 夜雨聆风
夜雨聆风最近在做时光笺的小宇助手时,我遇到一个很典型的 Agent 工程问题。
用户对小宇说:
明天下午 3 点提醒我开项目评审会这句话看起来很简单,但对系统来说,它有两种完全不同的处理方式。
一种是把它当成普通聊天,让大模型回复一句:
好的,我会提醒你。另一种是把它当成一个真实业务动作:识别用户意图,提取日期和时间,选择待办工具,调用后端接口,然后真的在系统里创建一条待办。
前者只是聊天。
后者才是 Agent。
这篇文章就从这个小场景讲起:用 Spring AI Alibaba 做待办 Agent 时,怎么让一句话真的变成一条业务数据,而不是停留在一段看起来很聪明的回复里。
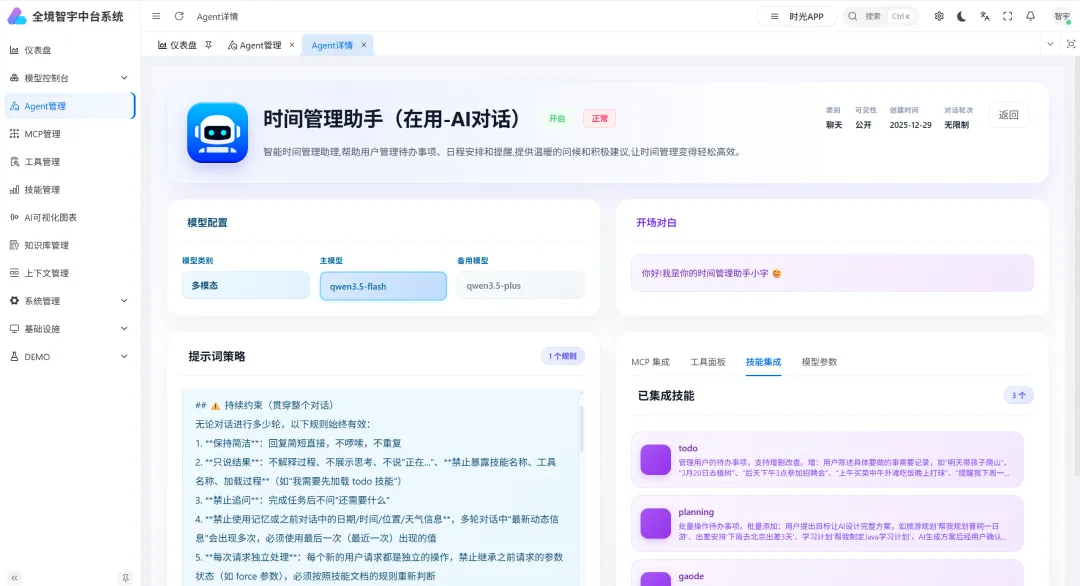
先说真实场景
时光笺里有一个 AI 助手叫小宇。
用户可能会对它说:
明天下午 3 点提醒我开项目评审会如果这是一个普通聊天机器人,它可以很轻松地回复:
好的,我会提醒你。但这句话对产品没有任何意义。
因为系统里并没有多出一条待办。
到了明天下午 3 点,也不会真的提醒用户。
对时间管理工具来说,AI 真正有价值的地方不是“回复得像人”,而是它能把这句话变成一条真实业务数据:
标题:项目评审会日期:明天时间:15:00状态:未完成来源:AI 创建提醒:需要这就是 Agent 和普通聊天入口的分界线。
聊天只需要生成文本。
Agent 要完成一个目标,它需要理解用户意图、选择工具、调用工具、观察结果,然后决定下一步。
这也正是 Spring AI Alibaba 里 ReactAgent 的核心思路:模型不是只输出最终答案,而是在推理和行动之间循环,通过工具调用推进任务。
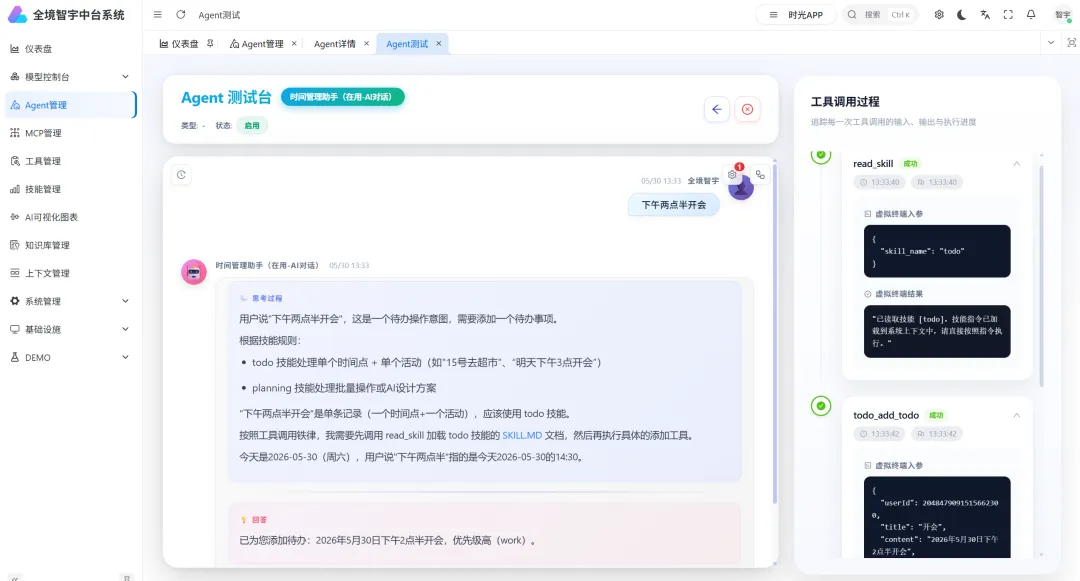
一句话创建待办,难点不在“生成”
从用户角度看,这件事很简单。
说一句话,创建一条待办。
但从系统角度看,这句话至少要经过几层转换。
第一层是意图识别。
用户到底是要创建待办,还是查询今天安排,或者修改已有任务?
比如:
明天下午 3 点提醒我开会这是创建待办。
我今天有什么安排这是查询待办。
把明天的会议改到后天这是修改待办。
帮我规划下周工作这可能是批量规划,不应该简单创建一条单任务。
第二层是字段提取。
创建待办不是把整句话原样塞进数据库。
至少要提取标题、日期、时间、内容、用户、是否提醒等字段。
第三层是工具选择。
单条待办创建,应该走 todo 相关工具。
批量规划,应该走 planning 相关工具。
查询时间范围,又是另一个工具。
第四层是业务校验。
日期格式是否正确?标题是否为空?同一天是否已有未完成待办?如果有冲突,是直接创建,还是让用户确认?
所以这里的核心问题不是“让大模型写一段 JSON”。
真正的问题是:怎么让大模型在受控边界里,稳定地调用正确工具。
必要时还得在链路追踪里面查找具体的调用情况
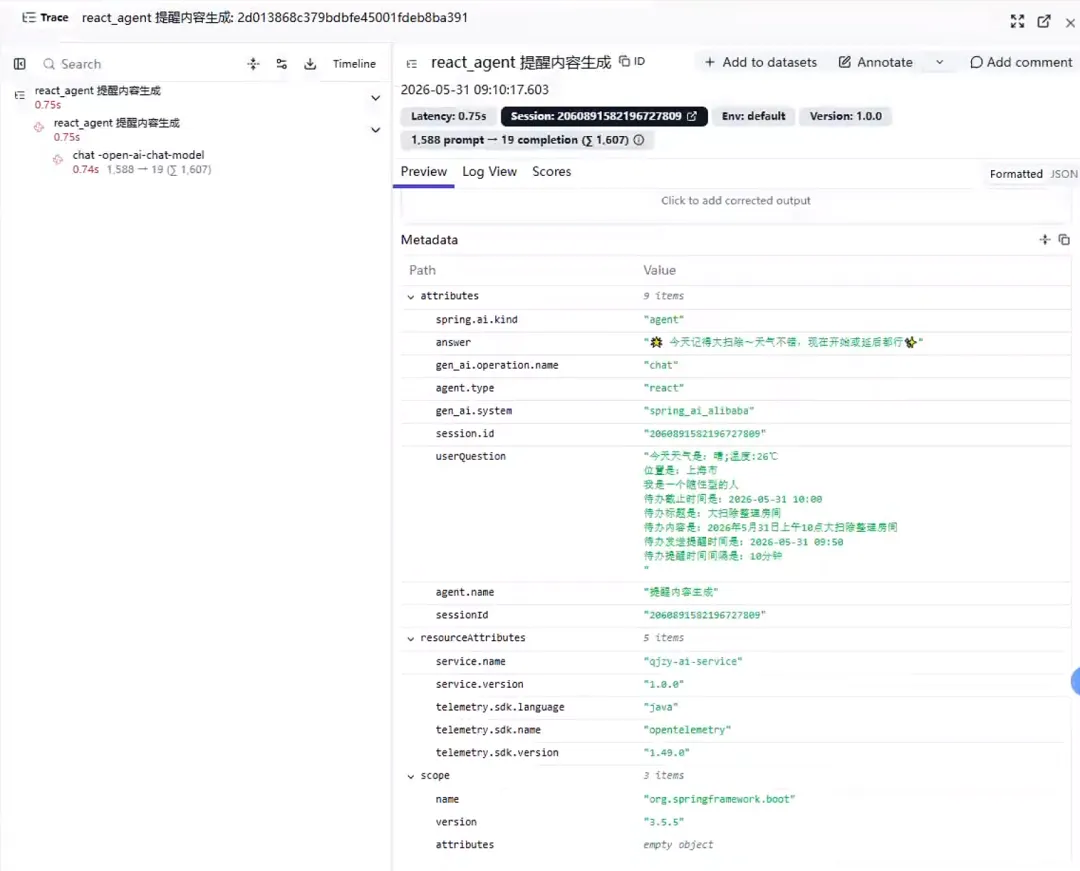
为什么不能一开始暴露所有工具
我之前踩过一个很典型的坑:把工具暴露得太早。
当时的实现里,Agent 一开始就能看到所有 Java Tool,比如添加待办、删除待办、批量规划等。
看起来很方便。
但实际效果并不好。
模型还没读取当前 Skill 的说明,就可能直接调用某个工具。
结果常见问题是:
参数没填完整; 把批量规划当成单条待办; 该先查询确认时直接删除; 工具虽然调了,但业务字段不符合要求; 报错以后模型又开始补一段看似合理的解释。
这类问题的本质是:工具太多,边界太早暴露。
大模型擅长理解语言,但它不是业务系统里的权限控制器。
如果我们把所有工具一开始都放在它面前,它很容易在上下文还不充分时做出错误选择。
所以后面我把思路改成了“渐进式工具披露”。
这个能力不是我自己凭空想出来的,Spring AI Alibaba 的 Skills 机制里就有类似的高级特性。
它的思路是:系统可以先把 Skill 列表放进上下文,让模型知道当前有哪些能力;但具体工具不需要一开始全部暴露。工具可以和 Skill 技能名绑定,只有当模型对某个技能调用了 read_skill 以后,这个技能对应的工具才会加入当次请求。
更关键的是,技能一旦被激活,对应工具在会话后续轮次中仍然可用。
这点对 Agent 很重要。
因为真实任务往往不是一轮对话就结束。
比如创建待办时,第一轮用户只说了“明天下午提醒我开会”,Agent 可能需要先读取 todo 技能,发现时间足够明确后调用创建工具;如果工具返回“当天已有安排”,下一轮还要继续使用同一组工具处理用户确认。
如果每一轮都重新暴露全部工具,模型选择空间太大。
如果工具只在当前一轮短暂可用,后续确认又会断掉。
所以“Skill 激活后工具在后续轮次仍可用”这个设计,刚好适合这种多轮业务操作。
用一句话概括就是:
先让 Agent 知道有哪些能力,再让它读取当前能力的使用说明,最后才给它对应工具。
我的待办 Agent 链路
简化后的链路大概是这样:
用户输入 ↓ReactAgent 推理 ↓判断需要 todo / planning 技能 ↓调用 read_skill 读取技能说明 ↓系统动态注入该技能对应工具 ↓模型提取字段并调用 Java @Tool ↓AI 中台请求业务服务 ↓业务服务校验并落库 ↓返回创建结果 ↓Agent 根据结果回复用户这个链路里有几个关键点。
第一,初始阶段只暴露 read_skill。
也就是说,模型一开始不能直接调用 todo_add_todo。
它需要先判断当前任务应该使用哪个 Skill。
第二,工具和 Skill 绑定。
比如 todo 技能下面才有单条待办增删改查工具,planning 技能下面才有批量规划工具。
第三,每一轮请求都从消息历史里检查哪些 Skill 已经被读取过。
如果模型读过 todo,系统就在后续请求里注入 todo 对应工具。
如果读过 planning,就注入规划相关工具。
这比“所有工具常驻”稳定很多。
模型不会在还没理解 Skill 规则时乱调工具。
从 Shell + Python 到 Java @Tool
工具披露解决的是“该不该调用、调用哪个”的问题。
但工具真的被调用以后,还有另一个工程问题:调用链路要尽量短。
早期方案里,Agent 创建待办大概是这样:
LLM ↓Shell 工具 ↓Python 脚本 ↓Redis ↓业务服务消费消息 ↓MySQL这个方案能跑,但链路太长。
每次调用都要启动子进程,Python 冷启动,还有 Redis 连接和异步一致性问题。
如果只是做 Demo,这些问题不明显。
但放到真实 App 里,用户说一句话后要等几秒,体验就会很差。
所以后面我改成了 Java @Tool + HTTP 的方式:
LLM ↓Java @Tool ↓AI 中台 HTTP 调用业务 RPC ↓业务服务校验并写库 ↓返回结构化结果这样做的收益很直接。
一是少了 Shell 和 Python 子进程。
二是少了 Redis 中转。
三是业务结果可以同步返回给 Agent。
四是排查问题时,日志链路更清楚。
对用户来说,这些都不会直接看见。
但他会感受到:小宇创建待办更快,失败时也更容易给出明确原因。
待办创建工具不能只负责写库
很多人做 Tool Calling 时,会把工具理解成“模型调一个接口,接口写数据库”。
但在真实业务里,这还不够。
待办创建工具至少要处理几类情况。
第一,字段完整性。
标题不能为空,日期格式要正确,用户身份要明确。
如果用户只说“下周提醒我复盘”,但没说具体哪一天,Agent 就不应该硬猜。
第二,时间冲突。
如果用户明天下午已经有安排,再创建一条同时间待办,最好提示一下。
第三,批量任务。
用户说“帮我规划下周工作”,很可能不是一条待办,而是多条任务。这个场景应该走 planning,而不是 todo_add_todo。
第四,返回结果要结构化。
工具不能只返回“成功”两个字。
它最好告诉 Agent:创建成功、创建失败、缺少字段、存在冲突,或者需要用户确认。
这样 Agent 才能继续做下一步。
比如同一天已有未完成待办,可以返回冲突信息,让 Agent 追问:
你明天下午已经有一个安排,是否仍然创建这条待办?这类确认很重要。
AI 产品最怕的不是“不够聪明”,而是“自作主张”。
核心逻辑可以简化成这样
为了把链路说清楚,可以把关键逻辑抽象成三段。
// 1. 初始只暴露 read_skillList<ToolCallback> getTools() { return List.of(readSkillTool);}// 2. 根据 read_skill 历史动态注入工具ModelRequest intercept(ModelRequest request) { Set<String> activatedSkills = extractReadSkillNames(request.messages()); List<ToolCallback> tools = new ArrayList<>(); for (String skillName : activatedSkills) { tools.addAll(groupedTools.getOrDefault(skillName, List.of())); } return ModelRequest.builder(request) .dynamicToolCallbacks(tools) .build();}// 3. 待办工具只做受控业务调用@Tool(name = "todo_add_todo")String addTodo(AddTodoRequest req) { validate(req); checkConflict(req); return todoRpcClient.add(req);}这里有三个关键点。
第一,getTools() 不直接返回所有业务工具。
第二,工具是否可用,取决于模型是否已经读取过对应 Skill。
第三,真正写库还是交给业务服务,Agent 只通过受控工具触发业务动作。
这样设计后,Agent 的行为会更接近一个可维护系统,而不是一个随时可能乱点按钮的聊天模型。
用户感受到的是什么
用户不会关心我们用了 ReactAgent、Skill 还是 Java @Tool。
用户能感受到的是:
第一,说话能创建真实任务。
不是回复“好的”,而是待办列表里真的出现一条任务。
第二,不用手动填很多字段。
自然语言里能识别出的标题、日期、时间,会被自动提取。
第三,关键场景不乱来。
信息不完整时追问,时间冲突时确认,不会为了显得智能就替用户乱决定。
第四,后续能力可以扩展。
今天是创建待办,后面可以继续扩展到批量规划、日程调整、协作邀请、提醒生成。
对技术系统来说,这叫工具调用链路。
对用户来说,就是“小宇真的能帮我把事情安排起来”。
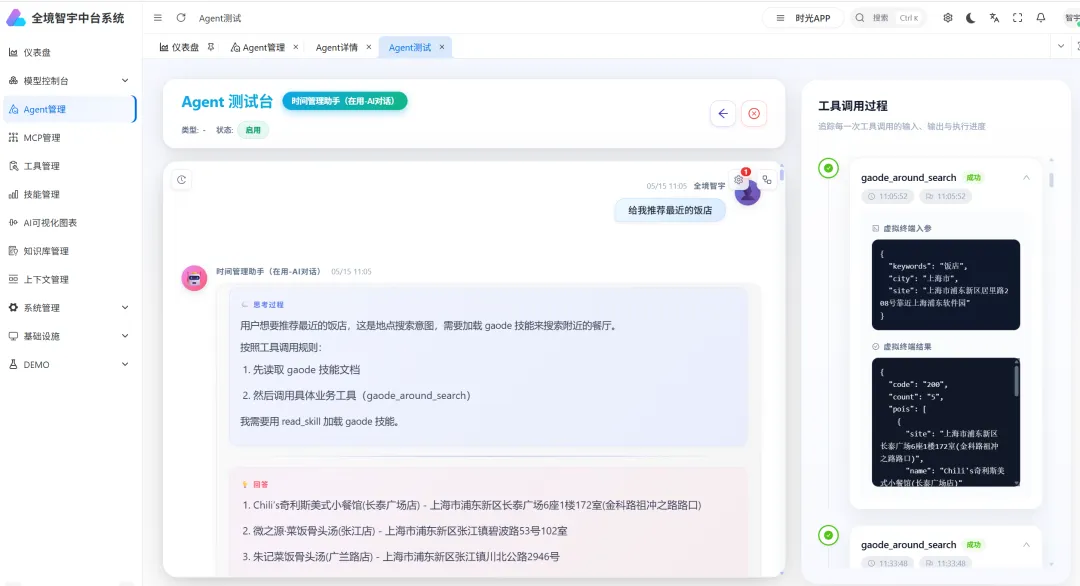
最后
一句话创建待办,表面上看是一个很小的功能。
但真放到 App 里做,就会发现它背后并不只是“让模型理解一句话”。
它涉及 Agent 如何选择技能、工具如何按需暴露、自然语言如何转成结构化字段、业务工具如何校验和落库。
这也是我现在对 AI 应用开发最大的感受:Demo 里最吸引人的是模型回答得聪明,真实产品里最重要的是每一次工具调用都可控、可追踪、可恢复。
后面我会继续结合时光笺的开发过程,记录一些 AI Agent 落地到真实 App 里遇到的问题。
如果你也在做 Agent 应用,或者正在研究 Spring AI Alibaba,希望这篇文章能给你一点参考。感兴趣的话,也可以去应用商店搜索「时光笺」体验一下。
我是南哥,10年全栈工程师,小公司项目经理
喜欢研究新技术,分享技术干货
回复“AI入门”,领取7本AI入门电子书;
回复“AI学习”,领取17本AI必看电子书;
