timestamp, sensor.gyro_rad, sensor.accelerometer_m_s2);
// 发布估计结果
vehicle_attitude_s att{};
att.timestamp = sensor.timestamp;
att.q[0] = _ekf.getStateQuaternion()(0);
// ...
_att_pub.publish(att);
vehicle_local_position_s pos{};
pos.timestamp = sensor.timestamp;
pos.x = _ekf.getStatePosition()(0);
// ...
_pos_pub.publish(pos);
}
EKF2的输入是融合后的sensor_combined_s(不是原始sensor_gyro_s——中间有个sensor模块做多IMU投票和优先级选择),输出是姿态(quaternion)和位置/速度。
一个关键设计:EKF2以固定频率运行(默认250Hz),不跟随传感器频率。传感器可能以800Hz或1kHz采样,但EKF2只取自己需要的数据。这层解耦保证了估计器行为可预测——不会因为传感器换了一个更快的型号就导致计算量暴增。
代价是传感器数据到估计输出之间有一个固定的延迟窗口,最多一个EKF周期(4ms)。在高速机动时这个延迟能感知到,这也是我写EKF时间状态扩展时想解决的问题——把预测步提前,补偿这个延迟。
EKF2输出两个核心主题:vehicle_attitude和vehicle_local_position。这两个主题驱动了PX4后续几乎所有模块。
Commander:状态机的中枢神经
Commander不碰数据,它碰状态。
哪个模式?是否解锁?是否故障?GPS锁定了吗?这些决策全在Commander里。
// src/modules/commander/commander.cpp
voidCommander::run()
{
// 检查所有安全条件
bool armed = _arm_auth.is_armed();
bool home_set = _home_position.is_valid();
bool global_pos_valid = _global_position.isValid();
// 状态机转换
if (should_disarm(armed)) { disarm(); }
if (should_failsafe(armed, global_pos_valid)) { activate_failsafe(); }
// 发布模式切换
vehicle_status_s status{};
status.nav_state = _nav_state; // OFFBOARD, POSCTL, AUTO.MISSION...
status.arming_state = _arming_state;
_status_pub.publish(status);
}
Commander是PX4里最"脏"的模块——大量if-else,大量状态检查,代码量大但很难拆分。因为飞行安全逻辑天然就是一堆规则组合:电池低于多少?GPS丢了几秒?遥控器断连多久?每个条件对应一个动作,这些动作之间还有优先级冲突。
读懂Commander的关键不是看代码,是看状态转换图。PX4文档里有,但源码里的注释更准确——文档偶尔滞后,代码不会。
控制链:从目标位置到PWM占空比
这是PX4最核心的链路,也是最常被误解的部分。很多人以为飞控的控制是一步到位的——给它一个目标位置,它直接算出电机转速。不是。
PX4的控制链是四层串级:

位置控制器 (mc_pos_control)
输入: 目标位置 + 当前位置
输出: 目标速度
↓
速度控制器 (mc_pos_control)
输入: 目标速度 + 当前速度
输出: 目标推力方向 + 目标加速度
↓
姿态控制器 (mc_att_control)
输入: 目标姿态 + 当前姿态
输出: 目标角速度
↓
角速度控制器 (mc_att_control)
输入: 目标角速度 + 当前角速度
输出: 力矩需求 (roll/pitch/yaw torque + 总推力)
位置和速度控制器在同一个模块mc_pos_control里,姿态和角速度控制器在mc_att_control里。每个控制器的输出是下一个控制器的输入,环环相扣。
// src/modules/mc_pos_control/mc_pos_control_main.cpp
voidMulticopterPositionControl::Run()
{
vehicle_local_position_s pos;
orb_copy(ORB_ID(vehicle_local_position), _pos_sub, &pos);
// 位置环 → 速度设定值
_pos_control.setPositionSpd(_pos_sp);
_vel_sp = _pos_control.update(pos.x, pos.y, pos.z);
// 速度环 → 推力方向 + 加速度
_vel_control.setVelSpd(_vel_sp);
_thrust_sp = _vel_control.update(pos.vx, pos.vy, pos.vz);
// 发布推力设定值和姿态设定值
vehicle_rates_setpoint_s rates_sp{};
rates_sp = _vel_control.getRatesSetpoint();
_rates_sp_pub.publish(rates_sp);
}
为什么拆四层而不是一层?因为不同层的动态特性差异巨大。位置变化是秒级的,姿态变化是百毫秒级的,角速度变化是十毫秒级的。如果用一个大控制器统一处理,带宽差异会导致内环响应被外环拖慢。串级结构让每层独立调参、独立响应。
但串级也有代价——每经过一层就多一个延迟。从位置设定值到电机输出,数据要穿过四层控制器,加上EKF2的估计延迟和uORB的传输延迟,总延迟在20-40ms量级。这个延迟在悬停时无感,在高速穿越或大机动时就是姿态振荡的根源。
Control Allocator:从力矩到电机
角速度控制器输出的是力矩需求(roll/pitch/yaw torque + 总推力),但电机不理解力矩,只理解转速。从力矩到转速的转换由Control Allocator完成。
// src/modules/control_allocator/control_allocator_main.cpp
voidControlAllocator::update()
{
// 力矩需求
float roll_torque = _control_allocation[0];
float pitch_torque = _control_allocation[1];
float yaw_torque = _control_allocation[2];
float thrust = _control_allocation[3];
// 根据机型矩阵分配到各电机
// 矩阵在ROMFS里定义,四旋翼是4x4,六旋翼是4x6
matrix::Vector<float, MAX_NUM_ACTUATORS> actuator_sp;
actuator_sp = _allocation_matrix * vector_torque_thrust;
// 发布执行器输出
actuator_outputs_s outputs{};
for (int i = 0; i < actuator_sp.size(); i++) {
outputs.output[i] = actuator_sp(i);
}
_outputs_pub.publish(outputs);
}
机型矩阵是这个模块的核心。四旋翼的分配矩阵是4×4(4个电机×3个力矩+1个推力),六旋翼是4×6,八旋翼是4×8。矩阵定义了每个电机对三个力矩轴和一个推力轴的贡献系数——本质上就是电机位置和旋翼方向的几何关系。
这个模块之前叫mixer,用一种自定义的mixer文件格式。后来重写成Control Allocator,用矩阵运算代替,更清晰也更通用。但老的mixer在PWM驱动层还残留着,代码里能同时看到两套。
PWM驱动:最后一公里
// src/drivers/px4fmu/px4fmu.cpp
voidPX4FMU::Run()
{
actuator_outputs_s outputs;
orb_copy(ORB_ID(actuator_outputs), _outputs_sub, &outputs);
// 将归一化值(0-1)转换为PWM脉宽(1000-2000μs)
for (int i = 0; i < _num_outputs; i++) {
uint16_t pwm = 1000 + (uint16_t)(outputs.output[i] * 1000);
_pwm_outputs[i] = pwm;
}
// 写入STM32定时器寄存器
up_pwm_output_set(_pwm_outputs);
}
从1000到2000微秒的PWM脉宽,1对应最低转速(很多电调还会把1000μs以下视为 disarm 信号),2对应最高转速。这是航模领域几十年的标准,PX4没有改它,只是在上面铺了层层抽象。
几个读代码时觉得设计聪明的地方
1. .msg文件自动生成uORB结构体
PX4的uORB主题不在C代码里定义,在msg/目录的.msg文件里:
# msg/vehicle_attitude.msg
uint64 timestamp
float32[4] q
float32[4] delta_q_reset
uint8 reset_counter
构建系统用Python脚本把.msg转成C结构体、Python绑定、Simulink接口。加一个新主题只需要加一个.msg文件,不需要手动写序列化代码或ORB注册代码。这个设计让PX4的主题数量膨胀到200+但仍然可控。
2. 参数系统的编译期生成
同理,参数在src/modules/下各模块的.c或.yaml文件里定义,构建时自动生成param.c和param.h。这意味着参数名、类型、默认值、最小最大值都在编译期确定,运行时只做查表。比运行时解析配置文件快一个数量级。
3. work_queue的优先级反转保护
PX4的work_queue分高/中/低三档优先级(wq_hp, wq_lp, wq_nav_and_ctrl)。IMU驱动跑在wq_hp,EKF2跑在wq_nav_and_ctrl,日志跑在wq_lp。调度器保证高优先级回调先执行,低优先级让路。但有一个细节:如果wq_lp上的日志模块持有了uORB的锁,wq_hp上的IMU驱动在发布时会被阻塞——这就是优先级反转。PX4的解决方案是uORB的发布操作不加锁,用原子操作代替。代价是极端情况下订阅者可能读到半新半旧的数据,但对飞控来说,读到旧数据比读不到数据好。
4. OrbPublication的RAII封装
新版PX4把裸的orb_advertise/orb_publish封装成了模板类:
uORB::Publication<vehicle_attitude_s> _att_pub{ORB_ID(vehicle_attitude)};
// 使用时直接
_att_pub.publish(att);
构造时自动advertise,析构时自动unadvertise。不再需要手动管理handle的生命周期。这个改动很小,但消除了一个常见的资源泄漏bug。
这条线的全貌
画成一条线:
IMU硬件中断
→ SPI读取原始数据 (BMI088驱动, wq_hp)
→ uORB发布 sensor_gyro
→ sensor模块融合多IMU, 发布 sensor_combined
→ EKF2订阅, 运行预测+更新 (wq_nav_and_ctrl)
→ uORB发布 vehicle_attitude + vehicle_local_position
→ Commander检查安全状态, 发布 vehicle_status
→ mc_pos_control: 位置环→速度环, 发布 vehicle_rates_setpoint
→ mc_att_control: 姿态环→角速度环, 发布 actuator_controls
→ Control Allocator: 力矩→电机分配, 发布 actuator_outputs
→ PWM驱动: 归一化值→脉宽, 写入定时器寄存器
→ 电机转动
12个模块,200+个uORB主题,一条数据流。
读懂这条线之后,PX4不再是一个模块列表。每个模块的存在都有原因——它消费了上游的什么数据,产出了下游的什么数据,它的位置能不能换、能不能省。这些是wiki不告诉你的,只有读代码才知道。
代码版本基于PX4 v1.14,部分接口在v1.15中有调整。
